







GLM-4V-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源多模态版本。 GLM-4V-9B 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B 都表现出卓越性能。
本次开源多个版本:
THUDM/glm-4v-9b
基座模型
THUDM/glm-4-9b-chat
偏好对齐的版本。 GLM-4-9B-Chat 还具备备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能
THUDM/glm-4-9b-chat-1m
支持 1M 上下文长度(约 200 万中文字符)的模型。
THUDM/glm-4v-9b
GLM-4 系列中的开源多模态版本
本文验证硬件环境:
BF16 : RTX4090*1,显存24GB,内存32GB,系统盘200GB
24G显存无法体验多模态:GLM-4V-9B
模型微调硬件要求更高。一般不建议个人用户环境使用
环境准备
硬件要求
- GLM-4-9B-Chat
| 精度 | 显存占用 | Prefilling / 首响 | Decode Speed | Remarks |
|---|---|---|---|---|
| BF16 | 19047MiB | 0.1554s | 27.8193 tokens/s | 输入长度为 1000 |
| 精度 | 显存占用 | Prefilling / 首响 | Decode Speed | Remarks |
|---|---|---|---|---|
| Int4 | 8251MiB | 0.1667s | 23.3903 tokens/s | 输入长度为 1000 |
| Int4 | 9613MiB | 0.8629s | 23.4248 tokens/s | 输入长度为 8000 |
| Int4 | 16065MiB | 4.3906s | 14.6553 tokens/s | 输入长度为 32000 |
- GLM-4-9B-Chat-1M
| 精度 | 显存占用 | Prefilling / 首响 | Decode Speed | Remarks |
|---|---|---|---|---|
| BF16 | 74497MiB | 98.4930s | 2.3653 tokens/s | 输入长度为 200000 |
- GLM-4V-9B
| 精度 | 显存占用 | Prefilling / 首响 | Decode Speed | Remarks |
|---|---|---|---|---|
| BF16 | 28131MiB | 0.1016s | 33.4660 tokens/s | 输入长度为 1000 |
| BF16 | 33043MiB | 0.7935a | 39.2444 tokens/s | 输入长度为 8000 |
| 精度 | 显存占用 | Prefilling / 首响 | Decode Speed | Remarks |
|---|---|---|---|---|
| Int4 | 10267MiB | 0.1685a | 28.7101 tokens/s | 输入长度为 1000 |
| Int4 | 14105MiB | 0.8629s | 24.2370 tokens/s | 输入长度为 8000 |
下载源码
git clone https://github.com/THUDM/GLM-4.git
cd GLM-4
模型准备
git clone https://huggingface.co/THUDM/glm-4-9b-chat
手动下载以下几个模型(体验时几个模型不一定需全下载)
下载地址:https://hf-mirror.com/THUDM
模型名称:
THUDM/glm-4-9b-chat
THUDM/glm-4-9b
THUDM/glm-4v-9b
本文统一放在模型存档目录:/u01/workspace/models
Docker 容器化部署
构建镜像
- Dockerfile样例
注意
COPY GLM-4/ /app/GLM-4/这行执行需要根据世纪GLM-4源码下载存放位置。
FROM pytorch/pytorch:2.2.1-cuda12.1-cudnn8-runtime
ARG DEBIAN_FRONTEND=noninteractive
WORKDIR /app
RUN apt-get update
RUN apt-get install -y curl git
RUN rm -rf /var/lib/apt/lists/*
RUN pip config set global.index-url http://mirrors.aliyun.com/pypi/simple
RUN pip config set install.trusted-host mirrors.aliyun.com
RUN pip install jupyter && \
pip install --upgrade ipython && \
ipython kernel install --user
RUN cd /tmp && \
curl -fsSL https://deb.nodesource.com/setup_22.x -o nodesource_setup.sh && \
bash nodesource_setup.sh && \
apt-get install -y nodejs && \
rm -rf nodesource_setup.sh && \
node -v
RUN npm config set registry https://registry.npmmirror.com
RUN npm install -g pnpm
RUN node - add --global pnpm
COPY GLM-4/ /app/GLM-4/
WORKDIR /app/GLM-4/composite_demo/browser
RUN mkdir -p /u01/workspace/models/
RUN npm --version
RUN pnpm --version
RUN pnpm install
#/u01/workspace/chatglm4/GLM-4/composite_demo/browser/src/config.ts
#LOG_LEVEL: 'debug',
#BROWSER_TIMEOUT: 10000,
#BING_SEARCH_API_URL: 'https://api.bing.microsoft.com/',
#BING_SEARCH_API_KEY: '',
#HOST: 'localhost',
#PORT: 3000,
#/u01/workspace/chatglm4/GLM-4/composite_demo/src/tools/config.py
#BROWSER_SERVER_URL = 'http://localhost:3000'
#IPYKERNEL = 'glm-4-demo'
#ZHIPU_AI_KEY = ''
#COGVIEW_MODEL = 'cogview-3'
WORKDIR /app/GLM-4
RUN pip install --verbose --use-pep517 -r composite_demo/requirements.txt
RUN pip install --verbose --use-pep517 -r basic_demo/requirements.txt
RUN pip install huggingface_hub==0.23.1
EXPOSE 8501
CMD [ "streamlit","run", "composite_demo/src/main.py" ]
- 执行构建
docker build -t qingcloudtech/chatglm4:v1.0 .
运行docker
docker run -it --gpus all \
-p 8501:8501 \
-v /u01/workspace/models/glm-4-9b-chat:/app/GLM-4/models/glm-4-9b-chat \
-v /u01/workspace/models/glm-4v-9b:/app/GLM-4/models/glm-4v-9b \
-e CHAT_MODEL_PATH=/app/GLM-4/models/glm-4-9b-chat \
qingcloudtech/chatglm4:v1.0 streamlit run composite_demo/src/main.py
web 访问地址: http://127.0.0.1:8501
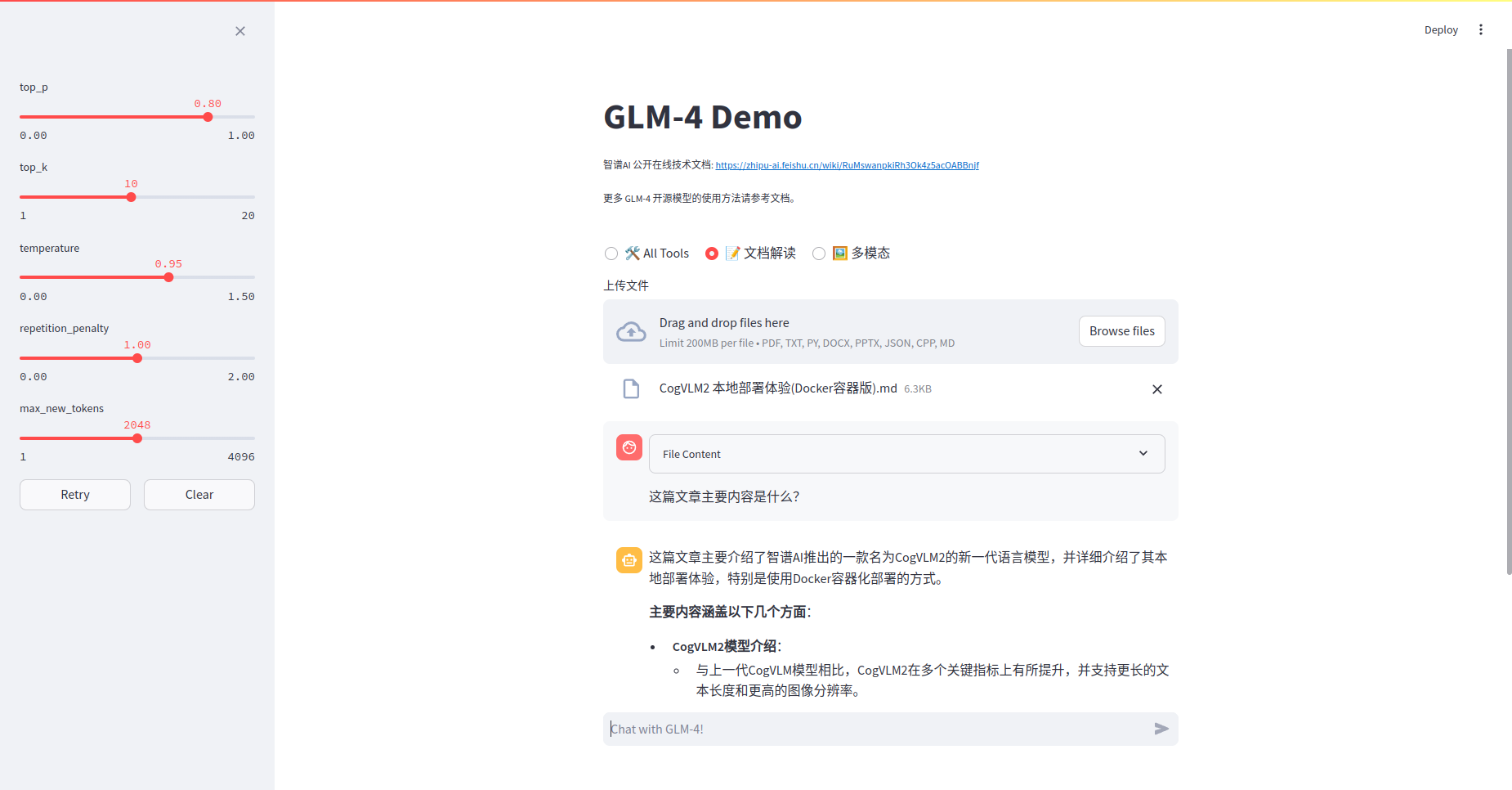
注意:默认24G显存状况下无法正常使用多模态模型。
openai api 方式运行
docker run -it --gpus all \
-p 8000:8000 \
-v /u01/workspace/models/glm-4-9b:/app/GLM-4/THUDM/glm-4-9b \
qingcloudtech/chatglm4:v1.0 python basic_demo/openai_api_server.py
测试验证
警告:
网页浏览、代码执行相关功能在该版本中并不支持,后续会逐步更新到容器中。尽情关注。
【Qinghub Studio 】更适合开发人员的低代码开源开发平台
【QingHub企业级应用统一部署】
【QingHub企业级应用开发管理】
【QingHub演示】
【https://qingplus.cn】

















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









