







 本文介绍了Linux内存管理的NUMA架构,包括存储节点、管理区和页面的概念。接着详细阐述了buddy内存分配算法,用于解决外碎片问题,以及slub内存分配算法,适用于频繁分配和释放的小对象。最后对比了slab和slub的区别。
本文介绍了Linux内存管理的NUMA架构,包括存储节点、管理区和页面的概念。接着详细阐述了buddy内存分配算法,用于解决外碎片问题,以及slub内存分配算法,适用于频繁分配和释放的小对象。最后对比了slab和slub的区别。
Linux内存管理是一个很复杂的系统,也是linux的精髓之一,网络上讲解这方面的文档也很多,我把这段时间学习内存管理方面的知识记录在这里,涉及的代码太多,也没有太多仔细的去看代码,深入解算法,这篇文章就当做内存方面学习的一个入门文档,方便以后在深入学习内存管理源码的一个指导作用;
(一)NUMA架构
NUMA通过提供分离的存储器给各个处理器,避免当多个处理器访问同一个存储器产生的性能损失来试图解决这个问题。对于涉及到分散的数据的应用(在服务器和类似于服务器的应用中很常见),NUMA可以通过一个共享的存储器提高性能至n倍,而n大约是处理器(或者分离的存储器)的个数。
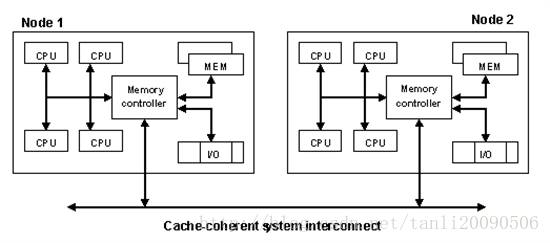
当然,不是所有数据都局限于一个任务,所以多个处理器可能需要同一个数据。为了处理这种情况,NUMA系统包含了附加的软件或者硬件来移动不同存储器的数据。这个操作降低了对应于这些存储器的处理器的性能,所以总体的速度提升受制于运行任务的特点。
Linux把物理内存划分为三个层次来管理:
1. 存储节点(Node): CPU被划分为多个节点(node), 内存则被分簇, 每个CPU对应一个本地物理内存, 即一个CPU-node对应一个内存簇bank,即每个内存簇被认为是一个节点;
2. 管理区(Zone):每个物理内存节点node被划分为多个内存管理区域, 用于表示不同范围的内存,内核可以使用不同的映射方式映射物理内存,通常管理区的类型可以分为:ZONE_NORMAL,ZONE_DMA,ZONE_HIGHMEM三种;内核(32位为例内核空间为1G)空间如下:
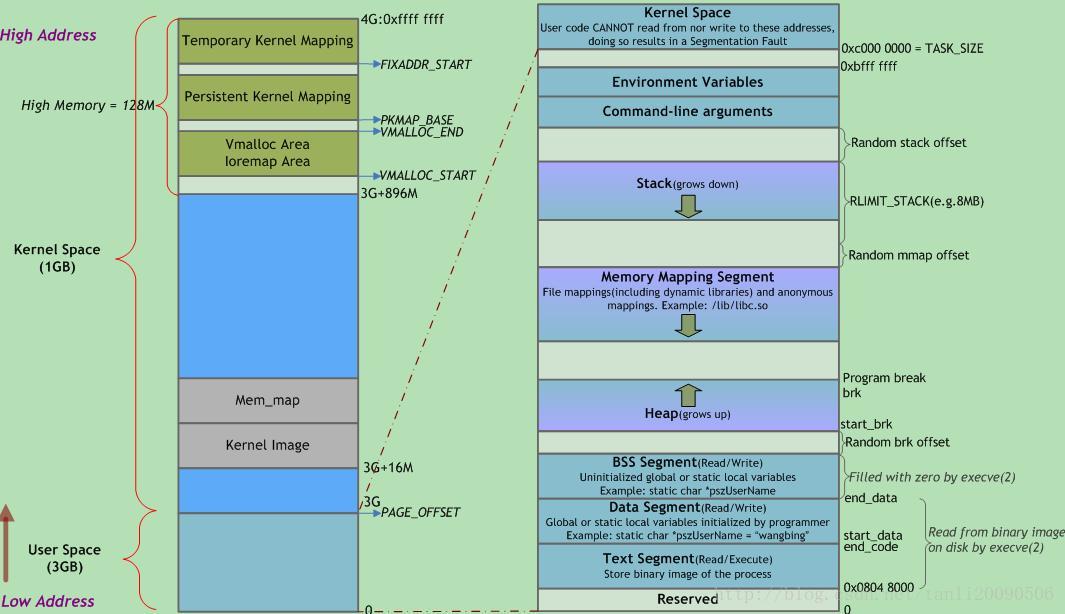
如果物理内存超过896 MiB就为highmem,则内核无法直接映射全部物理内存,最后的128 MiB用于其他目的,比如vmalloc就可以从这里分配不连续的内存,最珍贵的是3GB起始的16MB DMA区域直接用于外设和系统之间的数据传输;
3. 页面(Page):内存被细分为多个页面帧, 页面是最基本的页面分配的单位;
NUMA模式下,处理器被划分成多个”节点”(node), 每个节点被分配有的本地存储器空间。 所有节点中的处理器都可以访问全部的系统物理存储器,但是访问本节点内的存储器所需要的时间,比访问某些远程节点内的存储器所花的时间要少得多。Linux通过struct pglist_data这个结构体来描述节点;
722 typedef struct pglist_data {
723 struct zone node_zones[MAX_NR_ZONES];//是一个数组,包含了结点中各内存域的数据结构;
724 struct zonelist node_zonelists[MAX_ZONELISTS];//指定备用结点及其内存域的列表,以便在当前结点没有可用空间时,在备用结点分配内存;
725 int nr_zones;//保存结点中不同内存域的数目;
726 #ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
727 struct page *node_mem_map;//指向page实例数组的指针,用于描述结点的所有物理内存页,它包含了结点中所有内存域的页。
728 #ifdef CONFIG_MEMCG
729 struct page_cgroup *node_page_cgroup;
730 #endif
731 #ifdef CONFIG_PAGE_EXTENSION
732 struct page_ext *node_page_ext;
733 #endif
734 #endif
735 #ifndef CONFIG_NO_BOOTMEM
736 struct bootmem_data *bdata;//在系统启动期间,内存管理
//子系统初始化之前,内核页需要使用内存(另外,还需要保留部分内存用于初始
//化内存管理子系统)。bootmem分配器(bootmem allocator)的机制,这种
//机制仅仅用在系统引导时,它为整个物理内存建立起一个页面位图;
737 #endif
738 #ifdef CONFIG_MEMORY_HOTPLUG
...
750 #endif
751 unsigned long node_start_pfn;////该NUMA结点第一个页帧的逻辑编号。系统中所有的页帧是依次编号的,每个页帧的号码都是全局唯一的(不只是结点内唯一)。
752 unsigned long node_present_pages; /* total number of physical pages */ //结点中页帧的数目;
753 unsigned long node_spanned_pages; /* total size of physical page range, including holes *///该结点以页帧为单位计算的长度,包含内存空洞。
755 int node_id;//全局结点ID,系统中的NUMA结点都从0开始编号;
756 wait_queue_head_t kswapd_wait;//交换守护进程的等待队列,在将页帧换出结点时会用到。
757 wait_queue_head_t pfmemalloc_wait;
758 struct task_struct *kswapd; /* Protected by
759 mem_hotplug_begin/end() *///指向负责该结点的交换守护进程的task_struct。
760 int kswapd_max_order;//定义需要释放的区域的长度。
761 enum zone_type classzone_idx;
762 #ifdef CONFIG_NUMA_BALANCING
...
771 #endif
772 } pg_data_t;每个节点的内存会被分为几个块,我们称之为管理区(zone) ,一个管理区(zone)由struct zone结构体来描述;include/linux/mmzone.h;
327 struct zone {
331 unsigned long watermark[NR_WMARK];//当系统中可用内存很少的时候,系统进程kswapd被唤醒, 开始回收释放page, 水印这些参数(WMARK_MIN, WMARK_LOW, WMARK_HIGH)影响着这个代码的行为;
341 long lowmem_reserve[MAX_NR_ZONES];//为了防止一些代码必须运行在低地址区域,所以事先保留一些低地址区域的内存;
342
343 #ifdef CONFIG_NUMA
344 int node;
345 #endif
351 unsigned int inactive_ratio;//不活动页的比例,很少使用或者大部分情况下是只读的字段;
352
353 struct pglist_data *zone_pgdat;//zone所在的节点;
354 struct per_cpu_pageset __percpu *pageset;//每个CPU的热/冷页帧列表,有些页帧很可能在高速缓存中,可以快速访问,故称之为热的,反之为冷;
360 unsigned long dirty_balance_reserve;
361
362 #ifndef CONFIG_SPARSEMEM
367 unsigned long *pageblock_flags;
368 #endif /* CONFIG_SPARSEMEM */
369
370 #ifdef CONFIG_NUMA
374 unsigned long min_unmapped_pages;
375 unsigned long min_slab_pages;
376 #endif /* CONFIG_NUMA */
377
378 /* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
379 unsigned long zone_start_pfn;//内存域的第一个页帧;
422 unsigned long managed_pages;
423 unsigned long spanned_pages;//总页数,包含空洞;
424 unsigned long present_pages;//可用页数,不包涵空洞;
426 const char *name;//指向管理区类型名字;
432 int nr_migrate_reserve_block;
433
434 #ifdef CONFIG_MEMORY_ISOLATION
440 unsigned long nr_isolate_pageblock;
441 #endif
442
443 #ifdef CONFIG_MEMORY_HOTPLUG
444 /* see spanned/present_pages for more description */
445 seqlock_t span_seqlock;
446 #endif
472 wait_queue_head_t *wait_table;//进程等待队列的散列表, 这些进程正在等待管理区中的某页;
473 unsigned long wait_table_hash_nr_entries;//等待队列散列表中的调度实体数目;
474 unsigned long wait_table_bits;//等待队列散列表数组大小, 值为2^order;
475
476 ZONE_PADDING(_pad1_)
477
478 /* Write-intensive fields used from the page allocator */
479 spinlock_t lock;//对zone并发访问的保护的自旋锁;
480
481 /* free areas of different sizes */
482 struct free_area free_area[MAX_ORDER];//没个bit标识对应的page是否可以分配;
483
484 /* zone flags, see below */
485 unsigned long flags;//zone flags, 描述当前内存的状态;
486
487 ZONE_PADDING(_pad2_)
492 spinlock_t lru_lock;//LRU(最近最少使用算法)的自旋锁;
493 struct lruvec lruvec;
494
495 /* Evictions & activations on the inactive file list */
496 atomic_long_t inactive_age;
497
503 unsigned long percpu_drift_mark;
504
505 #if defined CONFIG_COMPACTION || defined CONFIG_CMA
506 /* pfn where co 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









