








3、优惠卷秒杀
3.1 -全局唯一ID
每个店铺都可以发布优惠券:

当用户抢购时,就会生成订单并保存到tb_voucher_order这张表中,而订单表如果使用数据库自增ID就存在一些问题:
-
id的规律性太明显
-
受单表数据量的限制
场景分析:如果我们的id具有太明显的规则,用户或者说商业对手很容易猜测出来我们的一些敏感信息,比如商城在一天时间内,卖出了多少单,这明显不合适。
场景分析二:随着我们商城规模越来越大,mysql的单表的容量不宜超过500W,数据量过大之后,我们要进行拆库拆表,但拆分表了之后,他们从逻辑上讲他们是同一张表,所以他们的id是不能一样的, 于是乎我们需要保证id的唯一性。
全局ID生成器,是一种在分布式系统下用来生成全局唯一ID的工具,一般要满足下列特性:
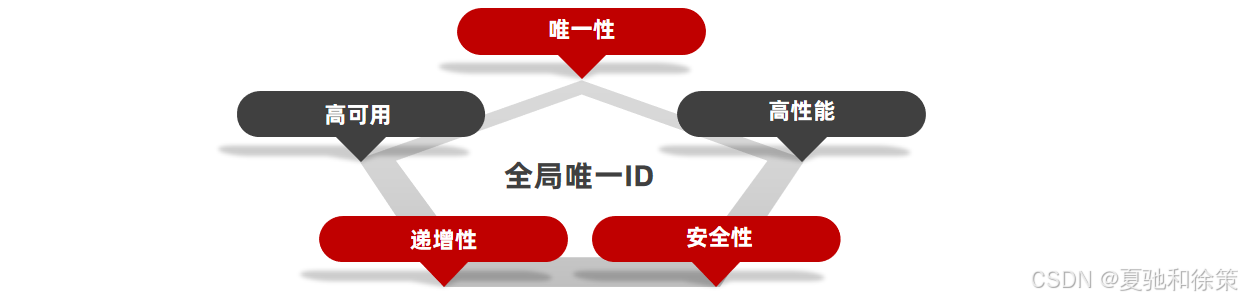
为了增加ID的安全性,我们可以不直接使用Redis自增的数值,而是拼接一些其它信息:

ID的组成部分:符号位:1bit,永远为0
时间戳:31bit,以秒为单位,可以使用69年
序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID
🧠 理论理解
在分布式系统中,生成全局唯一 ID 是高并发下的基础能力。
如果直接用数据库自增 ID,会遇到:
-
单点瓶颈(中心库压力大)
-
容量限制(单表数量有限)
-
规律暴露(连续数字暴露交易量等信息)
Redis 实现方案:
-
用时间戳(秒级)提供大范围唯一性,保证越晚生成 ID 越大。
-
用 Redis 的 INCR 提供秒内计数器,保证并发下不重复。
组合成高并发、分布式友好的 64 位 ID。
🏢 大厂实战理解
阿里(天猫双 11)、字节(抖音直播带货)、腾讯(王者荣耀订单)、Google(广告投放流水)、OpenAI(多租户模型任务)都需要分布式全局 ID。
它们会选择:
-
Snowflake(Twitter 开源方案,41bit 时间戳 + 10bit 机器 ID + 12bit 序列号)
-
Redis/Lua 脚本(灵活快速)
-
特定业务场景下自定义(如:预分段、数据库分库自增)
3.2 -Redis实现全局唯一Id
@Component
public class RedisIdWorker {
/**
* 开始时间戳
*/
private static final long BEGIN_TIMESTAMP = 1640995200L;
/**
* 序列号的位数
*/
private static final int COUNT_BITS = 32;
private StringRedisTemplate stringRedisTemplate;
public RedisIdWorker(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
public long nextId(String keyPrefix) {
// 1.生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - BEGIN_TIMESTAMP;
// 2.生成序列号
// 2.1.获取当前日期,精确到天
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
// 2.2.自增长
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
// 3.拼接并返回
return timestamp << COUNT_BITS | count;
}
}测试类
知识小贴士:关于countdownlatch
countdownlatch名为信号枪:主要的作用是同步协调在多线程的等待于唤醒问题
我们如果没有CountDownLatch ,那么由于程序是异步的,当异步程序没有执行完时,主线程就已经执行完了,然后我们期望的是分线程全部走完之后,主线程再走,所以我们此时需要使用到CountDownLatch
CountDownLatch 中有两个最重要的方法
1、countDown
2、await
await 方法 是阻塞方法,我们担心分线程没有执行完时,main线程就先执行,所以使用await可以让main线程阻塞,那么什么时候main线程不再阻塞呢?当CountDownLatch 内部维护的 变量变为0时,就不再阻塞,直接放行,那么什么时候CountDownLatch 维护的变量变为0 呢,我们只需要调用一次countDown ,内部变量就减少1,我们让分线程和变量绑定, 执行完一个分线程就减少一个变量,当分线程全部走完,CountDownLatch 维护的变量就是0,此时await就不再阻塞,统计出来的时间也就是所有分线程执行完后的时间。
@Test
void testIdWorker() throws InterruptedException {
CountDownLatch latch = new CountDownLatch(300);
Runnable task = () -> {
for (int i = 0; i < 100; i++) {
long id = redisIdWorker.nextId("order");
System.out.println("id = " + id);
}
latch.countDown();
};
long begin = System.currentTimeMillis();
for (int i = 0; i < 300; i++) {
es.submit(task);
}
latch.await();
long end = System.currentTimeMillis();
System.out.println("time = " + (end - begin));
}🧠 理论理解
秒杀系统要解决的关键问题:
✅ 业务正确性 → 秒杀时间、库存检查、下单条件(如一人一单)。
✅ 并发安全性 → 库存扣减、订单生成、状态一致要支持高并发场景。
✅ 性能优化 → 尽量避免数据库瓶颈,用缓存、限流等措施提升抗压能力。
代码层面:
-
秒杀条件 → 检查时间范围、库存数量。
-
库存扣减 → 乐观锁(where stock > 0),减少锁冲突。
-
一人一单 → 加锁(如 userId 粒度锁、分布式锁),保证唯一性。
🏢 大厂实战理解
阿里:用分布式锁(Tair、Redisson)结合乐观锁,保证库存和下单一致性。
字节:异步下单 + 消息队列(Kafka)削峰,前端快速响应,后端异步落库。
Google:AdWords 系统中广告位竞拍,用乐观锁 +分布式事务,保证中标唯一性。
OpenAI:多模型调度任务抢占,先写入 Redis 队列,异步持久化。
🧠 理论理解
这节的核心是:如何用 Redis 替代传统数据库自增 ID 实现分布式唯一 ID。
要解决两个关键问题:
✅ 并发安全 → Redis 的 INCR 命令是原子操作,天然保证并发下递增唯一。
✅ 时间可排序 → 在 ID 中加时间戳,保证 ID 越新越大,满足常见业务(如订单、流水号)的时间有序性需求。
方案组成:
-
前半部分 → 31bit 时间戳(秒级),保证有序。
-
后半部分 → 32bit 序列号(每天或每秒自增),保证同一秒内唯一。
相比数据库、雪花算法(Snowflake),这种方案更简单,依赖 Redis,适合中小规模系统快速实现。
🏢 大厂实战理解
阿里:自研 Leaf 服务(美团开源)生成分布式 ID,支持号段模式、Snowflake 模式。
字节:针对不同业务(短视频、直播、推荐),有专门的 UID 服务,用数据库 + 缓存 + 号段方案。
Google:使用 Spanner 提供全球唯一、强一致的主键分配能力。
OpenAI:用 UUIDv6(时间排序优化版)或 Redis/Lua 实现多租户 ID 生成。
❶ 全局唯一 ID(3.1–3.2)
Q1: 为什么不能直接用数据库自增 ID?用 Redis 生成全局唯一 ID 有什么优势和局限?
✅ 答案(分析):
直接用数据库自增 ID,存在三个主要问题:
1️⃣ 单点瓶颈 → 所有写入都要串行访问数据库,无法横向扩展。
2️⃣ 规律性暴露 → 自增数字容易被推测业务敏感数据(如每日订单量)。
3️⃣ 拆库拆表困难 → 多库多表后,很难保证唯一性和递增性。
用 Redis 生成唯一 ID 的优势:
✅ INCR 操作是分布式下原子操作,天然保证唯一。
✅ 结合时间戳 + 计数器设计,满足全局唯一 + 大体递增需求。
✅ 性能高、延迟低,可支撑高并发场景。
局限:
⚠️ 强依赖 Redis 可用性,单点故障或 Redis 异常会影响全局 ID 分配。
⚠️ 精确时间戳依赖机器时间同步,跨机房要注意 NTP 校准。
大厂实践通常结合 Redis、数据库号段、雪花算法等多种方案,按场景权衡选用。
❶ 全局唯一 ID(3.1–3.2)
场景题:
你在字节跳动广告推荐团队,广告投放订单每天数千万级,要求系统能快速生成全局唯一 ID,要求高并发、去中心化、容错性强。请问你会怎么设计?选择 Redis、数据库、雪花算法还是其他方案?
✅ 高智商答案:
我会分多层权衡:
1️⃣ 高并发场景下,数据库号段和自增 ID 先排除,中心化瓶颈明显。
2️⃣ Redis INCR 是好方案,但依赖单点,要保证 Redis 的高可用部署(主从、哨兵、集群)。
3️⃣ 雪花算法(Snowflake)非常适合,无需中心节点,按机器位分布 ID,但要注意机器时钟漂移(NTP 同步)。
4️⃣ Google Spanner 等全球一致性系统提供更强容错,但成本和接入复杂度高。
最终我会推荐:用雪花算法为主(去中心化、超低延迟),Redis INCR 作为兜底方案(防止极端场景 ID 生成失败)。核心是:按业务规模分散风险、降低依赖。
具体实现:
-
雪花算法(Snowflake)组件化部署,分布式无中心节点。
-
每个节点分配机器 ID(10bit),要求通过配置中心(如 Apollo)集中分配,避免重复。
-
时间戳部分(41bit)用毫秒时间,需要全集群 NTP 同步。
-
序列号部分(12bit)本地自增,每毫秒内最多 4096 个 ID,超出时线程等待到下一毫秒。
-
部署:在广告服务应用里做 Snowflake 工具类,用单例模式注入全局使用。
-
-
Redis INCR 备选方案:
-
Redis 部署主从 + 哨兵保证高可用。
-
按天分 key:
incr:order:202405,用INCR命令生成序列号。 -
拼接时间戳、业务前缀,构成最终 ID。
-
引入 Lua 脚本或 Redisson,确保分布式场景下的原子性。
-
监控:
✅ 接入 Prometheus/Grafana 监控 ID 生成速率、异常情况(如时间回拨、雪花节点冲突)。
✅ 定时巡检 Redis 主从状态、延迟。
✅ 潜在问题:
-
❗ 时间回拨:
如果机器时间被手动调整或 NTP 校准失败,雪花算法生成的时间戳会倒退,导致生成的 ID 重复或乱序。
→ 解决方案: 强制 NTP 校准 + 检测时间回拨时拒绝生成 ID + 在业务端做幂等。 -
❗ Redis INCR 单点问题:
如果 Redis 节点挂了,整个 INCR 流程中断。
→ 解决方案: 部署 Redis Cluster 或 Sentinel,客户端用 Redisson 自动感知主从切换。 -
❗ 高并发下 ID 生成慢:
如果本地雪花算法单机性能不足,高并发下成瓶颈。
→ 解决方案: 横向扩容节点,用机器位分配负载。
3.3 添加优惠卷
每个店铺都可以发布优惠券,分为平价券和特价券。平价券可以任意购买,而特价券需要秒杀抢购:

tb_voucher:优惠券的基本信息,优惠金额、使用规则等 tb_seckill_voucher:优惠券的库存、开始抢购时间,结束抢购时间。特价优惠券才需要填写这些信息
平价卷由于优惠力度并不是很大,所以是可以任意领取
而代金券由于优惠力度大,所以像第二种卷,就得限制数量,从表结构上也能看出,特价卷除了具有优惠卷的基本信息以外,还具有库存,抢购时间,结束时间等等字段
新增普通卷代码: VoucherController
@PostMapping
public Result addVoucher(@RequestBody Voucher voucher) {
voucherService.save(voucher);
return Result.ok(voucher.getId());
}新增秒杀卷代码:
VoucherController
@PostMapping("seckill")
public Result addSeckillVoucher(@RequestBody Voucher voucher) {
voucherService.addSeckillVoucher(voucher);
return Result.ok(voucher.getId());
}VoucherServiceImpl
@Override
@Transactional
public void addSeckillVoucher(Voucher voucher) {
// 保存优惠券
save(voucher);
// 保存秒杀信息
SeckillVoucher seckillVoucher = new SeckillVoucher();
seckillVoucher.setVoucherId(voucher.getId());
seckillVoucher.setStock(voucher.getStock());
seckillVoucher.setBeginTime(voucher.getBeginTime());
seckillVoucher.setEndTime(voucher.getEndTime());
seckillVoucherService.save(seckillVoucher);
// 保存秒杀库存到Redis中
stringRedisTemplate.opsForValue().set(SECKILL_STOCK_KEY + voucher.getId(), voucher.getStock().toString());
}🧠 理论理解
超卖问题是典型的并发安全问题:
-
多线程同时查询库存、同时扣减 → 超过实际库存。
解决方案:
✅ 悲观锁(如 synchronized、数据库行锁) → 强互斥,串行化操作。
✅ 乐观锁(如 CAS、版本号、where 条件限制) → 无锁优化,高并发友好。
选择乐观锁优于悲观锁,因为它能减少线程等待,提升系统吞吐量。
🏢 大厂实战理解
阿里:针对高频扣减场景(如双 11 抢购),用 Redis 原子操作、Lua 脚本直接扣减库存,绕过数据库。
字节:对核心限量商品,后台统一走分布式库存系统,用预分片技术分散写入压力。
Google:在大规模 API 调用限额场景,用分布式计数器(如 Google Cloud Spanner + F1)精准控制资源分配。
🧠 理论理解
在系统设计上,优惠券分为两类:
✅ 普通券 → 不限量、不限时,随时领取。
✅ 秒杀券 → 限时限量,必须有库存、时间窗口等约束。
数据库设计:
-
tb_voucher→ 基础信息表。 -
tb_seckill_voucher→ 秒杀信息表(库存、开始结束时间、限购策略)。
为了高并发性能,秒杀券库存会预先同步到 Redis,避免查询时直接打数据库。
这是典型的 “冷热数据分层” 设计,把热点数据提前进缓存。
🏢 大厂实战理解
阿里:双 11 秒杀商品在上线前批量预热到 Redis、Tair,库存量也分片分配。
字节:直播电商场景用 Redis 承载实时券、库存、限流等高频操作,数据库只做最终落库。
Google:Google Play 用 Redis、Memcached 缓存折扣券、限免券数据,保证海量用户瞬时访问。
❷ 优惠券系统设计(3.3)
Q2: 为什么要把秒杀券库存提前存入 Redis,而不是直接查数据库?如何保证缓存和数据库一致?
✅ 答案(分析):
直接查数据库,存在两个致命问题:
1️⃣ 访问压力 → 秒杀场景下,数据库难以承受每秒数十万 QPS。
2️⃣ 性能瓶颈 → 单次查询需要 IO,远慢于内存缓存,用户体验差。
把库存预热到 Redis:
✅ 高并发下,用内存读写替代数据库,大幅减轻压力。
✅ Redis 单线程、内存操作快,配合 Lua 脚本可实现扣减的原子性。
一致性保证:
1️⃣ 定期同步 → 定时任务定时修正 Redis 和数据库库存。
2️⃣ 强一致更新 → 扣减库存用 Lua 脚本同时修改 Redis + 异步写入数据库。
3️⃣ 补偿机制 → 出现不一致时,用日志对账、重算补偿。
大厂实践通常采用“最终一致性”理念,在可接受范围内牺牲强一致,换取系统吞吐量。
❷ 优惠券系统设计(3.3)
场景题:
你在阿里天猫工作,双 11 秒杀场景下,优惠券是热点资源,流量巨大。你会如何预热缓存、保证数据库和缓存的一致性?万一缓存丢失了,怎么办?
✅ 高智商答案:
第一步,我会在活动开始前用后台批量预热,把优惠券、库存、抢购时间等数据写入 Redis。
第二步,为保证一致性,操作必须遵循:先更新数据库 → 再刷新缓存(或直接删除缓存,等下次查询再回填)。
第三步,考虑缓存丢失:要设计双保险,例如:
-
异步任务定时检查、重建缓存。
-
请求穿透后,加布隆过滤器 + 空对象缓存,防止缓存击穿。
-
对超高流量场景,用静态化或 CDN 分担压力。
我会用分布式事务、异步补偿、日志重放等手段,在高性能和强一致性之间做平衡。
✅ 预热阶段:
-
活动开始前,后台管理系统通过批量脚本将
tb_voucher、tb_seckill_voucher数据拉取到 Redis。-
用 Redis Hash 保存商品详情。
-
用 Redis String 保存秒杀库存(
seckill:stock:<voucherId>)。 -
用 EXPIRE 设置秒杀结束时间,避免缓存永久占用。
-
✅ 秒杀期间:
-
核心写操作(扣减库存)直接在 Redis 完成,用 Lua 脚本保证原子性:
-
Lua 脚本检查库存 > 0,扣减库存,写入订单消息队列(如 RocketMQ、Kafka)。
-
Lua 脚本执行失败 → 库存不足或活动过期,直接返回前端失败提示。
-
✅ 最终一致性:
-
后台消费者从 MQ 消费订单消息,异步写入 MySQL,减少数据库压力。
-
定时任务(Quartz/Spring Schedule)每隔 5 分钟全表对账,发现 Redis 和数据库数据不一致时,用事务修正。
工具:
✅ 用 Redisson 做高并发锁。
✅ 用 Spring Boot + RedisTemplate 封装缓存访问。
✅ 潜在问题:
-
❗ 缓存击穿:
热点优惠券过期瞬间,大量请求同时打到数据库。
→ 解决方案: 给热点 key 加互斥锁(如 Redis SET NX)或用逻辑过期。 -
❗ 缓存一致性:
数据库更新了,缓存没更新,导致前后端数据不一致。
→ 解决方案: 采用删除缓存策略,先更新数据库,再删缓存,或者引入消息队列通知缓存刷新。 -
❗ 缓存雪崩:
大量 key 统一过期,瞬间打爆数据库。
→ 解决方案: 给 key 加随机过期时间,分散到不同时间点。
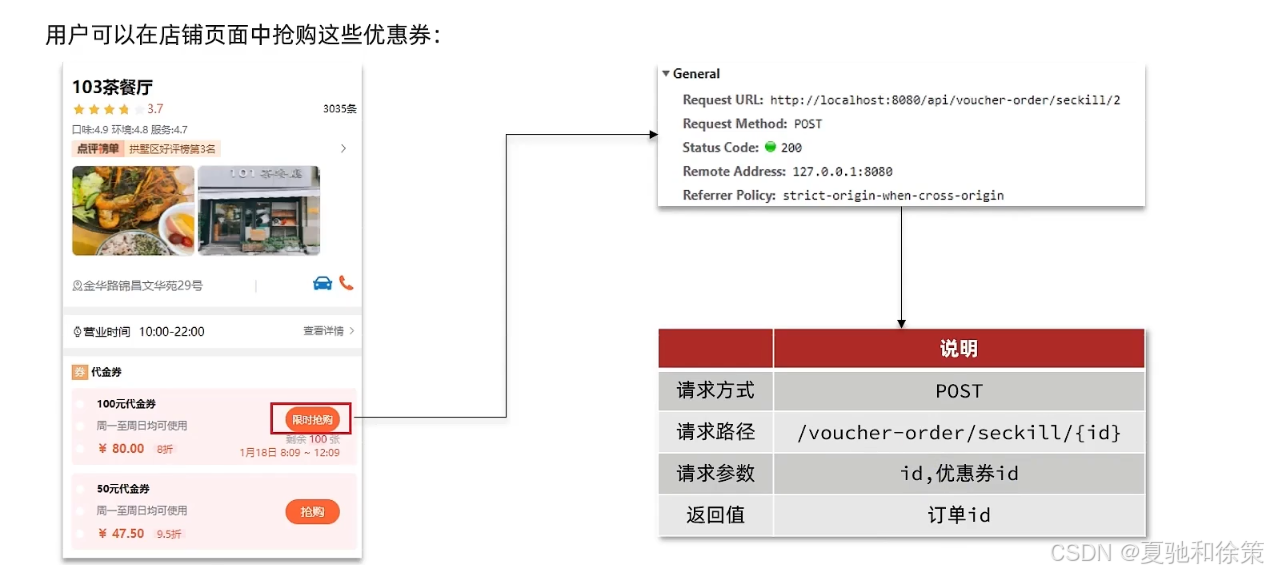
3.4 实现秒杀下单
下单核心思路:当我们点击抢购时,会触发右侧的请求,我们只需要编写对应的controller即可
秒杀下单应该思考的内容:
下单时需要判断两点:
-
秒杀是否开始或结束,如果尚未开始或已经结束则无法下单
-
库存是否充足,不足则无法下单
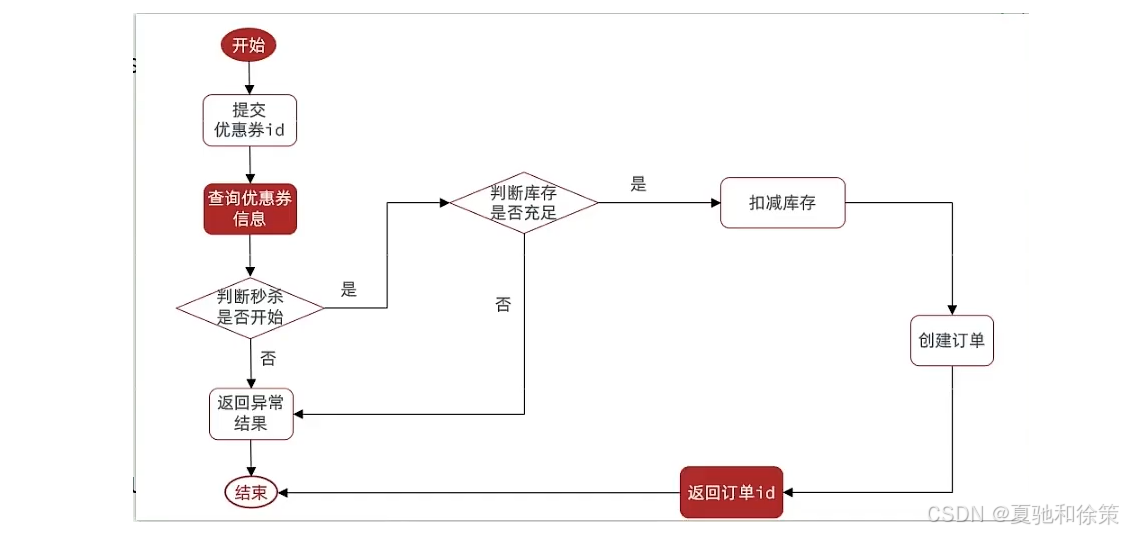
下单核心逻辑分析:
当用户开始进行下单,我们应当去查询优惠卷信息,查询到优惠卷信息,判断是否满足秒杀条件
比如时间是否充足,如果时间充足,则进一步判断库存是否足够,如果两者都满足,则扣减库存,创建订单,然后返回订单id,如果有一个条件不满足则直接结束。
VoucherOrderServiceImpl
@Override
public Result seckillVoucher(Long voucherId) {
// 1.查询优惠券
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
// 2.判断秒杀是否开始
if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀尚未开始!");
}
// 3.判断秒杀是否已经结束
if (voucher.getEndTime().isBefore(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀已经结束!");
}
// 4.判断库存是否充足
if (voucher.getStock() < 1) {
// 库存不足
return Result.fail("库存不足!");
}
//5,扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock= stock -1")
.eq("voucher_id", voucherId).update();
if (!success) {
//扣减库存
return Result.fail("库存不足!");
}
//6.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 6.1.订单id
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
// 6.2.用户id
Long userId = UserHolder.getUser().getId();
voucherOrder.setUserId(userId);
// 6.3.代金券id
voucherOrder.setVoucherId(voucherId);
save(voucherOrder);
return Result.ok(orderId);
}3.5 库存超卖问题分析
有关超卖问题分析:在我们原有代码中是这么写的
if (voucher.getStock() < 1) {
// 库存不足
return Result.fail("库存不足!");
}
//5,扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock= stock -1")
.eq("voucher_id", voucherId).update();
if (!success) {
//扣减库存
return Result.fail("库存不足!");
}假设线程1过来查询库存,判断出来库存大于1,正准备去扣减库存,但是还没有来得及去扣减,此时线程2过来,线程2也去查询库存,发现这个数量一定也大于1,那么这两个线程都会去扣减库存,最终多个线程相当于一起去扣减库存,此时就会出现库存的超卖问题。
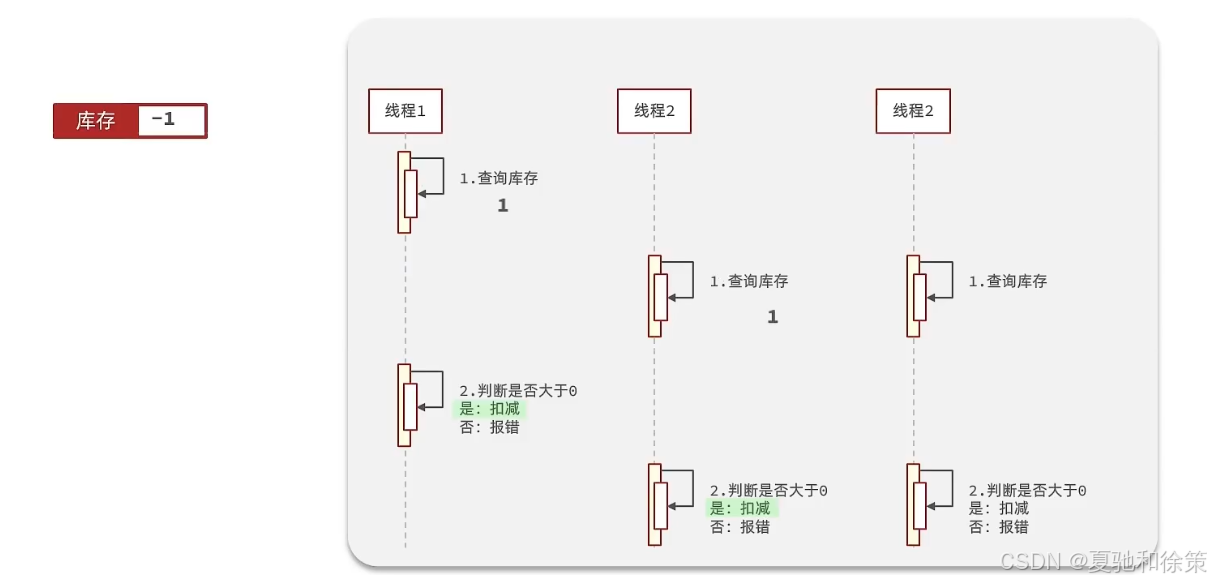
超卖问题是典型的多线程安全问题,针对这一问题的常见解决方案就是加锁:而对于加锁,我们通常有两种解决方案:见下图:
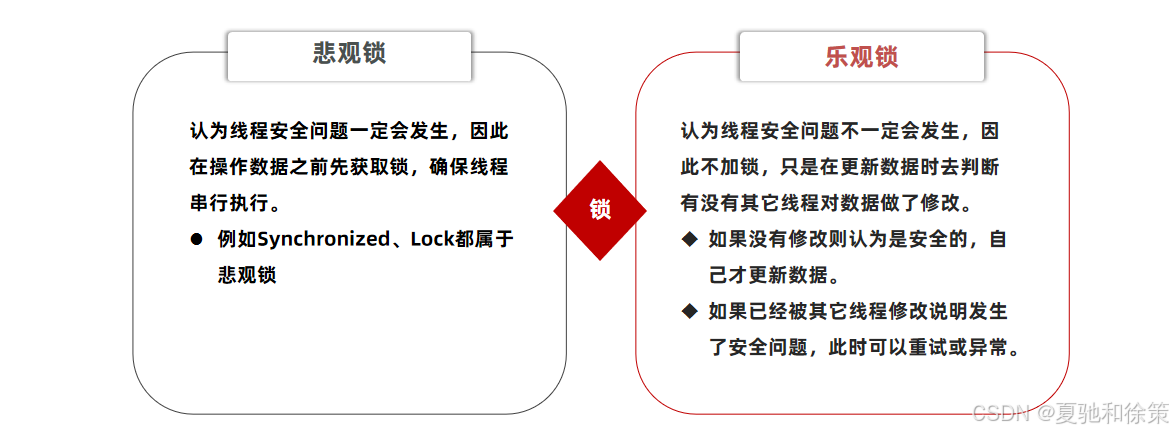
悲观锁:
悲观锁可以实现对于数据的串行化执行,比如syn,和lock都是悲观锁的代表,同时,悲观锁中又可以再细分为公平锁,非公平锁,可重入锁,等等
乐观锁:
乐观锁:会有一个版本号,每次操作数据会对版本号+1,再提交回数据时,会去校验是否比之前的版本大1 ,如果大1 ,则进行操作成功,这套机制的核心逻辑在于,如果在操作过程中,版本号只比原来大1 ,那么就意味着操作过程中没有人对他进行过修改,他的操作就是安全的,如果不大1,则数据被修改过,当然乐观锁还有一些变种的处理方式比如cas
乐观锁的典型代表:就是cas,利用cas进行无锁化机制加锁,var5 是操作前读取的内存值,while中的var1+var2 是预估值,如果预估值 == 内存值,则代表中间没有被人修改过,此时就将新值去替换 内存值
其中do while 是为了在操作失败时,再次进行自旋操作,即把之前的逻辑再操作一次。
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
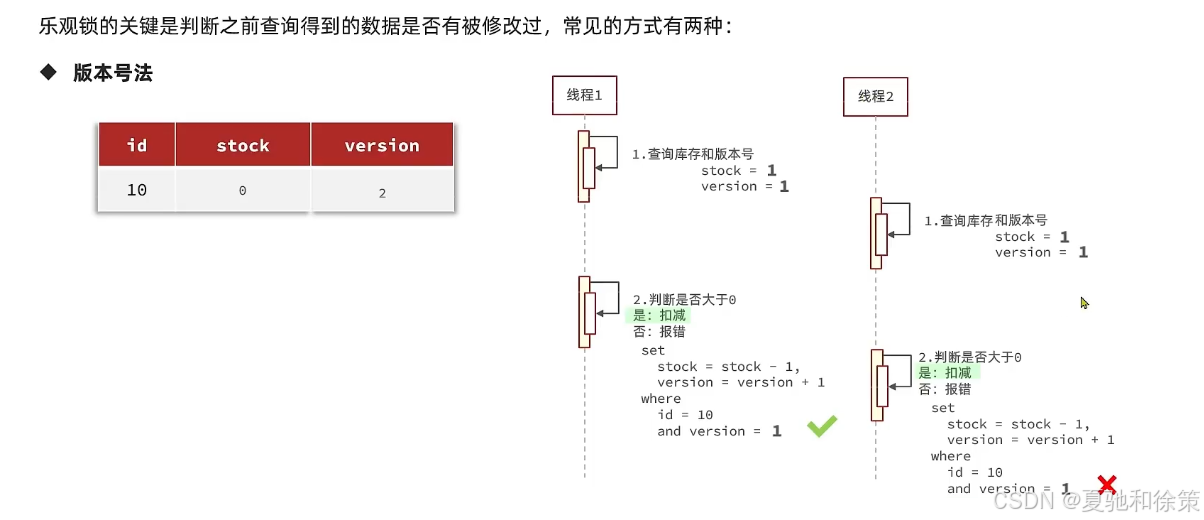
return var5;课程中的使用方式:
课程中的使用方式是没有像cas一样带自旋的操作,也没有对version的版本号+1 ,他的操作逻辑是在操作时,对版本号进行+1 操作,然后要求version 如果是1 的情况下,才能操作,那么第一个线程在操作后,数据库中的version变成了2,但是他自己满足version=1 ,所以没有问题,此时线程2执行,线程2 最后也需要加上条件version =1 ,但是现在由于线程1已经操作过了,所以线程2,操作时就不满足version=1 的条件了,所以线程2无法执行成功
❸ 库存超卖与并发安全(3.4–3.5)
Q3: 秒杀场景下,为何直接用数据库 UPDATE WHERE stock > 0 能防止超卖?这种做法的极限在哪里?
✅ 答案(分析):
UPDATE tb SET stock = stock -1 WHERE stock > 0
本质是一种乐观锁。MySQL 在执行时,先判断 WHERE 条件,再扣减 stock,避免负库存。
优势:
✅ 无需显式加锁,多个线程可并发发起更新。
✅ 一次 SQL 完成判断 + 扣减,减少网络往返。
极限问题:
⚠️ 高并发下,数据库更新操作仍需加行锁,争抢激烈时会增加事务冲突、回滚率,影响性能。
⚠️ 超高流量(如双 11 抢购)下,单库承压不足,需要用 Redis 原子扣减或分库分片。
大厂实践:核心扣减环节用缓存(Redis + Lua),减少数据库直接冲突,把数据库作为最终落库的“账本”。
❸ 库存超卖与并发安全(3.4–3.5)
场景题:
你在腾讯王者荣耀团队,做皮肤限量抢购系统。并发高达每秒数十万,怎么避免库存超卖?乐观锁和悲观锁怎么选?
✅ 高智商答案:
我会分三层优化:
1️⃣ 前端限流 → 在网关、CDN 层做请求过滤,减少后端压力。
2️⃣ 核心扣减逻辑 →
-
乐观锁(如 SQL where stock > 0)适合中低并发,但极限场景回滚率高。
-
悲观锁(如 row lock 或分布式锁)会降低吞吐,但能保证绝对安全。
-
我更推荐 Redis Lua 脚本实现原子扣减,高并发下单机 QPS 可达 10 万级。
3️⃣ 后台异步落库 → 核心扣减在缓存,最终账目落到数据库,用流水对账修正小误差。大厂工程里更重视:吞吐量 > 瞬时强一致。
✅ 第一层(缓存层):用 Redis Lua 脚本。
-
设计:
stock:<skinId>存库存数,Lua 脚本先检查库存 > 0,再扣减库存。Lua 脚本是原子操作,防止并发超卖。 -
部署:Redis 主从 + Sentinel 保证高可用。
✅ 第二层(数据库层,补充保障):用乐观锁。
-
MySQL 表设计:
skin_order表,stock字段加版本号version。 -
更新时 SQL 写
UPDATE ... WHERE stock > 0 AND version = ?,失败则回滚。 -
乐观锁适合并发较高场景,减少加锁开销。
✅ 第三层(异步化):用 MQ 异步下单,削峰填谷。
-
用户请求 → Kafka → 后台消费者扣减数据库库存 → 生成订单。
-
这样,即使 Redis 扣减失败,消息队列也能承接部分流量。
监控:
✅ 接入 Elasticsearch + Kibana 分析下单请求量、扣减失败率、MQ 堆积情况。
✅ 潜在问题:
-
❗ Redis 脚本误用:
Lua 脚本没有正确返回值或报错,库存扣减失败。
→ 解决方案: 写脚本时加严密的日志与错误返回,开发前用单元测试全面验证。 -
❗ MySQL 乐观锁高失败率:
并发太高时,大部分线程因为版本号不匹配而失败。
→ 解决方案: 先用 Redis 限流,减少到数据库的冲突请求。 -
❗ 网络延迟或超时:
高并发下,部分扣减请求在传输中超时、重发,导致重复扣减。
→ 解决方案: 接口设计幂等性 + 引入唯一请求 ID。
3.6 乐观锁解决超卖问题
修改代码方案一、
VoucherOrderServiceImpl 在扣减库存时,改为:
boolean success = seckillVoucherService.update()
.setSql("stock= stock -1") //set stock = stock -1
.eq("voucher_id", voucherId).eq("stock",voucher.getStock()).update(); //where id = ? and stock = ?以上逻辑的核心含义是:只要我扣减库存时的库存和之前我查询到的库存是一样的,就意味着没有人在中间修改过库存,那么此时就是安全的,但是以上这种方式通过测试发现会有很多失败的情况,失败的原因在于:在使用乐观锁过程中假设100个线程同时都拿到了100的库存,然后大家一起去进行扣减,但是100个人中只有1个人能扣减成功,其他的人在处理时,他们在扣减时,库存已经被修改过了,所以此时其他线程都会失败
修改代码方案二、
之前的方式要修改前后都保持一致,但是这样我们分析过,成功的概率太低,所以我们的乐观锁需要变一下,改成stock大于0 即可
boolean success = seckillVoucherService.update()
.setSql("stock= stock -1")
.eq("voucher_id", voucherId).update().gt("stock",0); //where id = ? and stock > 0知识小扩展:
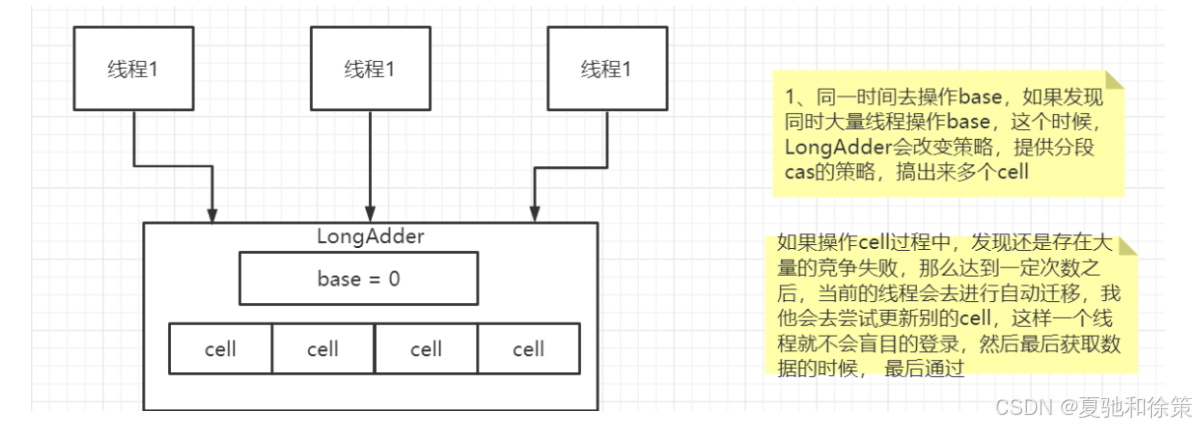
针对cas中的自旋压力过大,我们可以使用Longaddr这个类去解决
Java8 提供的一个对AtomicLong改进后的一个类,LongAdder
大量线程并发更新一个原子性的时候,天然的问题就是自旋,会导致并发性问题,当然这也比我们直接使用syn来的好
所以利用这么一个类,LongAdder来进行优化
如果获取某个值,则会对cell和base的值进行递增,最后返回一个完整的值
🧠 理论理解
一人一单是典型的业务幂等约束。
技术难点:在高并发下保证:
-
不重复下单
-
不超卖库存
同时保证性能。
单机场景 → synchronized 按 userId 锁定。
分布式场景 → 分布式锁(如 Redis 锁、Redisson),避免跨节点并发写入。
🏢 大厂实战理解
阿里:利用 userId 粒度分布式锁,配合事务,确保一人一单。
字节:用户维度上提前预判(如前置 Redis 布隆过滤器),减少写入冲突。
Google:跨区域下单场景,用 Paxos/Raft 等强一致协议确保主副本只接受一次写入。
❹ 一人一单约束(3.6)
Q4: 如何保证一个用户对同一张券只能下单一次?在高并发、集群环境下如何实现?
✅ 答案(分析):
思路上有三种方案:
1️⃣ 数据库唯一约束(userId, voucherId) → 最简单,但高并发下可能写入失败。
2️⃣ 应用层加锁 → 用 synchronized 或 Lock 按 userId 锁定,但只能在单机有效。
3️⃣ 分布式锁 → Redis SET NX 方案,按 userId 上锁,全集群互斥。
高并发、集群下推荐方案:
✅ Redis 分布式锁(用 Redisson 等高可用框架)按用户维度锁定,确保同一时刻只有一个节点的线程能成功下单。
✅ Redis 里用布隆过滤器预判、Lua 脚本 CAS 更新,可以进一步减少回写冲突。
大厂实践:绝大部分电商、抢购业务都会用“缓存判重 + 分布式锁 + 最终数据库唯一约束”三重保障。
3.6 优惠券秒杀-一人一单
需求:修改秒杀业务,要求同一个优惠券,一个用户只能下一单
现在的问题在于:
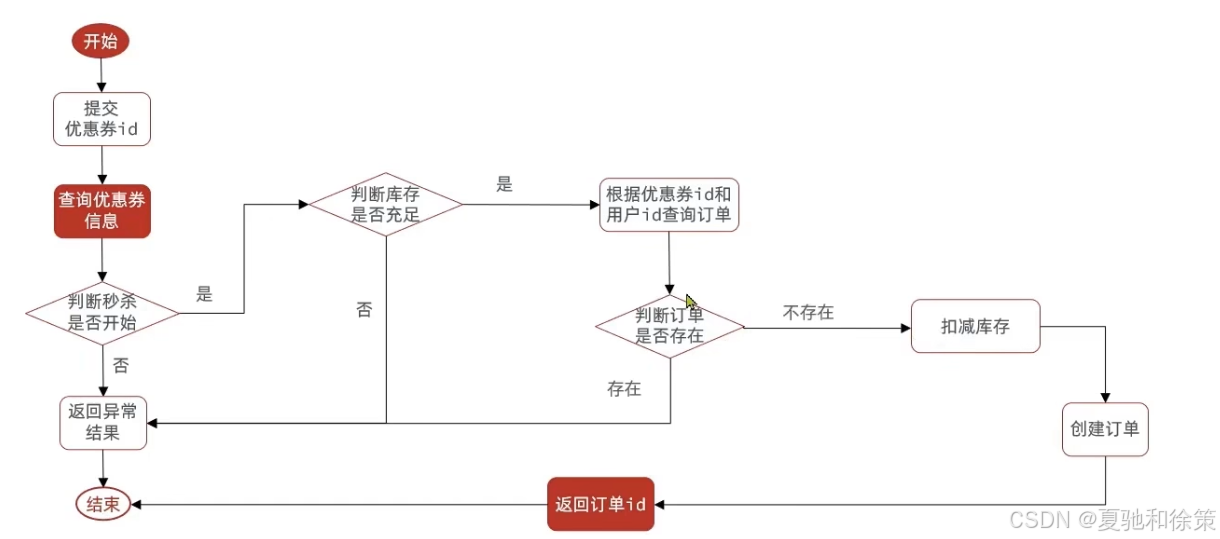
优惠卷是为了引流,但是目前的情况是,一个人可以无限制的抢这个优惠卷,所以我们应当增加一层逻辑,让一个用户只能下一个单,而不是让一个用户下多个单
具体操作逻辑如下:比如时间是否充足,如果时间充足,则进一步判断库存是否足够,然后再根据优惠卷id和用户id查询是否已经下过这个订单,如果下过这个订单,则不再下单,否则进行下单
VoucherOrderServiceImpl
初步代码:增加一人一单逻辑
@Override
public Result seckillVoucher(Long voucherId) {
// 1.查询优惠券
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
// 2.判断秒杀是否开始
if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀尚未开始!");
}
// 3.判断秒杀是否已经结束
if (voucher.getEndTime().isBefore(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀已经结束!");
}
// 4.判断库存是否充足
if (voucher.getStock() < 1) {
// 库存不足
return Result.fail("库存不足!");
}
// 5.一人一单逻辑
// 5.1.用户id
Long userId = UserHolder.getUser().getId();
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
// 5.2.判断是否存在
if (count > 0) {
// 用户已经购买过了
return Result.fail("用户已经购买过一次!");
}
//6,扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock= stock -1")
.eq("voucher_id", voucherId).update();
if (!success) {
//扣减库存
return Result.fail("库存不足!");
}
//7.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 7.1.订单id
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
voucherOrder.setUserId(userId);
// 7.3.代金券id
voucherOrder.setVoucherId(voucherId);
save(voucherOrder);
return Result.ok(orderId);
}存在问题:现在的问题还是和之前一样,并发过来,查询数据库,都不存在订单,所以我们还是需要加锁,但是乐观锁比较适合更新数据,而现在是插入数据,所以我们需要使用悲观锁操作
注意:在这里提到了非常多的问题,我们需要慢慢的来思考,首先我们的初始方案是封装了一个createVoucherOrder方法,同时为了确保他线程安全,在方法上添加了一把synchronized 锁
@Transactional
public synchronized Result createVoucherOrder(Long voucherId) {
Long userId = UserHolder.getUser().getId();
// 5.1.查询订单
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
// 5.2.判断是否存在
if (count > 0) {
// 用户已经购买过了
return Result.fail("用户已经购买过一次!");
}
// 6.扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1") // set stock = stock - 1
.eq("voucher_id", voucherId).gt("stock", 0) // where id = ? and stock > 0
.update();
if (!success) {
// 扣减失败
return Result.fail("库存不足!");
}
// 7.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 7.1.订单id
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
// 7.2.用户id
voucherOrder.setUserId(userId);
// 7.3.代金券id
voucherOrder.setVoucherId(voucherId);
save(voucherOrder);
// 7.返回订单id
return Result.ok(orderId);
},但是这样添加锁,锁的粒度太粗了,在使用锁过程中,控制锁粒度 是一个非常重要的事情,因为如果锁的粒度太大,会导致每个线程进来都会锁住,所以我们需要去控制锁的粒度,以下这段代码需要修改为: intern() 这个方法是从常量池中拿到数据,如果我们直接使用userId.toString() 他拿到的对象实际上是不同的对象,new出来的对象,我们使用锁必须保证锁必须是同一把,所以我们需要使用intern()方法
@Transactional
public Result createVoucherOrder(Long voucherId) {
Long userId = UserHolder.getUser().getId();
synchronized(userId.toString().intern()){
// 5.1.查询订单
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
// 5.2.判断是否存在
if (count > 0) {
// 用户已经购买过了
return Result.fail("用户已经购买过一次!");
}
// 6.扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1") // set stock = stock - 1
.eq("voucher_id", voucherId).gt("stock", 0) // where id = ? and stock > 0
.update();
if (!success) {
// 扣减失败
return Result.fail("库存不足!");
}
// 7.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
// 7.1.订单id
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
// 7.2.用户id
voucherOrder.setUserId(userId);
// 7.3.代金券id
voucherOrder.setVoucherId(voucherId);
save(voucherOrder);
// 7.返回订单id
return Result.ok(orderId);
}
}但是以上代码还是存在问题,问题的原因在于当前方法被spring的事务控制,如果你在方法内部加锁,可能会导致当前方法事务还没有提交,但是锁已经释放也会导致问题,所以我们选择将当前方法整体包裹起来,确保事务不会出现问题:如下:
在seckillVoucher 方法中,添加以下逻辑,这样就能保证事务的特性,同时也控制了锁的粒度

但是以上做法依然有问题,因为你调用的方法,其实是this.的方式调用的,事务想要生效,还得利用代理来生效,所以这个地方,我们需要获得原始的事务对象, 来操作事务

❹ 一人一单约束(3.6)
场景题:
在 Google Play 商店,设计限免应用抢购系统,一个账号只能抢一次。考虑分布式环境、跨地域部署,如何保证一人一单?
✅ 高智商答案:
我会综合:
✅ 前置判重:用 Redis、Memcached 记录已下单用户。
✅ 跨节点互斥:用分布式锁(如 Redis SET NX、Redisson 可重入锁)按 userId 粒度锁定。
✅ 最终一致:数据库层加唯一索引双重校验,防止极端情况下重复写入。
如果全球部署,跨区域延迟大,可用 Google Spanner 这类强一致数据库,或者分区域分配额度 + 汇总结算。
本质上,解决幂等问题,不能单靠单一层,最好是前中后台多层把关。
场景题:
Google Play 限免抢购系统,一个用户每天只能下单一次。如何保证一人一单?分布式下怎么实现?
✅ 答案(具体实现):
✅ 前置缓存:
-
Redis Key:
user:purchase:<userId>:<day>,用SETNX写入抢购标记,带 24h 过期时间。 -
如果
SETNX成功,允许下单;否则直接拒绝。
✅ 后置数据库:
-
MySQL 表上,(userId, voucherId) 建唯一索引,防止极端并发下的重复写入。
-
乐观锁或事务保证插入唯一性。
✅ 分布式锁:
-
用 Redisson 分布式锁,锁粒度为
userId,保证跨节点互斥。
优化:
-
热用户(大客户、重度玩家)单独限流,用专用缓存隔离。
-
用布隆过滤器提前预判老用户是否抢过,减少 Redis 查询量。
✅ 潜在问题:
-
❗ 分布式锁死锁:
加锁线程挂掉,锁无法释放。
→ 解决方案: 用 Redisson 带 Watchdog 自动续期,或加 TTL 的 Redis 锁。 -
❗ 锁粒度过粗:
如果锁按 voucherId 加,会导致所有用户互斥,影响吞吐量。
→ 解决方案: 锁粒度精确到userId:couponId。 -
❗ 数据库唯一索引漏掉:
如果只依赖应用层判重,极端情况下数据库可能插入重复记录。
→ 解决方案: 在userId + voucherId建唯一索引,兜底。
3.7 集群环境下的并发问题
通过加锁可以解决在单机情况下的一人一单安全问题,但是在集群模式下就不行了。
1、我们将服务启动两份,端口分别为8081和8082:

2、然后修改nginx的conf目录下的nginx.conf文件,配置反向代理和负载均衡:

具体操作(略)
有关锁失效原因分析
由于现在我们部署了多个tomcat,每个tomcat都有一个属于自己的jvm,那么假设在服务器A的tomcat内部,有两个线程,这两个线程由于使用的是同一份代码,那么他们的锁对象是同一个,是可以实现互斥的,但是如果现在是服务器B的tomcat内部,又有两个线程,但是他们的锁对象写的虽然和服务器A一样,但是锁对象却不是同一个,所以线程3和线程4可以实现互斥,但是却无法和线程1和线程2实现互斥,这就是 集群环境下,syn锁失效的原因,在这种情况下,我们就需要使用分布式锁来解决这个问题。
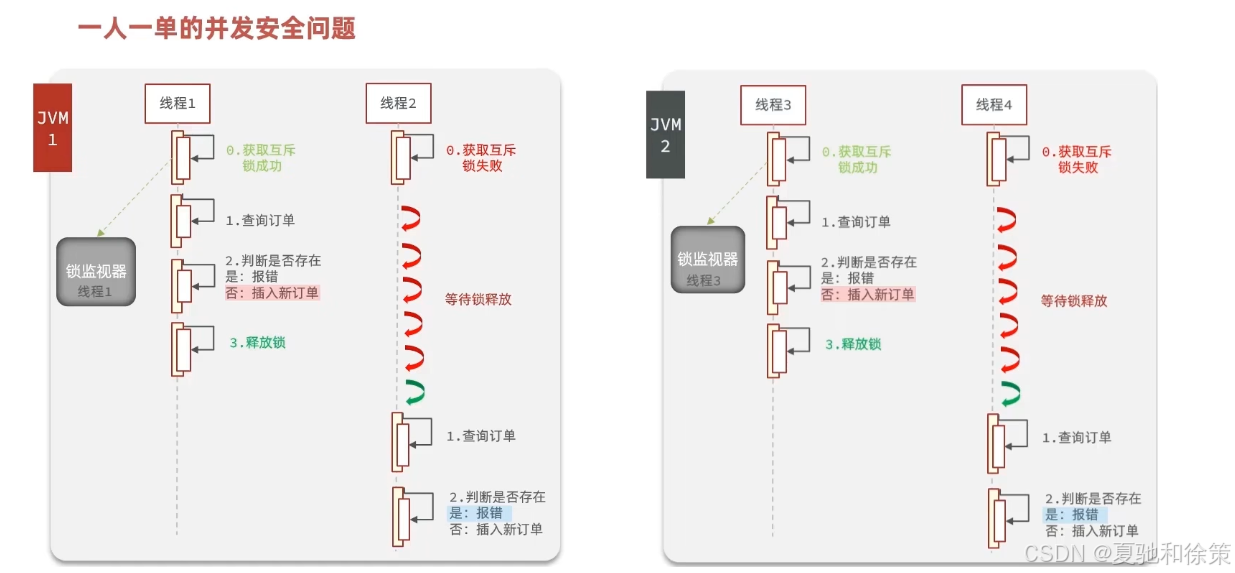
🧠 理论理解
单机内的 synchronized/Lock 只能管住当前 JVM,集群环境下必须用分布式锁。
分布式锁核心要点:
✅ 唯一性:不同节点拿到同一把锁。
✅ 安全性:锁自动续期、避免死锁。
✅ 性能:低延迟、高可用。
主流实现:基于 Redis、Zookeeper、Etcd。
🏢 大厂实战理解
阿里:用 Tair 分布式锁系统(比单纯 Redis 更高可用)。
字节:用 Redisson 配合 Redis 集群实现分布式锁,支持自动续期、可重入。
Google:用 Chubby、Spanner 锁服务做强一致分布式协调。
OpenAI:分布式任务分配,依赖 etcd + Kubernetes leader election 做锁管理。
❺ 集群环境下并发挑战(3.7)
Q5: 为什么单机锁(synchronized、ReentrantLock)在集群环境下失效?如何设计分布式锁保证跨节点互斥?
✅ 答案(分析):
单机锁只约束同一 JVM 内的线程,无法跨进程、跨机器起效。集群环境下,A 节点、B 节点的 synchronized 根本感知不到对方。
分布式锁设计要满足:
✅ 唯一性 → 全集群唯一标识(如基于 Redis Key)。
✅ 安全性 → 锁自动续期、防止死锁(如 Redisson 的 Watchdog 机制)。
✅ 可重入性 → 同线程可多次加锁、不死锁。
✅ 容错性 → 节点挂掉后,锁能自动释放。
大厂常用方案:
-
Redis 分布式锁(SET NX + EX、RedLock) → 高性能、广泛使用。
-
Zookeeper 基于临时节点的分布式锁 → 强一致、可观察,但性能稍弱。
-
Etcd/Kubernetes Leader election → 分布式调度、任务协调场景。
❺ 集群环境下并发挑战(3.7)
场景题:
在 OpenAI 多租户模型服务平台,每个客户每天只能调用 GPT 模型 1000 次。服务集群有上百个节点,你如何实现限流和并发控制?
✅ 高智商答案:
首先,我不会用单节点锁(如 synchronized),而是用全局限流方案。
✅ 全局限流:用 Redis 计数器(INCR + EXPIRE),按 tenantId 统计调用次数。
✅ 分布式锁:用 Redisson、Zookeeper、Etcd 等分布式锁工具,确保跨节点唯一性。
✅ 容错:限流规则存入配置中心(如 Apollo),系统重启后可快速恢复。
✅ 异步化:用消息队列(如 Kafka)接收调用日志,异步入库,保证最终账目可追溯。
系统设计里,限流不是单点功能,而是全链路安全和成本控制策略。
✅ 核心限流:
-
用 Redis 计数器:
gpt:tenant:<tenantId>:<day>,用INCR实现计数,EXPIRE自动过期。 -
每次调用前检查计数是否 >= 1000,超限拒绝请求。
✅ 跨节点一致性:
-
所有节点共享 Redis 集群作为限流数据中心。
-
为防止单点瓶颈,用 Redis Cluster + Redisson,自动分片、分布式高可用。
✅ 优化:
-
热租户用专门分片或独立缓存隔离,防止热点引发全局抖动。
-
异步落库,定时写入 PostgreSQL/Spanner 进行审计、对账。
-
限流策略用配置中心(如 Apollo)管理,支持动态调配。
✅ 潜在问题:
-
❗ 单节点限流失效:
用内存计数或单节点 Redis,集群部署后各节点互相不认。
→ 解决方案: 用 Redis Cluster、分布式限流组件(如 Sentinel、Envoy 限流器)。 -
❗ 分布式锁误释放:
如果 Redis 锁用DEL,但 key 被别的线程误删,可能提前放锁。
→ 解决方案: 锁 value 用 UUID 或线程 ID,释放时比对,确保自己释放自己的锁。 -
❗ 大规模节点同时续期压力:
Redisson Watchdog 自动续期可能带来 Redis 高频操作。
→ 解决方案: 合理设置锁超时时间,减少续期频率。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











