







字符串类型
MySQL 数据库的字符串类型有 CHAR、VARCHAR、BINARY、BLOB、TEXT、ENUM、SET。不同的类型在业务设计、数据库性能方面的表现完全不同,其中最常使用的是 CHAR、VARCHAR。
CHAR(N) 用来保存固定长度的字符,N 的范围是 0 ~ 255,请牢记,N 表示的是字符,而不是字节。
VARCHAR(N) 用来保存变长字符,N 的范围为 0 ~ 65536, N 表示字节。
在超出 65536 个字节的情况下,可以考虑使用更大的字符类型 TEXT 或 BLOB,两者最大存储长度为 4G,其区别是 BLOB 没有字符集属性,纯属二进制存储
字符集
在表结构设计中,除了将列定义为 CHAR 和 VARCHAR 用以存储字符以外,还需要额外定义字符对应的字符集,因为每种字符在不同字符集编码下,对应着不同的二进制值。常见的字符集有 GBK、UTF8,通常推荐把默认字符集设置为 UTF8。
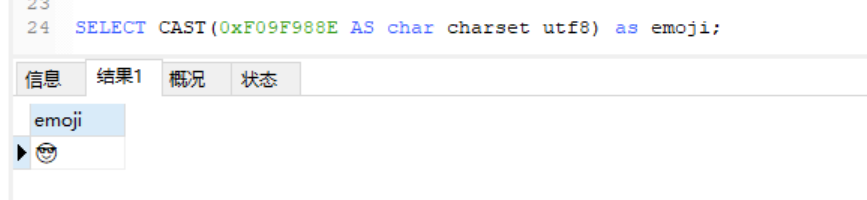
而且随着移动互联网的飞速发展,推荐把 MySQL 的默认字符集设置为 UTF8MB4,否则,某些 emoji 表情字符无法在 UTF8 字符集下存储,比如 emoji 笑脸表情,对应的字符编码为 0xF09F988E:
笔者这边实验utf-8出现了笑脸,使用utf8mb4反而是问号(在8.0.22及5.6.24-log均是如此)
姜老师的实验结果如下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uQnjTc04-1621410657635)(https://s0.lgstatic.com/i/image6/M00/3C/A0/CioPOWCLjaOANGrbAAD3LJzwYeU752.png)]
如下姜老师也有补充说明
包括 MySQL 8.0 版本在内,字符集默认设置成 UTF8MB4,8.0 版本之前默认的字符集为 Latin1。因为不同版本默认字符集的不同,你要显式地在配置文件中进行相关参数的配置:
[mysqld]
character-set-server = utf8mb4
...
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mlDs7KCX-1621410657637)(https://s0.lgstatic.com/i/image6/M00/3C/A0/CioPOWCLjb-ADQ97AADmWCr4bpE672.png)]
另外,不同的字符集,CHAR(N)、VARCHAR(N) 对应最长的字节也不相同。比如 GBK 字符集,1 个字符最大存储 2 个字节,UTF8MB4 字符集 1 个字符最大存储 4 个字节。所以从底层存储内核看,在多字节字符集下,CHAR 和 VARCHAR 底层的实现完全相同,都是变长存储!
从上面的例子可以看到,CHAR(1) 既可以存储 1 个 ‘a’ 字节,也可以存储 4 个字节的 emoji 笑脸表情,因此 CHAR 本质也是变长的。
鉴于目前默认字符集推荐设置为 UTF8MB4,所以在表结构设计时,可以把 CHAR 全部用 VARCHAR 替换,底层存储的本质实现一模一样。
排序顺序
排序规则(Collation)是比较和排序字符串的一种规则,每个字符集都会有默认的排序规则,你可以用命令 SHOW CHARSET 来查看:
SHOW CHARSET LIKE 'utf8%';
Charset Description Default collation Maxlen
utf8 UTF-8 Unicode utf8_general_ci 3
utf8mb4 UTF-8 Unicode utf8mb4_general_ci 4
SHOW COLLATION LIKE 'utf8mb4%';
Collation Charset Id Default Compiled Sortlen
utf8mb4_general_ci utf8mb4 45 Yes Yes 1
utf8mb4_bin utf8mb4 46 Yes 1
utf8mb4_unicode_ci utf8mb4 224 Yes 8
utf8mb4_icelandic_ci utf8mb4 225 Yes 8
utf8mb4_latvian_ci utf8mb4 226 Yes 8
utf8mb4_romanian_ci utf8mb4 227 Yes 8
utf8mb4_slovenian_ci utf8mb4 228 Yes 8
utf8mb4_polish_ci utf8mb4 229 Yes 8
utf8mb4_estonian_ci utf8mb4 230 Yes 8
utf8mb4_spanish_ci utf8mb4 231 Yes 8
utf8mb4_swedish_ci utf8mb4 232 Yes 8
utf8mb4_turkish_ci utf8mb4 233 Yes 8
utf8mb4_czech_ci utf8mb4 234 Yes 8
utf8mb4_danish_ci utf8mb4 235 Yes 8
utf8mb4_lithuanian_ciutf8mb4 236 Yes 8
utf8mb4_slovak_ci utf8mb4 237 Yes 8
utf8mb4_spanish2_ci utf8mb4 238 Yes 8
utf8mb4_roman_ci utf8mb4 239 Yes 8
utf8mb4_persian_ci utf8mb4 240 Yes 8
utf8mb4_esperanto_ci utf8mb4 241 Yes 8
utf8mb4_hungarian_ci utf8mb4 242 Yes 8
utf8mb4_sinhala_ci utf8mb4 243 Yes 8
utf8mb4_german2_ci utf8mb4 244 Yes 8
utf8mb4_croatian_ci utf8mb4 245 Yes 8
utf8mb4_unicode_520_ci utf8mb4 246 Yes 8
utf8mb4_vietnamese_ci utf8mb4 247 Yes 8
排序规则以 _ci 结尾,表示不区分大小写(Case Insentive),_cs 表示大小写敏感,_bin 表示通过存储字符的二进制进行比较。
绝大部分业务的表结构设计无须设置排序规则为大小写敏感!除非你能明白你的业务真正需要。
正确修改字符集
当业务设计的时候没有考虑到字符集对于业务数据存储的影响,后期进行字符集转换
ALTER TABLE emoji_test CHARSET utf8mb4;
上述修改只是将表的字符集修改为 UTF8MB4,下次新增列时,若不显式地指定字符集,新列的字符集会变更为 UTF8MB4,但对于已经存在的列,其默认字符集并不做修改
因此,正确修改列字符集的命令应该使用 ALTER TABLE … CONVERT TO…这样才能将之前的列 a 字符集从 UTF8 修改为 UTF8MB4:
ALTER TABLE emoji_test CONVERT TO CHARSET utf8mb4;
业务表设计
用户性别
如果使用tinyint列sex表示用户性别会存在如下问题
-
表达不清:在具体存储时,0 表示女,还是 1 表示女呢?每个业务可能有不同的潜规则;
-
脏数据:因为是 tinyint,因此除了 0 和 1,用户完全可以插入 2、3、4 这样的数值,最终表中存在无效数据的可能,后期再进行清理,代价就非常大了
在 MySQL 8.0 版本之前,可以使用 ENUM 字符串枚举类型,只允许有限的定义值插入。如果将参数 SQL_MODE 设置为严格模式,插入非定义数据就会报错:
由于类型 ENUM 并非 SQL 标准的数据类型,而是 MySQL 所独有的一种字符串类型。抛出的错误提示也并不直观,这样的实现总有一些遗憾,主要是因为MySQL 8.0 之前的版本并没有提供约束功能。自 MySQL 8.0.16 版本开始,数据库原生提供 CHECK 约束功能,可以方便地进行有限状态列类型的设计:
Create Table: CREATE TABLE `User` (
`id` bigint NOT NULL AUTO_INCREMENT,
`sex` char(1) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`),
CONSTRAINT `user_chk_1` CHECK (((`sex` = _utf8mb4'M') or (`sex` = _utf8mb4'F')))
) ENGINE=InnoDB
插入语句
INSERT INTO User VALUES (NULL,'M');
INSERT INTO User VALUES (NULL,'Z');
当插入非法数据 Z 时,你可以看到 MySQL 显式地抛出了违法约束的提示。
账户密码存储设计
可以在业务层使用MD5加密的方式,不要直接在数据库中存储密码。















 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









