overridedef main(args: Array[String]): Unit = {
// Initialize logging if it hasn't been done yet. Keep track of whether logging needs to// be reset before the application starts.val uninitLog = initializeLogIfNecessary(true, silent = true)
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
// scalastyle:off println
printStream.println(appArgs)
// scalastyle:on println
}
// 默认值执行submit分支
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
/*
1. 根据集群管理方式和部署模式,准备启动环境,包括classpath,系统属性,app参数
2. 启动主类 ,这里的主类就是我们自己编写的app的主类
*/privatedef submit(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
val (childArgs, childClasspath, sparkConf, childMainClass) =
// 准备提交环境
prepareSubmitEnvironment(args)
def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
overridedef run(): Unit = {
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
}
})
} catch {
case e: Exception =>
// Hadoop's AuthorizationException suppresses the exception's stack trace, which// makes the message printed to the output by the JVM not very helpful. Instead,// detect exceptions with empty stack traces here, and treat them differently.if (e.getStackTrace().length == 0) {
// scalastyle:off println
printStream.println(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}")
// scalastyle:on println
exitFn(1)
} else {
throw e
}
}
} else {
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
}
}
// Let the main class re-initialize the logging system once it starts.if (uninitLog) {
Logging.uninitialize()
}
// In standalone cluster mode, there are two submission gateways:// (1) The traditional RPC gateway using o.a.s.deploy.Client as a wrapper// (2) The new REST-based gateway introduced in Spark 1.3// The latter is the default behavior as of Spark 1.3, but Spark submit will fail over// to use the legacy gateway if the master endpoint turns out to be not a REST server.if (args.isStandaloneCluster && args.useRest) {
try {
// scalastyle:off println
printStream.println("Running Spark using the REST application submission protocol.")
// scalastyle:on println
doRunMain()
} catch {
// Fail over to use the legacy submission gatewaycase e: SubmitRestConnectionException =>
printWarning(s"Master endpoint ${args.master} was not a REST server. " +
"Falling back to legacy submission gateway instead.")
args.useRest = false
submit(args, false)
}
// In all other modes, just run the main class as prepared
} else {
doRunMain()
}
}
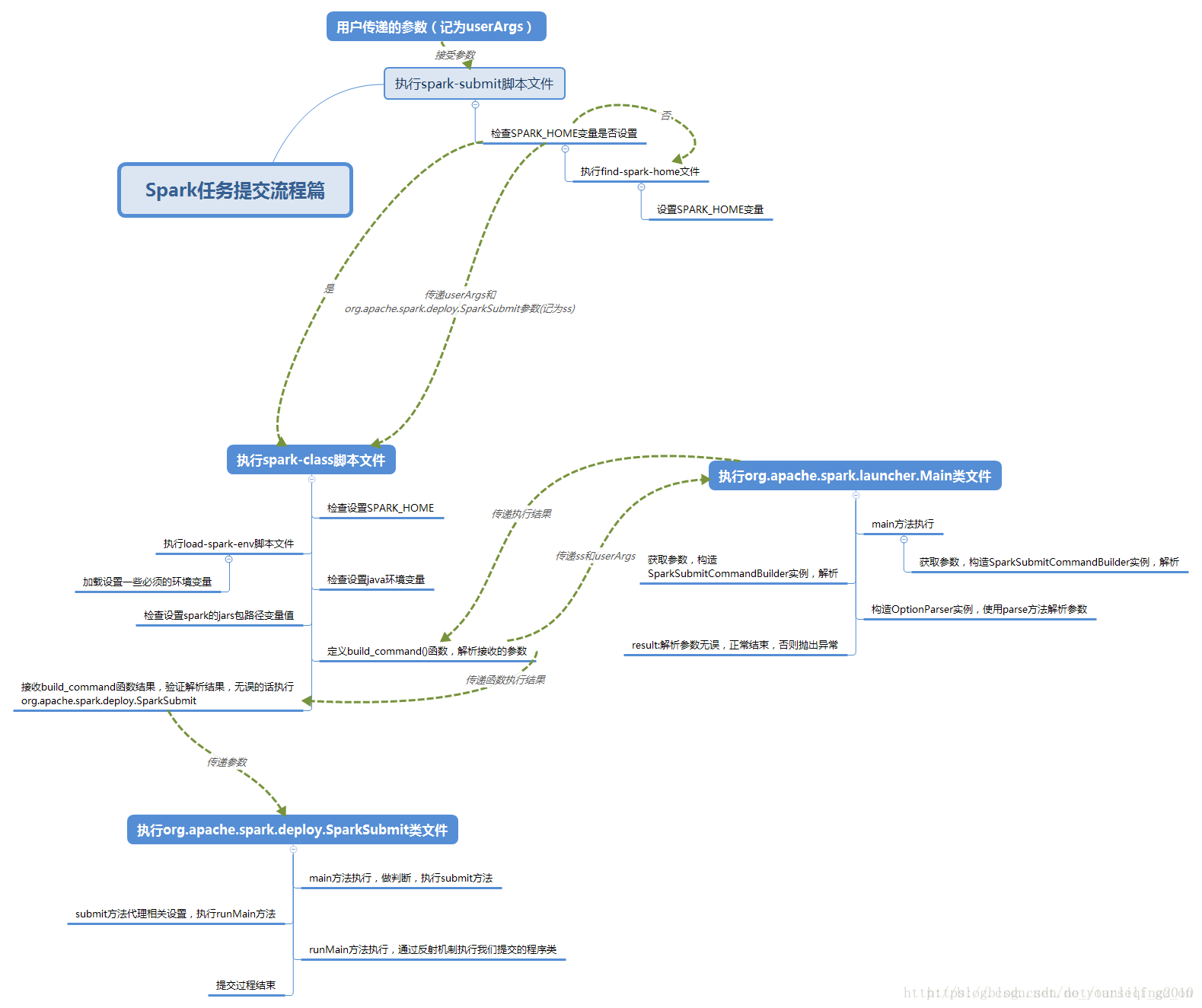
3 runMain
通过反射创建appclient对象,并执行start函数
privatedef runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sparkConf: SparkConf,
childMainClass: String,
verbose: Boolean): Unit = {
// scalastyle:off printlnif (verbose) {
printStream.println(s"Main class:\n$childMainClass")
printStream.println(s"Arguments:\n${childArgs.mkString("\n")}")
// sysProps may contain sensitive information, so redact before printing
printStream.println(s"Spark config:\n${Utils.redact(sparkConf.getAll.toMap).mkString("\n")}")
printStream.println(s"Classpath elements:\n${childClasspath.mkString("\n")}")
printStream.println("\n")
}
// scalastyle:on println// 获取类加载器val loader =
if (sparkConf.get(DRIVER_USER_CLASS_PATH_FIRST)) {
new ChildFirstURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
} else {
new MutableURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
}
Thread.currentThread.setContextClassLoader(loader)
// 提取classpath中的jar包for (jar <- childClasspath) {
addJarToClasspath(jar, loader)
}
var mainClass: Class[_] = null// 加载主类并初始化try {
mainClass = Utils.classForName(childMainClass)
} catch {
case e: ClassNotFoundException =>
e.printStackTrace(printStream)
if (childMainClass.contains("thriftserver")) {
// scalastyle:off println
printStream.println(s"Failed to load main class $childMainClass.")
printStream.println("You need to build Spark with -Phive and -Phive-thriftserver.")
// scalastyle:on println
}
System.exit(CLASS_NOT_FOUND_EXIT_STATUS)
case e: NoClassDefFoundError =>
e.printStackTrace(printStream)
if (e.getMessage.contains("org/apache/hadoop/hive")) {
// scalastyle:off println
printStream.println(s"Failed to load hive class.")
printStream.println("You need to build Spark with -Phive and -Phive-thriftserver.")
// scalastyle:on println
}
System.exit(CLASS_NOT_FOUND_EXIT_STATUS)
}
// 通过反射创建appval app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.newInstance().asInstanceOf[SparkApplication]
} else {
// SPARK-4170if (classOf[scala.App].isAssignableFrom(mainClass)) {
printWarning("Subclasses of scala.App may not work correctly. Use a main() method instead.")
}
new JavaMainApplication(mainClass)
}
@tailrecdef findCause(t: Throwable): Throwable = t match {
case e: UndeclaredThrowableException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: InvocationTargetException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: Throwable =>
e
}
// 启动apptry {
app.start(childArgs.toArray, sparkConf)
} catch {
case t: Throwable =>
findCause(t) match {
case SparkUserAppException(exitCode) =>
System.exit(exitCode)
case t: Throwable =>
throw t
}
}
}
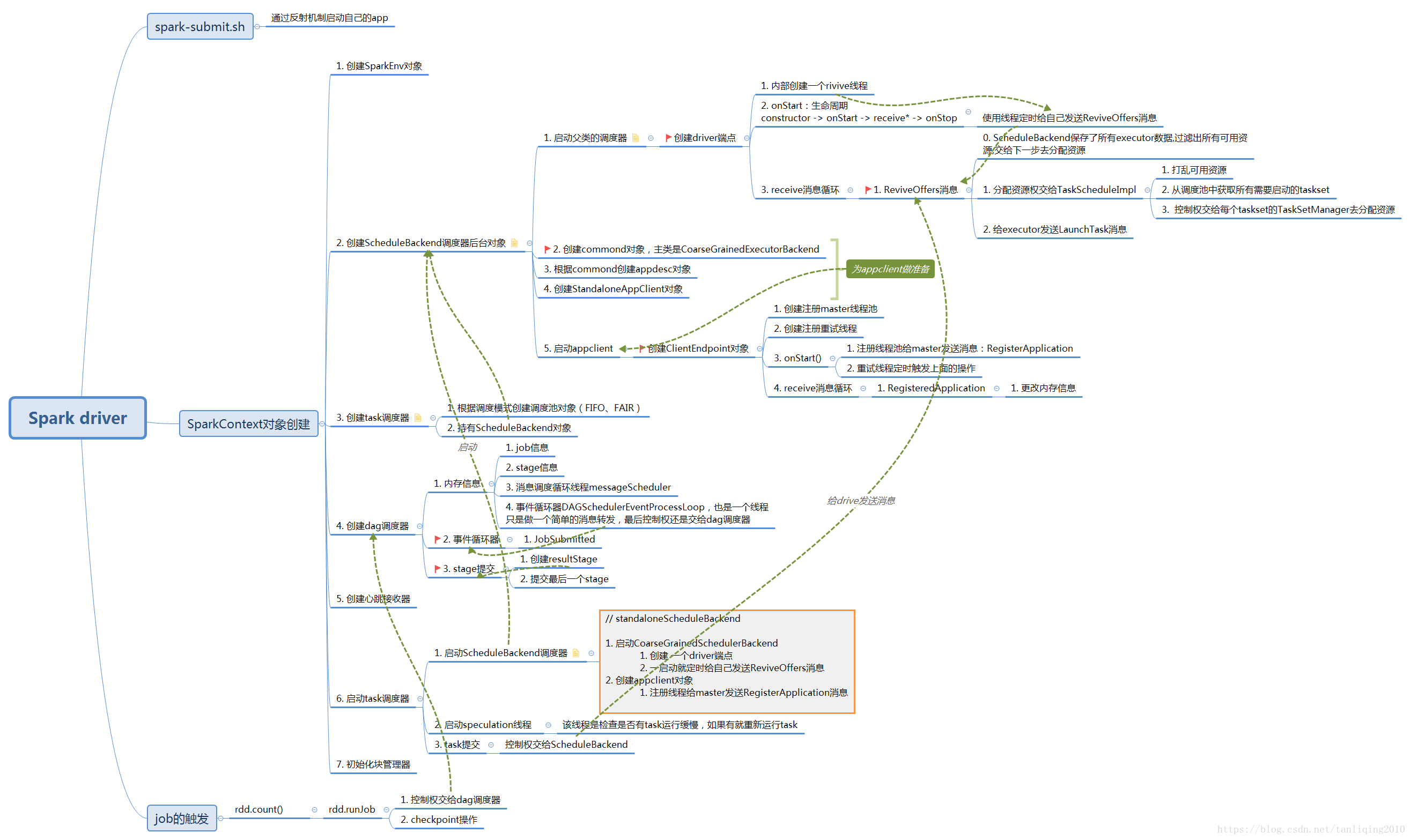
2 SparkContext执行过程
1 SparkContext保存的变量
var _env: SparkEnv———————————————> 保存spark实例运行中的所有数据,主要有RpcEnv,块管理器,map输出管理器
try {
// 配置文件相关操作
_conf = config.clone()
_conf.validateSettings()
if (!_conf.contains("spark.master")) {
thrownew SparkException("A master URL must be set in your configuration")
}
if (!_conf.contains("spark.app.name")) {
thrownew SparkException("An application name must be set in your configuration")
}
// log out spark.app.name in the Spark driver logs
logInfo(s"Submitted application: $appName")
// 如果app master运行在yarn集群上,那么必须设置app.id// System property spark.yarn.app.id must be set if user code ran by AM on a YARN clusterif (master == "yarn" && deployMode == "cluster" && !_conf.contains("spark.yarn.app.id")) {
thrownew SparkException("Detected yarn cluster mode, but isn't running on a cluster. " +
"Deployment to YARN is not supported directly by SparkContext. Please use spark-submit.")
}
if (_conf.getBoolean("spark.logConf", false)) {
logInfo("Spark configuration:\n" + _conf.toDebugString)
}
// Set Spark driver host and port system properties. This explicitly sets the configuration// instead of relying on the default value of the config constant.
_conf.set(DRIVER_HOST_ADDRESS, _conf.get(DRIVER_HOST_ADDRESS))
_conf.setIfMissing("spark.driver.port", "0")
_conf.set("spark.executor.id", SparkContext.DRIVER_IDENTIFIER)
_jars = Utils.getUserJars(_conf)
_files = _conf.getOption("spark.files").map(_.split(",")).map(_.filter(_.nonEmpty))
.toSeq.flatten
_eventLogDir =
if (isEventLogEnabled) {
val unresolvedDir = conf.get("spark.eventLog.dir", EventLoggingListener.DEFAULT_LOG_DIR)
.stripSuffix("/")
Some(Utils.resolveURI(unresolvedDir))
} else {
None
}
_eventLogCodec = {
val compress = _conf.getBoolean("spark.eventLog.compress", false)
if (compress && isEventLogEnabled) {
Some(CompressionCodec.getCodecName(_conf)).map(CompressionCodec.getShortName)
} else {
None
}
}
_listenerBus = new LiveListenerBus(_conf)
// Initialize the app status store and listener before SparkEnv is created so that it gets// all events.
_statusStore = AppStatusStore.createLiveStore(conf)
listenerBus.addToStatusQueue(_statusStore.listener.get)
/// 创建SparkEnv,spark执行环境// Create the Spark execution environment (cache, map output tracker, etc)
_env = createSparkEnv(_conf, isLocal, listenerBus)
// 保存在driver的内存中
SparkEnv.set(_env)
// If running the REPL, register the repl's output dir with the file server.
_conf.getOption("spark.repl.class.outputDir").foreach { path =>
val replUri = _env.rpcEnv.fileServer.addDirectory("/classes", new File(path))
_conf.set("spark.repl.class.uri", replUri)
}
_statusTracker = new SparkStatusTracker(this, _statusStore)
_progressBar =
if (_conf.get(UI_SHOW_CONSOLE_PROGRESS) && !log.isInfoEnabled) {
Some(new ConsoleProgressBar(this))
} else {
None
}
_ui =
if (conf.getBoolean("spark.ui.enabled", true)) {
Some(SparkUI.create(Some(this), _statusStore, _conf, _env.securityManager, appName, "",
startTime))
} else {
// For tests, do not enable the UI
None
}
// Bind the UI before starting the task scheduler to communicate// the bound port to the cluster manager properly
_ui.foreach(_.bind())
_hadoopConfiguration = SparkHadoopUtil.get.newConfiguration(_conf)
// Add each JAR given through the constructorif (jars != null) {
jars.foreach(addJar)
}
if (files != null) {
files.foreach(addFile)
}
//设置executor内存,
_executorMemory = _conf.getOption("spark.executor.memory")
.orElse(Option(System.getenv("SPARK_EXECUTOR_MEMORY")))
.orElse(Option(System.getenv("SPARK_MEM"))
.map(warnSparkMem))
.map(Utils.memoryStringToMb)
.getOrElse(1024)
// Convert java options to env vars as a work around// since we can't set env vars directly in sbt.for { (envKey, propKey) <- Seq(("SPARK_TESTING", "spark.testing"))
value <- Option(System.getenv(envKey)).orElse(Option(System.getProperty(propKey)))} {
executorEnvs(envKey) = value
}
Option(System.getenv("SPARK_PREPEND_CLASSES")).foreach { v =>
executorEnvs("SPARK_PREPEND_CLASSES") = v
}
// The Mesos scheduler backend relies on this environment variable to set executor memory.// TODO: Set this only in the Mesos scheduler.
executorEnvs("SPARK_EXECUTOR_MEMORY") = executorMemory + "m"
executorEnvs ++= _conf.getExecutorEnv
executorEnvs("SPARK_USER") = sparkUser
// We need to register "HeartbeatReceiver" before "createTaskScheduler" because Executor will// retrieve "HeartbeatReceiver" in the constructor. (SPARK-6640)// 创建心跳接受器,是一个rpc端点
_heartbeatReceiver = env.rpcEnv.setupEndpoint(
HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))
// Create and start the scheduler// 创建task调度器,创建StandaloneSchedulerBackendval (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
// 创建dag调度器
_dagScheduler = new DAGScheduler(this)
// 向心跳接收器发送TaskSchedulerIsSet消息
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's// constructor// 启动task调度器
_taskScheduler.start()
// 创建appId
_applicationId = _taskScheduler.applicationId()
_applicationAttemptId = taskScheduler.applicationAttemptId()
_conf.set("spark.app.id", _applicationId)
if (_conf.getBoolean("spark.ui.reverseProxy", false)) {
System.setProperty("spark.ui.proxyBase", "/proxy/" + _applicationId)
}
_ui.foreach(_.setAppId(_applicationId))
// 初始化块管理器
_env.blockManager.initialize(_applicationId)
// The metrics system for Driver need to be set spark.app.id to app ID.// So it should start after we get app ID from the task scheduler and set spark.app.id.
_env.metricsSystem.start()
// Attach the driver metrics servlet handler to the web ui after the metrics system is started.
_env.metricsSystem.getServletHandlers.foreach(handler => ui.foreach(_.attachHandler(handler)))
_eventLogger =
if (isEventLogEnabled) {
val logger =
new EventLoggingListener(_applicationId, _applicationAttemptId, _eventLogDir.get,
_conf, _hadoopConfiguration)
logger.start()
listenerBus.addToEventLogQueue(logger)
Some(logger)
} else {
None
}
// Optionally scale number of executors dynamically based on workload. Exposed for testing.val dynamicAllocationEnabled = Utils.isDynamicAllocationEnabled(_conf)
_executorAllocationManager =
if (dynamicAllocationEnabled) {
schedulerBackend match {
case b: ExecutorAllocationClient =>
Some(new ExecutorAllocationManager(
schedulerBackend.asInstanceOf[ExecutorAllocationClient], listenerBus, _conf))
case _ =>
None
}
} else {
None
}
_executorAllocationManager.foreach(_.start())
_cleaner =
if (_conf.getBoolean("spark.cleaner.referenceTracking", true)) {
Some(new ContextCleaner(this))
} else {
None
}
_cleaner.foreach(_.start())
setupAndStartListenerBus()
postEnvironmentUpdate()
postApplicationStart()
// Post init
_taskScheduler.postStartHook()
_env.metricsSystem.registerSource(_dagScheduler.metricsSource)
_env.metricsSystem.registerSource(new BlockManagerSource(_env.blockManager))
_executorAllocationManager.foreach { e =>
_env.metricsSystem.registerSource(e.executorAllocationManagerSource)
}
// Make sure the context is stopped if the user forgets about it. This avoids leaving// unfinished event logs around after the JVM exits cleanly. It doesn't help if the JVM// is killed, though.
logDebug("Adding shutdown hook") // force eager creation of logger
_shutdownHookRef = ShutdownHookManager.addShutdownHook(
ShutdownHookManager.SPARK_CONTEXT_SHUTDOWN_PRIORITY) { () =>
logInfo("Invoking stop() from shutdown hook")
stop()
}
} catch {
case NonFatal(e) =>
logError("Error initializing SparkContext.", e)
try {
stop()
} catch {
case NonFatal(inner) =>
logError("Error stopping SparkContext after init error.", inner)
} finally {
throw e
}
}
privatedef createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._
// When running locally, don't try to re-execute tasks on failure.val MAX_LOCAL_TASK_FAILURES = 1
master match {
// 本地模式case"local" =>
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, 1)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_REGEX(threads) =>
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*] estimates the number of cores on the machine; local[N] uses exactly N threads.val threadCount = if (threads == "*") localCpuCount else threads.toInt
if (threadCount <= 0) {
thrownew SparkException(s"Asked to run locally with $threadCount threads")
}
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_FAILURES_REGEX(threads, maxFailures) =>
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*, M] means the number of cores on the computer with M failures// local[N, M] means exactly N threads with M failuresval threadCount = if (threads == "*") localCpuCount else threads.toInt
val scheduler = new TaskSchedulerImpl(sc, maxFailures.toInt, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
// standalone模式case SPARK_REGEX(sparkUrl) =>
// 创建task调度器val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
// StandaloneSchedulerBackend只有TaskSchedulerImpl对象val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
// 初始化TaskSchedulerImpl
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_CLUSTER_REGEX(numSlaves, coresPerSlave, memoryPerSlave) =>
// Check to make sure memory requested <= memoryPerSlave. Otherwise Spark will just hang.val memoryPerSlaveInt = memoryPerSlave.toInt
if (sc.executorMemory > memoryPerSlaveInt) {
thrownew SparkException(
"Asked to launch cluster with %d MB RAM / worker but requested %d MB/worker".format(
memoryPerSlaveInt, sc.executorMemory))
}
val scheduler = new TaskSchedulerImpl(sc)
val localCluster = new LocalSparkCluster(
numSlaves.toInt, coresPerSlave.toInt, memoryPerSlaveInt, sc.conf)
val masterUrls = localCluster.start()
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
backend.shutdownCallback = (backend: StandaloneSchedulerBackend) => {
localCluster.stop()
}
(backend, scheduler)
// yarn模式或者其他模式case masterUrl =>
val cm = getClusterManager(masterUrl) match {
case Some(clusterMgr) => clusterMgr
case None => thrownew SparkException("Could not parse Master URL: '" + master + "'")
}
try {
val scheduler = cm.createTaskScheduler(sc, masterUrl)
val backend = cm.createSchedulerBackend(sc, masterUrl, scheduler)
cm.initialize(scheduler, backend)
(backend, scheduler)
} catch {
case se: SparkException => throw se
case NonFatal(e) =>
thrownew SparkException("External scheduler cannot be instantiated", e)
}
}
}
4 TaskSchedulerImpl初始化
创建调度池
def initialize(backend: SchedulerBackend) {
this.backend = backend
schedulableBuilder = {
schedulingMode match {
// FIFO调度器case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
// FAIR调度器case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
case _ =>
thrownew IllegalArgumentException(s"Unsupported $SCHEDULER_MODE_PROPERTY: " +
s"$schedulingMode")
}
}
schedulableBuilder.buildPools()
}
5 创建DAGScheduler对象
1. driver内存中数据结构
job,stage信息
创建DAGSchedulerEventProcessLoop
private[spark] val metricsSource: DAGSchedulerSource = new DAGSchedulerSource(this)
private[scheduler] val nextJobId = new AtomicInteger(0)
private[scheduler] def numTotalJobs: Int = nextJobId.get()
privateval nextStageId = new AtomicInteger(0)
private[scheduler] val jobIdToStageIds = new HashMap[Int, HashSet[Int]]
private[scheduler] val stageIdToStage = new HashMap[Int, Stage]
/**
* Mapping from shuffle dependency ID to the ShuffleMapStage that will generate the data for
* that dependency. Only includes stages that are part of currently running job (when the job(s)
* that require the shuffle stage complete, the mapping will be removed, and the only record of
* the shuffle data will be in the MapOutputTracker).
*/private[scheduler] val shuffleIdToMapStage = new HashMap[Int, ShuffleMapStage]
private[scheduler] val jobIdToActiveJob = new HashMap[Int, ActiveJob]
// Stages we need to run whose parents aren't doneprivate[scheduler] val waitingStages = new HashSet[Stage]
// Stages we are running right nowprivate[scheduler] val runningStages = new HashSet[Stage]
// Stages that must be resubmitted due to fetch failuresprivate[scheduler] val failedStages = new HashSet[Stage]
private[scheduler] val activeJobs = new HashSet[ActiveJob]
/**
* Contains the locations that each RDD's partitions are cached on. This map's keys are RDD ids
* and its values are arrays indexed by partition numbers. Each array value is the set of
* locations where that RDD partition is cached.
*
* All accesses to this map should be guarded by synchronizing on it (see SPARK-4454).
*/privateval cacheLocs = new HashMap[Int, IndexedSeq[Seq[TaskLocation]]]
// For tracking failed nodes, we use the MapOutputTracker's epoch number, which is sent with// every task. When we detect a node failing, we note the current epoch number and failed// executor, increment it for new tasks, and use this to ignore stray ShuffleMapTask results.//// TODO: Garbage collect information about failure epochs when we know there are no more// stray messages to detect.privateval failedEpoch = new HashMap[String, Long]
private [scheduler] val outputCommitCoordinator = env.outputCommitCoordinator
// A closure serializer that we reuse.// This is only safe because DAGScheduler runs in a single thread.privateval closureSerializer = SparkEnv.get.closureSerializer.newInstance()
/** If enabled, FetchFailed will not cause stage retry, in order to surface the problem. */privateval disallowStageRetryForTest = sc.getConf.getBoolean("spark.test.noStageRetry", false)
/**
* Whether to unregister all the outputs on the host in condition that we receive a FetchFailure,
* this is set default to false, which means, we only unregister the outputs related to the exact
* executor(instead of the host) on a FetchFailure.
*/private[scheduler] val unRegisterOutputOnHostOnFetchFailure =
sc.getConf.get(config.UNREGISTER_OUTPUT_ON_HOST_ON_FETCH_FAILURE)
/**
* Number of consecutive stage attempts allowed before a stage is aborted.
*/private[scheduler] val maxConsecutiveStageAttempts =
sc.getConf.getInt("spark.stage.maxConsecutiveAttempts",
DAGScheduler.DEFAULT_MAX_CONSECUTIVE_STAGE_ATTEMPTS)
privateval messageScheduler =
ThreadUtils.newDaemonSingleThreadScheduledExecutor("dag-scheduler-message")
private[scheduler] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
taskScheduler.setDAGScheduler(this)
overridedef start() {
//CoarseGrainedSchedulerBackend.startsuper.start()
// SPARK-21159. The scheduler backend should only try to connect to the launcher when in client// mode. In cluster mode, the code tCoarseGrainedSchedulerBackendhat submits the application to the Master needs to connect// to the launcher instead.if (sc.deployMode == "client") {
launcherBackend.connect()
}
// The endpoint for executors to talk to us// 创建driverurlval driverUrl = RpcEndpointAddress(
sc.conf.get("spark.driver.host"),
sc.conf.get("spark.driver.port").toInt,
CoarseGrainedSchedulerBackend.ENDPOINT_NAME).toString
val args = Seq(
"--driver-url", driverUrl,
"--executor-id", "{{EXECUTOR_ID}}",
"--hostname", "{{HOSTNAME}}",
"--cores", "{{CORES}}",
"--app-id", "{{APP_ID}}",
"--worker-url", "{{WORKER_URL}}")
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
val libraryPathEntries = sc.conf.getOption("spark.executor.extraLibraryPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
// When testing, expose the parent class path to the child. This is processed by// compute-classpath.{cmd,sh} and makes all needed jars available to child processes// when the assembly is built with the "*-provided" profiles enabled.val testingClassPath =
if (sys.props.contains("spark.testing")) {
sys.props("java.class.path").split(java.io.File.pathSeparator).toSeq
} else {
Nil
}
// Start executors with a few necessary configs for registering with the schedulerval sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
// appdesc中的主类就是CoarseGrainedExecutorBackend(重点,后面executor启动的时候,使用的就是该类)val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val webUrl = sc.ui.map(_.webUrl).getOrElse("")
val coresPerExecutor = conf.getOption("spark.executor.cores").map(_.toInt)
// If we're using dynamic allocation, set our initial executor limit to 0 for now.// ExecutorAllocationManager will send the real initial limit to the Master later.val initialExecutorLimit =
if (Utils.isDynamicAllocationEnabled(conf)) {
Some(0)
} else {
None
}
// 创建app描述符val appDesc = ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
webUrl, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit)
// 新建StandaloneAppClient(重点)
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start()
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)
}
5 CoarseGrainedSchedulerBackend启动函数
创建DriverEndpoint内部类对象,是一个rpc端点
overridedef start() {
val properties = new ArrayBuffer[(String, String)]
for ((key, value) <- scheduler.sc.conf.getAll) {
if (key.startsWith("spark.")) {
properties += ((key, value))
}
}
// TODO (prashant) send conf instead of properties
driverEndpoint = createDriverEndpointRef(properties)
}
protecteddef createDriverEndpointRef(
properties: ArrayBuffer[(String, String)]): RpcEndpointRef = {
rpcEnv.setupEndpoint(ENDPOINT_NAME, createDriverEndpoint(properties))
}
protecteddef createDriverEndpoint(properties: Seq[(String, String)]): DriverEndpoint = {
new DriverEndpoint(rpcEnv, properties)
}
// 被资源管理器调用,在slaves上预分配资源def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
// Mark each slave as alive and remember its hostname// Also track if new executor is addedvar newExecAvail = falsefor (o <- offers) {
// 把host 到executor的对应管理保存在内存中if (!hostToExecutors.contains(o.host)) {
hostToExecutors(o.host) = new HashSet[String]()
}
if (!executorIdToRunningTaskIds.contains(o.executorId)) {
//
hostToExecutors(o.host) += o.executorId
// 给ScheduleBackend的事件循环发送消息:ExecutorAdded
executorAdded(o.executorId, o.host)
// executor的id和主机对应关系保存在内存中
executorIdToHost(o.executorId) = o.host
// executorID与运行的task对应关系保存在内存中
executorIdToRunningTaskIds(o.executorId) = HashSet[Long]()
newExecAvail = true
}
for (rack <- getRackForHost(o.host)) {
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
}
}
// Before making any offers, remove any nodes from the blacklist whose blacklist has expired. Do// this here to avoid a separate thread and added synchronization overhead, and also because// updating the blacklist is only relevant when task offers are being made.
blacklistTrackerOpt.foreach(_.applyBlacklistTimeout())
// 过滤出正常的executorsval filteredOffers = blacklistTrackerOpt.map { blacklistTracker =>
offers.filter { offer =>
!blacklistTracker.isNodeBlacklisted(offer.host) &&
!blacklistTracker.isExecutorBlacklisted(offer.executorId)
}
}.getOrElse(offers)
// 打乱可分配资源,负载均衡val shuffledOffers = shuffleOffers(filteredOffers)
// Build a list of tasks to assign to each worker.// 在每一个worker上创建一个task列表,根据executor上的core数量除以每个task需要分配core的数量,// 就是executor上最多可以分配最大的task数量,返回二维数组,数组大小为// executor的数量 * (executor剩余cores / 每个task需要的core数)val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores / CPUS_PER_TASK))
// 返回一个一元数组,获取可用cpu资源列表val availableCpus = shuffledOffers.map(o => o.cores).toArray
/*
* 1. rootPool是taskschedule对象中保存的调度池对象,内部保存的是TaskSetManager对象,
* TaskSetManager对象是管理TaskSet对象的
* 2. getSortedTaskSetQueue:返回排序(FIFO,FIRE)好的TaskSet队列
*/val sortedTaskSets = rootPool.getSortedTaskSetQueue
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
taskSet.executorAdded()
}
}
// Take each TaskSet in our scheduling order, and then offer it each node in increasing order// of locality levels so that it gets a chance to launch local tasks on all of them.// NOTE: the preferredLocality order: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY// 循环TaskSet列表for (taskSet <- sortedTaskSets) {
var launchedAnyTask = falsevar launchedTaskAtCurrentMaxLocality = falsefor (currentMaxLocality <- taskSet.myLocalityLevels) {
do {
//
launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet(
taskSet, currentMaxLocality, shuffledOffers, availableCpus, tasks)
launchedAnyTask |= launchedTaskAtCurrentMaxLocality
} while (launchedTaskAtCurrentMaxLocality)
}
if (!launchedAnyTask) {
taskSet.abortIfCompletelyBlacklisted(hostToExecutors)
}
}
if (tasks.size > 0) {
hasLaunchedTask = true
}
return tasks
}
resourceOfferSingleTaskSet 为TaskSet分配资源
privatedef resourceOfferSingleTaskSet(
taskSet: TaskSetManager,
maxLocality: TaskLocality,
shuffledOffers: Seq[WorkerOffer],
availableCpus: Array[Int],
tasks: IndexedSeq[ArrayBuffer[TaskDescription]]) : Boolean = {
var launchedTask = false// nodes and executors that are blacklisted for the entire application have already been// filtered out by this point// 循环每一个executorfor (i <- 0 until shuffledOffers.size) {
// 获取executorId和主机val execId = shuffledOffers(i).executorId
val host = shuffledOffers(i).host
// 如果executor中可用cpu可以达到task要求if (availableCpus(i) >= CPUS_PER_TASK) {
try {
// 控制权交给TaskSetManager去分配资源,返回taskdescfor (task <- taskSet.resourceOffer(execId, host, maxLocality)) {
tasks(i) += task
val tid = task.taskId
taskIdToTaskSetManager(tid) = taskSet
taskIdToExecutorId(tid) = execId
executorIdToRunningTaskIds(execId).add(tid)
availableCpus(i) -= CPUS_PER_TASK
assert(availableCpus(i) >= 0)
launchedTask = true
}
} catch {
case e: TaskNotSerializableException =>
logError(s"Resource offer failed, task set ${taskSet.name} was not serializable")
// Do not offer resources for this task, but don't throw an error to allow other// task sets to be submitted.return launchedTask
}
}
}
return launchedTask
}
resourceOffer TaskSetManager对象分配资源
def resourceOffer(
execId: String,
host: String,
maxLocality: TaskLocality.TaskLocality)
: Option[TaskDescription] =
{
// 获取黑名单资源列表val offerBlacklisted = taskSetBlacklistHelperOpt.exists { blacklist =>
blacklist.isNodeBlacklistedForTaskSet(host) ||
blacklist.isExecutorBlacklistedForTaskSet(execId)
}
if (!isZombie && !offerBlacklisted) {
val curTime = clock.getTimeMillis()
var allowedLocality = maxLocality
if (maxLocality != TaskLocality.NO_PREF) {
allowedLocality = getAllowedLocalityLevel(curTime)
if (allowedLocality > maxLocality) {
// We're not allowed to search for farther-away tasks
allowedLocality = maxLocality
}
}
dequeueTask(execId, host, allowedLocality).map { case ((index, taskLocality, speculative)) =>
// Found a task; do some bookkeeping and return a task descriptionval task = tasks(index)
val taskId = sched.newTaskId()
// Do various bookkeeping
copiesRunning(index) += 1val attemptNum = taskAttempts(index).size
val info = new TaskInfo(taskId, index, attemptNum, curTime,
execId, host, taskLocality, speculative)
taskInfos(taskId) = info
taskAttempts(index) = info :: taskAttempts(index)
// Update our locality level for delay scheduling// NO_PREF will not affect the variables related to delay schedulingif (maxLocality != TaskLocality.NO_PREF) {
currentLocalityIndex = getLocalityIndex(taskLocality)
lastLaunchTime = curTime
}
// Serialize and return the taskval serializedTask: ByteBuffer = try {
ser.serialize(task)
} catch {
// If the task cannot be serialized, then there's no point to re-attempt the task,// as it will always fail. So just abort the whole task-set.case NonFatal(e) =>
val msg = s"Failed to serialize task $taskId, not attempting to retry it."
logError(msg, e)
abort(s"$msg Exception during serialization: $e")
thrownew TaskNotSerializableException(e)
}
if (serializedTask.limit > TaskSetManager.TASK_SIZE_TO_WARN_KB * 1024 &&
!emittedTaskSizeWarning) {
emittedTaskSizeWarning = true
logWarning(s"Stage ${task.stageId} contains a task of very large size " +
s"(${serializedTask.limit / 1024} KB). The maximum recommended task size is " +
s"${TaskSetManager.TASK_SIZE_TO_WARN_KB} KB.")
}
addRunningTask(taskId)
// We used to log the time it takes to serialize the task, but task size is already// a good proxy to task serialization time.// val timeTaken = clock.getTime() - startTimeval taskName = s"task ${info.id} in stage ${taskSet.id}"
logInfo(s"Starting $taskName (TID $taskId, $host, executor ${info.executorId}, " +
s"partition ${task.partitionId}, $taskLocality, ${serializedTask.limit} bytes)")
sched.dagScheduler.taskStarted(task, info)
new TaskDescription(
taskId,
attemptNum,
execId,
taskName,
index,
sched.sc.addedFiles,
sched.sc.addedJars,
task.localProperties,
serializedTask)
}
} else {
None
}
}
4. job的提交
stage的划分
/** Called when stage's parents are available and we can now do its task. */privatedef submitMissingTasks(stage: Stage, jobId: Int) {
logDebug("submitMissingTasks(" + stage + ")")
// First figure out the indexes of partition ids to compute.// 找到stage的丢失的分区val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
// Use the scheduling pool, job group, description, etc. from an ActiveJob associated// with this Stageval properties = jobIdToActiveJob(jobId).properties
runningStages += stage
// SparkListenerStageSubmitted should be posted before testing whether tasks are// serializable. If tasks are not serializable, a SparkListenerStageCompleted event// will be posted, which should always come after a corresponding SparkListenerStageSubmitted// event.
stage match {
case s: ShuffleMapStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1)
case s: ResultStage =>
outputCommitCoordinator.stageStart(
stage = s.id, maxPartitionId = s.rdd.partitions.length - 1)
}
// 计算需要计算区分的最佳位置val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
// If there are tasks to execute, record the submission time of the stage. Otherwise,// post the even without the submission time, which indicates that this stage was// skipped.if (partitionsToCompute.nonEmpty) {
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
}
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
// TODO: Maybe we can keep the taskBinary in Stage to avoid serializing it multiple times.// Broadcasted binary for the task, used to dispatch tasks to executors. Note that we broadcast// the serialized copy of the RDD and for each task we will deserialize it, which means each// task gets a different copy of the RDD. This provides stronger isolation between tasks that// might modify state of objects referenced in their closures. This is necessary in Hadoop// where the JobConf/Configuration object is not thread-safe.var taskBinary: Broadcast[Array[Byte]] = null// task序列化,并且广播task数据try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).// For ResultTask, serialize and broadcast (rdd, func).val taskBinaryBytes: Array[Byte] = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort executionreturncase NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
// 根据依赖关系,创建ShuffleMapTask,ResultTaskval tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
if (tasks.size > 0) {
logInfo(s"Submitting ${tasks.size} missing tasks from $stage (${stage.rdd}) (first 15 " +
s"tasks are for partitions ${tasks.take(15).map(_.partitionId)})")
// 控制权交给task调度器
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
} else {
// Because we posted SparkListenerStageSubmitted earlier, we should mark// the stage as completed here in case there are no tasks to run
markStageAsFinished(stage, None)
val debugString = stage match {
case stage: ShuffleMapStage =>
s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})"case stage : ResultStage =>
s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})"
}
logDebug(debugString)
submitWaitingChildStages(stage)
}
}
task的提交
overridedef submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
// 创建taskset管理器val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
thrownew IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
overridedef run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
backend.reviveOffers()
}







 本文详细介绍了Apache Spark的任务提交过程、SparkContext的初始化及执行流程。从spark-submit脚本开始,逐步解析如何启动应用程序,再到SparkContext内部的组件如TaskSchedulerImpl、DAGScheduler等的初始化与工作原理。
本文详细介绍了Apache Spark的任务提交过程、SparkContext的初始化及执行流程。从spark-submit脚本开始,逐步解析如何启动应用程序,再到SparkContext内部的组件如TaskSchedulerImpl、DAGScheduler等的初始化与工作原理。

















 5440
5440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









