








🚀 JUC并发编程 - 4. 共享模型之管程
这一节我们聚焦 共享模型,理解多线程操作共享资源时出现的各种问题,以及 Java 提供的解决方案。
📚 本章内容
-
共享问题
-
synchronized
-
线程安全分析
-
Monitor
-
wait/notify
-
线程状态转换
-
活跃性
-
Lock
4.1 共享带来的问题
小故事
老王(操作系统)有一台超厉害的算盘(CPU),为了赚钱,他租给别人用。
👦 小南 和 👧 小女(两个线程)来租算盘,分别执行自己的计算任务,并按使用时间付费。
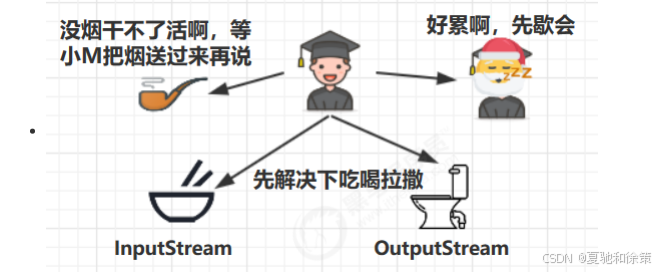
但小南工作时:
-
有时候打个盹(
sleep) -
有时候去厕所(阻塞 I/O)
-
有时候抽烟,没烟就啥也干不了(
wait)
这些情况都属于 阻塞状态,算盘就闲置了,老王很不爽,觉得浪费。
而且,小女也急着用算盘,如果老是被小南霸着,就不公平。
于是老王灵机一动:
“轮流用!小南你用一会,小女你再用一会。”
✅ 结果:
当小南阻塞时,算盘可以分给小女使用,不浪费;反之亦然。
🧠 理论理解
当多个线程共享同一块数据时,尤其是读写操作交织,就会产生所谓的 “并发冲突”。
关键问题:
-
单线程中,CPU 执行是顺序的,数据一致性有保障。
-
多线程中,CPU 会进行上下文切换,导致线程操作共享资源的步骤交错。
这就引出了两个核心概念:
-
临界区(Critical Section):
包含对共享资源的读写的那段代码区域。 -
竞态条件(Race Condition):
多线程在临界区交替执行时,由于顺序不确定,导致程序结果不可预测。
这正是并发编程中最“诡异”的问题之一:看似简单的代码,却因为线程交错执行,出现各种意料之外的结果。
🏢 企业实战理解
阿里巴巴:
在电商高并发秒杀系统中,如果库存扣减的逻辑没有加锁保护,会导致“超卖”现象,用户明明看着有库存,却最终下单失败,这就是典型的共享资源冲突。
美团:
在骑手实时调度系统中,大量线程同时修改“订单状态”,需要保证状态修改是原子的,否则会出现“同一个订单同时被两个骑手接单”的风险。
NVIDIA:
在 GPU 多任务并行计算中,线程块(warp)共享显存,如果对显存的读写不加同步,会导致数据污染,影响整个矩阵计算的精度。
💬 面试题(字节跳动)
问:多线程操作共享资源时为什么会出现数据不一致问题?根本原因是什么?
✅ 参考答案
根本原因是非原子性操作:
虽然一个语句看起来是单个操作(如 counter++),但底层其实拆成多步(读取 → 修改 → 写回),而线程切换可能发生在任意一步,这就导致了共享数据在多线程场景下的数据不一致。
Java 内存模型(JMM)下,线程的工作内存和主存交换数据也加剧了这种问题。
💬 场景题(字节跳动)
你开发一个接口统计请求次数,代码用 counter++ 记录访问量,压测时发现数据不稳定,实际请求 10000 次,结果有时是 10000,有时是 9000 多,有时 10000 多。请分析原因和优化思路。
✅ 参考答案
原因:
-
counter++不是原子操作,多个线程在高并发下交替执行,发生了数据竞争,导致丢失或覆盖。
优化思路:
1️⃣ 使用 AtomicInteger 替代 int,通过 CAS 保证原子性
2️⃣ 或者用 synchronized 包裹自增逻辑
3️⃣ 更好的做法:用 Redis 的原子自增命令实现分布式统计
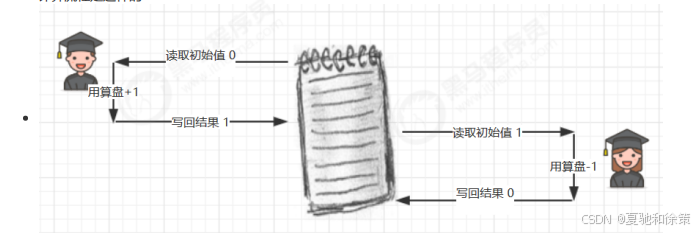
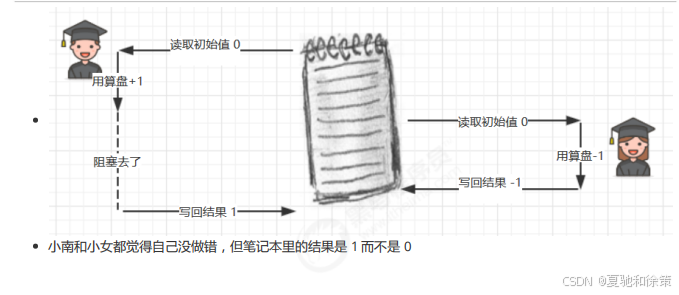
笔记本事故
最近的任务比较复杂,计算中要记录中间结果。由于小南和小女脑容量不够(线程的工作内存有限),老王准备了一个笔记本(主存)帮忙记录。
流程是这样的:
1️⃣ 小南读到笔记本的初始值 0,做了 +1 运算,还没写回。
2️⃣ 老王喊停:“小南,你时间到了!” 小南只好把 1 记在脑子里,离开了。
3️⃣ 老王叫小女上场,小女看笔记本还是 0,做了 -1 运算,写回 -1。
4️⃣ 老王再喊小南回来:“继续干!” 小南把脑中的 1 写了回去。
🔎 结果:
小南和小女都没错,但最后笔记本的值是 1,不是预期的 0。
💻 Java 实例
我们用 Java 代码模拟一下 👇:
static int counter = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5000; i++) {
counter++;
}
}, "t1");
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5000; i++) {
counter--;
}
}, "t2");
t1.start();
t2.start();
t1.join();
t2.join();
log.debug("最终结果: {}", counter);
}
看起来很简单:
两个线程,一个做 +1,一个做 -1,各5000次,按理结果是 0 对吧?
❗ 实际上,多次运行,你会发现结果可能是 0、正数、负数……
🔬 问题分析
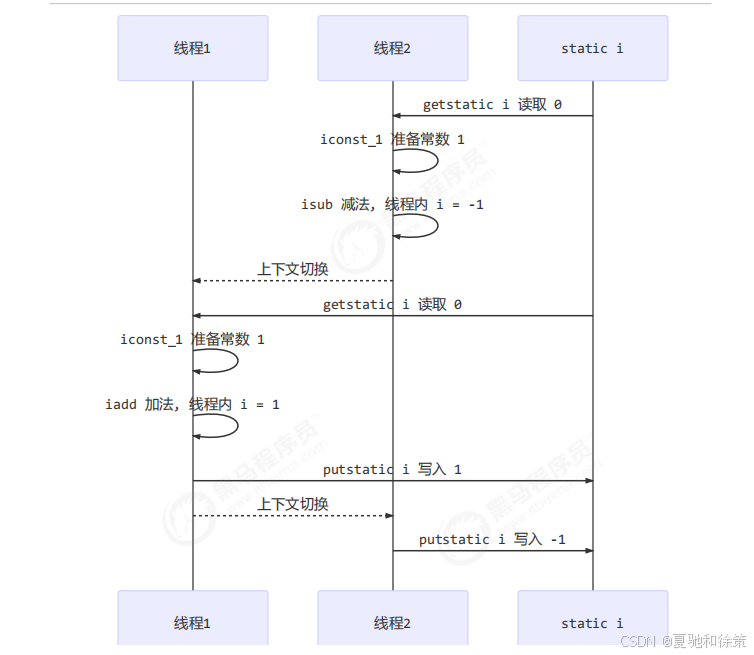
原因:自增/自减不是原子操作。
例如 counter++ 实际上拆成了如下 JVM 字节码指令:
getstatic i // 读取 counter
iconst_1 // 准备 1
iadd // 执行加法
putstatic i // 写回 counter
counter-- 同理:
getstatic i // 读取 counter
iconst_1 // 准备 1
isub // 执行减法
putstatic i // 写回 counter
🧩 内存模型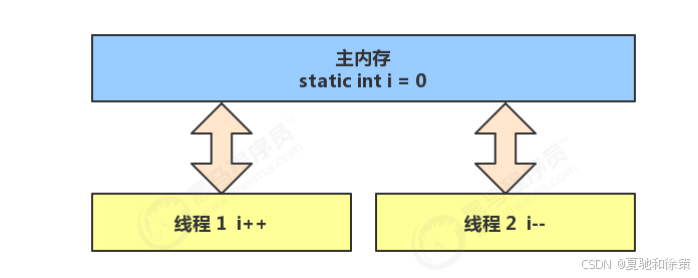
在 Java 内存模型中,静态变量的自增/自减涉及 主存 和 线程工作内存 之间的数据交换。
✅ 单线程没问题:
1️⃣ 读取 i(主存)
2️⃣ 加/减
3️⃣ 写回 i
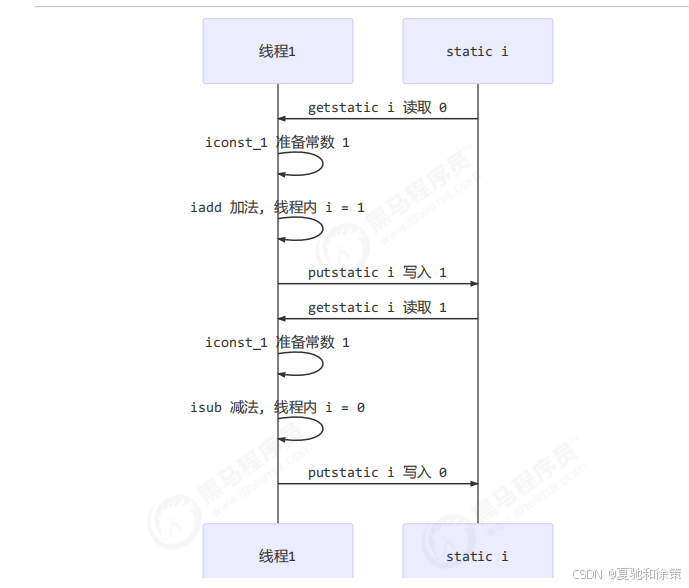
❌ 多线程会交错:
示例1:出现负数
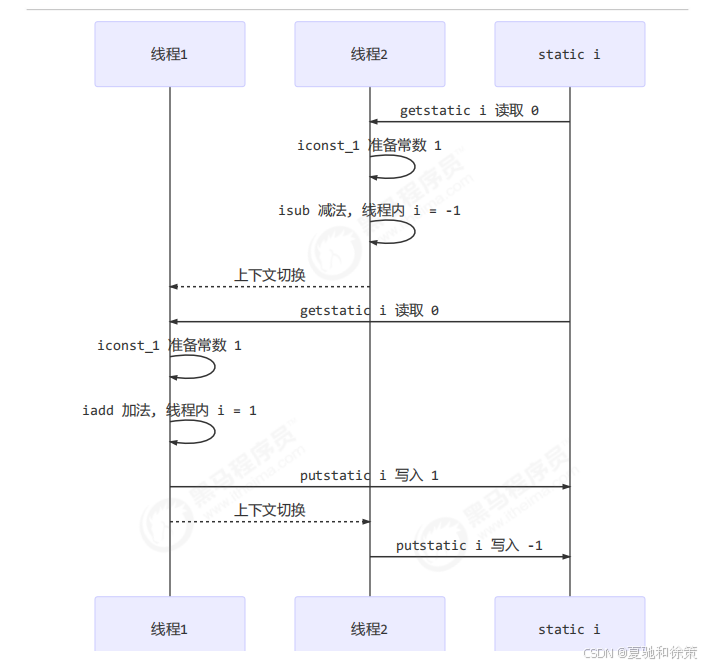
| 线程1 | 线程2 |
|---|---|
| 读取 0 | |
| 加 1 | |
| 读取 0 | |
| 减 1 | |
| 写入 1 | |
| 写入 -1 |
示例2:出现正数
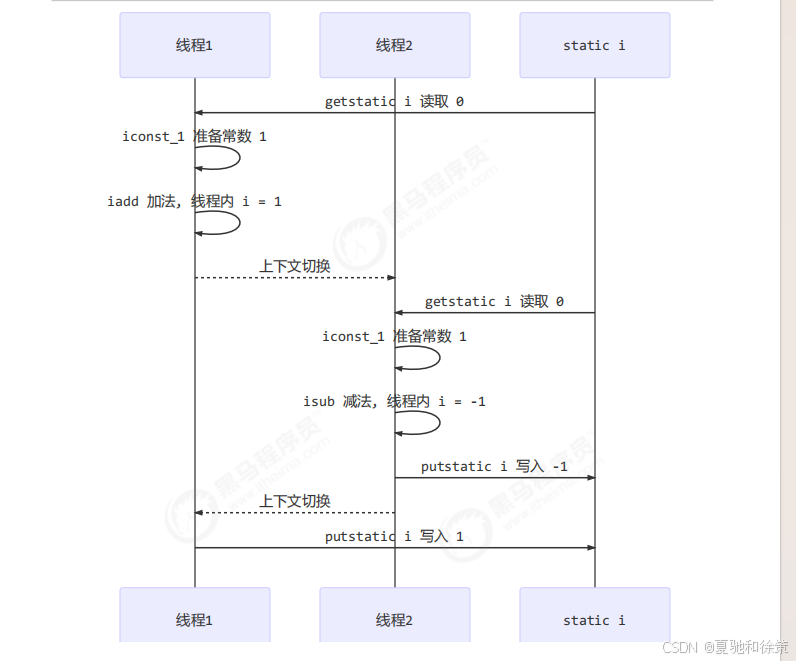
| 线程1 | 线程2 |
|---|---|
| 读取 0 | |
| 读取 0 | |
| 加 1 | |
| 减 1 | |
| 写入 1 | |
| 写入 -1 |
结果是不可预测的!
🧠 理论理解
counter++ 看似简单,其实底层是三步:
1️⃣ 读取 counter(从主存 → 线程的工作内存)
2️⃣ +1 操作
3️⃣ 写回 counter(从工作内存 → 主存)
这三步是分开的!如果两个线程“同时”执行到 读取 阶段,都会拿到相同的值,接下来无论怎么加/减,都会导致最终结果覆盖、丢失。
根源:非原子性。
🏢 企业实战理解
字节跳动:
在短视频点赞/评论等高并发场景中,后端会用 Redis 的 原子自增 替代传统数据库的自增,避免出现“丢点赞”现象。
华为云:
后台服务统计 PV/UV 时会使用 CAS(Compare And Swap)保证并发写入的安全性,而不是简单的 count++。
💬 面试题(腾讯)
问:为什么 counter++ 不是线程安全的?它背后具体拆解成了什么步骤?
✅ 参考答案
counter++ 在 Java 字节码层面会被拆分为:
1️⃣ getstatic(读取 counter)
2️⃣ iconst_1(准备 1)
3️⃣ iadd(执行 +1)
4️⃣ putstatic(写回 counter)
这四步不是原子操作。多个线程可能在 1️⃣ 读取完成后被切换走,导致“旧值”被多次读取并修改,进而出现数据覆盖。
💬 场景题(腾讯)
你写了两个线程,一个做 counter++,一个做 counter--,结果预期是 0,但运行几次之后发现结果可能是 0,也可能是正数/负数。请用底层原理解释这个现象。
✅ 参考答案
counter++ 和 counter-- 都是非原子性操作,每次都拆解成 读取 → 修改 → 写回 三步。
当两个线程同时读取时,都会拿到旧值 0,即使一个加 1、一个减 1,最后各自写回时就会出现:
-
线程1:+1 写入 1
-
线程2:-1 写入 -1
它们覆盖了彼此的结果,导致数据不一致。
3️⃣ 临界区 & 竞态条件
🔒 临界区(Critical Section)
👉 问题根源: 多线程“同时”操作 共享资源 时出现的 竞态条件(Race Condition)。
-
✔ 读共享资源(无风险)
-
❗ 读+写共享资源(高风险)
比如上面的 counter++ / counter--,这块代码就是 临界区:
多个线程访问共享资源,并且至少有一个线程在修改它。
💬 面试题(阿里)
问:什么是临界区?什么是竞态条件?这两者有什么联系?
✅ 参考答案
-
临界区(Critical Section):
指多线程环境下,访问共享资源的代码块。 -
竞态条件(Race Condition):
指多个线程在临界区内交替执行,由于执行顺序不同,导致程序行为或结果不确定。
关系:临界区是“战场”,竞态条件是“结果”。
只要存在共享资源 + 多线程修改,就有临界区,也就有发生竞态的风险。
💬 场景题(阿里)
一次并发测试中,你发现线程池中多个线程读写同一个 List,有时会抛出 ConcurrentModificationException,有时数据丢失。请分析原因,指出代码的“临界区”在哪,并提出解决方案。
✅ 参考答案
原因:
-
多个线程同时对
ArrayList进行写操作,ArrayList本身不是线程安全的。
临界区:
-
list.add()、list.remove()等涉及共享资源的代码块就是典型临界区。
解决方案:
1️⃣ 使用 Collections.synchronizedList() 包装
2️⃣ 或者改为 CopyOnWriteArrayList
3️⃣ 高并发下考虑 ConcurrentLinkedQueue 等无锁队列
⚠ 竞态条件(Race Condition)
当多个线程在临界区交替执行时,由于执行顺序不同,导致最终结果不可预测,就发生了竞态条件。
➡ 解决方案(后续章节讲解):
-
synchronized
-
Lock
-
原子变量
🧠 理论理解
“临界区” 是潜在问题发生的“战场”;
“竞态条件” 是因为多个线程抢占战场,导致结果混乱。
核心点:
-
临界区:只要共享资源+读写就一定有临界区。
-
竞态条件:是指由于执行顺序不同,结果不确定。
解决方法的本质就是 锁住临界区,让多个线程 有序排队 执行。
🏢 企业实战理解
腾讯:
在 QQ 消息推送系统中,消息队列是典型的临界区,腾讯采用 多级锁分段机制,把大锁拆成小锁,提高并发性能。
Google:
在 Chrome 浏览器的多线程渲染中,DOM 树操作是一个临界区,Google 团队用细粒度锁、异步任务分发等技术避免阻塞渲染主线程。
4️⃣ CPU 上下文切换
🧠 理论理解
上下文切换是 CPU 在多个线程之间切换时的一个“保存-恢复”过程:
-
保存当前线程的执行状态(寄存器、栈等)
-
加载新线程的状态
这个过程本身是有开销的,而“竞态条件”很多时候正是因为上下文切换时机不同导致。
🏢 企业实战理解
美团:
高并发请求中,过多的上下文切换导致线程池“雪崩”现象,美团通过限流、熔断等手段减少切换。
OpenAI:
在 GPT 推理引擎中,推理过程会尽量绑定 CPU 核心,避免多次切换带来的性能抖动。
💬 面试题(美团)
问:什么是上下文切换?它对并发程序的影响是什么?
✅ 参考答案
上下文切换是指 CPU 保存当前线程状态并切换到另一个线程执行的过程。涉及:
-
保存/恢复 CPU 寄存器
-
切换堆栈、程序计数器
-
更新操作系统调度信息
影响:
-
开销大: 每次切换消耗 CPU 资源
-
易出问题: 临界区操作时若发生切换,会导致竞态条件出现
优化建议:
-
降低线程数量(避免过度并发)
-
使用线程池复用线程,减少频繁创建和销毁
💬 场景题(美团)
在一次性能优化中,你发现线程池开了 1000 个线程,但服务器只有 8 核,结果 CPU 使用率很高但吞吐量反而下降。请解释原因。
✅ 参考答案
原因:
-
过多线程同时争抢 CPU,导致上下文切换频繁,大量 CPU 时间浪费在保存/恢复线程状态上,实际用于任务执行的时间反而变少。
优化:
-
降低线程池大小,控制在
CPU 核心数 * 2左右 -
使用异步/事件驱动架构减少阻塞线程
5️⃣ Java 内存模型
💬 面试题(华为)
问:Java 内存模型(JMM)中,为什么线程操作共享变量时会出现“可见性问题”?
✅ 参考答案
JMM 定义了主内存和线程工作内存的交互:
-
每个线程有自己的工作内存(类似缓存)
-
操作共享变量时,线程会从主内存拷贝到工作内存再执行
问题:
当一个线程修改了共享变量的值但未及时刷新到主存时,其他线程依然看到的是旧值,造成可见性问题。
解决方案:
-
使用
volatile -
使用锁(synchronized、ReentrantLock)
💬 场景题(华为云)
你在实现一个标志位 running = true 控制线程运行,期望某个线程能检测到 running = false 及时停止。但实际中发现,设置 running = false 后,线程依然无限循环。请分析原因和解决方法。
✅ 参考答案
原因:
-
running是普通变量,可见性问题导致其他线程没有立刻看到更新后的值(仍然在本地缓存中读取旧值)。
解决方法:
1️⃣ 将 running 声明为 volatile
2️⃣ 或者用 synchronized 封装读取和修改
✅ 总结
这一节我们通过一个有趣的小故事,讲清楚了:
-
线程共享模型的本质
-
为什么会出现线程安全问题
-
临界区 & 竞态条件的概念
-
以及 Java 中经典的竞态演示
在并发编程中,共享资源 + 多线程修改 是 bug 的温床!下一节我们将进入 synchronized 解决方案 👊。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











