







动手学深度学习 - 11. 注意力机制和转换器 - 11.1 查询、键和值
📚 本节对应《动手学深度学习(PyTorch版)》第十一章注意力机制与转换器中的 11.1 查询、键和值 小节,深入探讨了现代深度学习中极为核心的注意力机制三元组构成:Query、Key 与 Value 的概念与数学定义。
一、引入:从数据库类比谈起
在自然语言处理与计算机视觉任务中,注意力机制已经成为 Transformer 等结构的基石。但它的本质其实可以被类比为一次“智能数据库查询”操作。
假设有如下数据库结构:
{ ("Zhang", "Aston"), ("Li", "Mu"), ("Smola", "Alex"), ("Werness", "Brent") }
我们可以用姓氏作为 Key,名字作为 Value,那么我们对 "Li" 的查询就相当于在键中查找匹配项并返回值 "Mu"。
🧠 这个类比说明了注意力机制的基本操作:给定一个 Query,从多个 Key 中找到最匹配的项,并返回对应 Value 的加权组合结果。
✅ 面试题 1:
什么是 Query、Key、Value?它们在注意力机制中的角色分别是什么?
答:
-
Query 是当前输入的“查询向量”,表示模型当前需要处理的信息;
-
Key 是数据库中“检索项”的表示,通常来自已知信息;
-
Value 是与每个 Key 对应的实际内容;
-
注意力机制的目标是根据 Query 与每个 Key 的相似度(如点积)计算权重,再对所有 Value 加权求和,得到最终输出。
📌 场景题 1
你在 Google 的机器翻译团队中工作,发现模型对长句翻译效果不好,尤其是前后语义一致性较差。有人建议优化“query-key-value 注意力机制”。你会如何分析与改进?
✅ 答案:
分析:
-
长句翻译困难常源于注意力机制无法聚焦于与当前 query 相关的远程 key。
-
原始 attention 机制可能更关注临近词,忽略上下文长程依赖。
改进方案:
-
使用多头注意力(Multi-head Attention)将不同注意力子空间覆盖不同层级关系;
-
引入位置编码(Positional Encoding),保留 token 顺序信息;
-
在 Query-Key 兼容函数中尝试加权方式(如 dot-product + bias),增强长距离注意力能力。
Google 实战:
-
在 Transformer 论文中即引入 Scaled Dot-Product Attention;
-
后续的 mT5、PaLM、Gemini 等多语言模型均优化了 QKV 的结构(如 Sparse Attention、Longformer 技术)以提升长文本处理能力。
二、核心公式推导:注意力权重计算
给定查询 q\mathbf{q}、键集合 {k1,…,kn}\{\mathbf{k}_1, \dots, \mathbf{k}_n\},我们需要计算每一个键与查询之间的相关性(兼容性),通常用一个打分函数 a(q,ki)a(\mathbf{q}, \mathbf{k}_i)。
注意力权重 α(q,ki)\alpha(\mathbf{q}, \mathbf{k}_i) 的计算公式如下:
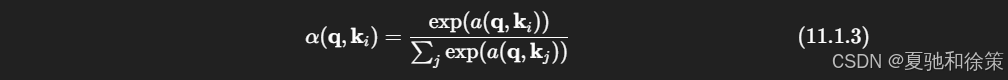
这是标准的 softmax 操作,它满足两个关键要求:
-
所有权重非负;
-
所有权重和为 1(归一化)。
最终输出为所有 Value 的加权和:
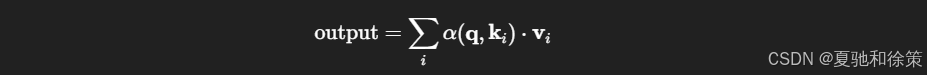
这个操作被称为 注意力汇聚(Attention Pooling),可看作是一种特殊的、数据驱动的加权平均操作。
🧠 理论理解:
-
注意力机制的核心公式为:
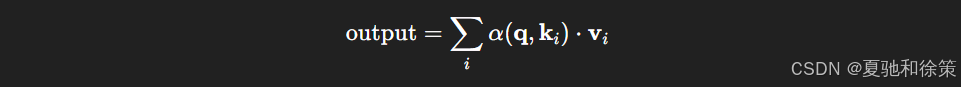
其中,Query q\mathbf{q}q 表示“当前输入的查询”,Key ki\mathbf{k}_iki 是“已知信息的标识”,Value vi\mathbf{v}_ivi 是该 Key 对应的信息。通过兼容函数 a(q,k)a(q,k)a(q,k) 计算 query 与各 key 的匹配度,再经 softmax 得出注意力权重 α\alphaα。
-
注意力机制本质上是 加权汇聚已知信息以满足当前查询 的一种方法,是对信息的一种“相关性检索”。
-
有多种特例:
-
平均池化:所有权重相等;
-
one-hot:只有一个权重为1,其余为0;
-
softmax:广泛使用的连续加权方式,保证可导性与训练稳定性。
-
🏢 企业实战理解:
-
Google Transformer(2017):首次全面使用 Query-Key-Value 机制建模语言序列,实现并行化语言建模,替代RNN。
-
字节跳动推荐系统:在多兴趣建模中使用“用户行为序列作为Key-Value,当前页面作为Query”计算相关性,从而推荐匹配内容。
-
OpenAI GPT 系列:大规模预训练语言模型通过 QKV attention 在上下文之间捕捉长程依赖,使得模型具备“对话记忆”能力。
-
NVIDIA Megatron-LM:在超大模型中使用混合并行 attention(张量并行+流水并行),其中 Q、K、V 跨GPU计算,支持数百亿参数模型训练。
✅ 面试题 2:
请推导 Scaled Dot-Product Attention 的核心公式,并解释为什么要除以 dk\sqrt{d_k}dk。
答:
Scaled Dot-Product Attention 计算过程如下:

-
其中 Q∈Rn×dkQ \in \mathbb{R}^{n \times d_k}Q∈Rn×dk,K∈Rm×dkK \in \mathbb{R}^{m \times d_k}K∈Rm×dk,V∈Rm×dvV \in \mathbb{R}^{m \times d_v}V∈Rm×dv;
-
除以 dk\sqrt{d_k}dk 是为了避免在高维空间中点积过大,造成 softmax 梯度过小,导致梯度消失或不稳定。
📌 场景题 2
你在字节跳动内容推荐团队中负责信息流模型。用户特征非常复杂,包括点击、浏览、停留时长、搜索词等。如何基于注意力机制构造 Query-Key-Value 来建模用户兴趣?
✅ 答案:
目标是实现 动态用户建模,让模型能根据当前推荐上下文动态调整兴趣权重。
构建方式:
-
Key: 用户历史行为的 embedding(每一条行为如一个 key);
-
Value: 与 key 对应的行为具体内容(如视频 embedding);
-
Query: 当前推荐 item 的 embedding(即想推荐的内容)。
注意力机制输出就是当前 item 与用户历史之间的 匹配程度加权值,代表兴趣偏好。
字节跳动实战:
-
在抖音、头条推荐系统中使用 DIN/DIEN(Deep Interest Network)结构,通过 attention 提取“当前上下文相关兴趣”;
-
使用了自定义 attention 层(类似 scaled dot-product),动态聚合行为序列。
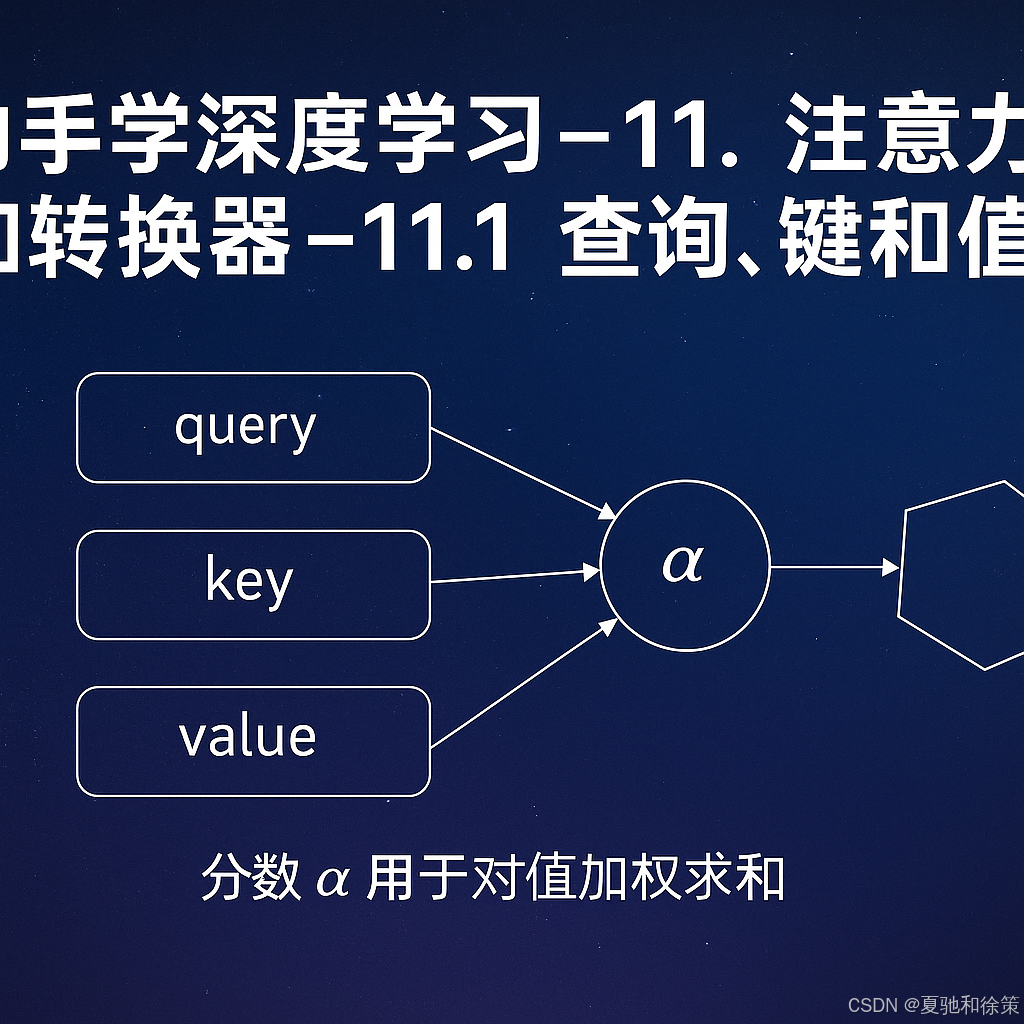
三、图示理解:QKV机制结构图
图 11.1.1 展示了一个典型的注意力机制计算流程:
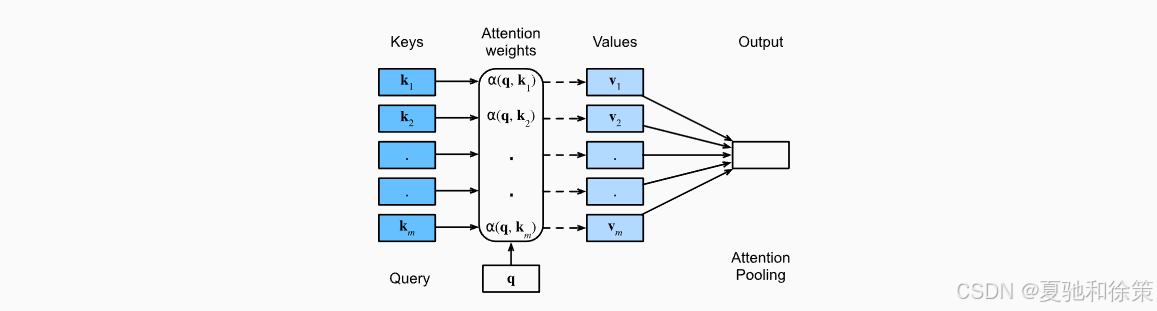
-
Query用于向数据库发起“检索意图”; -
Key表示数据库中已有的“检索项”; -
Value是与每个 Key 关联的内容; -
Attention 模块根据 q,ki\mathbf{q}, \mathbf{k}_i 计算每个权重,再对所有 Value 加权求和。
✅ 面试题 3:
注意力机制中的 Q/K/V 是如何生成的?可以共用 embedding 吗?
答:
-
Q/K/V 通常由输入序列经过不同的线性变换得到:
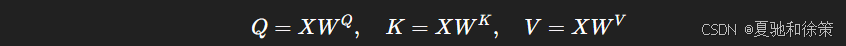
-
每个变换权重 WQ,WK,WVW^Q, W^K, W^VWQ,WK,WV 是独立可学习参数;
-
理论上可以共享 embedding,但在实践中分开可以让模型更灵活地学习“谁来问”(Q),“谁被问”(K),“问到后给出什么内容”(V)的不同语义角色。
📌 场景题 3
你在 OpenAI 担任 GPT-4 系统工程师,发现模型生成中出现了“语义跳跃”(比如回答中前后不连贯)。这可能与注意力分配有关。你会如何检查并定位 attention 问题?
✅ 答案:
分析步骤:
-
可视化每一层每个 Head 的 attention matrix,看 attention 是否集中在某些 token 上,或是否关注到 prompt 中关键 token;
-
检查 Q/K/V 的 embedding 是否退化(如 Query 与所有 Key 相似度低,导致 softmax 输出接近平均);
-
对于 Decoder 结构,确认是否保留了 Causal Mask(防止看到未来 token)。
改进方向:
-
引入稀疏注意力(Sparse Attention)或局部+全局 attention;
-
调整 LayerNorm 和 Residual 顺序(如 PreNorm vs PostNorm)以稳定梯度传播;
-
添加 Memory token 保留 prompt 中的重要语义。
OpenAI 实战:
-
GPT 系列采用层层叠加的多头注意力,每层学不同层级语义;
-
在 GPT-4 训练中使用 attention log 分析模块追踪异常 attention 路径,辅助 debug;
-
GPT-4 Turbo 加入缓存式 Key-Value 结构提升 attention 精度。
四、可视化:权重矩阵热图
我们可以用一个单位矩阵(对角线为 1,其余为 0)模拟一种“完全匹配”的 attention 权重分布,展示如下图所示:
attention_weights = torch.eye(10).reshape((1, 1, 10, 10))
show_heatmaps(attention_weights, xlabel='Keys', ylabel='Queries')
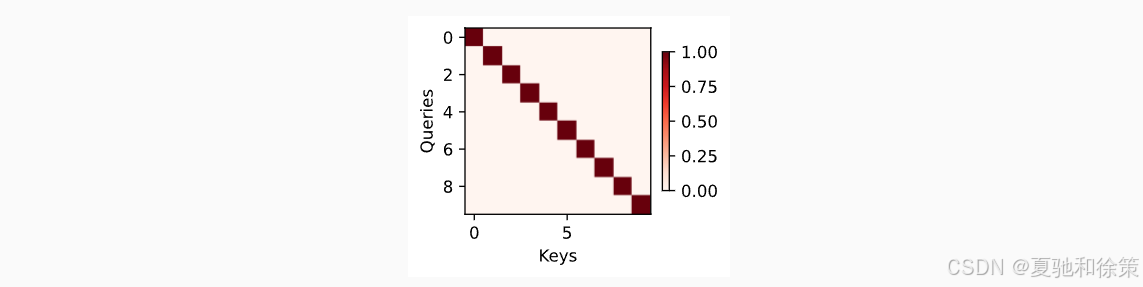
当 Queries 和 Keys 完全对齐时(如机器翻译中的字对字对齐),attention 权重分布接近对角线。
🧠 理论理解:
-
将 attention weight 可视化为热力图,可以直观观察 Query 与哪些 Key 匹配更紧密。单位矩阵的 attention 权重显示“完全匹配”特性,即 Q==K 时权重最大。
-
可视化可以用于 debug:例如查看模型是否仅关注开头/结尾单词,或是否学会长程依赖。
-
可视化操作常通过 matplotlib + heatmap 或 tensorboard plugin 实现。
🏢 企业实战理解:
-
Google BERT:训练后分析 attention heatmap,发现某些 Head 专注于短距离依赖,另一些则关注实体指代、句子关系。
-
字节跳动抖音视频推荐系统:可视化用户行为序列 attention 热力图,解释模型为何推荐某条视频(模型解释模块)。
-
OpenAI Codex/GPT-4:在代码生成任务中,内部可视化 attention 路径以判断模型是否成功记忆跨函数的变量依赖。
-
英伟达 Triton Inference Server:提供可视化接口以分析 Transformer 推理阶段 attention 层的计算开销与热度,优化 GPU 执行图。
✅ 面试题 4:
如果 Q=K=V,这个注意力机制有什么意义?它被用于什么结构中?
答:
当 Q=K=V 时,就是 自注意力(Self-Attention),每个 token 可以与序列中其他 token 交互,捕捉全局上下文关系。
-
在 Transformer 编码器中广泛使用,允许模型捕捉任意位置的依赖关系;
-
是 GPT、BERT、ViT 等模型的核心。
五、小结与延伸
-
注意力机制是一种可微分的检索机制;
-
它可解释为在查询–键空间中的“加权检索”;
-
可泛化为精确匹配(one-hot)、平均池化(全等权)或软选择(softmax);
-
为 Transformer 等模型引入灵活且高效的信息整合能力。
在下一节(11.2),我们将进一步探讨如何通过键与查询之间的相似性来决定注意力权重,也就是通过相似性进行注意力汇聚。
🧠 理论理解:
-
注意力机制提供了一种 可微分的选择机制:它让模型可以从一堆信息中“有偏地挑选”,而不是盲目平均或硬选择。
-
与数据库类比:
-
Key → 数据库索引;
-
Query → 查询条件;
-
Value → 实际数据;
-
Output → 检索结果的加权平均。
-
-
这种机制对长序列任务极其重要(如 NLP、图像描述、强化学习中的状态估计)。
🏢 企业实战理解:
-
阿里巴巴搜索排序模型:将多种商品特征映射为 Key/Value,用户当前行为意图为 Query,实现对候选商品的动态评分。
-
腾讯混合模型系统:在广告推荐中使用注意力聚焦于用户最近活跃行为,用于动态建模兴趣偏好。
-
OpenAI DALL·E 图像生成系统:将文本编码为 Query,图像 patch 编码为 Key/Value,进行跨模态 attention 以引导图像生成。
-
Google AlphaStar(星际争霸 AI):对地图中敌方单位状态进行注意力聚合,实现战术推理和多目标操作。
✅ 面试题 5:
你如何理解 Attention 是一种“可微的选择机制”?
答:
注意力机制通过 softmax 将 query 与各个 key 的相似度转化为概率分布,再将这些概率加权 value,等价于从多个候选中“软选择”。
-
与 one-hot 的硬选择不同,注意力可以为多个候选赋予不同程度的权重;
-
可导性使得它能参与端到端反向传播;
-
本质上是一种“信息检索 + 加权组合”机制,适用于序列建模、推荐排序、多模态对齐等任务。
✅ 面试题 6:
为什么在大规模模型中会使用多头注意力(Multi-Head Attention)?
答:
多头注意力可以从多个子空间并行学习注意力权重,提高模型表达能力:
-
每个 head 学习不同的子关系(如短程 vs 长程依赖);
-
多头结构提升模型的鲁棒性与上下文建模能力;
-
实践中常用 head 数量为 8、12、16、32(依模型大小);
-
Transformer 中每个 head 的输出会 concat 再通过线性层融合。
✅ 面试题 7:
Attention 权重矩阵中的对角线含义是什么?什么时候它趋近于单位矩阵?
答:
-
权重矩阵的对角线表示当前 token 更关注自己(self);
-
如果 attention 是单位矩阵,对应 Q 和 K 完全匹配,只有自己有最大 attention 权重;
-
常出现在初始阶段、未训练时或做 sanity check;
-
在序列对齐任务中,如翻译、对话,attention 权重可能近似沿对角线分布(token 一一对应)。
✅ 面试题 8:
请说出你知道的几种 Attention 类型和它们的不同点。
答:
-
Self-Attention:Q=K=V,建模序列内依赖;
-
Cross-Attention:Q 来自一个序列,K/V 来自另一个序列,用于对齐两种信息;
-
Masked Attention:限制注意力不能看到未来 token,用于生成任务;
-
Local Attention:只关注邻近窗口,提升效率;
-
Global+Local Attention(Longformer):混合建模长文本;
-
Multi-head Attention:多个子空间并行建模。
📌 推荐思考题(节选自原教材)
-
假设你要实现 approximate key-query 匹配,你会如何选择注意力函数?
-
如果我们将
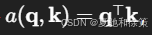 证明输出确实是 query 与 key 相似度的 softmax 权重。
证明输出确实是 query 与 key 相似度的 softmax 权重。 -
能否用注意力机制实现一个可微分的“搜索引擎”?如何设计?
📌 场景题 4
你在阿里巴巴图像搜索团队,使用视觉 Transformer(ViT)处理商品图片。训练过程中注意力收敛慢,聚焦区域不明确。你如何优化 Q-K-V attention 部分以提升效果?
✅ 答案:
问题原因:
-
初始 patch embedding 不具备语义,attention 无法聚焦有效区域;
-
多头注意力每个 Head 可能无效(冗余或无学习能力)。
优化方法:
-
加入位置编码(2D)以保持空间结构;
-
引入引导注意力(Guided Attention):
-
将预训练模型中的中间特征作为引导 Query;
-
或使用辅助 loss 让某些 Head 聚焦目标区域(如商品主体)。
-
-
使用 Self-Attention + Cross-Attention 联合训练,跨模态提升语义理解。
阿里实战:
-
在搜索主图检测中使用 ViT + ROI-Attention 联合建模;
-
淘宝商品识别使用 Swin Transformer 改进 attention 架构,并在 Q/K/V 加入类别先验 embedding;
📌 场景题 5
你在 NVIDIA AI 推理平台(Triton)优化多路 Transformer 推理任务时,发现部分实例 batch 推理耗时不均,CPU/GPU 资源利用不均衡。怀疑是 attention 模块阻塞所致。你如何排查和解决?
✅ 答案:
分析角度:
-
attention 模块计算量与序列长度平方相关(O(n²));
-
Q/K/V 分别需要与每个样本的长度适配,导致 batch 内差异影响统一推理。
排查方式:
-
打开 Triton profiling 日志,查看每层 attention 耗时;
-
对比不同 batch size / 不同 max length 的执行图,发现是否 padding 不均;
-
分析 GPU 的 CUDA kernel 执行时间是否有冗余。
优化方式:
-
使用 Dynamic Padding 统一 batch 中有效长度,减少无效计算;
-
用 FlashAttention、xFormers 等稀疏 attention 库替代传统实现;
-
将推理阶段的 Key/Value 缓存提取出至独立模块,实现跨 session 重用。
NVIDIA 实战:
-
在 Megatron/NeMo 中实现 KV Cache 共享机制,大幅减少推理时间;
-
Triton Server 支持动态批次裁剪 attention 输入,避免低效 padding。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











