









1、数据预处理
主要包括
•特征提取
•处理缺失数据
•数据定标
•数据转换: One-Hot encoding, One/Two/MultiGram, Bag of words, 取对数
•1、特征提取:
- a、以基于图像进行行人检测为例, 需要提取图像的梯度直方图
- b、以自然语言处理为例, 需要提取文字的n-gram,其实就是将文字转换成数字形式,然后通过计算句子各个单词同时出现的概率(通过历史训练的数据得到各个单词间两两同时存在的概率)
使用条件概率公式p(S)=p(w1w2⋯wn)=p(w1)p(w2∣w1)⋯p(wn∣wn−1wn−2)计算概率值,具体看下面链接内容
如下博客对n-gram描述得比较细致:https://blog.csdn.net/songbinxu/article/details/80209197
2、数据预处理之处理缺失数据
•以Titanic数据集为例, 部分乘客的年龄, 80%乘客的仓位有缺失
•处理方式:
•1. 使用均值或者中间值(median)代替数值类型(年龄)的缺失数据
•2. 使用众数(mode)代替分类数据(性别)的缺失数据
•3. 使用聚类的方式, 找到相似的数据点, 使用这些相似数据点的均值等替代缺失数据
•4. 如果某一个特征的数据丢失率太高, 直接丢弃这个特征的数据也许更好
3、数据预处理之数据定标
1)
•Normalization/Min-Max-Scaler (归一化)
•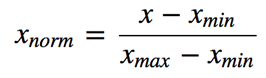
•Standardization (标准化)
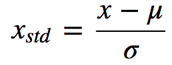
2)也可以使用降维处理,或者通过坐标轴向量转换

经过转换之后就可以比较清晰直观观测到数据间的区别
4、数据转换: One-Hot encoding
















 2828
2828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









