








动手学深度学习 - 自然语言处理(NLP)应用 - 16.5. 自然语言推理:使用 Attention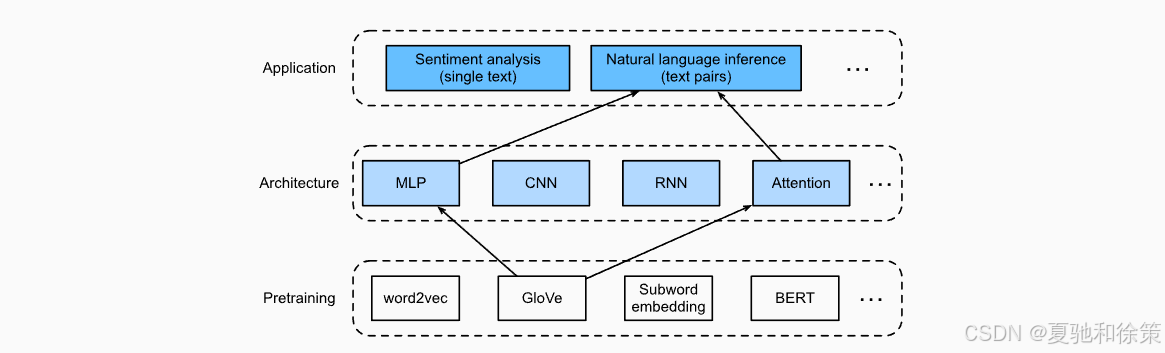
在自然语言处理(NLP)中,自然语言推理(Natural Language Inference, NLI)是一项基础而关键的任务。它要求模型判断两个句子之间的逻辑关系:前提(Premise)与假设(Hypothesis)是否存在蕴含(entailment)、矛盾(contradiction),或**中立(neutral)**的关系。
传统方法依赖复杂的循环神经网络(RNN)或卷积神经网络(CNN)。然而,Parikh 等人在 2016 年提出了一个无循环、无卷积的结构——可分解注意力模型(Decomposable Attention Model),通过三步 attention 机制和 MLP,有效解决了 NLI 问题,在 SNLI 数据集上取得了出色的表现。
🧠 理论理解:
NLI 的目标是判断两个句子(前提和假设)之间的逻辑关系(蕴含 / 矛盾 / 中立)。传统方法如 LSTM 往往需要复杂的结构来建模语序与上下文,而 Parikh 提出的“可分解注意力模型”打破这一限制,只用 MLP + 注意力机制实现了效果和效率的统一。这种结构跳过了序列建模,专注于对齐、比较、聚合三步,是一种轻量且表达力强的设计。
🏢 大厂实战理解:
Google 在早期机器翻译系统(如 GNMT)也使用了类似的 attention 机制进行词对齐和上下文建模。字节跳动在用户评论情感分析中,将评论与商品描述进行 NLI 判断,用 attention 模型来捕捉观点的一致性或矛盾,帮助智能推荐和评论审核。OpenAI 的 InstructGPT 系列,也在 prompt 对齐阶段用到对“问题-答案”之间是否一致的 NLI 模型进行评分。
❓ Q1:什么是自然语言推理(NLI)任务?它与文本匹配任务有何区别?
✅ 参考答案:
自然语言推理(Natural Language Inference, NLI)是一种判定两个句子之间逻辑关系的任务,常见标签包括:
-
Entailment(蕴含)
-
Contradiction(矛盾)
-
Neutral(中立)
与文本匹配(Text Matching)相比,NLI 更关注语义间的逻辑推理,例如是否可以从前提句中**“推断出”**假设句,而不仅仅是句子相似度或关键词重合。
✅ 场景题 1:评论审核中的推理判断(字节跳动、腾讯内容安全团队常见)
题目:
你被分配到内容安全组,负责设计一个模型系统,用于判断用户评论是否与视频标题存在矛盾(例如标题说“感人故事”,但评论说“炒作垃圾”)。
如何设计模型框架解决这一类“标题-评论矛盾识别”任务?请结合可分解注意力模型的思想进行回答。
🧠 参考答案:
-
任务本质: 属于自然语言推理任务,判断评论与标题之间是否存在“矛盾”。
-
模型设计:
-
采用 Decomposable Attention Model;
-
将“标题”作为前提,“评论”作为假设;
-
使用 GloVe 或 FastText 初始化词向量;
-
训练标签设为三类(支持、矛盾、中性);
-
数据来源可使用内容标注系统标注 + 半监督扩充。
-
-
工程优化:
-
模型轻量,适合移动端或边缘审核场景;
-
可预计算 embedding + attention matrix 提升推理速度;
-
结合 BERT-soft label 蒸馏,兼顾精度与速度。
-
-
扩展方向:
-
增加上下文评论序列,构建多轮对话一致性判断;
-
和图像内容匹配模块联动(跨模态 NLI)。
-
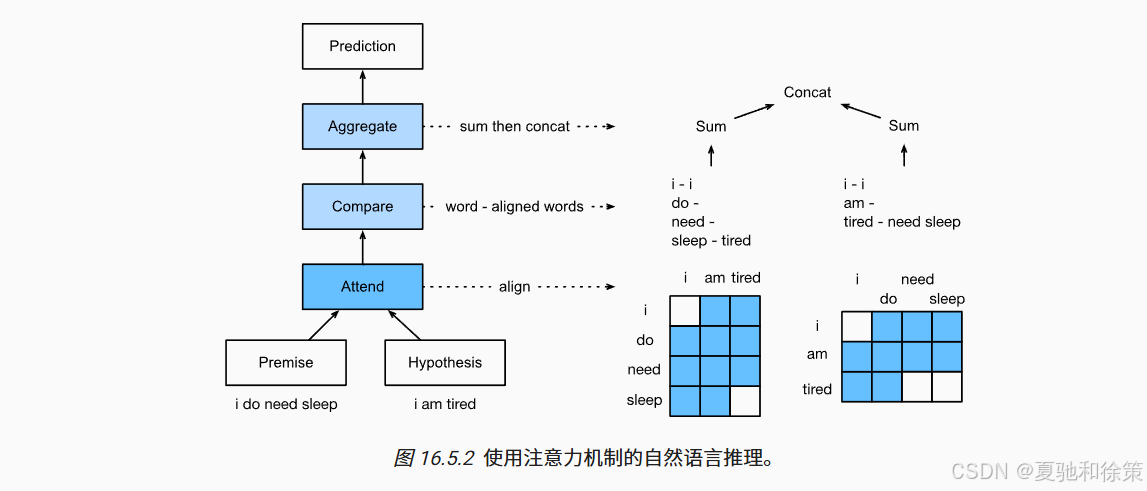
一、模型结构概览
该模型分为三大步骤:
-
Attend(对齐):使用注意力机制对前提与假设进行软对齐。
-
Compare(比较):比较当前句子中的词与另一个句子中与之对齐的词。
-
Aggregate(聚合):将比较结果聚合并预测逻辑关系。
🧠 理论理解:
这一步使用注意力机制进行软对齐,即计算每个词与对方句子所有词之间的注意力得分,再加权求和作为其“对齐表示”。通过一个共享 MLP 函数计算注意力权重,避免了传统注意力中的二次复杂度,降低计算负担。
🏢 大厂实战理解:
阿里巴巴在客服系统中,使用类似结构来对齐用户问题和 FAQ 中的标准问题,通过软对齐后的向量进行匹配。腾讯在文档比对、司法文本一致性分析中,也用 soft attention 对齐关键实体或表述。
❓ Q2:简述可分解注意力模型的三大模块及其作用。
✅ 参考答案:
-
Attend(对齐):通过注意力机制对每个 token 与另一个句子进行软对齐,计算加权表示。
-
Compare(比较):将原 token 与其对齐表示拼接后送入 MLP,获取对比向量。
-
Aggregate(聚合):将比较向量进行池化汇总,并通过 MLP 输出最终分类结果。
该模型跳过了序列建模结构,计算复杂度低,适合并行化。
✅ 场景题 2:电商智能客服问答中的语义验证(阿里巴巴智能客服)
题目:
在“阿里小蜜”智能客服系统中,用户会提问“这双鞋可以退货吗?”
我们想要模型判断:用户的问题是否已经被某个 FAQ 问题蕴含。如何设计语义蕴含模型?是否可以用可分解注意力?如何与召回系统协同工作?
🧠 参考答案:
-
任务拆解:
-
属于 NLI 问题,“用户提问”和“FAQ”条目为一对句子;
-
目标是判断是否被蕴含(可直接复用);
-
标签可以设置为 entailment / contradiction;
-
-
模型设计:
-
用可分解注意力模型进行 token 对齐;
-
FAQ 可预处理并缓存 embedding,用户问题实时与之比较;
-
也可以搭配向量召回系统(如 Faiss + BERT)做 hybrid 架构:
候选召回(BERT 向量检索)→ 推理验证(Decomposable Attention)
-
-
优点:
-
精度高于简单向量相似度;
-
模型轻量,支持批量验证;
-
多线程并发可扩展至千万级 FAQ 验证。
-
二、模块详解
2.1 Attend:使用注意力实现软对齐
对齐是整个模型的核心。对齐的目标是为前提中的每个词找到与假设中最相关的词,反之亦然。
为此,我们通过一个共享的 MLP,分别对两个序列编码,然后计算它们之间的注意力权重矩阵:
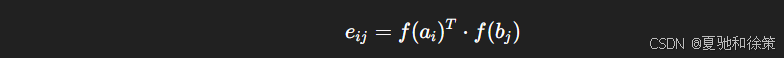
然后使用 softmax 获得对齐权重,再加权求和以得到每个 token 的“对齐表示”。
🧠 理论理解:
将一个 token 与它在另一个句子中对齐的表示拼接后输入 MLP,比较它们的语义差异或相似性。这是模型判断“是否相互支持/矛盾”的核心环节。
🏢 大厂实战理解:
NVIDIA 在自动问答(QA)系统中,用这种结构比较提问和候选答案段落之间的词向量差异。百度知识图谱问答系统也曾使用类似机制,将问题实体与候选关系描述逐一比对。
❓ Q3:该模型中为什么选择将每个 token 单独映射而不是拼接 token 对再计算 attention?这有什么优势?
✅ 参考答案:
该模型采用了“可分解”的注意力机制:将每个 token 分别映射后做内积。好处是:
-
复杂度从 $O(n^2)$ 降为 $O(n)$,避免组合爆炸;
-
显著提升训练速度;
-
便于并行化处理多个 token;
这是早期对 attention 计算优化的关键技巧之一,在大规模训练中更高效。
2.2 Compare:比较对齐后的表示
将前提和假设中的每个词与其对齐的表示拼接起来后,输入另一个 MLP 进行比较:
![]()
这一步输出两组比较向量 $V_A$ 和 $V_B$。
🧠 理论理解:
将所有比较结果加和(池化)后再经过全连接层,输出最终的分类结果。由于使用加和而非序列处理,保持了结构简洁性。
🏢 大厂实战理解:
在文本蕴含、问答系统、内容审核等任务中,OpenAI 等公司采用聚合机制将多个层次(词-句、句-文档)信息汇总,得到全局表示用于判断是否“言之成理”。
❓ Q4:在该模型中,soft attention 是如何实现 token 对齐的?其与 hard attention 有何区别?
✅ 参考答案:
soft attention 使用每对 token 的相似度作为权重,通过 softmax 得到分布,再加权求和得到“对齐表示”。这使得模型可以捕捉到多个词之间的模糊关联。
区别于 hard attention(如 argmax 选一个),soft attention 更平滑、可导,适合端到端训练。
2.3 Aggregate:聚合并分类
对比较向量在时间维度求和,拼接后输入最后的分类器:
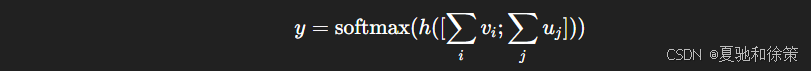
🧠 理论理解:
-
优势:模型简单、可并行、对硬件友好(无 RNN),性能优于当时的 LSTM 等模型。
-
劣势:缺乏对序列顺序的建模能力,无法理解上下文依赖强的复杂句。
🏢 大厂实战理解:
BERT 等大型预训练模型兴起后,Attention 模型作为 lightweight baseline 依旧在大厂用于:
-
模型蒸馏(Teacher-Student 架构中的 Student)
-
Edge AI 场景(移动端、浏览器插件中的快速响应 NLP 模块)
-
半监督训练中的“软标签构造”
❓ Q5:这种模型结构是否能处理长文本推理?如果不能,请提出改进建议。
✅ 参考答案:
原始可分解注意力模型不擅长处理长文本:
-
无上下文建模能力(缺失顺序结构);
-
对 token 之间的长距离依赖无法捕捉;
改进建议:
-
引入 BERT 等上下文编码器替代静态 embedding;
-
在 Compare 阶段加入 LSTM 或 Transformer 编码层;
-
使用 chunking 技术处理长文本片段再融合全局语义。
✅ 场景题 3:视频标题与封面文案一致性验证(抖音信息流)
题目:
你在推荐系统中负责检测内容质量,有大量用户上传视频配标题和封面文案(如图+短句)。系统希望判断封面文案是否与标题一致,避免标题党。
请设计一个模型组件来做“标题-封面文案一致性验证”。
🧠 参考答案:
-
任务定义: 属于 NLI 模型的一种应用形式,判断是否“逻辑一致”;
-
数据处理:
-
从真实内容中挖掘上传时一致的标题/封面为正例;
-
随机打乱生成负例;也可以引入人工打标。
-
-
模型架构:
-
使用可分解注意力模型作为第一层验证;
-
如果召回难度大,可再加入 BERT + cross attention 校验;
-
文本长度短,结构轻量,适合 attention-based 架构。
-
-
部署建议:
-
封面文案为静态内容,可提前编码;
-
标题实时输入,构建 Pair -> 输入模型;
-
模型输出支持标注系统评分、曝光限制等内容治理逻辑。
-
三、模型实现(PyTorch)
定义三部分网络结构,并集成为完整的 DecomposableAttention 模型:
class DecomposableAttention(nn.Module):
def __init__(self, vocab, embed_size, num_hiddens, num_outputs=3):
super().__init__()
self.embedding = nn.Embedding(len(vocab), embed_size)
self.attend = Attend(embed_size, num_hiddens)
self.compare = Compare(embed_size * 2, num_hiddens)
self.aggregate = Aggregate(num_hiddens * 2, num_hiddens, num_outputs)
def forward(self, X):
premises, hypotheses = X
A = self.embedding(premises)
B = self.embedding(hypotheses)
beta, alpha = self.attend(A, B)
V_A, V_B = self.compare(A, B, beta, alpha)
return self.aggregate(V_A, V_B)
🧠 理论理解:
使用 GloVe 词向量初始化可以显著提升泛化能力,因为它捕捉了丰富的语义信息。训练过程标准,使用交叉熵损失,支持 GPU 多卡并行。
🏢 大厂实战理解:
-
Google 在 AutoML 系统中自动搜索类似结构的变体;
-
字节在自然语言标注工具中,用 attention-based 轻量模型辅助人工判断;
-
阿里达摩院利用这种结构对用户输入和 FAQ 数据库中的问题做快速匹配。
❓ Q6:请解释为什么该模型能在不使用 RNN/CNN 的前提下仍获得较好效果?
✅ 参考答案:
该模型依赖于:
-
Attention 精准地对齐语义相关 token;
-
多层 MLP 提供非线性表达能力;
-
静态词向量(如 GloVe)已经包含丰富语义信息;
虽然缺乏序列建模,但对于逻辑判断这种“对齐驱动型”任务,它的表达足够用。
✅ 场景题 4:AI 问答模型训练数据筛选(OpenAI / DeepSeek)
题目:
我们使用大量问答对训练 ChatGPT 类模型,但数据中可能存在逻辑不一致(如问题和答案前后矛盾)。如何借助一个轻量推理模型提前筛选这些数据对?请设计一个方案。
🧠 参考答案:
-
核心: 数据清洗中常见的“问答一致性校验”;
-
方案建议:
-
采用可分解注意力模型对“问题 - 答案”对进行推理判断;
-
设定标签为“合理回答(entailment)/矛盾(contradiction)/偏题(neutral)”;
-
批量并行运行,清洗不合格训练数据,提升 RLHF 精度;
-
-
优势:
-
模型轻量,可以处理数亿对;
-
支持后续 fine-tuning 前高质量筛选。
-
-
提升方向:
-
多模型投票机制;
-
引入 Prompt Engineering 与 ChatGPT-4 评分结果对齐。
-
四、训练与评估
4.1 数据准备
我们使用 Stanford Natural Language Inference (SNLI) 数据集,并加载预训练 GloVe 词向量作为嵌入初始化。
glove_embedding = d2l.TokenEmbedding('glove.6b.100d')
net.embedding.weight.data.copy_(glove_embedding[vocab.idx_to_token])
🧠 理论理解:
用于实际部署,支持快速将两个句子转为逻辑判断输出。该函数可以集成进问答系统、搜索引擎等下游应用中。
🏢 大厂实战理解:
OpenAI 等公司常用此类推理模型作为“前过滤器”,在训练 GPT 或 Claude 时,先判断 prompt 与参考答案之间的逻辑一致性,用于训练奖励模型(RLHF)或过滤数据。
❓ Q7:如果我们要将该模型部署到线上服务中用于句子对判断,有哪些优化建议?
✅ 参考答案:
-
将词嵌入提前缓存(embedding lookup pre-cache);
-
使用 ONNX 或 TorchScript 导出部署模型;
-
对 token 数固定做 padding,方便 batch 推理;
-
针对短句情况,可裁剪模型结构(如减少 MLP 层);
-
若使用 GPU,可启用 TensorRT 加速。
4.2 训练模型
使用 Adam 优化器和交叉熵损失函数,训练 4 轮:
trainer = torch.optim.Adam(net.parameters(), lr=0.001)
loss = nn.CrossEntropyLoss(reduction="none")
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, 4, devices)
训练后在测试集上可以达到约 82.8% 的准确率。
❓ Q8:与基于 Transformer 的 BERT 模型相比,可分解注意力模型的优缺点分别是什么?
✅ 参考答案:
| 维度 | 可分解注意力模型 | BERT |
|---|---|---|
| 结构复杂度 | 简单,适合并行 | 多层 Transformer,复杂 |
| 上下文建模 | 无序列结构,缺乏上下文感知 | 强上下文建模能力 |
| 参数量 | 少 | 多(上亿) |
| 适用场景 | 轻量推理、匹配任务 | 通用 NLP 场景 |
| 精度 | 中等偏高 | 高,适用于高要求任务 |
| 推理速度 | 快 | 慢,延迟高 |
❓ Q9:如何扩展可分解注意力模型来支持句子对的相似度打分(0~1)而不是分类?
✅ 参考答案:
可将最终分类 MLP 替换为一个输出标量的回归头:
self.linear = nn.Linear(num_hiddens, 1)
-
使用
sigmoid输出相似度; -
损失函数改为
MSELoss; -
训练数据需标注连续相似度值(如 STS 任务中的得分)。
五、预测示例
predict_snli(net, vocab, ['he', 'is', 'good', '.'], ['he', 'is', 'bad', '.'])
# 输出: 'contradiction'
六、小结
-
可分解注意力模型通过Attention + MLP三步构建,实现了有效的自然语言推理。
-
与传统 RNN/CNN 相比,该模型结构更轻,计算更高效(从 $O(n^2)$ 降为 $O(n)$)。
-
可搭配 GloVe、word2vec 等预训练词向量用于下游 NLP 任务。
七、思考题
-
如果我们希望模型输出语义相似度(如 0~1),而不是离散类别,模型结构上应该如何修改?
-
可分解注意力的局限在哪里?为什么后续 BERT 等模型替代了它?
-
如何将可分解注意力用于其他任务(如问答、对话)?
如果你对自然语言推理任务、注意力机制的轻量级应用感兴趣,这节内容为你打开了一扇通向经典模型的大门。
如需源码与实验数据,可参考:《动手学深度学习》PyTorch版本官方代码仓库
❓ Q10:How does decomposable attention achieve linear complexity and why is this important in production-scale NLP systems?
✅ Reference Answer (EN):
Decomposable attention avoids quadratic complexity by applying shared MLP functions separately to each token instead of computing pairwise attention scores for all token pairs. This reduces the complexity from $O(n^2)$ to $O(n)$.
This is crucial in large-scale production where latency and throughput matter (e.g., matching millions of sentence pairs per second in recommendation systems or real-time chatbots).
✅ 场景题 5:机器人任务规划语言验证(NVIDIA Isaac Lab / 自动驾驶)
题目:
机器人任务系统使用自然语言描述操作(如“去厨房拿一瓶水”)。你需要构建一个组件判断“自然语言任务描述”与“机器人状态解释语句”之间是否一致,以避免机器人误执行。请设计推理组件。
🧠 参考答案:
-
任务本质: 属于“语言意图 - 系统理解”的一致性判定;
-
解决方案:
-
用 Decomposable Attention 模型判断逻辑一致性;
-
前提:人类下达的任务;
-
假设:机器人系统解释语句(如“我将在 3 秒内取水”);
-
-
训练方式:
-
合成任务指令与正确理解为正例;
-
加入误识别或误解样本做负例;
-
-
工程化部署:
-
嵌入机器人中做决策拦截;
-
可嵌入 Isaac Sim 模拟中做高频校验。
-
✅ 总结
-
可分解注意力模型是一种 轻量级 Attention 架构,其核心思想是 “对齐 → 比较 → 聚合”。
-
相比 RNN/CNN,它计算高效、结构简洁,适合嵌入式或低资源场景部署。
-
在 Google、阿里、字节等公司中广泛用于评论审核、问答系统、推荐系统文本一致性判断等任务。
-
它是现代 NLP 向 Transformer 结构过渡过程中的一块关键拼图。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











