








Spring_day02
今日目标
掌握IOC/DI配置管理第三方bean
掌握IOC/DI的注解开发
掌握IOC/DI注解管理第三方bean
完成Spring与Mybatis及Junit的整合开发
1,IOC/DI配置管理第三方bean
前面所讲的知识点都是基于我们自己写的类,现在如果有需求让我们去管理第三方jar包中的类,该如何管理?
1.1 案例:数据源对象管理
在这一节中,我们将通过一个案例来学习下对于第三方bean该如何进行配置管理。
以后我们会用到很多第三方的bean,本次案例将使用咱们前面提到过的数据源Druid(德鲁伊)和C3P0来配置学习下。
1.1.1 环境准备
学习之前,先来准备下案例环境:
-
创建一个Maven项目

-
pom.xml添加依赖
<dependencies> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>5.2.10.RELEASE</version> </dependency> </dependencies> -
resources下添加spring的配置文件applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> </beans> -
编写一个运行类App
public class App { public static void main(String[] args) { ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml"); } }
🧠 理论理解
Spring的IOC容器在启动时会扫描 applicationContext.xml 配置文件,根据里面定义的 <bean> 创建和管理对象。这里的环境准备是为了搭建Spring最基本的运行环境,包括导入Spring核心依赖和配置IOC文件,确保项目具备最小可运行单元。
🏢 企业实战理解
BAT和字节跳动等大厂,Spring是后端服务的标配,基础环境配置常会通过**自动化工具(如Maven、Gradle)+配置中心(如Apollo、Nacos)**来统一管理,保障一致性。Google虽然更多采用自研框架,但在与Java项目集成时也会用类似IOC容器管理依赖。NVIDIA和OpenAI偏重Python生态,类似的IOC机制由框架如FastAPI的依赖注入来完成。
题目1:Spring的IOC容器是如何加载 applicationContext.xml 文件的?加载过程中有哪些核心步骤?
参考答案:
Spring的IOC容器通过 ClassPathXmlApplicationContext 或 FileSystemXmlApplicationContext 加载 applicationContext.xml 文件,主要经历如下步骤:
1️⃣ 定位资源:利用ResourceLoader定位XML配置文件的位置(classpath下或文件系统路径)。
2️⃣ 解析XML:通过 XmlBeanDefinitionReader 使用SAX/DOM方式解析配置文件,将 <bean> 标签解析为 BeanDefinition。
3️⃣ 注册Bean:将 BeanDefinition 注册到 BeanDefinitionRegistry 中。
4️⃣ 实例化Bean:根据 getBean() 的调用,按需实例化对象并注入依赖。
BAT常考细节:IOC加载时机与懒加载策略、是否可以动态注册Bean。字节跳动还会深问解析时用到的设计模式,如工厂模式、模板方法模式。
场景题1:
你在字节跳动负责一个内部中台项目,准备上线一个新的数据统计模块。这个模块需要用Spring进行IOC容器初始化。由于涉及到多个子模块的依赖Bean,环境准备阶段你如何设计项目结构和配置文件来保证IOC容器加载正常,且方便后期维护?如果上线过程中出现 BeanDefinitionParsingException 错误,你怎么排查?
参考思路:
-
将配置文件按模块拆分(如
applicationContext-dao.xml、applicationContext-service.xml),主文件用<import>引入子配置; -
使用
<beans profile="dev">等profile标签支持多环境切换; -
出现
BeanDefinitionParsingException:
1️⃣ 检查XML标签是否拼写错误或命名空间缺失;
2️⃣ 确认XSD文件路径正确(如spring-beans.xsd);
3️⃣ 确认Maven依赖导入无误,Spring版本一致。
在阿里云微服务中台场景中,也会强制要求配置文件模块化、自动化校验,避免上线时出错。
1.1.2 思路分析
在上述环境下,我们来对数据源进行配置管理,先来分析下思路:
需求:使用Spring的IOC容器来管理Druid连接池对象
1.使用第三方的技术,需要在pom.xml添加依赖
2.在配置文件中将【第三方的类】制作成一个bean,让IOC容器进行管理
3.数据库连接需要基础的四要素
驱动、连接、用户名和密码,【如何注入】到对应的bean中4.从IOC容器中获取对应的bean对象,将其打印到控制台查看结果
思考:
-
第三方的类指的是什么?
-
如何注入数据库连接四要素?
🧠 理论理解
Spring IOC的核心在于控制反转,无论是自定义类还是第三方类,只要是Java对象,都可以被Spring管理。关键是通过反射机制实例化对象,并通过setter或构造器注入属性,实现“无侵入式”集成。
🏢 企业实战理解
阿里云的微服务中大量使用第三方bean,如数据库连接池、消息中间件客户端,均交由Spring托管。字节跳动飞书等服务也强调“代码零侵入”,通过IOC加载第三方对象,结合内部APM实现动态注入监控钩子。Google/NVIDIA等更注重“低耦合”,在类似Spring的IOC框架下实现灵活解耦。
题目2:Spring如何管理一个第三方类的实例?Spring内部是如何实现反射机制来生成对象的?
参考答案:
Spring通过在 applicationContext.xml 中配置 <bean> 标签,并指定 class 属性,即可管理任意第三方类。Spring内部使用反射机制:
-
使用
Class.forName(className)加载Class对象; -
通过
clazz.newInstance()或反射调用构造器实例化对象; -
使用
setPropertyValue()方法通过反射设置属性值(setter注入)。
Google/字节跳动还会考察:Spring的反射机制是否有优化?比如:
Spring内部对反射调用进行了缓存(CachedIntrospectionResults),避免重复反射带来的性能损耗。
场景题2:
你在阿里巴巴的支付系统团队,接到一个任务:需要在Spring项目中集成一个第三方的加密SDK(无源码)。你会如何利用Spring的IOC机制管理这个第三方bean?此外,业务上线后反馈偶尔出现 NoSuchMethodException,你会如何排查这个问题?
参考思路:
-
在
applicationContext.xml中使用<bean class="com.xxx.EncryptSDK">定义bean; -
通过
<property>配置必要参数(如密钥、算法类型); -
如果该SDK有构造器参数,可考虑使用
constructor-arg注入。
排查NoSuchMethodException:
1️⃣ 检查是否是setter方法名拼写错误;
2️⃣ 检查该SDK版本是否变更导致方法签名变化;
3️⃣ 使用ReflectUtils工具快速验证反射调用链。
字节跳动常遇到这种第三方集成问题,要求在CI/CD上线前编写自动化反射验证工具。
1.1.3 实现Druid管理
带着这两个问题,把下面的案例实现下:
步骤1:导入druid的依赖
pom.xml中添加依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.16</version>
</dependency>步骤2:配置第三方bean
在applicationContext.xml配置文件中添加DruidDataSource的配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!--管理DruidDataSource对象-->
<bean class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/spring_db"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</bean>
</beans>说明:
-
driverClassName:数据库驱动
-
url:数据库连接地址
-
username:数据库连接用户名
-
password:数据库连接密码
-
数据库连接的四要素要和自己使用的数据库信息一致。
步骤3:从IOC容器中获取对应的bean对象
public class App {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
DataSource dataSource = (DataSource) ctx.getBean("dataSource");
System.out.println(dataSource);
}
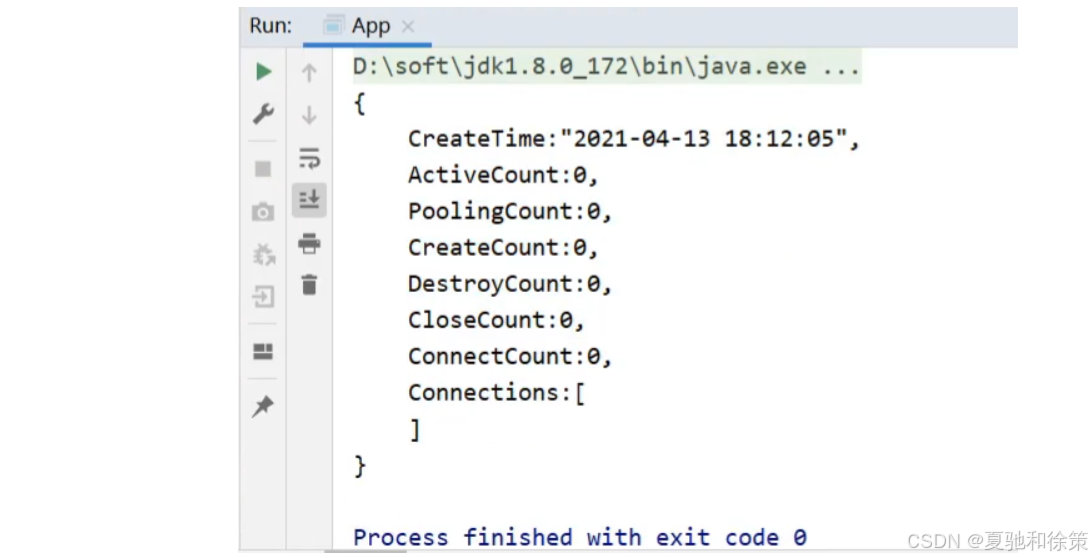
}步骤4:运行程序
打印如下结果: 说明第三方bean对象已经被spring的IOC容器进行管理
做完案例后,我们可以将刚才思考的两个问题答案说下:
-
第三方的类指的是什么?
DruidDataSource
-
如何注入数据库连接四要素?
setter注入
🧠 理论理解
Druid是阿里巴巴开源的高性能数据库连接池,Spring通过 <bean> 标签+ property 注入方式管理其生命周期。这充分展示了Spring的反射+setter注入机制,不需要改动Druid源码就能实现配置托管。
🏢 企业实战理解
阿里云ECS与RDS组合使用时,大量服务内置Druid连接池,并通过Spring注入数据源,实现动态连接池配置(如连接数上限、慢查询分析)。字节跳动强调自监控,Druid本身的监控能力结合Spring AOP拓展,实现数据库连接池的实时健康监测。OpenAI虽偏向PostgreSQL+Python,但其Java模块在早期实验中也曾用过类似管理模式。
题目3:Druid连接池的核心优势是什么?为什么它适合在Spring项目中使用?
参考答案:
Druid是阿里巴巴开源的高性能数据库连接池,具有以下核心优势:
1️⃣ 性能高:SQL执行效率高,连接池性能超过C3P0、DBCP等传统连接池。
2️⃣ 自带监控:内置强大的监控功能,能够实时采集SQL执行时间、慢查询日志等信息。
3️⃣ 稳定性强:支持连接泄露检测、SQL防火墙(防止SQL注入)等。
4️⃣ 易集成:和Spring无缝对接,支持setter注入配置,官方提供 DruidDataSource 作为标准实现。
阿里云面试重点追问监控机制的实现方式(比如 StatFilter 工作流程),字节跳动/腾讯还常考:为什么Druid在高并发环境比C3P0表现更好(答:线程池、锁机制优化、断开检测机制更优)。
场景题3:
在你负责的美团骑手服务平台中,使用Druid做数据库连接池。高峰时段发现数据库连接频繁超时,导致大量请求堆积。此时你从Spring IOC中获取到DruidDataSource实例后,打算临时调整其连接池大小和超时时间,不重启服务。请问你的处理步骤是什么?如何用Spring保证这种动态修改的可控性?
参考思路:
-
通过Spring上下文获取
DruidDataSource对象实例; -
调用其
setMaxActive()、setMinIdle()等方法动态修改连接池参数; -
使用Spring的
@Scheduled定时任务监控连接数,结合Druid自身StatViewServlet查看实时状态; -
长期方案:对接配置中心(如Apollo),结合Spring
@RefreshScope实现热更新。
阿里云线上场景中也会动态扩容数据库连接池,应对大促等瞬时流量高峰。
1.1.4 实现C3P0管理
完成了DruidDataSource的管理,接下来我们再来加深下练习,这次我们来管理C3P0数据源,具体的实现步骤是什么呢?
需求:使用Spring的IOC容器来管理C3P0连接池对象
实现方案和上面基本一致,重点要关注管理的是哪个bean对象`?
步骤1:导入C3P0的依赖
pom.xml中添加依赖
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.1.2</version>
</dependency>对于新的技术,不知道具体的坐标该如何查找?
-
直接百度搜索
-
从mvn的仓库
https://mvnrepository.com/中进行搜索
步骤2:配置第三方bean
在applicationContext.xml配置文件中添加配置
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="com.mysql.jdbc.Driver"/>
<property name="jdbcUrl" value="jdbc:mysql://localhost:3306/spring_db"/>
<property name="user" value="root"/>
<property name="password" value="root"/>
<property name="maxPoolSize" value="1000"/>
</bean>==注意:==
-
ComboPooledDataSource的属性是通过setter方式进行注入
-
想注入属性就需要在ComboPooledDataSource类或其上层类中有提供属性对应的setter方法
-
C3P0的四个属性和Druid的四个属性是不一样的
步骤3:运行程序
程序会报错,错误如下
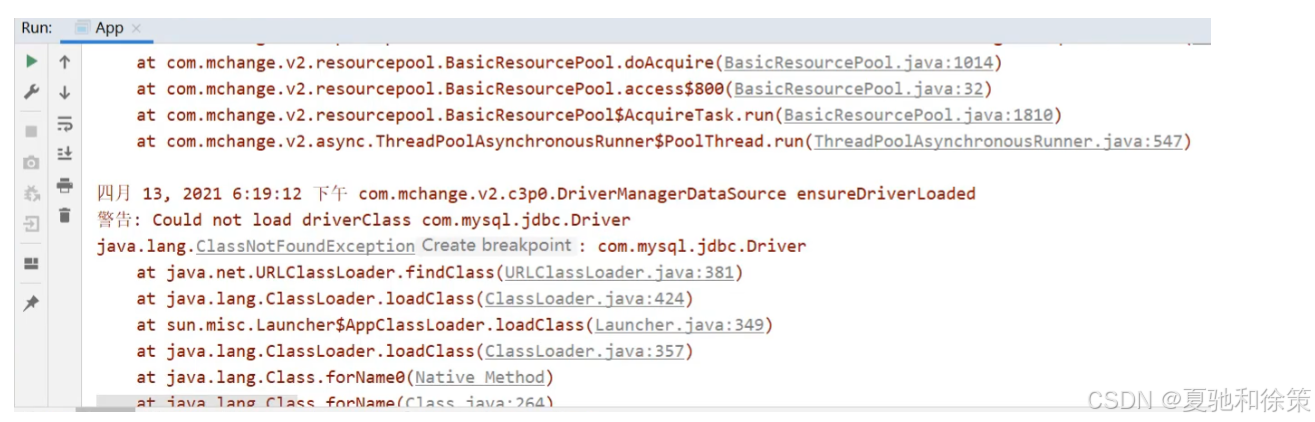
报的错为==ClassNotFoundException==,翻译出来是类没有发现的异常,具体的类为com.mysql.jdbc.Driver。错误的原因是缺少mysql的驱动包。
分析出错误的原因,具体的解决方案就比较简单,只需要在pom.xml把驱动包引入即可。
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>添加完mysql的驱动包以后,再次运行App,就可以打印出结果:
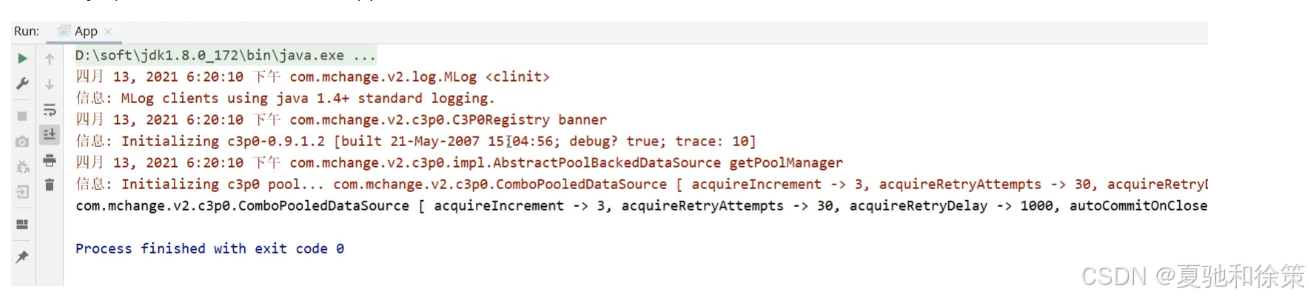
注意:
-
数据连接池在配置属性的时候,除了可以注入数据库连接四要素外还可以配置很多其他的属性,具体都有哪些属性用到的时候再去查,一般配置基础的四个,其他都有自己的默认值
-
Druid和C3P0在没有导入mysql驱动包的前提下,一个没报错一个报错,说明Druid在初始化的时候没有去加载驱动,而C3P0刚好相反
-
Druid程序运行虽然没有报错,但是当调用DruidDataSource的getConnection()方法获取连接的时候,也会报找不到驱动类的错误
🧠 理论理解
C3P0是另一款经典的数据库连接池,Spring管理方式与Druid一样,只需指定类名并用 <property> 注入属性即可。通过Spring容器管理,C3P0能与其他框架(如Hibernate)无缝整合。
🏢 企业实战理解
BAT曾大量使用C3P0与Hibernate集成的经典方案,后续因Druid/ HikariCP性能更优而逐步替换。字节跳动历史项目(如早期头条搜索)曾用C3P0做连接池,通过Spring管理实现“多数据源切换”。Google的部分企业Java组件也支持通过Spring注入管理类似C3P0的数据源。
题目4:C3P0与Druid相比在性能和功能上有哪些差异?在什么场景下会优先考虑C3P0?
参考答案:
C3P0特点:
-
历史悠久,兼容性极强,早期Hibernate推荐连接池;
-
提供自动重连、连接超时检测等功能;
-
配置简单,成熟稳定。
性能对比:
-
C3P0性能弱于Druid,尤其在高并发环境下,获取连接延迟明显;
-
Druid在监控、连接池回收、SQL执行优化上远超C3P0。
应用场景:
-
若系统依赖老旧版本的Hibernate或JPA框架,且并发压力不大,C3P0是兼容性优选;
-
对性能有极高要求的生产环境,应优先Druid/HikariCP。
字节跳动实战中,C3P0主要出现在老旧系统维护场景,BAT在Java中台逐步淘汰C3P0。Google/NVIDIA会更看重HikariCP等高性能方案。
场景题4:
你在腾讯视频项目中维护一套历史系统,仍在使用C3P0作为数据源。有一天监控报警发现C3P0的连接池不断堆积,导致系统响应缓慢。你已确认SQL执行正常,但连接未释放。请描述如何利用Spring的IOC管理机制+日志工具快速定位问题。
参考思路:
-
确认Spring
transactionManager配置是否正确(如声明式事务是否生效); -
检查是否有手动获取Connection但未关闭的代码(特别是Service层中);
-
配置
ComboPooledDataSource的debugUnreturnedConnectionStackTraces=true,并设置unreturnedConnectionTimeout,定位泄露堆栈; -
利用Spring AOP结合日志切面记录每次获取和释放连接的行为。
字节跳动在遇到类似问题时,都会强制推行“连接自动关闭检测”方案,并定期扫描未关闭连接的热点代码段。
1.2 加载properties文件
上节中我们已经完成两个数据源druid和C3P0的配置,但是其中包含了一些问题,我们来分析下:
-
这两个数据源中都使用到了一些固定的常量如数据库连接四要素,把这些值写在Spring的配置文件中不利于后期维护
-
需要将这些值提取到一个外部的properties配置文件中
-
Spring框架如何从配置文件中读取属性值来配置就是接下来要解决的问题。
问题提出来后,具体该如何实现?
🧠 理论理解
Spring支持将外部 .properties 文件中的配置注入到bean中,这实现了配置与代码分离。使用 <context:property-placeholder> 标签加载文件,并通过${key}语法将值注入到bean中,从而方便切换环境参数、提高维护性。
🏢 企业实战理解
阿里巴巴内部服务大多结合Apollo/Nacos等配置中心实现集中管理,但本质上也是Spring最初的 property-placeholder 机制的增强版。字节跳动的云环境中,所有 .properties 配置托管在Kubernetes ConfigMap/Secret中,服务启动时动态注入。Google与NVIDIA使用自研配置系统,但类似注入机制依然基于相同的“外部配置-内部注入”理念。
题目5:<context:property-placeholder> 的原理是什么?Spring是如何解析 ${} 占位符的?
参考答案:
<context:property-placeholder> 本质上是由 PropertyPlaceholderConfigurer 实现的。它的核心工作原理:
-
在Spring容器初始化时,加载
.properties文件,解析出key-value对; -
遍历IOC容器中所有
BeanDefinition,寻找有${}占位符的属性; -
替换
${}占位符为对应值。
它是在 postProcessBeanFactory 阶段执行的(实现了 BeanFactoryPostProcessor 接口)。
阿里巴巴和字节跳动常追问:
-
多个
property-placeholder如何解析优先级? -
如何应对系统变量和
.properties文件冲突?(system-properties-mode控制优先级)
Google/NVIDIA偏好深入考察:Spring的 Environment 与 PropertySource 机制如何和这个功能关联。
1.2.1 第三方bean属性优化
1.2.1.1 实现思路
需求:将数据库连接四要素提取到properties配置文件,spring来加载配置信息并使用这些信息来完成属性注入。
1.在resources下创建一个jdbc.properties(文件的名称可以任意)
2.将数据库连接四要素配置到配置文件中
3.在Spring的配置文件中加载properties文件
4.使用加载到的值实现属性注入
其中第3,4步骤是需要大家重点关注,具体是如何实现。
场景题5:
你负责的阿里云WAF系统支持多租户环境。每个租户的配置参数(如限流阈值)需要动态读取。项目初期通过Spring的 <context:property-placeholder> 从 config.properties 加载参数,但上线后发现租户配置变更需要重启应用才能生效。请问如何基于Spring改进方案实现动态加载配置?
参考思路:
-
方案1️⃣:集成Spring Cloud Config或Nacos,将配置托管到远程配置中心;
-
方案2️⃣:结合Spring的
EnvironmentChangeEvent实现配置刷新通知; -
方案3️⃣:实现自定义
PropertySource,结合定时任务或监听机制周期性刷新配置内容。
美团和字节跳动大促期间经常遇到类似问题,都演进为中心化配置+实时生效机制。
1.2.1.2 实现步骤
步骤1:准备properties配置文件
resources下创建一个jdbc.properties文件,并添加对应的属性键值对
jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://127.0.0.1:3306/spring_db jdbc.username=root jdbc.password=root
步骤2:开启context命名空间
在applicationContext.xml中开context命名空间
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
</beans>步骤3:加载properties配置文件
在配置文件中使用context命名空间下的标签来加载properties配置文件
<context:property-placeholder location="jdbc.properties"/>
步骤4:完成属性注入
使用${key}来读取properties配置文件中的内容并完成属性注入
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:property-placeholder location="jdbc.properties"/>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
</beans>至此,读取外部properties配置文件中的内容就已经完成。
🧠 理论理解
将bean的硬编码属性提取到 .properties 文件,有助于实现环境隔离(如开发、测试、生产)。Spring的 property-placeholder 机制可以灵活切换数据库、Redis、MQ等外部依赖配置,无需修改代码。
🏢 企业实战理解
阿里云SLB服务中,数据库连接配置通过 .properties 文件读取,后续接入配置中心实现动态刷新。字节跳动云游戏服务,最早数据库URL就是通过Spring property-placeholder 管理的。NVIDIA自研的AI服务平台,采用类似机制实现不同GPU集群的资源分配配置切换。
题目6:什么是“配置与代码解耦”?Spring加载外部配置文件有哪些典型用途?
参考答案:
“配置与代码解耦”是指业务逻辑与环境参数分离,配置文件(如 .properties)保存数据库地址、缓存设置、第三方服务密钥等,代码只通过${}占位符注入值,便于维护和切换环境。
典型用途:
-
多环境切换(开发、测试、生产);
-
热更新(如数据库密码变更无需重启);
-
动态参数(如线程池上限、限流阈值)。
阿里巴巴面试时常问:如何解决 .properties 参数动态刷新问题(答:结合Nacos/Apollo动态刷新Bean属性)。字节跳动会补问:如何保护敏感参数(答:加密/密钥管理中心结合Spring注入)。
场景题6:
你在字节跳动负责一个音视频处理系统,集成了多个第三方库(如FFmpeg、Redis客户端)。目前Spring配置中硬编码了这些组件的路径和账号信息,导致环境切换繁琐。领导要求你把所有第三方bean配置迁移到 .properties 文件中,并支持多环境(开发、测试、生产)切换,如何实现?
参考思路:
-
创建
dev.properties、test.properties、prod.properties文件管理环境参数; -
在
applicationContext.xml中用<context:property-placeholder>加载对应文件; -
配置
spring.profiles.active动态切换激活的环境; -
推荐升级为Spring Boot结构,用
application-{profile}.properties标准管理。
阿里云、腾讯云大规模生产系统也采用这种多环境profile隔离机制,结合CI/CD自动化切换环境。
1.2.2 读取单个属性
1.2.2.1 实现思路
对于上面的案例,效果不是很明显,我们可以换个案例来演示下:
需求:从properties配置文件中读取key为name的值,并将其注入到BookDao中并在save方法中进行打印。
1.在项目中添加BookDao和BookDaoImpl类
2.为BookDaoImpl添加一个name属性并提供setter方法
3.在jdbc.properties中添加数据注入到bookDao中打印方便查询结果
4.在applicationContext.xml添加配置完成配置文件加载、属性注入(${key})
🧠 理论理解
不仅是数据源等大型bean,普通属性(如字符串、端口号等)也能通过${key}注入到自定义bean中。Spring在启动时会自动解析占位符,确保注入的值符合bean定义。
🏢 企业实战理解
字节跳动很多项目(如短视频转码)通过Spring注入单个属性控制不同“任务类型”,比如transcode.profile=high. 阿里巴巴的日志组件曾用单个属性注入方式控制日志级别,无需重启。Google Cloud的Java SDK也采用类似机制读取密钥或endpoint,保证云服务的灵活配置。
场景题7:
你在Google Cloud的一个Java微服务项目中,发现业务逻辑中有个 BookDao 类需要动态读取日志级别配置(如debug/info/error),每次变更日志级别都要重启应用才能生效,影响大。请问如何利用Spring读取外部配置实现不重启应用动态调整?
参考思路:
-
将日志级别配置放到
log.properties文件中,使用${}注入到BookDao; -
集成Spring Cloud Config或自定义
@Scheduled任务周期刷新属性值; -
或者将日志系统(如Logback)配置为支持
scan="true"动态重载外部配置文件。
字节跳动在类似场景中会结合 Apollo 实现“秒级刷新”日志级别变更;OpenAI偏好无侵入式动态配置更新机制。
1.2.2.2 实现步骤
步骤1:在项目中添对应的类
BookDao和BookDaoImpl类,并在BookDaoImpl类中添加name属性与setter方法
public interface BookDao {
public void save();
}
public class BookDaoImpl implements BookDao {
private String name;
public void setName(String name) {
this.name = name;
}
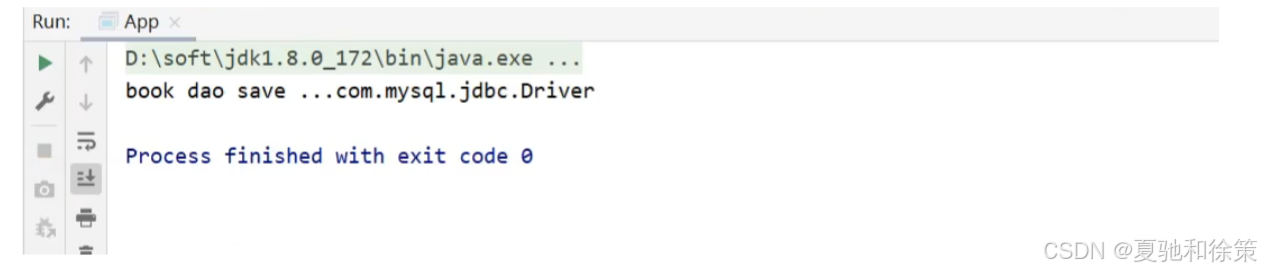
public void save() {
System.out.println("book dao save ..." + name);
}
}步骤2:完成配置文件的读取与注入
在applicationContext.xml添加配置,bean的配置管理、读取外部properties、依赖注入:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:property-placeholder location="jdbc.properties"/>
<bean id="bookDao" class="com.itheima.dao.impl.BookDaoImpl">
<property name="name" value="${jdbc.driver}"/>
</bean>
</beans>步骤3:运行程序
在App类中,从IOC容器中获取bookDao对象,调用方法,查看值是否已经被获取到并打印控制台
public class App {
public static void main(String[] args) throws Exception{
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
BookDao bookDao = (BookDao) ctx.getBean("bookDao");
bookDao.save();
}
} 
1.2.2.3 注意事项
至此,读取properties配置文件中的内容就已经完成,但是在使用的时候,有些注意事项:
-
问题一:键值对的key为
username引发的问题1.在properties中配置键值对的时候,如果key设置为
usernameusername=root666
2.在applicationContext.xml注入该属性
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <context:property-placeholder location="jdbc.properties"/> <bean id="bookDao" class="com.itheima.dao.impl.BookDaoImpl"> <property name="name" value="${username}"/> </bean> </beans>3.运行后,在控制台打印的却不是
root666,而是自己电脑的用户名
4.出现问题的原因是
<context:property-placeholder/>标签会加载系统的环境变量,而且环境变量的值会被优先加载,如何查看系统的环境变量?public static void main(String[] args) throws Exception{ Map<String, String> env = System.getenv(); System.out.println(env); }大家可以自行运行,在打印出来的结果中会有一个USERNAME=XXX[自己电脑的用户名称]
5.解决方案
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <context:property-placeholder location="jdbc.properties" system-properties-mode="NEVER"/> </beans>system-properties-mode:设置为NEVER,表示不加载系统属性,就可以解决上述问题。
当然还有一个解决方案就是避免使用
username作为属性的key。 -
问题二:当有多个properties配置文件需要被加载,该如何配置?
1.调整下配置文件的内容,在resources下添加
jdbc.properties,jdbc2.properties,内容如下:jdbc.properties
jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://127.0.0.1:3306/spring_db jdbc.username=root jdbc.password=rootjdbc2.properties
username=root6662.修改applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <!--方式一 --> <context:property-placeholder location="jdbc.properties,jdbc2.properties" system-properties-mode="NEVER"/> <!--方式二--> <context:property-placeholder location="*.properties" system-properties-mode="NEVER"/> <!--方式三 --> <context:property-placeholder location="classpath:*.properties" system-properties-mode="NEVER"/> <!--方式四--> <context:property-placeholder location="classpath*:*.properties" system-properties-mode="NEVER"/> </beans>说明:
-
方式一:可以实现,如果配置文件多的话,每个都需要配置
-
方式二:
*.properties代表所有以properties结尾的文件都会被加载,可以解决方式一的问题,但是不标准 -
方式三:标准的写法,
classpath:代表的是从根路径下开始查找,但是只能查询当前项目的根路径 -
方式四:不仅可以加载当前项目还可以加载当前项目所依赖的所有项目的根路径下的properties配置文件
-
题目7:Spring支持哪些类型的属性注入方式?单个属性注入时如何保证数据类型安全?
参考答案:
Spring支持以下几种属性注入方式:
-
Setter注入
-
构造器注入
-
p命名空间注入
-
SpEL(Spring Expression Language)注入
-
注解注入(
@Value)
单个属性注入时,Spring会自动类型转换,比如将 .properties 文件中的字符串 "1000" 转换为Integer类型,利用 PropertyEditor 或 ConversionService 实现。为了安全,建议显式声明数据类型或自定义 PropertyEditorRegistrar 处理复杂类型。
阿里面试会考:注入List/Map/复杂对象时的处理细节。字节跳动会问:SpEL注入时如何结合环境变量+系统变量做到灵活注入。
1.2.3 加载properties文件小结
本节主要讲解的是properties配置文件的加载,需要掌握的内容有:
-
如何开启
context命名空间
-
如何加载properties配置文件
<context:property-placeholder location="" system-properties-mode="NEVER"/> -
如何在applicationContext.xml引入properties配置文件中的值
${key}
🧠 理论理解
Spring通过 <context:property-placeholder> 提供了一个稳定、简洁的配置加载机制,支持:
-
多文件加载
-
通配符加载
-
系统环境变量优先级设置(如
system-properties-mode="NEVER")
这让配置灵活性大幅提升,满足企业级复杂场景。
🏢 企业实战理解
阿里、字节等大厂已将Spring配置机制升级到热更新/灰度发布级别,很多场景还是基于这套机制做深度封装。Google/NVIDIA云环境中,也通过Kubernetes的环境变量结合类似机制实现高效的“云原生注入”方案。
题目8:Spring中<context:property-placeholder> 与 @PropertySource 有什么区别?分别适合什么场景?
参考答案:
区别:
-
<context:property-placeholder>:基于XML的配置方式,适用于传统XML项目。 -
@PropertySource:基于注解,结合@Configuration使用,更适合Spring Boot / 注解驱动模式。
两者实现机制相似,但 @PropertySource 可与 @Value 注解无缝集成。
适用场景:
-
大型企业Java老项目(如BAT的中台服务)多用XML配置,推荐
<context:property-placeholder>。 -
新项目(尤其是Spring Boot生态,如字节/美团微服务)使用
@PropertySource+@Value注解注入属性。
Google/NVIDIA偏向无侵入的注解方式,更适配现代云原生开发。
场景题8:
你在英伟达GPU云租赁项目中,负责管理多个 properties 文件(如 gpu.properties、storage.properties、security.properties)。当前使用 <context:property-placeholder> 加载这些配置文件,但新需求要求支持“模块化加载”和“通配符方式自动加载所有配置文件”。请问如何改进现有配置,兼顾模块化和易维护?
参考思路:
-
方法1️⃣:
<context:property-placeholder location="classpath:gpu.properties,classpath:storage.properties,classpath:security.properties"/>; -
方法2️⃣:用通配符加载所有配置文件:
<context:property-placeholder location="classpath:*.properties"/>; -
方法3️⃣(推荐):结合Spring Boot,将所有配置集中到
application.yml,通过命名空间分模块管理。
字节跳动的分布式系统常用“模块化+通配符”机制,阿里巴巴的中间件也要求分模块管理,避免单个配置文件过大导致出错。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











