








3,统一异常处理
3.1 问题描述
在讲解这一部分知识点之前,我们先来演示个效果,修改BookController类的getById方法
@GetMapping("/{id}")
public Result getById(@PathVariable Integer id) {
//手动添加一个错误信息
if(id==1){
int i = 1/0;
}
Book book = bookService.getById(id);
Integer code = book != null ? Code.GET_OK : Code.GET_ERR;
String msg = book != null ? "" : "数据查询失败,请重试!";
return new Result(code,book,msg);
}重新启动运行项目,使用PostMan发送请求,当传入的id为1,则会出现如下效果: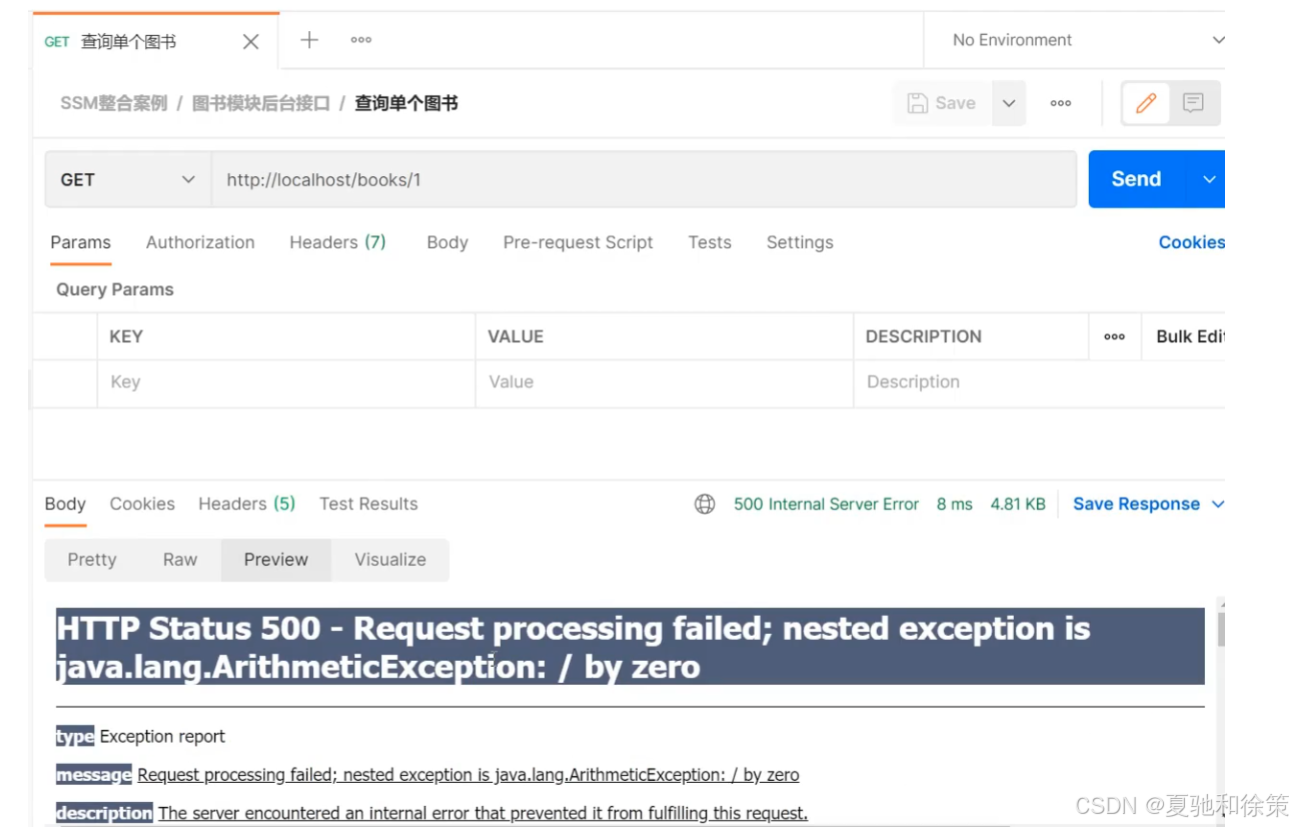
前端接收到这个信息后和之前我们约定的格式不一致,这个问题该如何解决?
在解决问题之前,我们先来看下异常的种类及出现异常的原因:
-
框架内部抛出的异常:因使用不合规导致
-
数据层抛出的异常:因外部服务器故障导致(例如:服务器访问超时)
-
业务层抛出的异常:因业务逻辑书写错误导致(例如:遍历业务书写操作,导致索引异常等)
-
表现层抛出的异常:因数据收集、校验等规则导致(例如:不匹配的数据类型间导致异常)
-
工具类抛出的异常:因工具类书写不严谨不够健壮导致(例如:必要释放的连接长期未释放等)
看完上面这些出现异常的位置,你会发现,在我们开发的任何一个位置都有可能出现异常,而且这些异常是不能避免的。所以我们就得将异常进行处理。
思考
-
各个层级均出现异常,异常处理代码书写在哪一层?
==所有的异常均抛出到表现层进行处理==
-
异常的种类很多,表现层如何将所有的异常都处理到呢?
==异常分类==
-
表现层处理异常,每个方法中单独书写,代码书写量巨大且意义不强,如何解决?
==AOP==
对于上面这些问题及解决方案,SpringMVC已经为我们提供了一套解决方案:
-
异常处理器:
-
集中的、统一的处理项目中出现的异常。

-
🧠 理论理解
在未统一异常处理前,前端接收到的错误响应往往是:
-
不同接口返回不同格式的错误信息
-
部分接口返回原始堆栈(不安全)
-
部分接口干脆直接断掉(HTTP 500)
这不仅让前端开发难以维护,还会暴露后台系统细节,存在安全隐患。
所以,统一异常处理的目标是:
✅ 不管后台出什么错,都用统一格式包裹(比如统一的 Result 类)
✅ 前端只需看 code 和 msg,不用关心后端出错细节
✅ 后端日志、报警、通知等也能根据异常分类更好处理
🏢 企业实战理解
-
阿里巴巴:整个蚂蚁金服、淘宝等业务线,都通过全局异常拦截器统一兜底,把异常按系统异常、业务异常分级,并引入监控系统(如 SLS 日志、Prometheus)实时监控。
-
字节跳动:字节内部微服务通过统一的「字节内部网关」处理异常,网关统一拦截所有请求的异常,前端只接收结构化的 JSON(含 code、message、trace_id)。
-
Google:GCP 云服务 API 设计中,所有错误响应严格符合 Google Cloud API 错误标准(标准 JSON,带 error code、message、status)。
-
NVIDIA:NVIDIA 的深度学习云平台(NGC)采用 gRPC 接口,所有异常必须被转换为定义好的 gRPC StatusCode。
-
OpenAI:ChatGPT API 服务统一使用 HTTP 200 + JSON 错误结构,即使失败也是 200,error 字段包含详细信息,方便客户端自动化处理。
❓ 面试题 1:
为什么前后端项目需要统一异常处理?如果不统一,前端会遇到什么问题?
✅ 答案:
前后端项目需要统一异常处理,是因为后端的错误来源复杂,包括系统异常(如网络超时、数据库崩溃)、业务异常(如手机号已注册)以及未知异常。如果不统一,前端会面临这些问题:
-
不同接口返回不同格式,前端需要逐个特殊处理,增加解析复杂度。
-
有些错误直接返回 HTTP 500,前端拿不到有用信息。
-
部分接口可能暴露堆栈信息或系统细节,存在安全隐患。
统一异常处理后,后端只需按照约定结构(如 code、msg、data)返回,前端根据 code 判定成功或失败,简化开发并提升安全性。
场景题 1:阿里巴巴 · 双11高峰场景
你在阿里负责电商后端订单服务,双11当天系统突发大规模系统异常:
-
Redis 突然宕机,导致大量订单查询接口抛出连接超时异常;
-
前端反馈用户看到的是空白页或直接 HTTP 500 页面,没有友好提示。
请问:
✅ 如何用 SpringMVC 的全局异常处理方案快速修复?
✅ 如何保证这些系统异常未来能被快速感知到,而不是等前端或用户报错才发现?
答案:
首先,双11这种极端高峰,系统异常属于不可完全避免的“灰犀牛”事件。最关键是即使后端报错,前端也能拿到结构化的、可处理的错误信息,而不是 HTTP 500。
解决方案:
-
使用 @RestControllerAdvice 统一捕获 Exception;
-
在 ProjectExceptionAdvice 中,针对连接超时类异常(如 RedisTimeoutException)定制专门的 @ExceptionHandler 方法,返回结构化响应(如 code、msg、data);
-
确保前端根据 code 做兜底提示,比如:“系统繁忙,请稍后再试”,而不是直接暴露堆栈或让页面崩溃。
✅ 如何保证这些系统异常未来能被快速感知到?
-
在 doSystemException() 方法中集成日志系统(如 Logback、ELK),记录异常详细信息;
-
结合阿里内部的监控体系(如鹰眼、CAT),自动上报异常;
-
配置报警(钉钉机器人、PagerDuty 等),确保关键系统异常第一时间推送到值班 SRE 或开发群。
3.2 异常处理器的使用
3.2.1 环境准备
-
创建一个Web的Maven项目
-
pom.xml添加SSM整合所需jar包
-
创建对应的配置类
-
编写Controller、Service接口、Service实现类、Dao接口和模型类
-
resources下提供jdbc.properties配置文件
内容参考前面的项目或者直接使用前面的项目进行本节内容的学习。
最终创建好的项目结构如下:
3.2.2 使用步骤
步骤1:创建异常处理器类
//@RestControllerAdvice用于标识当前类为REST风格对应的异常处理器
@RestControllerAdvice
public class ProjectExceptionAdvice {
//除了自定义的异常处理器,保留对Exception类型的异常处理,用于处理非预期的异常
@ExceptionHandler(Exception.class)
public void doException(Exception ex){
System.out.println("嘿嘿,异常你哪里跑!")
}
}
==确保SpringMvcConfig能够扫描到异常处理器类==
步骤2:让程序抛出异常
修改BookController的getById方法,添加int i = 1/0.
@GetMapping("/{id}")
public Result getById(@PathVariable Integer id) {
int i = 1/0;
Book book = bookService.getById(id);
Integer code = book != null ? Code.GET_OK : Code.GET_ERR;
String msg = book != null ? "" : "数据查询失败,请重试!";
return new Result(code,book,msg);
}步骤3:运行程序,测试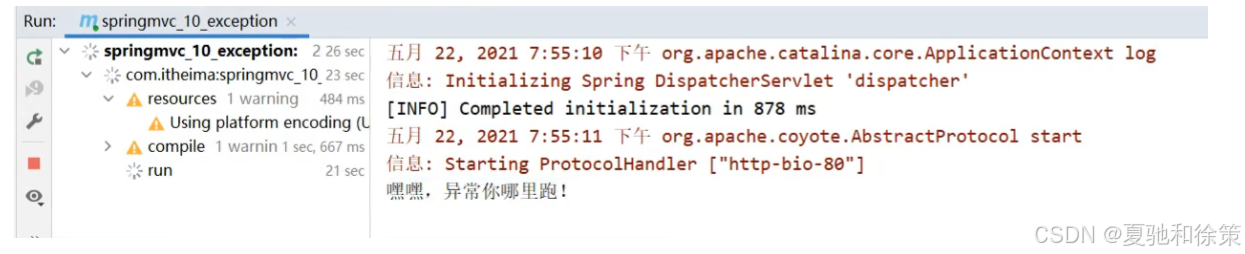
说明异常已经被拦截并执行了doException方法。
异常处理器类返回结果给前端
//@RestControllerAdvice用于标识当前类为REST风格对应的异常处理器
@RestControllerAdvice
public class ProjectExceptionAdvice {
//除了自定义的异常处理器,保留对Exception类型的异常处理,用于处理非预期的异常
@ExceptionHandler(Exception.class)
public Result doException(Exception ex){
System.out.println("嘿嘿,异常你哪里跑!")
return new Result(666,null,"嘿嘿,异常你哪里跑!");
}
}
启动运行程序,测试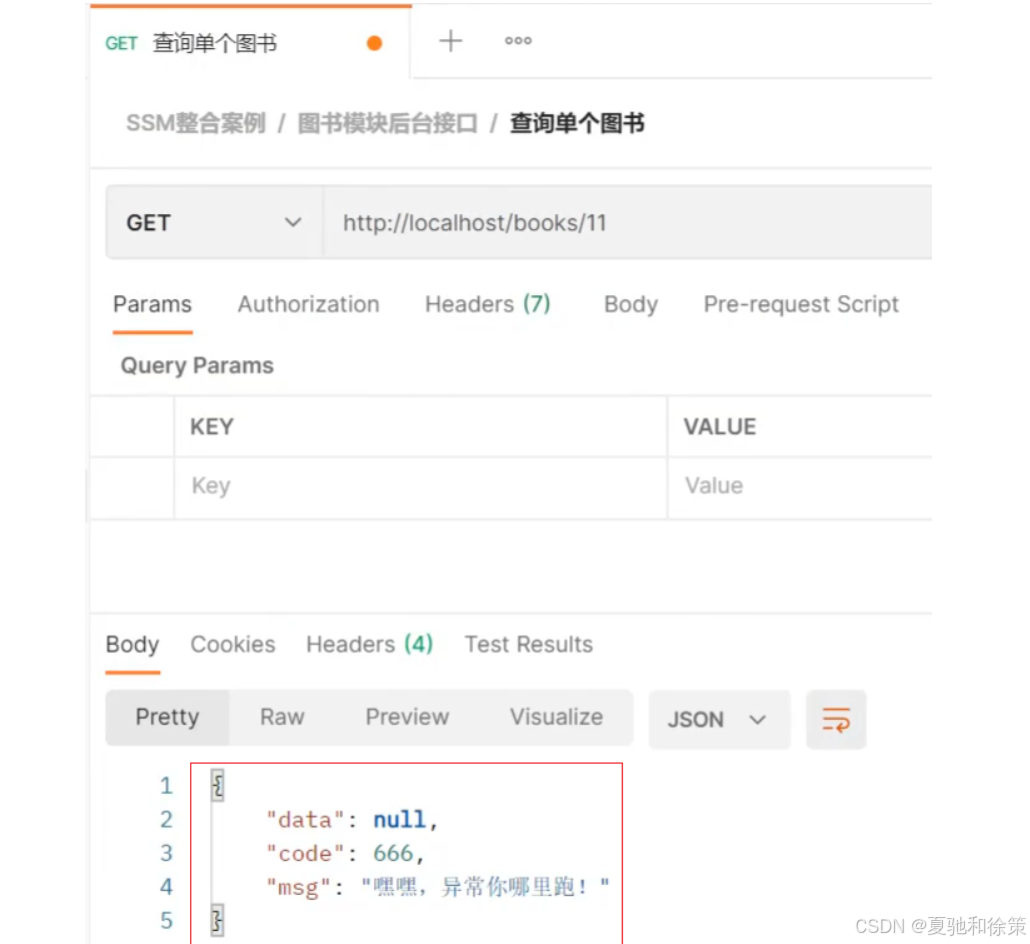
至此,就算后台执行的过程中抛出异常,最终也能按照我们和前端约定好的格式返回给前端。
知识点1:@RestControllerAdvice
| 名称 | @RestControllerAdvice |
|---|---|
| 类型 | ==类注解== |
| 位置 | Rest风格开发的控制器增强类定义上方 |
| 作用 | 为Rest风格开发的控制器类做增强 |
说明:此注解自带@ResponseBody注解与@Component注解,具备对应的功能
知识点2:@ExceptionHandler
| 名称 | @ExceptionHandler |
|---|---|
| 类型 | ==方法注解== |
| 位置 | 专用于异常处理的控制器方法上方 |
| 作用 | 设置指定异常的处理方案,功能等同于控制器方法, 出现异常后终止原始控制器执行,并转入当前方法执行 |
说明:此类方法可以根据处理的异常不同,制作多个方法分别处理对应的异常
🧠 理论理解
SpringMVC 提供:
-
@RestControllerAdvice:声明全局控制器增强类(带@ResponseBody)。 -
@ExceptionHandler:声明具体处理某类异常的方法。
这意味着:
✅ 我们可以全局捕获异常而不是在每个 Controller 写 try-catch。
✅ 可以对不同类型异常分类处理。
✅ 可以集中做日志记录、报警、邮件通知。
🏢 企业实战理解
-
阿里:除了统一异常响应,还会在异常处理器里打点日志,接入链路追踪(如 SkyWalking、EagleEye)。
-
字节:异常处理器中直接上报异常堆栈到字节自研的日志系统,用于分布式链路分析。
-
Google:内部 API 框架集成 Error Reporting,捕获到的异常直接汇入 Google Cloud Console。
-
NVIDIA:处理 gRPC 异常时,内部框架会自动转为标准 gRPC status,开发者不用手写 handler。
-
OpenAI:后端统一用 FastAPI 处理 HTTP 异常,开发者只需在中间件层定义好全局异常处理即可。
❓ 面试题 2:
SpringMVC 中用哪个注解实现全局异常处理?它的核心作用是什么?
✅ 答案:
用 @RestControllerAdvice 注解实现全局异常处理。它的核心作用有:
-
标记当前类为 REST 风格控制器的增强器,具备异常处理功能。
-
自动扫描所有控制器方法,捕获其中抛出的异常。
-
配合
@ExceptionHandler,可以对不同异常类型进行分类处理。
这让我们不需要在每个 Controller 里手动写 try-catch,而是集中管理异常、统一返回响应格式。
❓ 面试题 3:
@ExceptionHandler 和 @RestControllerAdvice 有什么区别和关系?
✅ 答案:
@RestControllerAdvice 是类级别注解,用来标识全局增强器(同时带有 @Component 和 @ResponseBody)。
@ExceptionHandler 是方法级别注解,用来标记当前方法专门处理哪类异常。
它们的关系是:@ExceptionHandler 必须写在 @RestControllerAdvice(或 @ControllerAdvice)类中才能生效,用于指定具体异常的处理方案。
场景题 2:字节跳动 · 抖音短视频业务场景
你在字节跳动的抖音后端团队工作,发现后台日志里经常出现「分布式 ID 生成服务调用超时」的错误,偶尔还会伴随「业务参数校验失败」的报错。
目前后端直接把这些异常原样传给前端,结果前端展示出来的是 Java 异常堆栈,用户体验非常差。
请问:
✅ 你如何用自定义异常(SystemException 和 BusinessException)对这些错误进行分级封装?
✅ 在全局异常处理器中,你会如何设计返回结构,让前端既能区分是系统问题还是业务问题,又避免暴露后端实现细节?
✅ 如何用自定义异常对这些错误进行分级封装?
-
参数校验失败:封装为 BusinessException,code 可以用 400 开头(客户端可修正类错误);
-
分布式 ID 服务超时:封装为 SystemException,code 用 500 开头(后端系统异常)。
✅ 全局异常处理器如何设计返回结构?
-
返回统一 Result 对象,结构如:
{
"code": 40001,
"msg": "参数校验失败:id不能为空",
"data": null
}
或
{
"code": 50002,
"msg": "系统异常:分布式 ID 服务超时",
"data": null
}
这样前端只需要判断 code 属于哪段范围(4xx 还是 5xx),就能区分是用户问题还是系统问题;
同时 msg 只给出必要信息,避免直接暴露 Java 异常堆栈。
3.3 项目异常处理方案
3.3.1 异常分类
异常处理器我们已经能够使用了,那么在咱们的项目中该如何来处理异常呢?
因为异常的种类有很多,如果每一个异常都对应一个@ExceptionHandler,那得写多少个方法来处理各自的异常,所以我们在处理异常之前,需要对异常进行一个分类:
-
业务异常(BusinessException)
-
规范的用户行为产生的异常
-
用户在页面输入内容的时候未按照指定格式进行数据填写,如在年龄框输入的是字符串
-
-
不规范的用户行为操作产生的异常
-
如用户故意传递错误数据

-
-
-
系统异常(SystemException)
-
项目运行过程中可预计但无法避免的异常
-
比如数据库或服务器宕机
-
-
-
其他异常(Exception)
-
编程人员未预期到的异常,如:用到的文件不存在

-
将异常分类以后,针对不同类型的异常,要提供具体的解决方案:
🧠 理论理解
常见分类:
✅ 系统异常(如服务器宕机、数据库断开、网络超时)
✅ 业务异常(如手机号已注册、余额不足)
✅ 未知异常(兜底类:所有没被明确捕获的)
分类的好处:
-
不同的异常可以有不同的响应码。
-
系统异常通常需要记录日志、报警,而业务异常只需返回友好提示。
🏢 企业实战理解
-
阿里:异常按 P0(系统挂了)、P1(业务关键异常)、P2(非核心业务异常)分级,P0 会直接报警。
-
字节:所有异常分为系统级、业务级、网络级,自动打标签进入监控平台。
-
Google:云服务 API 错误分为
4xx(客户端错误)、5xx(服务器错误),不同等级异常直接映射 HTTP 状态。 -
NVIDIA:AI 推理任务出错分为
ResourceExhausted(显存不够)、DeadlineExceeded(超时)等类别。 -
OpenAI:API 错误结构里,error code 细分为
rate_limit_exceeded、invalid_request_error、server_error。
❓ 面试题 4:
在项目中,为什么要将异常分为系统异常和业务异常?如何划分它们?
✅ 答案:
划分的原因:
-
系统异常指的是因基础设施或系统性问题导致的错误(如网络断开、数据库连接失败、服务器宕机),它通常需要被记录日志、报警、可能需要重试或运维介入。
-
业务异常是指因业务逻辑触发的错误(如库存不足、用户未登录、权限不足),它通常只需要告诉前端具体的提示信息,不需要系统层的干预。
划分的意义在于: -
可以给不同异常定义不同的 code 和 message。
-
系统异常可带 trace_id 等调试信息,而业务异常直接提示给用户。
-
在全局异常处理器里,分类处理更高效。
3.3.2 异常解决方案
-
业务异常(BusinessException)
-
发送对应消息传递给用户,提醒规范操作
-
大家常见的就是提示用户名已存在或密码格式不正确等
-
-
-
系统异常(SystemException)
-
发送固定消息传递给用户,安抚用户
-
系统繁忙,请稍后再试
-
系统正在维护升级,请稍后再试
-
系统出问题,请联系系统管理员等
-
-
发送特定消息给运维人员,提醒维护
-
可以发送短信、邮箱或者是公司内部通信软件
-
-
记录日志
-
发消息和记录日志对用户来说是不可见的,属于后台程序
-
-
-
其他异常(Exception)
-
发送固定消息传递给用户,安抚用户
-
发送特定消息给编程人员,提醒维护(纳入预期范围内)
-
一般是程序没有考虑全,比如未做非空校验等
-
-
记录日志
-
🧠 理论理解
核心步骤:
✅ 编写自定义异常类(带 code + message)
✅ 在业务层捕获系统异常,包装成自定义异常
✅ 在全局异常处理器中分门别类地处理这些异常
✅ 对系统异常做好日志、报警;对业务异常直接响应给前端。
🏢 企业实战理解
-
阿里:自定义异常体系有专门的
BaseException,子类分模块(支付、商品、用户中心),方便定位。 -
字节:开发者只需抛出自定义异常,网关层自动映射为标准响应,不需要每个微服务手动处理。
-
Google:使用 protobuf 定义 Error 类型,不同服务复用同一错误模型。
-
NVIDIA:在 AI 推理平台,模型崩溃的错误会统一包装成
InferenceException,方便监控。 -
OpenAI:即使是 Python FastAPI 项目,也会定义一套标准
OpenAIAPIError,专门用于包装异常。
❓ 面试题 5:
如何设计自定义异常类?请列举其中包含的核心字段和功能。
✅ 答案:
设计自定义异常类(如 SystemException、BusinessException)时,核心字段包括:
-
Integer code:状态码,用于区分异常类型(如 50001 系统超时、60002 业务错误)。 -
String message:异常描述,向前端或日志输出。 -
Throwable cause:异常链,用于记录底层抛出的原始异常(方便调试)。
核心功能: -
继承 RuntimeException,避免强制使用 try-catch。
-
提供多种构造函数(支持只传 code/message 或带 cause)。
-
在业务代码中主动抛出,或者在捕获系统异常后包装抛出。
3.3.3 异常解决方案的具体实现
思路:
1.先通过自定义异常,完成BusinessException和SystemException的定义
2.将其他异常包装成自定义异常类型
3.在异常处理器类中对不同的异常进行处理
步骤1:自定义异常类
//自定义异常处理器,用于封装异常信息,对异常进行分类
public class SystemException extends RuntimeException{
private Integer code;
public Integer getCode() {
return code;
}
public void setCode(Integer code) {
this.code = code;
}
public SystemException(Integer code, String message) {
super(message);
this.code = code;
}
public SystemException(Integer code, String message, Throwable cause) {
super(message, cause);
this.code = code;
}
}
//自定义异常处理器,用于封装异常信息,对异常进行分类
public class BusinessException extends RuntimeException{
private Integer code;
public Integer getCode() {
return code;
}
public void setCode(Integer code) {
this.code = code;
}
public BusinessException(Integer code, String message) {
super(message);
this.code = code;
}
public BusinessException(Integer code, String message, Throwable cause) {
super(message, cause);
this.code = code;
}
}
说明:
-
让自定义异常类继承
RuntimeException的好处是,后期在抛出这两个异常的时候,就不用在try...catch...或throws了 -
自定义异常类中添加
code属性的原因是为了更好的区分异常是来自哪个业务的
步骤2:将其他异常包成自定义异常
假如在BookServiceImpl的getById方法抛异常了,该如何来包装呢?
public Book getById(Integer id) {
//模拟业务异常,包装成自定义异常
if(id == 1){
throw new BusinessException(Code.BUSINESS_ERR,"请不要使用你的技术挑战我的耐性!");
}
//模拟系统异常,将可能出现的异常进行包装,转换成自定义异常
try{
int i = 1/0;
}catch (Exception e){
throw new SystemException(Code.SYSTEM_TIMEOUT_ERR,"服务器访问超时,请重试!",e);
}
return bookDao.getById(id);
}具体的包装方式有:
-
方式一:
try{}catch(){}在catch中重新throw我们自定义异常即可。 -
方式二:直接throw自定义异常即可
上面为了使code看着更专业些,我们在Code类中再新增需要的属性
//状态码
public class Code {
public static final Integer SAVE_OK = 20011;
public static final Integer DELETE_OK = 20021;
public static final Integer UPDATE_OK = 20031;
public static final Integer GET_OK = 20041;
public static final Integer SAVE_ERR = 20010;
public static final Integer DELETE_ERR = 20020;
public static final Integer UPDATE_ERR = 20030;
public static final Integer GET_ERR = 20040;
public static final Integer SYSTEM_ERR = 50001;
public static final Integer SYSTEM_TIMEOUT_ERR = 50002;
public static final Integer SYSTEM_UNKNOW_ERR = 59999;
public static final Integer BUSINESS_ERR = 60002;
}
步骤3:处理器类中处理自定义异常
//@RestControllerAdvice用于标识当前类为REST风格对应的异常处理器
@RestControllerAdvice
public class ProjectExceptionAdvice {
//@ExceptionHandler用于设置当前处理器类对应的异常类型
@ExceptionHandler(SystemException.class)
public Result doSystemException(SystemException ex){
//记录日志
//发送消息给运维
//发送邮件给开发人员,ex对象发送给开发人员
return new Result(ex.getCode(),null,ex.getMessage());
}
@ExceptionHandler(BusinessException.class)
public Result doBusinessException(BusinessException ex){
return new Result(ex.getCode(),null,ex.getMessage());
}
//除了自定义的异常处理器,保留对Exception类型的异常处理,用于处理非预期的异常
@ExceptionHandler(Exception.class)
public Result doOtherException(Exception ex){
//记录日志
//发送消息给运维
//发送邮件给开发人员,ex对象发送给开发人员
return new Result(Code.SYSTEM_UNKNOW_ERR,null,"系统繁忙,请稍后再试!");
}
}步骤4:运行程序
根据ID查询,
如果传入的参数为1,会报BusinessException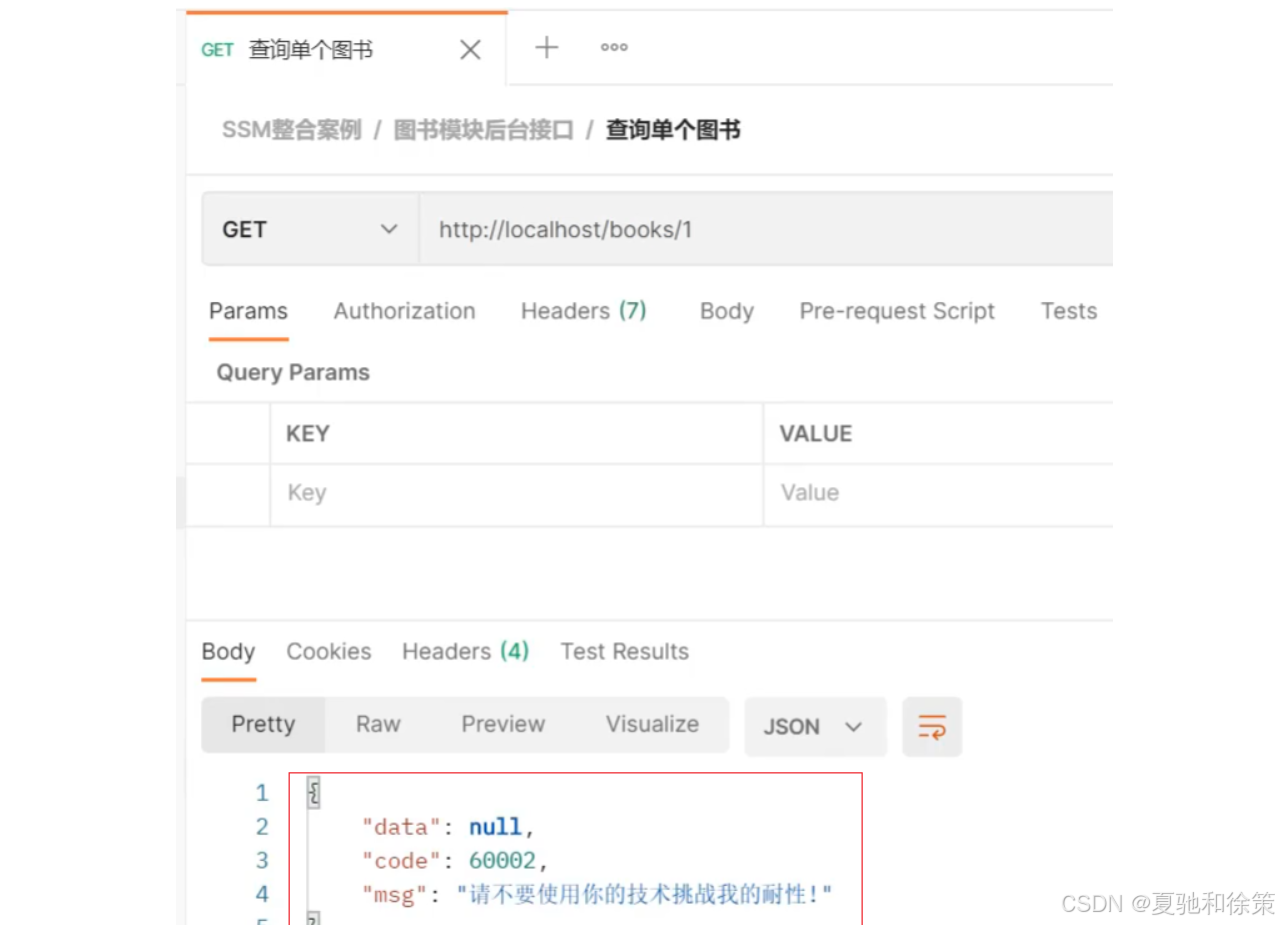
如果传入的是其他参数,会报SystemException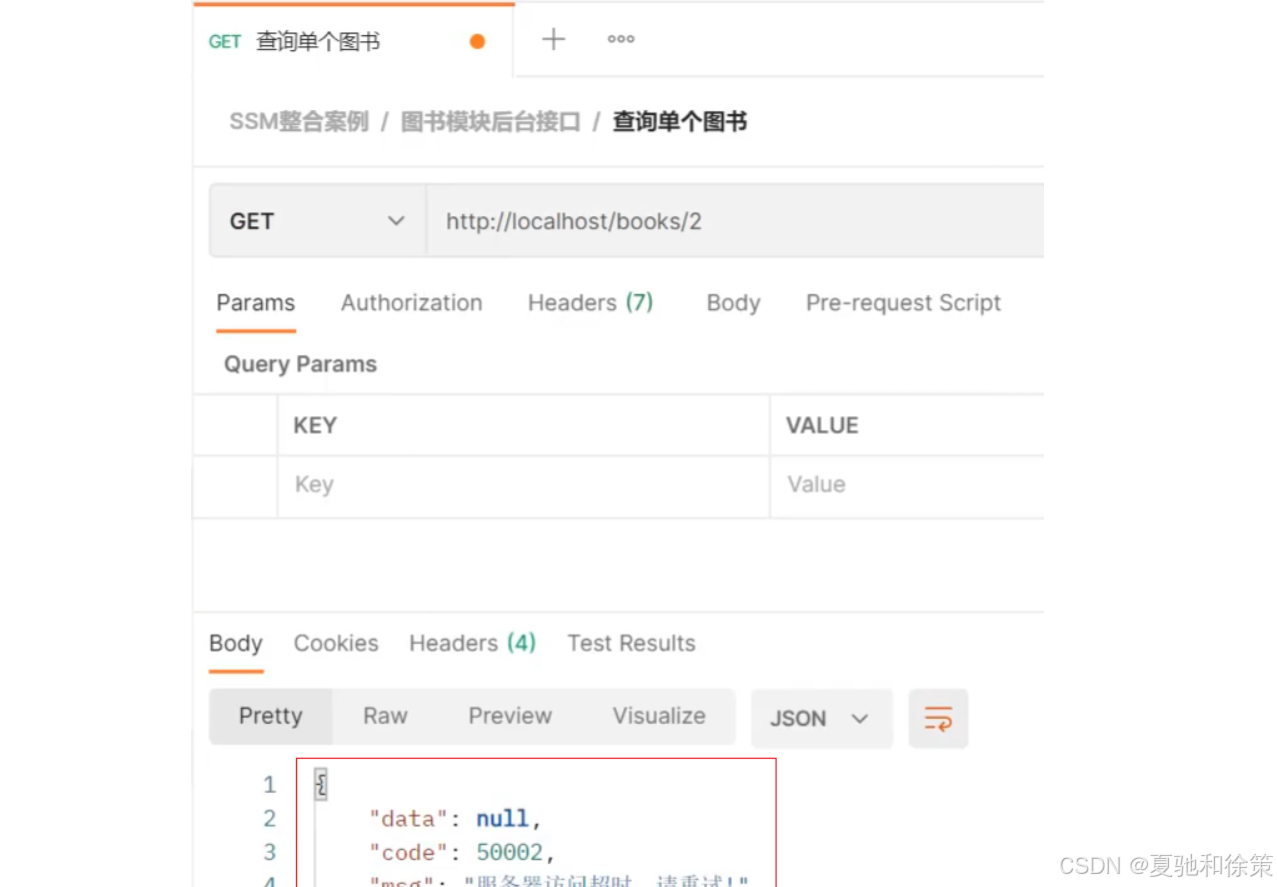
对于异常我们就已经处理完成了,不管后台哪一层抛出异常,都会以我们与前端约定好的方式进行返回,前端只需要把信息获取到,根据返回的正确与否来展示不同的内容即可。
小结
以后项目中的异常处理方式为: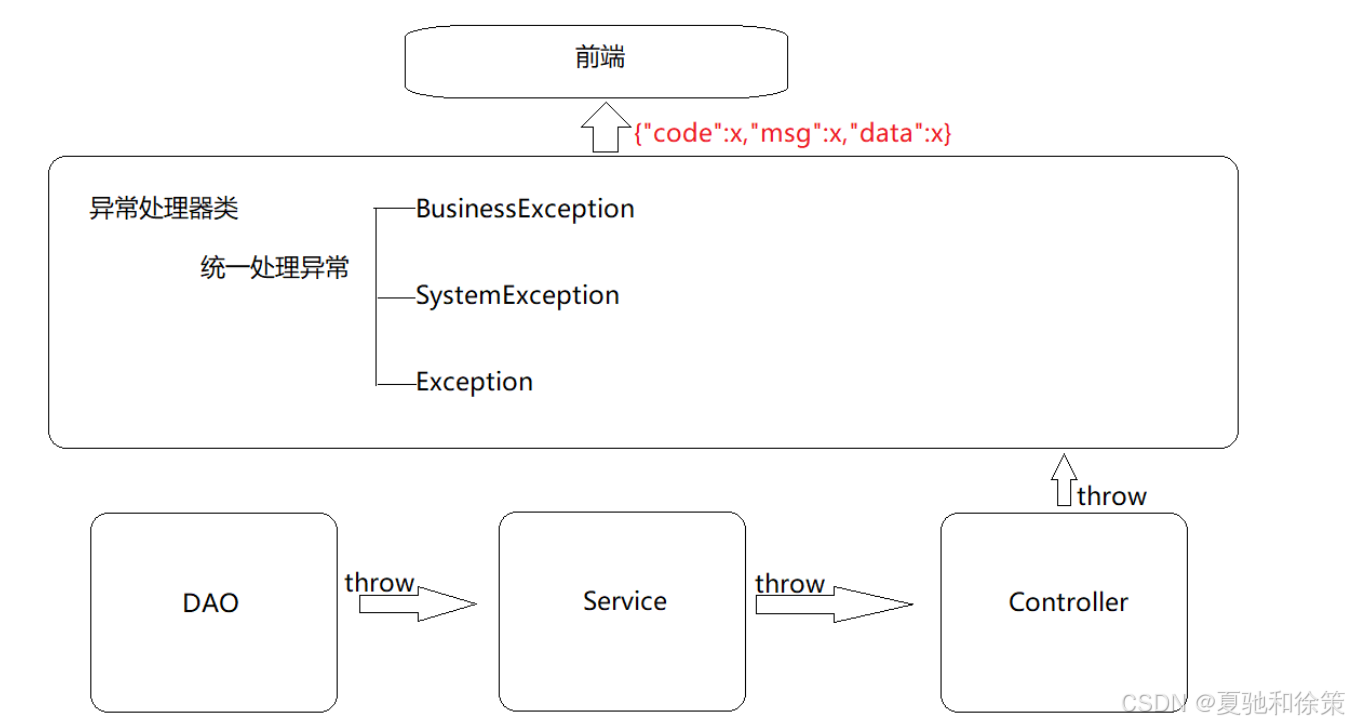
🧠 理论理解
最终落地方案:
-
定义
SystemException、BusinessException。 -
在业务层
try-catch里抛SystemException,逻辑错误直接throw new BusinessException()。 -
在
@RestControllerAdvice中,针对不同异常分类用@ExceptionHandler分别处理。 -
未知异常兜底用
Exception.class。
🏢 企业实战理解
-
阿里:会把 SystemException 直接推送到钉钉告警群。
-
字节:业务异常一般打成 info 日志,系统异常打成 error 日志。
-
Google:异常捕获后,直接打到 Cloud Error Reporting,带 trace_id 便于排查。
-
NVIDIA:AI 平台里的异常除了日志,还会触发重试或资源回收。
-
OpenAI:生产环境的全局异常处理会带有 trace_id,方便开发团队快速定位问题。
❓ 面试题 6:
全局异常处理器中为什么要保留 Exception.class 的兜底方法?它的作用是什么?
✅ 答案:
保留 @ExceptionHandler(Exception.class) 方法的目的是处理所有未被专门捕获的异常。它的作用是:
-
防止未知异常(如代码 bug、配置错误)直接传递到前端,暴露敏感信息。
-
给前端统一返回「系统繁忙,请稍后再试」等友好提示。
-
在后台记录日志、打点、触发报警,帮助开发和运维排查问题。
这相当于「最后一道防线」,保证即使发生未预料的问题,也能优雅处理。
❓ 面试题 7:
系统异常处理器里通常要做哪些额外工作?为什么这些工作重要?
✅ 答案:
系统异常处理器(处理 SystemException 或 Exception)通常会做:
-
记录异常详细日志(包括堆栈、trace_id、请求参数)。
-
发送告警到运维或开发(如短信、钉钉、邮件通知)。
-
在必要时触发重试机制或流量降级。
这些工作重要的原因是: -
系统异常往往是影响全局的问题,需要立刻被关注。
-
如果只是简单返回前端提示,而不记录或告警,问题可能被埋没,导致用户体验受损甚至重大事故。
-
企业级应用必须具备健壮的异常监控与恢复机制。
场景题 3:Google · 全球化接口场景
你在 Google 参与一个全球化项目,为不同地区的用户提供统一接口服务。
但是你发现各个区域的分支系统抛出的异常格式千差万别,有的返回 JSON,有的返回 XML,有的直接 HTTP 404、500。
请问:
✅ 如何在你负责的中台网关(SpringMVC 实现)统一封装这些多样化的后端异常?
✅ 如何让前端和客户端只用解析一种标准格式,无论后端用什么技术栈都能一致?
✅ 如何统一封装多样化后端异常?
-
在中台网关用 SpringMVC 实现全局异常捕获;
-
无论后端返回 JSON、XML、HTML,只要是非 2xx 响应,就用网关拦截包装成统一格式,例如:
{
"code": 50001,
"msg": "内部服务错误,请稍后重试",
"data": null
}
-
如果后端系统未提供详细异常,可以通过 fallback 统一给出“系统繁忙”提示。
✅ 让前端和客户端只用解析一种标准格式?
-
定义跨全公司的标准响应协议(如 Google 内部 API Contract),明确:所有响应都必须是统一的 JSON 格式;
-
网关负责兜底,即使后端有历史包袱(XML、HTML),统一在出口转换为 JSON。
场景题 4:NVIDIA · GPU 云租赁平台场景
你在 NVIDIA 云服务平台做后端开发,发现当 GPU 租赁 API 出现系统错误(比如 GPU 库驱动崩溃)时,异常日志没有记录 GPU 实例的编号,导致定位问题非常困难。
请问:
✅ 你会如何扩展全局异常处理器,让它自动把请求上下文(如 GPU 实例 ID、用户 ID、trace_id)写入日志?
✅ 在返回前端的响应中,你会直接暴露这些内部 ID 吗?为什么?
✅ 如何扩展全局异常处理器,自动写入请求上下文?
-
在 ProjectExceptionAdvice 中,拦截异常时获取当前请求上下文:
-
GPU 实例 ID(从请求 header 或上下文中提取);
-
用户 ID(从登录态中提取);
-
trace_id(用来链路追踪,可能来自 OpenTracing 或自研系统)。
-
-
使用日志框架(如 Logback MDC、SLF4J)把这些上下文一并打入日志,方便问题回溯。
✅ 返回前端的响应中,是否直接暴露这些内部 ID?为什么?
-
不直接暴露。
原因:-
GPU 实例 ID、trace_id 等属于后端内部信息,暴露给前端可能带来安全隐患(被猜测、攻击)。
-
前端只需要知道发生了什么错误(系统问题 vs 参数问题),具体的 trace_id 可在开发者与 SRE 内部沟通时用到,而不是直接传给终端用户。
-
场景题 5:OpenAI · ChatGPT API 场景
你在 OpenAI 负责 ChatGPT API 后端,最近发现大量海外开发者调用接口时因为参数拼错导致 500 错误,误以为是系统 bug,频繁在 GitHub 提 issue。
请问:
✅ 你如何在全局异常处理中区分「参数错误」(用户侧可修正)和「系统异常」?
✅ 返回给调用方的响应中,你会包含哪些信息帮助他们定位问题,又如何避免暴露内部敏感信息?
✅ 如何区分参数错误和系统异常?
-
参数错误(如缺少必填参数、格式不正确):封装为 BusinessException,code 用 4xx。
-
系统异常(如 GPU 节点宕机、Redis 超时):封装为 SystemException,code 用 5xx。
✅ 返回给调用方的响应中包含哪些信息?如何避免敏感信息?
-
返回内容:
-
code:明确区分是 4xx 还是 5xx。
-
msg:用户友好提示,如“参数缺失:prompt 为必填”。
-
不包含内部异常堆栈或具体服务名(例如,不直接告诉调用方“RedisTimeoutException”)。
-
-
如果需要开发者定位问题,可在响应 header 中隐秘地附带 trace_id(用于工单或反馈场景),但绝不直接暴露敏感细节。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











