







一:软件准备
![]()
![]()

![]()
![]()

![]()
![]()

![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
1、操作系统:centOS6.5 64位
2、hadoop2.2.0安装包
下载地址:
http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.2.0/
注意:由于我使用的操作系统是64位的,hadoop官网上编译好的安装包只有32位的,所以需要自己下载源码包使用maven编译成64位的安装包,如果直接将官网下载的32位的hadoop运行在64位的机器上,格式化以及启动hdfs时会报
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
错误。本教程略过了hadoop2.2.0的编译过程,可自行百度^^。
3、JDK安装包
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
由于hadoop是使用java语言开发的,所以需要运行在java环境中。我使用的jdk安装包是:jdk-7u45-linux-x64.rpm
二:集群架构
由于搭建的只是实验环境,不是生产环境,所以使用一台服务器,虚拟出3台虚拟机,一台作为master(sjfx),两台作为slave(sjfx01、sjfx02)。
IP hostname
192.168.57.127 sjfx
192.168.57.128 sjfx01
192.168.57.129 sjfx02
三:系统环境准备
略去系统安装以及ip配置
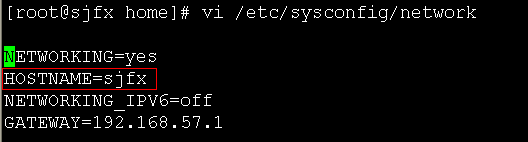
1、修改主机名
命令:vi /etc/sysconfig/network
对照集群架构,修改对应的主机名
注:另外两台机子的配置同理。
2、修改hosts配置
命令:vi /etc/hosts
对应集群架构,将ip与主机名进行绑定,修改完成后,可以通过ping命令验证
![]()
![]()
注:可以直接将配置好的hosts文件发送给另外两台机器,因为配置的内容是一样的,命令如下:
scp /etc/hosts root@sjfx01:/etc/hosts
scp /etc/hosts root@sjfx02:/etc/hosts
3、关闭防火墙
命令:service iptables stop
4、关闭防火墙自启动
命令:chkconfig iptables off
验证:chkconfig --list | grep iptables
注:另外两台机器3、4步做同样操作。
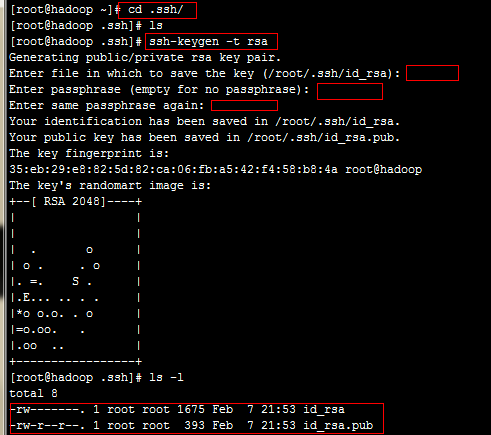
5、配置ssh免密码登录
a、生成的密码会存放在~/.ssh目录下,进入到该目录 cd ~/.ssh/
输入命令:ssh-keygen -t rsa 一路回车,会生成两个文件
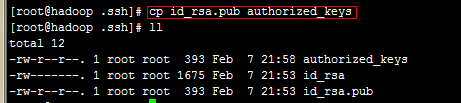
b、复制公钥的内容 cp id_rsa.pub authorized_keys
验证是否成功:ssh localhost
c、将公钥信息分发给集群中的其他机器,从而保证免密码登录:
命令:ssh-copy-id -i ~/.ssh/id_rsa.pub sjfx01
ssh-copy-id -i ~/.ssh/id_rsa.pub sjfx02
注:另外两台机器做类似操作。由于hadoop进程间的通信采用ssh方式,配置免密码登录可以避免每次都要输入密码。
四:JDK安装
1、从上面提供的网址下载jdk的安装包,因为我的系统是linux 64位的,所以要下载linux 64位的jdk版本。
2、由于我下载的是rpm格式的安装包,所以使用命令:rpm -ivh jdk-7u45-linux-x64.rpm 进行安装。
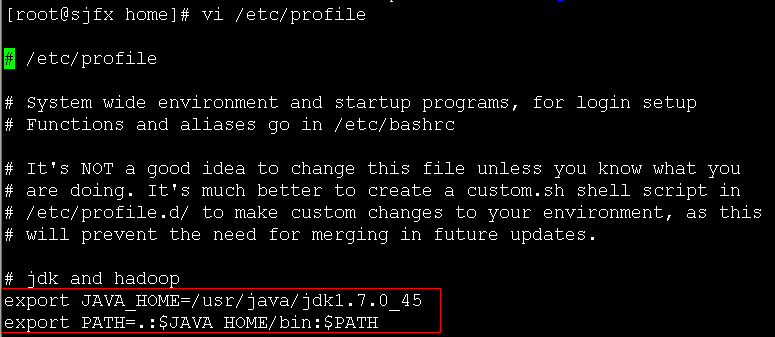
3、jdk安装完成后配置环境变量:
命令:vi /etc/profile
添加两行内容:
export JAVA_HOME=/usr/java/jdk1.7.0_45
export PATH=.:$JAVA_HOME/bin:$PATH
保存退出后,执行命令:source /etc/profile 让刚才的修改立即生效。
4、执行命令:java -version 查看jdk是否安装成功。
注:另外两台机子按照相同方式安装jdk
五:hadoop2.2.0安装
1、使用maven编译hadoop-2.2.0-src,编译好的hadoop2.2.0会放在hadoop-2.2.0-src/hadoop-dist/target目录下,将hadoop2.2.0文件夹复制到你要安装的位置即可(我放在了/home目录下)。
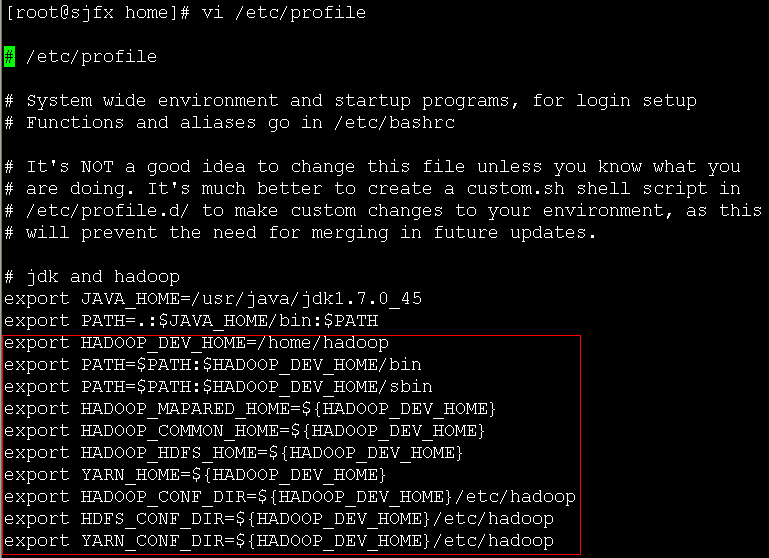
2、配置环境变量
hadoop的环境变量配置跟jdk的环境变量配置类似
命令:vi /etc/profile
增加下面几行内容(根据自己的安装目录,做适当修改):
export HADOOP_DEV_HOME=/home/hadoop
export PATH=$PATH:$HADOOP_DEV_HOME/bin
export PATH=$PATH:$HADOOP_DEV_HOME/sbin
export HADOOP_MAPARED_HOME=${HADOOP_DEV_HOME}
export HADOOP_COMMON_HOME=${HADOOP_DEV_HOME}
export HADOOP_HDFS_HOME=${HADOOP_DEV_HOME}
export YARN_HOME=${HADOOP_DEV_HOME}
export HADOOP_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop
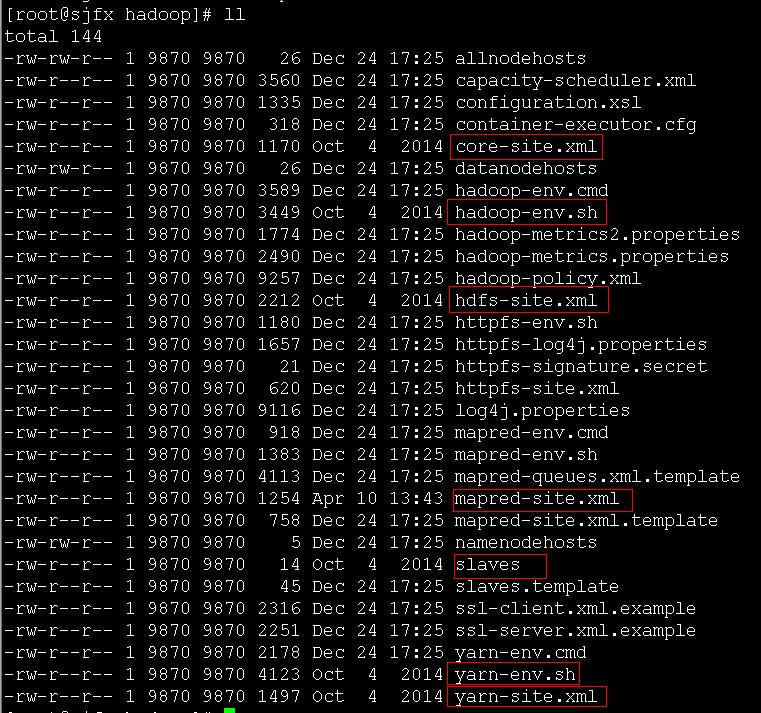
3、修改配置文件,hadoop2.2.0的配置文件在 ${HADOOP_HOME}/etc/hadoop/ 目录下
主要修改:hadoop-env.sh 、 yarn-env.sh、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
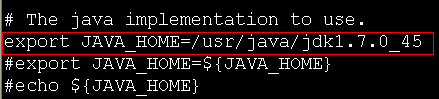
a、在hadoop-env.sh文件中第27行修改java的home目录
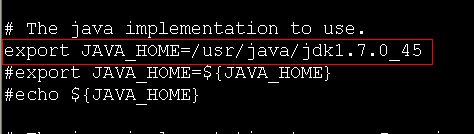
b、在yarn-env.sh文件中第27行修改java的home目录
c、在slaves文件中添加slave node
d、修改core-site.xml文件,添加如下配置(根据自己的实际情况进行修改):
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://sjfx:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>sjfx</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
e、修改hdfs-site.xml文件,添加如下配置(根据自己的实际情况进行修改):
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.federation.nameservice.id</name>
<value>ns1</value>
</property>
<property>
<name>dfs.namenode.backup.address.ns1</name>
<value>sjfx:50100</value>
</property>
<property>
<name>dfs.namenode.backup.http-address.ns1</name>
<value>sjfx:50105</value>
</property>
<property>
<name>dfs.federation.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>sjfx:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>sjfx:19000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>sjfx:23001</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>sjfx:13001</value>
</property>
<property>
<name>dfs.dataname.data.dir</name>
<value>/hadoop/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns1</name>
<value>sjfx:23002</value>
</property>
f、修改mapred-site.xml文件,添加如下配置(根据自己的实际情况进行修改):
注:默认没有mapred-site.xml文件,只有mapred-site.xml.template文件
通过命令:cp mapred-site.xml.template mapred-site.xml 复制mapred-site.xml.template,然后再修改mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>sjfx:10020</value>
</property>
g、修改yarn-site.xml文件,添加如下配置(根据自己的实际情况进行修改):
<property>
<name>yarn.resourcemanager.address</name>
<value>sjfx:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>sjfx:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>sjfx:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>sjfx:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>sjfx:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
注:另外两台机子做同样的配置,可以直接通过scp命令将配置好的hadoop安装包以及环境变量发送给另外两台机子。
4、所有机器的hadoop都配置好后,在namenode上执行命令格式化hdfs
命令:hadoop namenode -format
(会有一大段输出,自己检查下是否一切正常)
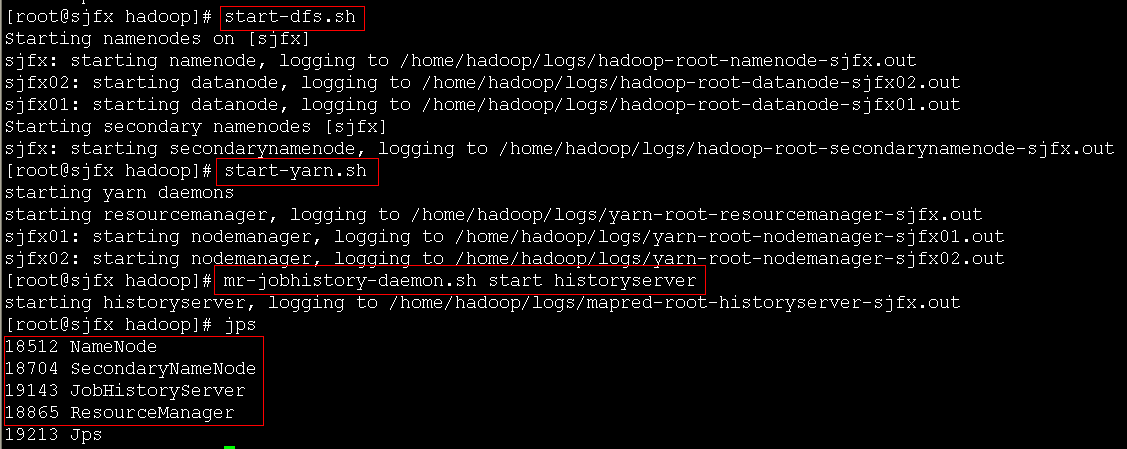
5、启动hadoop集群
启动hdfs命令:start-dfs.sh
启动yarn命令:start-yarn.sh
启动historyserver命令:mr-jobhistory-daemon.sh start historyserver
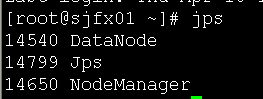
sjfx01:
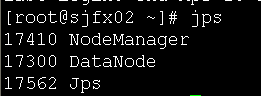
sjfx02:
总结:
hadoop2.2.0的安装主要注意以下几点:
1、机器环境的配置,检查防火墙是否关闭,配置ssh免密码登录
2、安装jdk
3、安装hadoop,注意hadoop的配置,要熟悉hadoop的配置文件
















 1454
1454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











