








2.Redis主从
2.1.搭建主从架构
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
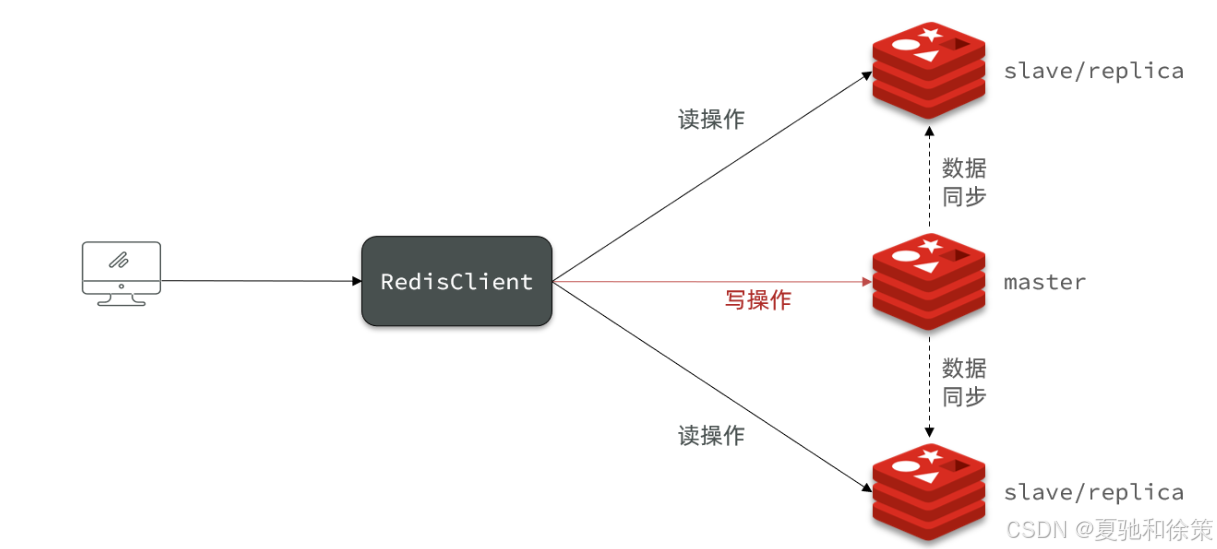
具体搭建流程参考课前资料《Redis集群.md》:

🧠 理论理解
Redis 的主从架构是一种经典的读写分离方案。Master 处理写操作,同时将数据同步给多个 Slave,而 Slave 处理读操作,有效分担了主节点的压力。
主从复制是 Redis 最基础的分布式能力,是后续集群、哨兵机制等功能的基础,核心目的是提升系统的并发读能力、容灾能力和横向扩展性。
🏢 企业实战理解
在腾讯、字节跳动等大厂中,Redis 主从结构广泛用于 用户会话、热点排行榜、商品详情页缓存等业务。Master 通常部署在写敏感节点,多个 Slave 放在靠近用户的边缘节点,从而实现 地理分布式读写分离,并辅以 读请求自动路由 + 连接池负载均衡。
💡 面试题 1(基础原理)
问:Redis 主从复制的作用是什么?主从架构是如何提升性能的?
参考答案:
Redis 主从复制的主要作用是实现读写分离和数据冗余容灾。通过一个 Master 节点接收写请求,多个 Slave 节点提供只读服务,可以显著提升系统整体的读性能。
当主节点写入数据后,会自动异步同步到各个从节点,确保各个节点数据一致。若 Master 宕机,某个 Slave 可提升为新的 Master,确保系统高可用。
📌 场景题 1:主从频繁全量同步导致系统雪崩
背景:
你负责的用户登录服务使用 Redis 作为缓存。架构为 1 个 Master + 3 个 Slave,正常情况下访问量稳定。但在某次运营活动高峰期,Redis 突然频繁触发全量同步,导致主节点阻塞、接口大量超时,最终缓存雪崩。
问题:
-
你如何快速定位问题根因?
-
如何避免后续再次发生类似雪崩?
参考思路:
🔍 问题定位:
-
查看 Slave 日志:
-
是否频繁触发
Full resync,说明 offset 被覆盖或replid不匹配。
-
-
分析原因:
-
写入过快,Slave offset 同步不过来。
-
repl_backlog_size太小,offset 很快被覆盖。 -
网络抖动,导致同步中断,offset 丢失。
-
-
查看 Redis 配置:
-
是否
min-slaves-to-write未配置,导致主节点一直写入无从可读。
-
-
监控指标:
-
关注
master_repl_offset - slave_repl_offset差值; -
检查带宽、CPU 是否打满。
-
✅ 优化方案:
-
增大
repl_backlog_size(比如从 1MB 提高到 100MB); -
使用更快网络,提升 Slave 同步能力;
-
实现连接池健康检查,避免将请求打到未同步完的 Slave;
-
使用 Sentinel 或 Redis Cluster,实现自动故障转移;
-
高峰前预热缓存 + Slave 提前同步。
2.2.主从数据同步原理
2.2.1.全量同步
主从第一次建立连接时,会执行全量同步,将master节点的所有数据都拷贝给slave节点,流程:
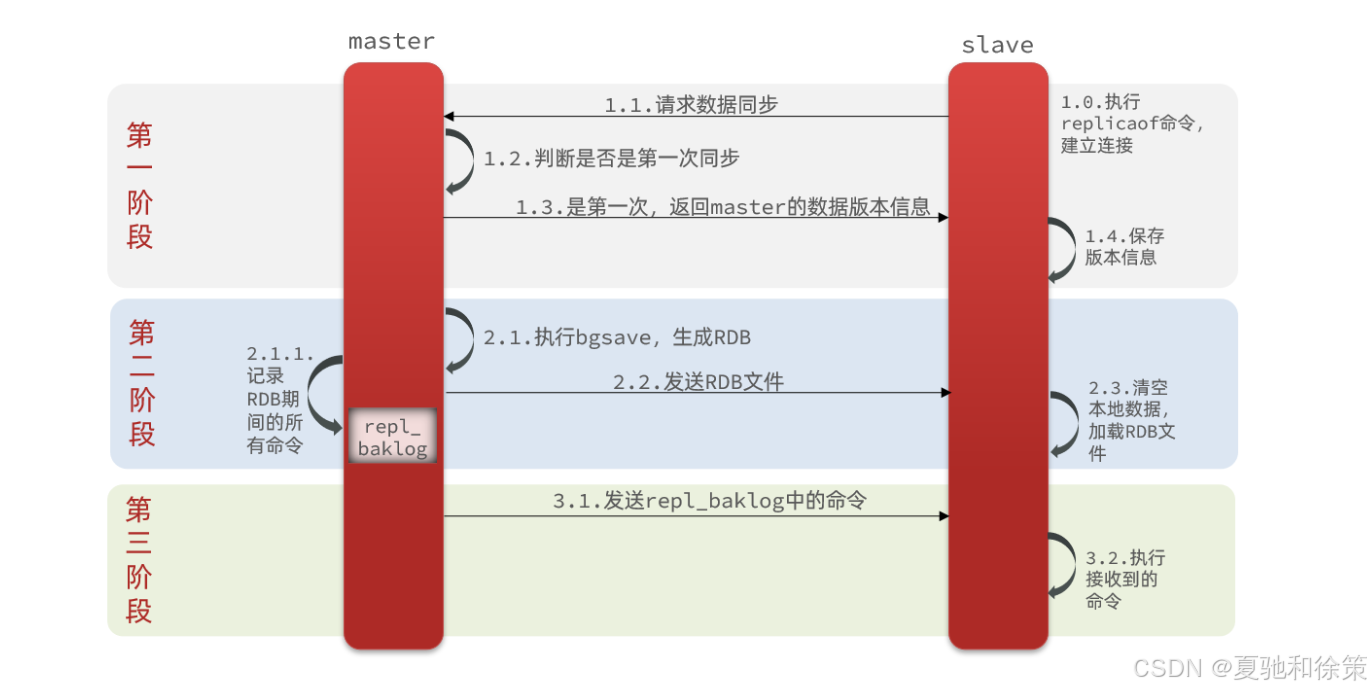
这里有一个问题,master如何得知salve是第一次来连接呢??
有几个概念,可以作为判断依据:
-
Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
-
offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据。
因为slave原本也是一个master,有自己的replid和offset,当第一次变成slave,与master建立连接时,发送的replid和offset是自己的replid和offset。
master判断发现slave发送来的replid与自己的不一致,说明这是一个全新的slave,就知道要做全量同步了。
master会将自己的replid和offset都发送给这个slave,slave保存这些信息。以后slave的replid就与master一致了。
因此,master判断一个节点是否是第一次同步的依据,就是看replid是否一致。
如图:
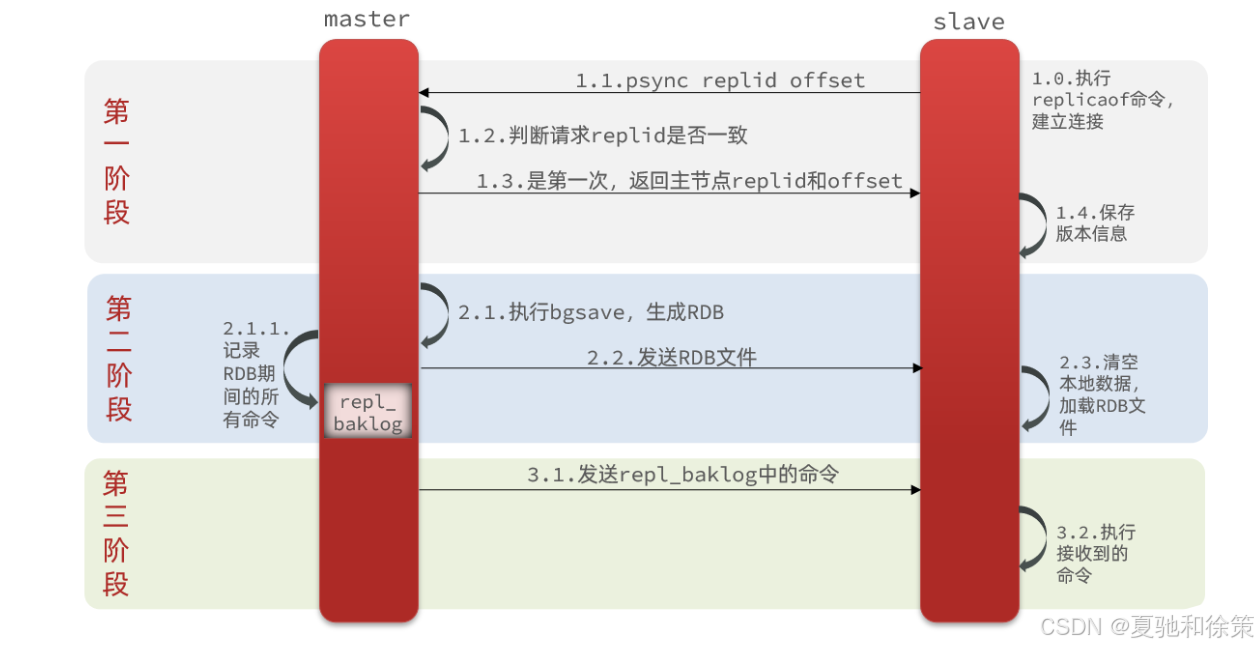
完整流程描述:
-
slave节点请求增量同步
-
master节点判断replid,发现不一致,拒绝增量同步
-
master将完整内存数据生成RDB,发送RDB到slave
-
slave清空本地数据,加载master的RDB
-
master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
-
slave执行接收到的命令,保持与master之间的同步
🧠 理论理解
全量同步是 Slave 第一次连接到 Master 时的标准操作。Redis 会通过 RDB 快照机制生成一份内存快照,并通过 socket 将整个数据文件发送到 Slave。之后再将期间写入的命令缓冲同步,保证最终数据一致。
核心判断依据是 replid 和 offset:Master 发现 Slave 发来的 replid 与自己不同,就知道对方是“初次来访者”,必须全量同步。
🏢 企业实战理解
在阿里巴巴的缓存架构中,全量同步阶段被认为是系统的“脆弱期”,极易对 Master 造成性能压力。因此通常会在夜间低峰时段批量上线新 Slave,并使用流量削峰系统限流同步速率。同时使用独立线程做快照生成,减少主线程阻塞。
💡 面试题 2(同步机制)
问:Redis 主从复制中的全量同步和增量同步有什么区别?它们分别在什么情况下触发?
参考答案:
-
全量同步:Slave 第一次连接 Master,或与 Master 断开时间太久导致 offset 无法追溯时触发。Master 会生成 RDB 快照并发送给 Slave,然后再同步期间缓存的命令。
-
增量同步:Slave 与 Master 仅有短暂断连,且 offset 仍在
repl_backlog范围内,则可只同步缺失的部分命令。
触发条件总结:
| 场景 | 同步方式 |
|---|---|
| 首次连接 | 全量同步 |
| offset 被覆盖 | 全量同步 |
| 短暂断线 | 增量同步 |
2.2.2.增量同步
全量同步需要先做RDB,然后将RDB文件通过网络传输个slave,成本太高了。因此除了第一次做全量同步,其它大多数时候slave与master都是做增量同步。
什么是增量同步?就是只更新slave与master存在差异的部分数据。如图:

那么master怎么知道slave与自己的数据差异在哪里呢?
🧠 理论理解
增量同步通过 offset 差值来实现,仅同步未完成的数据命令,避免全量 RDB 的高开销。主节点使用一个环形 repl_backlog 缓冲区存储最近操作,Slave 若能在其中找到自己缺失的数据位置,即可增量追赶。
🏢 企业实战理解
在京东、网易的缓存架构中,增量同步几乎是常态手段。它配合复制偏移量监控工具,可以实时检测主从同步延迟(replication lag),并根据偏移量差异调整缓冲区大小和写入节奏,确保大促期间系统稳定运行。
💡 面试题 3(企业实战)
问:你在项目中如何优化 Redis 主从架构,保证高并发场景下的数据一致性与性能?
参考答案:
项目中,我使用以下策略优化主从同步:
-
主从拓扑结构:一主多从,读请求统一由连接池路由到负载最小的 Slave;
-
合理配置参数:根据写入速率将
repl_backlog_size调整为 10~100MB,防止频繁触发全量同步; -
监控同步状态:定期采集
master_repl_offset和slave_repl_offset,实时监控复制延迟; -
连接隔离机制:通过连接池策略避免高并发读压挤占主节点;
-
哨兵自动故障转移:结合 Redis Sentinel + 健康检查,自动切换 Master 并重连客户端。
2.2.3.repl_backlog原理
master怎么知道slave与自己的数据差异在哪里呢?
这就要说到全量同步时的repl_baklog文件了。
这个文件是一个固定大小的数组,只不过数组是环形,也就是说角标到达数组末尾后,会再次从0开始读写,这样数组头部的数据就会被覆盖。
repl_baklog中会记录Redis处理过的命令日志及offset,包括master当前的offset,和slave已经拷贝到的offset:

slave与master的offset之间的差异,就是salve需要增量拷贝的数据了。
随着不断有数据写入,master的offset逐渐变大,slave也不断的拷贝,追赶master的offset:

直到数组被填满:

此时,如果有新的数据写入,就会覆盖数组中的旧数据。不过,旧的数据只要是绿色的,说明是已经被同步到slave的数据,即便被覆盖了也没什么影响。因为未同步的仅仅是红色部分。
但是,如果slave出现网络阻塞,导致master的offset远远超过了slave的offset:

如果master继续写入新数据,其offset就会覆盖旧的数据,直到将slave现在的offset也覆盖:

棕色框中的红色部分,就是尚未同步,但是却已经被覆盖的数据。此时如果slave恢复,需要同步,却发现自己的offset都没有了,无法完成增量同步了。只能做全量同步。

🧠 理论理解
repl_backlog 是 Redis 主节点中维护的 命令历史缓冲区,默认大小为 1MB。它以环形数组的形式存储操作命令,并随着写入不断循环覆盖。
Slave 的同步能力取决于:其 offset 是否还在 backlog 范围内,一旦 backlog 被覆盖,就必须重新全量同步。
🏢 企业实战理解
在美团、百度等企业中,repl_backlog 的大小不是默认固定值,而是根据业务写入量动态调整(如配置为 100MB),并借助定时快照 + 数据差异检查脚本,动态判定 Slave 是否需要全量同步,从而实现智能化同步调度策略。
💡 面试题 4(源码机制)
问:Redis 中是如何判断某个 Slave 是否需要全量同步的?
参考答案:
Redis 在同步开始时,Slave 会发送自己的 replid 和 offset 给 Master。Master 通过以下逻辑判断:
-
如果 Slave 的
replid与 Master 的不一致,说明是第一次连接或与旧 Master 同步过,触发全量同步; -
如果
replid一致,Master 会判断offset是否仍在repl_backlog中,若是,则进行增量同步; -
否则,同样触发全量同步。
该机制基于 replication.c 中的 sync_with_master() 方法逻辑。
📌 场景题 2:Redis 读压力过高,某个从节点崩溃
背景:
你的系统在大促活动中使用 Redis 存储用户购物车数据,主从模式部署。一天下午突然某个 Slave 由于高并发查询请求被压垮,导致服务不稳定。
问题:
-
为何某个 Slave 成为单点瓶颈?
-
你如何重构当前架构以提升系统鲁棒性?
参考思路:
⚠️ 可能原因:
-
客户端连接池未做负载均衡,仅连接了某一个 Slave;
-
某些服务实例配置硬编码 Slave 地址;
-
大 key 查询或慢查询耗尽该节点资源;
-
没有健康检查,导致故障节点依然在路由中。
🏗 架构重构建议:
-
使用 中间件客户端如 Codis、Twemproxy、Redis Proxy 实现读请求负载均衡;
-
配置客户端连接池支持多 Slave 自动路由;
-
针对热点 key 做分片或拆分(使用 hash tag);
-
引入监控 + 异常下线机制,Slave 宕机后自动切出请求池;
-
用 Sentinel 或 Cluster,自动替换故障节点。
2.3.主从同步优化
主从同步可以保证主从数据的一致性,非常重要。
可以从以下几个方面来优化Redis主从就集群:
-
在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
-
Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
-
适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
-
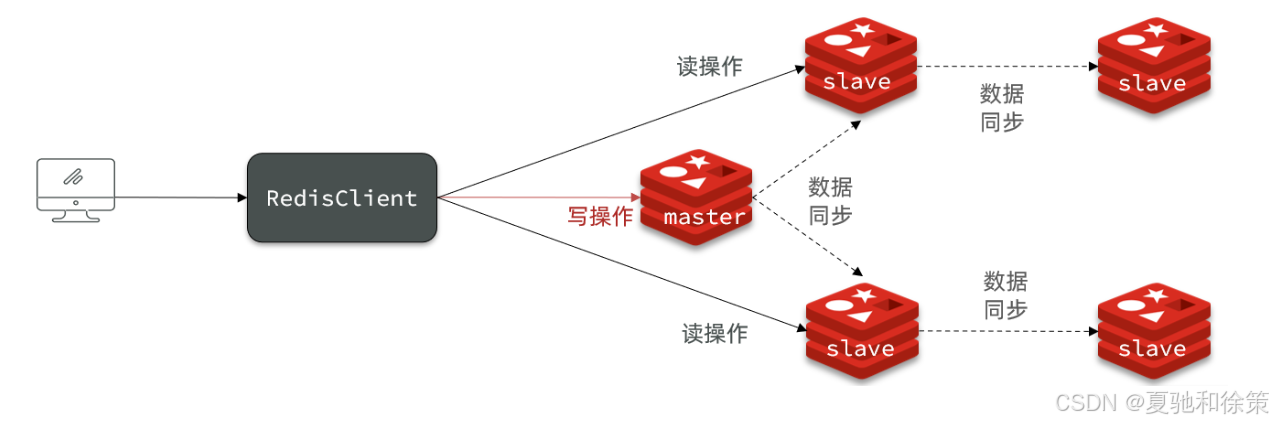
限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
主从从架构图:
🧠 理论理解
主从同步虽然提供了高可用能力,但不当配置会造成严重延迟、主节点阻塞等问题。常见优化策略包括:
-
合理规划主从数量(读请求均衡);
-
调整
repl_backlog缓冲区大小; -
使用持久化策略(RDB/AOF)增强容灾;
-
引入哨兵或集群提升可用性。
🏢 企业实战理解
在字节跳动,每个 Redis 主节点配有 3~5 个 Slave,结合自研中间件实现自动读写路由。当 Master 突然故障时,哨兵或 Kubernetes operator 立即触发主从切换并恢复连接池。而在 Google 内部,Redis 被改造成分布式 Paxos 风格主从,支持跨区域多副本同步,以支持全球产品一致性。
💡 面试题 5(异常场景)
问:如果主节点写入速度过快,Slave 同步不上怎么办?会发生什么后果?如何处理?
参考答案:
若 Master 写入太快导致 repl_backlog 被频繁覆盖,而 Slave 未能及时同步完,则 Slave 的 offset 无法对齐,只能触发 全量同步。
后果包括:
-
主节点性能骤降(频繁生成 RDB);
-
网络带宽压力激增;
-
若多个 Slave 同时全量同步,主节点可能被拖垮。
应对策略:
-
增大
repl_backlog_size缓冲容量; -
限流写入(配合队列或网关限流);
-
增加 Slave 同步带宽或放置在更近网络节点;
-
使用 Redis Cluster 分区降低单节点压力。
📌 场景题 3:主节点重启,Slave 节点全部失效
背景:
某次服务器维护后,Redis Master 重启,随后 5 个 Slave 无法完成同步,报错full resync required but backlog not found,导致大量读请求失败,业务瘫痪 5 分钟。
问题:
-
为什么 Slave 会同步失败?
-
如何让系统在重启后快速恢复同步能力?
参考解析:
📌 同步失败原因:
-
Master 重启导致
replid变化,Slave 无法继续用原 offset 增量同步; -
repl_backlog丢失(内存中数据丢失); -
Slave 被迫执行全量同步,但 Master 高负载期间无法支撑多个全量。
🛠 解决方案:
-
启用 Redis 6.0+ 的 PSYNC2 协议 +
diskless replication,提高同步效率; -
开启 RDB 文件 + AOF 持久化,Master 重启后可恢复旧 offset;
-
使用 Redis Cluster 替代传统主从,避免单点 Master 影响;
-
引入运维预案:滚动重启 + 缓存预热机制。
2.4.小结
简述全量同步和增量同步区别?
-
全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
-
增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?
-
slave节点第一次连接master节点时
-
slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
-
slave节点断开又恢复,并且在repl_baklog中能找到offset时
🧠 理论理解
-
全量同步:成本高,首次连接或 offset 不可用时使用;
-
增量同步:高效,利用 offset 对比和命令日志追赶主节点;
-
同步失败回退机制:保证数据一致性是第一优先级。
🏢 企业实战理解
大厂工程师在使用 Redis 主从时,会引入以下机制做强化:
-
定期主从 offset 审计;
-
主从读写延迟告警系统;
-
可视化监控 replid / offset;
-
同步状态 dashboard 配合自动诊断工具。
这些机制构建起了 Redis 主从同步的工业级生产力防线。
💡 面试题 6(场景题)
问:某公司在双十一期间遇到 Redis 主从同步频繁失败,Slave 总是重新全量同步,系统负载过高,你如何排查与优化?
参考答案:
排查步骤:
-
查看 Slave 日志,确认是否频繁因 offset 不匹配回退全量同步;
-
检查 Master 的
repl_backlog_size是否偏小,offset 被频繁覆盖; -
查看网络延迟与 Redis 写入量是否突增,造成 Slave 滞后;
-
检查是否存在慢查询或大 key 导致命令阻塞;
-
检查 Redis 持久化开销是否影响主线程。
优化建议:
-
增大
repl_backlog_size; -
给 Slave 提升配置,确保其追赶能力;
-
使用读写分离、降级服务策略缓解压力;
-
开启 AOF 重写 + RDB 混合持久化降低压力;
-
若支持,可改为 Redis Cluster + 分区压缩读写集中度。
📌 场景题 4:某地区 Slave 同步延迟过高
背景:
你们是一个全国分布的 SaaS 系统,Redis 部署在杭州主节点,北京部署一台 Slave 提供本地读服务。运维监控发现该 Slave 总是比 Master 落后 30s 左右,导致部分用户读到旧数据。
问题:
-
造成延迟的可能原因有哪些?
-
如何解决跨地域主从同步延迟问题?
参考分析:
🧭 可能原因:
-
杭州到北京链路延迟大;
-
带宽不足或中间链路丢包;
-
Slave 机器性能差或 IO 被占;
-
网络抖动或 Redis 主线程阻塞。
📈 解决方案:
-
将数据中心 Redis 部署成“多主多从跨地域架构”,提升异地可用性;
-
使用异步消息队列 + 本地缓存,缓解读延迟;
-
结合 CDN + 本地副本缓存;
-
若业务允许,设置 最终一致性策略,短暂延迟可容忍。



















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











