







回看了一下之前自己大学时候总结的C渣渣博客,没想到自己毕业不知不觉已经在java的开发之路上走了好几个月了,在java开发上还是一只小菜鸡,希望自己快点成长吧,借鉴多个大佬优秀博客,整理出来的java.Collection集合,欢迎大家纠错,菜鸡慢慢进步吧~~
ヽ(◕ฺˇд ˇ◕)ノ (ง •̀_•́)ง (ฅ´ω`ฅ) ✿◡‿◡
1.1 集合概述
集合是什么?
集合是java中提供的一种容器,可以用来存储多个数据。
1.2 集合框架
JAVASE提供了满足各种需求的API,在使用这些API前,先了解其继承与接口操作架构,才能了解何时采用哪个类,以及类之间如何彼此合作,从而达到灵活应用。
集合按照其存储结构可以分为两大类,分别是
单列集合java.util.Collection
双列集合java.util.Map。
接下来通过两张图来描述整个集合类的继承体系。
说明:
黄色:代表接口
绿色:代表抽象接口
蓝色:代表实现类


本篇文章我们主要来看看Collection 的相关内容。
Collection
2.1 Collection 简介
集合和数组既然都是容器,它们有什么区别呢?
1、数组长度固定,集合长度可变。
数组是静态的,一个数组实例具有固定的大小,一旦创建了就无法改变容量了,而且生命周期也是不能改变的,还有数组也会做边界检查,如果发现有越界现象,会报RuntimeException异常错误,当然检查边界会以效率为代价。而集合的长度是可变的,可以动态扩展容量,可以根据需要动态改变大小。
2、数组中只能是同一类型的元素且可以存储基本数据类型和对象。集合不能存放基本数据类型,只能存对象,类型可以不一致。
3、集合以类的形式存在,具有封装、继承、多态等类的特性,通过简单的方法和属性即可实现各种复杂操作,大大提高了软件的开发效率
那么集合与数组之间可以进行转换吗?答案是可以的
数组转换为集合:Arrays.asList(数组)
易错点:
1、不能将基本类型数组作为asList的参数
2、不能将数组作为asList参数后,修改数组或List
3、数组转换为集合后,不能进行增删元素
剖析原因:
1、我们通过IDEA debug发现,asList()返回的是 java.util.Arrays.ArrayList,Arrays.ArrayList参数为可变长泛型,而基本类型是无法泛型化的

2、Arrays.ArrayList将外部数组的引用直接通过“=”赋予内部的泛型数组,所以当外部数组或集合改变时,数组和集合会同步变化,这在平时我们编码时可能产生莫名的问题。

3、Arrays.ArrayList继承了abstractList抽象类,但是没有直接实现List接口,并没有重写add,remove等方法,所以它会调用父类AbstractList的方法,而父类的方法中抛出的却是异常信息。
集合转换为数组:集合.toArray();
toArray()方法会返回List中所有元素构成的数组,并且数组类型是Object[]。还要注意一点就是,返回的数组是新生成的一个数组,也就是说,多次运行toArray()方法会获得不同的数组对象,但是这些数组对象中内容一样的。也就是说,toArray()返回的数组是安全的,你可以对它进行任意的修改,其原因就是List不会维持一个对该返回的数组的引用。
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
Object[] objects1 = list.toArray();
Object[] objects2 = list.toArray();
System.out.println("objects1 == objects2 : "+(objects1 == objects2));
objects1[1]=4;
System.out.println("show objects1: "+ Arrays.toString(objects1));
System.out.println("show objects2: "+ Arrays.toString(objects2));
System.out.println("show list: "+list);
}
运行结果:
objects1 == objects2 : false
show objects1: [1, 4]
show objects2: [1, 2]
show list: [1, 2]
Collection:单列集合类的根接口,用于存储一系列符合某种规则的元素,它有三个重要的子接口,分别是java.util.List,java.util.Set和java.util.queue。
List的特点是元素有序、元素可重复。
Set的特点是元素无序,而且不可重复。
Queue的特点是先进先出。
2.2 Collection 框架示意图

2.3 Collection 常用功能
Collection是所有单列集合的父接口,因此在Collection中定义了单列集合(List和Set)通用的一些方法,这些方法适用于操作所有的单列集合。方法如下:
- public boolean add(E e):把给定的对象添加到当前集合中 。
- public void clear():清空集合中所有的元素。
- public boolean remove(E e):把给定的对象在当前集合中删除。
- public boolean contains(E e):判断当前集合中是否包含给定的对象。
- public boolean isEmpty():判断当前集合是否为空。
- public int size():返回集合中元素的个数。
- public Object[] toArray():把集合中的元素,存储到数组中。
代码示例:
package com.tanrui.collection;
import java.util.ArrayList;
import java.util.Collection;
public class DemoCellection {
public static void main(String[] args) {
//创建集合对象
Collection<String> coll = new ArrayList<String>();
//add
coll.add("李明");
coll.add("小花");
coll.add("张三");
System.out.println(coll);
//contains
System.out.println("判断 张三 是否在集合中 :" + coll.contains("张三"));
//remove
System.out.println("删除张三 :" + coll.remove("张三"));
System.out.println("删除张三后集合为 :" + coll);
//size
System.out.println("集合中有 :" + coll.size() + "个元素");
//toArray()
Object[] objects = coll.toArray();
for (int i = 0; i < objects.length; i++) {
System.out.println("集合为 :" + objects[i]);
}
//clear()
coll.clear();
System.out.println("clear后集合为:" + coll);
//isEmpty()
System.out.println("集合是否为空:" +coll.isEmpty());
}
}
运行结果为:
[李明, 小花, 张三]
判断 张三 是否在集合中 :true
删除张三 :true
删除张三后集合为 :[李明, 小花]
集合中有 :2个元素
集合为 :李明
集合为 :小花
clear后集合为:[]
集合是否为空:true
List接口
3.1 List接口介绍
java.util.List接口继承自Collection接口,在List集合元素可重复、元素有序。所有的元素是以一种线性方式进行存储的,在程序中可以通过索引来访问集合中的指定元素,而且元素的存入顺序和取出顺序一致。
List接口特点:
- 元素存取有序
- 带有索引的集合:与数组的索引是一个道理
- 元素重复:通过元素的equals方法,来比较是否为重复的元素。
3.2 List接口中常用方法
List作为Collection集合的子接口,不但继承了Collection接口中的全部方法,还有一些根据元素索引来操作集合的特有方法,如下:
- public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。
- public E get(int index):返回集合中指定位置的元素。
- public E remove(int index):移除列表中指定位置的元素, 返回的是被移除的元素。
- public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素。
代码示例:
public class ListDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
// add
list.add("张三");
list.add("李四");
list.add("赵让");
System.out.println(list);
// add(int index,String s) 往指定位置添加
list.add(1,"李亮");
System.out.println(list);
// String remove(int index) 删除指定位置元素 返回被删除元素
// 删除索引位置为2的元素
System.out.println("删除索引位置为2的元素");
System.out.println(list.remove(2));
System.out.println(list);
// String set(int index,String s)
// 在指定位置 进行 元素替代(改)
// 修改指定位置元素
list.set(0, "太二");
System.out.println(list);
// String get(int index) 获取指定位置元素
// 跟size() 方法一起用 来 遍历的
for(int i = 0;i<list.size();i++){
System.out.println(list.get(i));
}
//还可以使用增强for
for (String string : list) {
System.out.println(string);
}
}
}
List的子类
4.1 ArrayList
java.util.ArrayList集合数据存储的结构是数组结构—元素增删慢,查找快。
由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList是最常用的集合。
ArrayList是基于数组实现的,ArrayList内部维护一个数组elementData,用于保存列表元素,基于数组的数组这数据结构,我们知道,其索引元素是非常快:
public E get(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
return (E) elementData[index]; // 索引无需遍历,效率非常高!
}
public E set(int index, E element) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
E oldValue = (E) elementData[index];
elementData[index] = element; // 索引无需遍历,效率非常高!
return oldValue;
}
从插入操作的源码看,插入前,要先判断是否需要扩容,然后把Index后面的元素都偏移一位,这里的偏移是需要把元素复制后,再赋值当前元素的后一索引的位置。显然,这样一来,插入一个元素,牵连到多个元素,效率自然就低了:
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
ensureCapacityInternal(size + 1); // 先判断是否需要扩容
System.arraycopy(elementData, index, elementData, index + 1, // 把index后面的元素都向后偏移一位
size - index);
elementData[index] = element;
size++;
}
同样,删除一个元素,需要把index后面的元素向前偏移一位,填补删除的元素,也是牵连了多个元素:
public E remove(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0) {
// 把index后面的元素向前偏移一位,填补删除的元素
System.arraycopy(elementData, index + 1, elementData, index,
numMoved);
}
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
4.1.1 浅谈ArrayList动态扩容
总的来说就是分两步:
1、扩容
把原来的数组复制到另一个内存空间更大的数组中
2、添加元素
把新元素添加到扩容以后的数组中
ArrayList扩容发生在add()方法调用的时候,详看源码:
public boolean add(E e) {
//扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
根据意思可以看出ensureCapacityInternal()是用来扩容的,
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
通过方法calculateCapacity(elementData, minCapacity)获取:
private static int calculateCapacity(Object[] elementData, int minCapacity) {
//如果传入的是个空数组则最小容量取默认容量与minCapacity之间的最大值
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
ensureExplicitCapacity方法可以判断是否需要扩容:
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 如果最小需要空间比elementData的内存空间要大,则需要扩容
if (minCapacity - elementData.length > 0)
//扩容
grow(minCapacity);
}
接下来重点来了,ArrayList扩容的关键方法grow():
private void grow(int minCapacity) {
// 获取到ArrayList中elementData数组的内存空间长度
int oldCapacity = elementData.length;
// 扩容至原来的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 再判断一下新数组的容量够不够,够了就直接使用这个长度创建新数组,
// 不够就将数组长度设置为需要的长度
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//若预设值大于默认的最大值检查是否溢出
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 调用Arrays.copyOf方法将elementData数组指向新的内存空间时newCapacity的连续空间
// 并将elementData的数据复制到新的内存空间
elementData = Arrays.copyOf(elementData, newCapacity);
}
从此方法中我们可以清晰的看出其实ArrayList扩容的本质就是计算出新的扩容数组的size后实例化,并将原有数组内容复制到新数组中去。到此扩容就基本完成了。
4.2 LinkedList
java.util.LinkedList集合数据存储的结构是双向链表结构-----元素增删快,查找慢的集合。
插入元素只需新建一个node,再把前后指针指向对应的前后元素即可:
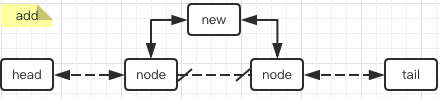
// 链尾追加
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
// 指定节点前插入
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
// 插入节点,succ为Index的节点,可以看到,是插入到index节点的前一个节点
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
删除元素只要把删除节点的链剪掉,再把前后节点连起来就搞定:
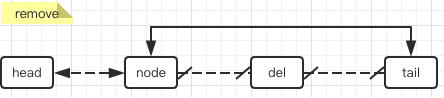
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
// 链头
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
// 链尾
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
但由于链表我们只知道头和尾,中间的元素要遍历获取的,所以导致了访问元素时,效率就不好:
Node<E> node(int index) {
// 使用了二分法
if (index < (size >> 1)) { // 如果索引小于二分之一,从first开始遍历
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { // 如果索引大于二分之一,从last开始遍历
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
4.3 Vector 和 Stack
Vector和Stack我们几乎是不使用的了,了解一下缺点:
- Vector线程同步影响效率
Vector也是基于数组实现,同样支持快速访问,并且线程安全因为跟ArrayList一样,都是基于数组实现,所以ArrayList具有的优势和劣势Vector同样也有,只是Vector在每个方法都加了同步锁,所以它是线程安全的。但我们知道,同步会大大影响效率的,所以在不需要同步的情况下,Vector的效率就不如ArrayList了。所以我们在不需要同步的情况下,优先选择ArrayList;而在需要同步的情况下,也不是使用Vector,而是使用SynchronizedList。 - Vector的扩容机制不完善
Vector默认容量也是10,跟ArrayList不同的是,Vector每次扩容的大小是可以指定的,如果不指定,每次扩容原来容量大小的2倍。不像ArrayList,如果是用Vector的默认构造函数创建实例,那么第一次添加元素就需要扩容,但不会扩容到默认容量10,只会根据用户指定或两倍的大小扩容。如果容量大小和扩容大小都不指定,开始可能会频繁地进行扩容
如果指定了容量大小不指定扩容大小,以2倍的大小扩容会浪费很多资源,如果指定了扩容大小,扩容大小就固定了,不管数组多大,都按这大小来扩容,那么这个扩容大小的取值总有不理想的时候。
protected Object[] elementData; // 元素数组
protected int elementCount; // 元素数量
protected int capacityIncrement; // 扩容大小
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
public Vector(int initialCapacity) {
this(initialCapacity, 0); // 默认扩容大小为0,那么扩容时会增大两倍
}
public Vector() {
this(10); // 默认容量为10
}
public synchronized void ensureCapacity(int minCapacity) {
if (minCapacity > 0) {
modCount++;
ensureCapacityHelper(minCapacity);
}
}
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0) // 大于当前容量就扩容
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity); // 默认扩容两倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
- Stack继承于Vector,在其基础上扩展了栈的方法
Stack我们也不使用了,它只是添加多几个栈常用的方法(这个LinkedList也有),简单来看下它们的实现:
// 进栈
public E push(E item) {
addElement(item);
return item;
}
// 出栈
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
Set接口
java.util.Set接口和java.util.List接口一样,同样继承自Collection接口,它与Collection接口中的方法基本一致,并没有对Collection接口进行功能上的扩充,只是比Collection接口更加严格了。与List接口不同的是,Set接口中元素无序且不重复,刚好全与list相反,set会以某种规则保证存入的元素不出现重复。
以HashSet 为例,具体说明Set如何保证不重复:
首先是HasHSet 的构造方法:
public HashSet() {
map = new HashMap<>();
}
可以看到,hashSet 实际上就是封装了HashMap,其他的构造方法也是分别调用hashMap的构造
之后是Add 方法,当HashSet进行add操作时,其实是将要add的元素作为map的key,将PRESENT这个对象作为map的value,存入map中,并且需要注意到add方法的返回值是一个boolean。
因为HashSet的底层是由HashMap实现的,而HashSet的add方法,是将元素作为map的key进行存储的,map的key是不会重复的,所以HashSet中的元素也不会重复。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
也是调用map中的put 方法,而map的put方法实际上是调用putVal() 方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断tab数组是否为空,为空的话进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//获取元素在数组对应的index,并判断该位置是否有值,没有的话新建一个Node
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//否则的话说明该位置已经存在元素
else {
Node<K,V> e; K k;
//当hash值相等并且key 值也相当的情况下,将已经存在的节点P赋值个空节点e
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//在上面的基础上,此时的e!= null,会将新的value值替换之前旧的value值,
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
总结:在插入操作中首先是会判断hashCode()方法返回是否相同,在相同的条件下再去比较key.equals(key),如果这个两个key的equals比较返回true。那么新添加的value会覆盖原来的value
Set接口子类
5.1 HashSet
java.util.HashSet底层的实现其实是一个java.util.HashMap支持。
HashSet是根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。保证元素唯一性的方式依赖于:hashCode与equals方法。
代码示例:
public class HashSetDemo {
public static void main(String[] args) {
//创建 Set集合
HashSet<String> set = new HashSet<String>();
//添加元素
set.add(new String("张三"));
set.add("李四");
set.add("王二");
set.add("张三");
//遍历
for (String name : set) {
System.out.println(name);
}
}
}
运行结果:
张三
李四
王二
即,重复的元素,set不存储
HashSet集合存储数据的结构—哈希表
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。


因此保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的,如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。HashSet没有提供get()方法,是同HashMap一样,Set内部是无序的,只能通过迭代的方式获得。
5.2 LinkedHashSet
LinkedHashSet是 HashSet的子类,底层数据结构由哈希表和链表组成。
哈希表:保证元素的唯一性
链表:保证元素有序(存储和取出顺序一致)
代码示例:
public class LinkedHashSetDemo {
public static void main(String[] args) {
Set<String> set = new LinkedHashSet<String>();
set.add("秃头哥");
set.add("地中海哥");
set.add("平头哥");
set.add("假发哥");
Iterator<String> it = set.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
5.3 TreeSet
TreeSet底层是红黑树,TreeSet 真正的比较是依赖于元素的 compareTo()方法,而这个方法是定义在 Comparable 接口里面的。
所以,你要想重写该方法,就必须先实现 Comparable 接口。这个接口表示的就是自然排序。

代码示例:
public class TreeSetTest {
public static void main(String[] args) {
testTreeSetAPIs();
}
// 测试TreeSet的api
public static void testTreeSetAPIs() {
String val;
// 新建TreeSet
TreeSet tSet = new TreeSet();
// 将元素添加到TreeSet中
tSet.add("aaa");
// Set中不允许重复元素,所以只会保存一个“aaa”
tSet.add("aaa");
tSet.add("bbb");
tSet.add("eee");
tSet.add("ddd");
tSet.add("ccc");
System.out.println("TreeSet:"+tSet);
// 打印TreeSet的实际大小
System.out.printf("size : %d\n", tSet.size());
// 导航方法
// floor(小于、等于)
System.out.printf("floor bbb: %s\n", tSet.floor("bbb"));
// lower(小于)
System.out.printf("lower bbb: %s\n", tSet.lower("bbb"));
// ceiling(大于、等于)
System.out.printf("ceiling bbb: %s\n", tSet.ceiling("bbb"));
}
}
Queue接口
6.1 Queue接口介绍
队列是一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
在队列这种数据结构中,最先插入的元素将是最先被删除的元素;反之最后插入的元素将是最后被删除的元素,因此队列又称为“先进先出”(FIFO—first in first out)的线性表。
Queue使用时要尽量避免Collection的add()和remove()方法,而是要使用offer()来加入元素,使用poll()来获取并移出元素。它们的优点是通过返回值可以判断成功与否,add()和remove()方法在失败的时候会抛出异常
Queue是非线程安全的。
时间复杂度:
● 索引: O(n)
● 搜索: O(n)
● 插入: O(1)
● 移除: O(1)
6.2 Queue接口中常用的方法
- booleab add(E e):插入指定的元素要队列中,并返回true或者false,如果队列数量超过了容量,则抛出IllegalStateException的异常。
- boolean offer(E e):插入指定的元素到队列,并返回true或者false,如果队列数量超过了容量,不会抛出异常,只会返回false。
- E remove():搜索并删除最顶层的队列元素,如果队列为空,则抛出一个Exception
- E poll():搜索并删除最顶层的队列元素,如果队列为空,则返回null
- E element():检索但不删除并返回队列中最顶层的元素,如果该队列为空,则抛出一个Exception
- E peek(): 检索但不删除并返回最顶层的元素,如果该队列为空,则返回null
值得注意的是LinkedList实现了Deque接口,Deque接口继承了Queue接口,所以LinkedList也可以当做Queue来操作:
public class QueueTest {
public static void main(String[] args){
LinkedList linkedList = new LinkedList();
System.out.println("poll搜索并删除最顶层的队列元素,如果队列为空,则返回null:"+linkedList.poll());
// System.out.println("搜索并删除最顶层的队列元素,如果队列为空,则抛出一个Exception:"+linkedList.remove());
linkedList.add("100");
linkedList.add("200");
System.out.println("LinkedList数量"+linkedList.size());
linkedList.poll();
System.out.println("LinkedList数量"+linkedList.size());
System.out.println("检索但不删除并返回最顶层的元素,如果该队列为空,则返回nul:"+linkedList.peek());
}
Iterator迭代器
7.1 Iterator接口
在程序开发中,经常需要遍历集合中的所有元素。针对这种需求,JDK专门提供了一个接口java.util.Iterator。
Iterator接口也是Java集合中的一员,但它与Collection、Map接口有所不同,Collection接口与Map接口主要用于存储元素,Iterator主要用于迭代访问(即遍历)Collection中的元素,因此Iterator对象也被称为迭代器。
想要遍历Collection集合,那么就要获取该集合迭代器完成迭代操作,获取迭代器的方法:
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素。
7.2 迭代的概念
即Collection集合元素的通用获取方式。在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续在判断,如果还有就再取出出来。一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
Iterator接口的常用方法有:
- public E next() : 返回迭代的下一个元素。
- public boolean hasNext() : 如果仍有元素可以迭代,则返回
true。
代码示例:
package com.tanrui.collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class IteratorDemo {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<String>();
coll.add("张三");
coll.add("李四");
coll.add("王二");
//使用迭代器遍历--每个集合对象都有自己的迭代器
Iterator<String> it = coll.iterator();
while (it.hasNext()) { //判断是否有迭代元素
String s = it.next();//获取迭代出的元素
System.out.println(s);
}
}
}
运行结果:
张三
李四
王二
7.3 迭代器的实现原理
当遍历集合时,首先通过调用集合的iterator()方法获得迭代器对象,然后使用hashNext()方法判断集合中是否存在下一个元素,如果存在,则调用next()方法将元素取出,否则说明已到达了集合末尾,停止遍历元素。
Iterator对象迭代元素的过程:

在调用Iterator的next方法之前,迭代器的索引位于第一个元素之前,不指向任何元素,当第一次调用迭代器的next方法后,迭代器的索引会向后移动一位,指向第一个元素并将该元素返回,当再次调用next方法时,迭代器的索引会指向第二个元素并将该元素返回,依此类推,直到hasNext方法返回false,表示到达了集合的末尾,终止对元素的遍历。
7.4 增强for(foreach)
增强for循环(也称for each循环)是JDK1.5以后出来的一个高级for循环,专门用来遍历数组和集合的。它的内部原理其实是个Iterator迭代器,所以在遍历的过程中,不能对集合中的元素进行增删操作。
格式:
for(元素的数据类型 变量 : Collection集合or数组){
//写操作代码
}
代码示例:
package com.tanrui.collection;
import java.util.ArrayList;
import java.util.Collection;
public class For {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<String>();
coll.add("张三");
coll.add("李四");
coll.add("王五");
for(String s :coll){
System.out.println(s);
}
}
}
运行结果:
张三
李四
王五















 2085
2085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









