








📘 统计学习方法 - 1.4 模型评估与模型选择
在机器学习中,模型评估与选择是理解泛化能力、避免过拟合的核心环节。本节将结合《统计学习方法》的内容,对第1.4~1.5节进行深入解读,帮助大家掌握训练误差、测试误差、过拟合、模型复杂度等关键概念。
✏️ 1.4.1 训练误差与测试误差
📌 定义理解
在监督学习中,模型的最终目的是希望在未见过的新样本上也能有良好的预测能力,这就是所谓的泛化能力(generalization ability)。
为了衡量模型的性能,我们通常将样本数据划分为训练集和测试集:
-
训练误差(Training Error):模型在训练集上的平均损失。
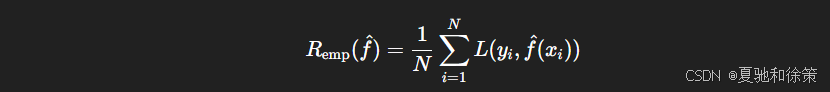
-
测试误差(Test Error):模型在测试集上的平均损失。
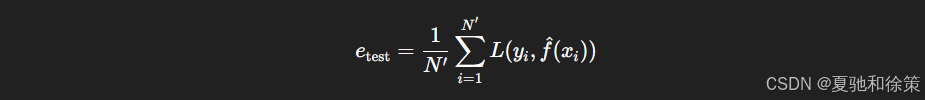
其中 L(y,y^)L(y, \hat{y}) 是损失函数,常见的有0-1损失、平方损失等。
✅ 常见评价指标
-
错误率(Error Rate):
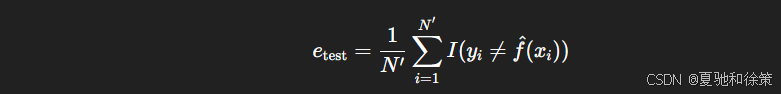
-
准确率(Accuracy):
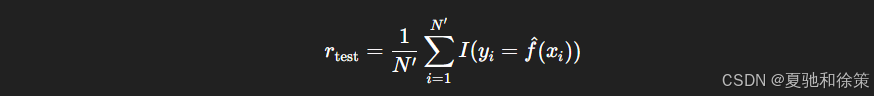
其中 I(⋅)I(\cdot) 是指示函数。
🔍 结论:
训练误差不是越小越好,关键是测试误差的表现。只有测试误差低,模型才具备良好的泛化能力。
🧠 理论理解
训练误差与测试误差的划分,体现了统计学习中拟合与泛化之间的本质矛盾:
-
训练误差衡量模型对已知数据的拟合能力;
-
测试误差衡量模型在未知数据上的预测能力,也就是泛化能力。
这部分强调:低训练误差不等于好模型,真正重要的是低测试误差。
另外,通过引入错误率与准确率,体现了监督学习中分类问题的常见评价指标的定义方法。
🏢 企业实战理解
在字节跳动、百度推荐系统中,模型经常面临离线 AUC 高、上线 CTR 下降的现象,其根本原因正是测试误差估计不准导致的“离线好,线上差”。
为此企业常用的手段包括:
-
将训练集和验证集严格时间切割(模拟线上真实分布);
-
构建更大规模的 hold-out 测试集;
-
用在线 A/B 实验测试真实“测试误差”。
因此,训练误差只是“造轮子”的第一步,测试误差才是“轮子能不能跑”的真正标准。
🎯 面试题一:什么是训练误差和测试误差?它们之间有何区别?
**面试官意图:**考察你是否理解机器学习的核心评估指标及泛化能力。
参考答案:
-
训练误差(Training Error): 指模型在训练集上产生的平均损失,用于衡量模型对已知数据的拟合能力。
-
测试误差(Test Error): 指模型在未见过的测试集上的平均损失,衡量模型的泛化能力。
区别:训练误差低不代表模型好,只有测试误差低,才能说明模型泛化能力强,是优质模型。
追问延展:
-
为什么有时候训练误差为0,测试误差却很高?(提示:过拟合)
-
有哪些策略可以降低测试误差?(正则化、交叉验证、数据增强等)
🧪 场景题 1:字节跳动推荐系统中的模型泛化异常
题目描述:
你在字节跳动的推荐算法团队,负责优化一个短视频推荐模型。近期上线的模型在训练集上表现优异,Loss 降得非常快,但上线后点击率(CTR)反而下降,用户平均观看时长也变短。
团队初步怀疑是模型过拟合导致的泛化能力下降。
请回答:
-
你如何确认是否真的发生了过拟合?
-
如果是,你将采取哪些技术手段缓解过拟合?
-
你会如何重新选择或设计模型,提升泛化能力?
参考答案:
✅ 1. 确认过拟合:
-
检查训练误差 vs 验证误差:
-
若训练误差持续下降而验证误差升高,说明过拟合。
-
-
检查模型的复杂度(embedding size, 层数, 参数量);
-
查看用户维度的 A/B 结果分布:
-
如果只在“老用户”群体表现好,说明模型记住了历史偏好而不具备泛化能力。
-
✅ 2. 缓解过拟合策略:
-
加入正则化(L2、dropout);
-
使用 early stopping:
-
如果验证集 loss 多轮不下降,就提前停止训练;
-
-
使用更少参数或浅层模型(降低模型复杂度);
-
引入对抗训练或数据增强(如在 embedding 上添加噪声);
-
引入 batchnorm 层进行稳定化。
✅ 3. 模型选择优化:
-
尝试 Wide&Deep 等结构:Wide 提升泛化能力,Deep 负责拟合复杂模式;
-
进行 embedding size 搜索、层数搜索,使用交叉验证选最优结构;
-
在验证集上评估 AUC、NDCG、P@K 等指标,综合评估模型稳定性。
✨ 工程价值观补充:
模型不是训练误差越低越好,真正重要的是能否在“明天的推荐”中继续保持预测能力,即泛化性。
✏️ 1.4.2 过拟合与模型选择
🎯 什么是模型选择?
模型选择(Model Selection)是指在多个模型中挑选最优模型的问题,通常考虑模型的复杂度、泛化能力等因素。一个简单例子是从多项式模型中选择合适的次数 MM。
-
模型越复杂(例如高次多项式),训练误差可能越小;
-
但测试误差可能会因为过拟合而变大。
📉 过拟合的例子与图示
假设我们用多项式函数拟合一组数据:
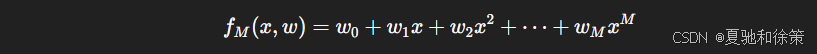
并定义损失函数:
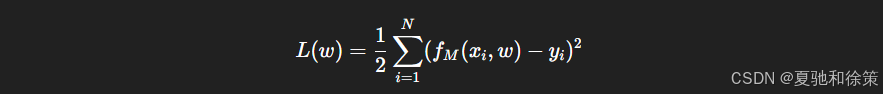
通过最小化损失函数,可以计算出最优的参数 wjw_j:
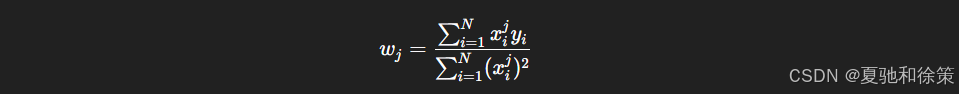
如下图(图 1.2)所示:
-
当 M=0M = 0,模型过于简单,拟合效果差;
-
当 M=3M = 3,拟合效果较好,测试误差最低;
-
当 M=9M = 9,尽管训练误差几乎为 0,但测试误差急剧上升 → 出现过拟合。
🧠 理论理解
本节是整个模型评估的关键核心 —— 如何根据测试误差选择最优模型。关键概念有:
-
模型复杂度:参数数目、函数形式的灵活性;
-
过拟合(overfitting):模型对训练集学习过头,记住了噪声;
-
欠拟合(underfitting):模型太简单,学习不到数据结构;
-
模型选择的目标:找到复杂度刚好,使得测试误差最小的模型。
通过多项式拟合的例子(图1.2),形象展示了:复杂度过小、过大都会带来预测风险。
🏢 企业实战理解
在工业界,模型选择主要靠验证集性能 + 线上指标,比如:
-
阿里搜索团队在商品点击预测中,尝试过不同深度的神经网络;
-
当网络层数过深时,训练集准确率接近 100%,但测试集 AUC 反而下降;
-
-
Google 在 BERT 微调阶段会使用 dev set 检查 loss 下降是否稳定,否则回退到之前的 checkpoint;
-
在大模型训练中(如 GPT),选择 best checkpoint 时往往依赖验证集 perplexity,而不是训练 loss。
结论是:泛化性能始终是第一指标,甚至可以牺牲一些训练精度。
🎯 面试题二:请解释过拟合和欠拟合的区别,并给出实际例子
参考答案:
-
过拟合(Overfitting): 模型过度学习训练数据中的噪声,导致在测试集上表现差;
-
欠拟合(Underfitting): 模型过于简单,无法捕捉训练数据的内在规律。
例子:
用高阶多项式拟合少量数据点时(如 M=9 拟合10个样本),训练误差趋近于0,但在新数据上误差很大,这是典型过拟合。
企业场景补充:
在字节跳动推荐系统中,embedding size 设置过大时,经常会出现 overfitting 现象,测试AUC反而下降。工程上会设置正则项限制模型复杂度,或采用 early stop 策略。
🧪 场景题 2:阿里搜索召回系统的模型切换抉择
题目描述:
你在阿里巴巴搜索算法组,负责从多个召回模型中选择一个用于双11活动。你已经训练了如下三种模型:
-
模型 A:多项式回归,训练误差低,测试误差略高;
-
模型 B:深度神经网络,训练误差极低,但测试误差大;
-
模型 C:树模型(XGBoost),训练误差适中,测试误差最低但训练较慢。
问题:
-
你会如何评估这三个模型的选择?
-
若选择模型 C,但双11当日线上 QPS 升高严重,你会做哪些优化?
参考答案:
✅ 1. 模型选择策略:
-
优先选择模型 C,因为其测试误差最低,泛化能力强;
-
模型 A 测试误差偏高,可能欠拟合;
-
模型 B 虽训练误差极低但测试误差大,存在过拟合,不宜上线;
-
综合考虑 latency/QPS,可对 C 进行加速。
✅ 2. 优化思路(上线部署):
-
使用模型压缩技术(例如 XGBoost 的量化、剪枝);
-
利用离线预召回:部分计算前置到离线;
-
模型蒸馏:用小模型 mimic 大模型输出;
-
建立多级召回结构:
-
一级粗召回(轻量模型),二级精召回(复杂模型);
-
-
引入缓存或向量索引加速策略(如 Faiss)。
✏️ 1.5 正则化与交叉验证(引入)
📈 模型复杂度与误差的关系
如图 1.3 所示:
-
随着模型复杂度提升:
-
训练误差下降;
-
测试误差先降后升,形成一个“U型”曲线;
-
-
最佳模型应当处于测试误差最小点(即泛化能力最强)。
🎯 目标是: 找到既不过拟合也不欠拟合的“黄金模型”。
🧠 理论理解
这一节的图 1.3 直观揭示了一个重要结论:
模型复杂度提高时,训练误差会持续下降,而测试误差呈现先下降后上升的“U 型”趋势。
目标就是找到这个“谷底”,即最小测试误差对应的模型复杂度。
这也正是偏差-方差权衡的典型体现:
-
偏差大 → 欠拟合
-
方差大 → 过拟合
最优模型应当在二者之间取得平衡。
🏢 企业实战理解
在真实业务中:
-
字节跳动推荐系统会基于模型复杂度(如 embedding size、神经网络层数)画出一条类似图1.3的“泛化曲线”;
-
腾讯广告部门曾用正则化策略防止过拟合,包括 L2 正则、dropout、early stopping;
-
OpenAI 在大模型训练中,也会设定“验证集指标停滞超过 N 步就 early stop”,避免浪费计算资源。
此外,自动模型选择系统(如 AutoML)已经广泛部署,通过验证集自动选择最优超参数,甚至选择最优网络结构。
🎯 面试题三:请解释图1.3 中“测试误差的U型曲线”背后的本质原因?
参考答案:
随着模型复杂度的提升:
-
训练误差持续下降;
-
测试误差先下降(学习更多数据结构),后上升(学习噪声、过拟合)。
这种趋势形成了测试误差的“U 型曲线”,反映了偏差-方差权衡原理:
-
偏差大 → 欠拟合;
-
方差大 → 过拟合。
实际应用补充:
在 Google 搜索排序模型中,通过绘制“模型复杂度 vs 验证损失”的图来调节 DNN 层数,从而选出最优 checkpoint。
🧪 场景题 3:腾讯广告系统中的模型泛化问题
题目描述:
你在腾讯广告算法组。你训练了一个 CTR 预估模型,并希望上线做 A/B 测试,但你发现该模型在测试集上效果波动大,离线评估 AUC 不稳定,甚至出现过几次严重下降。
请问:
-
出现这个问题可能有哪些原因?
-
你该如何验证模型评估过程是否存在问题?
-
你会如何优化测试误差估计策略?
参考答案:
✅ 1. 可能原因:
-
测试集划分不合理(时序泄漏、分布漂移);
-
模型对样本扰动敏感(欠鲁棒);
-
验证集太小,评估波动大;
-
Feature Drift:上线环境与离线特征存在不一致;
-
特征泄漏:训练时使用了未来信息。
✅ 2. 验证模型评估可靠性:
-
检查是否使用真实时间切片划分训练/验证集;
-
使用多轮 K 折交叉验证降低单次评估偏差;
-
记录每轮验证指标分布,画出误差置信区间。
✅ 3. 优化策略:
-
引入 时间窗口切分 的交叉验证(TimeSeriesSplit);
-
增加验证集样本数,提高鲁棒性;
-
使用更贴近线上流量的模拟测试集(Shadow Traffic);
-
在正式上线前使用 Canary Test 和小流量灰度发布验证稳定性。
🧠 总结
| 名词 | 解释 |
|---|---|
| 训练误差 | 模型在训练集上的平均损失 |
| 测试误差 | 模型在测试集上的平均损失,衡量泛化能力 |
| 过拟合 | 模型在训练集表现好但测试集表现差 |
| 模型选择 | 从多个模型中选取泛化能力最强的模型 |
| 模型复杂度 | 模型参数数量或结构复杂性 |
| 正则化 | 控制模型复杂度、避免过拟合的技术 |
| 交叉验证 | 在多个子集上测试模型稳定性的评估方法 |
🎯 面试题四:你如何在实际项目中进行模型选择?说说你用过的经验方法
参考答案结构:
-
先用训练集训练多个备选模型(如 XGBoost、DNN、LightGBM);
-
用验证集评估每个模型的测试误差(如 LogLoss, AUC);
-
若模型表现相近,则优先选:
-
泛化更好;
-
模型更轻量;
-
可解释性更强;
-
-
最后通过线上 A/B 测试或灰度发布验证模型效果。
实际经验举例:
在腾讯广告系统中,我们曾在 CTR 预估中比较 DeepFM 与 DCN 两种模型,发现 DCN 训练误差低,但在验证集上 AUC 表现下降,最终采用了参数更少但泛化能力更强的 DeepFM。
🎯 面试题五(高阶):假设训练误差为0,但测试误差极高,请分析可能原因并提出解决方案
参考答案:
这是典型的过拟合现象。原因可能包括:
-
模型过于复杂;
-
训练样本过少;
-
数据噪声大;
-
特征维度过高。
解决策略包括:
-
引入正则化项(L1/L2);
-
使用 dropout、early stopping;
-
扩充训练数据,或使用数据增强;
-
降维(PCA)或特征选择;
-
使用交叉验证精确估计测试误差。
延伸场景:
在阿里达摩院内部,有时模型在业务冷启动阶段遇到数据稀疏问题,为了避免过拟合,常采用 Wide&Deep 中的 Wide 部分增强泛化能力。
🎯 面试题六(工程应用):你如何使用交叉验证来估计测试误差并进行模型选择?
参考答案:
交叉验证(Cross Validation)是一种稳健的测试误差估计方法,特别适用于样本数量较少的情况。
-
K 折交叉验证(K-Fold CV):
-
将数据分成 K 份;
-
每次用 K-1 份训练,剩余1份测试;
-
重复K次,取平均测试误差。
-
工程经验:
在百度 NLP 任务中,由于数据量较小,我们采用 5 折交叉验证来评估不同 LSTM 模型的泛化能力,并通过平均验证 loss 选出最优模型结构。
📌 博客小贴士
-
如何避免过拟合?
-
正则化、交叉验证、早停、数据增强等方法。
-
-
训练误差为0就一定好吗?
-
否,需结合测试误差综合判断。
-
🧪 场景题 4:Google NLP 团队中的过拟合控制挑战
题目描述:
你在 Google 的 NLP 团队中开发一个情感分类模型,使用的是预训练的 BERT 进行微调。你发现训练10轮后准确率已经达到95%,但验证集准确率在90%左右徘徊。
问题:
-
这属于什么现象?你如何判断问题关键?
-
如何在大模型微调时避免过拟合?
-
有哪些 industry-level 技术专门用于 BERT 微调泛化能力控制?
参考答案:
✅ 1. 属于典型过拟合
BERT 模型表达能力强,容易在小数据集上过拟合。训练集过高准确率而验证集无法跟进,是泛化能力差的信号。
✅ 2. 避免过拟合方法:
-
加入 Dropout;
-
降低微调学习率;
-
使用 Early Stopping;
-
仅微调部分层(如 Top-2 层);
-
增加数据、使用 backtranslation 或同义替换等数据增强。
✅ 3. BERT 微调行业优化手段:
-
Adapter 模块:冻结原模型,仅训练 Adapter,控制参数数量;
-
Layer-wise LR decay:底层学习率小,顶部学习率大;
-
R-Drop / Mixout:提升鲁棒性和泛化能力;
-
Prompt Tuning:只训练 Prompt 向量,参数量极小,减少过拟合风险。
📚 参考来源:《统计学习方法(第2版)》李航著,第1章 模型评估与选择。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











