







近期对深度学习中的Attention模型进行了深入研究,该模型在图像识别、语音识别和自然语言处理三大深度学习的热门领域均有广泛的使用,是2014和2015年深度学习领域的重要进展。现对其原理、主要应用及研究进展进行详细介绍。
1. 基本原理
Attention模型最初应用于图像识别,模仿人看图像时,目光的焦点在不同的物体上移动。当神经网络对图像或语言进行识别时,每次集中于部分特征上,识别更加准确。如何衡量特征的重要性呢?最直观的方法就是权重,因此,Attention模型的结果就是在每次识别时,首先计算每个特征的权值,然后对特征进行加权求和,权值越大,该特征对当前识别的贡献就大。
机器翻译中的Attention模型最直观,易于理解,因为每生成一个单词,找到源句子中与其对应的单词,翻译才准确。此处就以机器翻译为例讲解Attention模型的基本原理。在此之前,需要先介绍一下目前机器翻译领域应用最广泛的模型——Encoder-Decoder结构,谷歌最新发布的机器翻译系统就是基于该框架[1],并且采用了Attention模型。
Encoder-Decoder框架包括两个步骤,第一步是Encoder,将输入数据(如图像或文本)编码为一系列特征,第二步是Decoder,以编码的特征作为输入,将其解码为目标输出。Encoder和Decoder是两个独立的模型,可以采用神经网络,也可以采用其他模型。机器翻译中的Encoder-Decoder示例如下图(取自[2]):
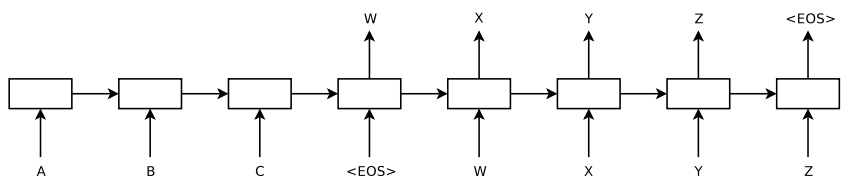
该示例将一个句子(ABC)翻译为另一种语言的句子(WXYZ),其中A、B、C和W、X、Y、Z分别表示一个字或一个单词,图中每个方框表示一个RNN模型,不同的方框表示不同的时刻,<eos>表示句子结束。
了解Encoder-Decoder结构之后,我们再回到Attention模型,Attention在Encoder-Decoder中介于Encoder和Decoder中间,首先根据Encoder和Decoder的特征计算权值,然后对Encoder的特征进行加权求和,作为Decoder的输入,其作用是将Encoder的特征以更好的方式呈献给Decoder。 [3] 首次将Attention模型应用到机器翻译中,我们参照下图对其展开讲解。
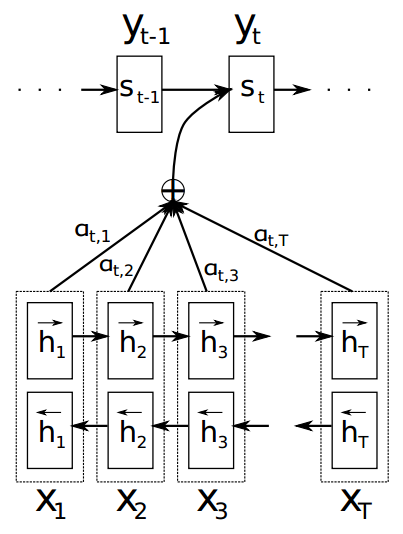
该图将句子 (x1,x2,...,xT) 翻译为 (y1,y2,...,yt,...) ,Encoder和Decoder均采用RNN模型,下方的一系列h为Encoder生成的特征,考虑到句子中单词的上下文关系,此处采用了双向RNN模型,所以每个时刻生成的特征由两个方向的特征组合而成,即 hi=[hi→;hi←] 。图中的 αt,i 就是Attention模型生成的权值,在t时刻,对特征h进行加权组合
ct=∑i=1Tαt,ihi
那么生成新的单词的过程为
p(yt)=RNN(yt−1,st,ct)
如果没有Attention模型计算权值,那么该过程就变为
c=f(h1,...,hT)
p(yt)=RNN(yt−1,st,c)
也就是说,在Decoder的每个时刻,其输入特征均是固定的,将所有的输入x编码为一个固定的特征容易造成信息损失,而且在Decoder的时候,每一个时刻均选取所有特征,没有针对性,因此就产生了Attention模型。那么Attention模型中的权值 α 是怎么计算的呢?
αt,i=exp(et,i)∑Tk=1exp(et,k)
et,i=fatt(st−1,hi)
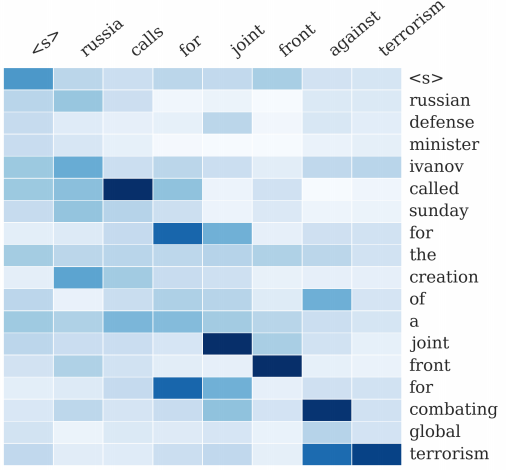
前面说了那么多,其实这里的 fatt 才是Attention模型的核心,它被称为alignment模型,计算Encoder的特征与Decoder特征的对应关系。举例如下图:

该图表示法语到英语的翻译,图中的小方格就是表示Attention模型的权值 α 的大小,颜色越浅表示权值越大。可以看到,大的权值基本上分布在对角线上,而在European Economic Area三个单词处,权值成反对角线分布,这是因为法语与英语的句法结构不同,这三个单词的权值依然是对应的,说明Attention模型在这里准确实现了单词之间的对应关系。
综上所述,Attention模型就是对输入特征进行加权以衡量每个特征对当前识别的重要性,它自己集中于重要的特征,忽略不重要的特征。
2. Attention模型的主要应用
Attention模型主要应用于深度学习,目前深度学习最热门的应用就是自然语言理解、图像识别和语音识别三大领域。本文针对三个领域分别列举几个Attention模型的应用。
2.1 自然语言理解
第一节的机器翻译就是一个非常重要的应用,谷歌在最新发布的机器翻译模型中就采用了Attention模型,[4]一文中将Attention模型应用到文本摘要,从长句子或段落中提取关键词,如下图:
华为诺亚方舟实验室的李航博士将Attention模型应用于短文本对话 [5] 。
2.2 图像识别
Attention模型在图像识别里的应用既有图像分类,如[6][7],又有图像生成,如[8][9],个人最感兴趣的是图像标题生成[10],如下图:
 |  |
该研究中将Attention模型的权值可视化,显示在原图中,即图中白色的区域,可以看出,图中的飞盘和狗分别与句子中的frisbee和dog形成了对应关系。
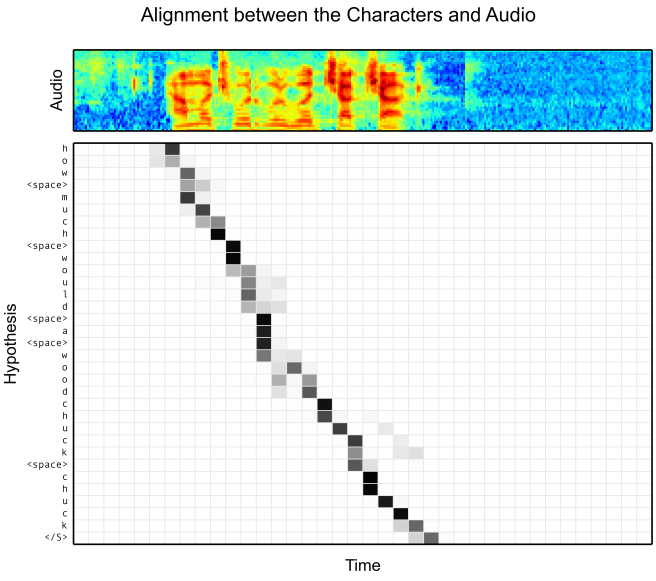
2.3 语音识别
语音识别的经典模型要数CTC,基于Attention模型的Encoder-Decoder框架也取得了较好的结果,如[11][12],Attention模型也建立了语音与单词之间的对应关系。
3. 研究进展
自从Attention模型引入深度学习后,不但获得了广泛应用,也产生了很多改进,下面列举几个研究进展。
[10]首次将Attention模型引入图像标题应用时,提出了两种Attention方法——soft attention和hard attention,其中soft attention就是最初的attention方法,而hard attention在选取特征组合时,并不针对所有的特征生成权值,而是只选取1个或者几个特征,因此是hard的。
从Attention中的alignment模型
et,i=fatt(st−1,hi)
可以看出,它实际上是基于Decoder的t-1时刻的状态预测t时刻状态与Encoder特征
hi
的关联程度,在[13]中,首先不使用Attention模型进行Decoder,然后就可以使用Attenion计算t时刻的Decoder状态与Encoder特征的关联程度,
et,i=fatt(st,hi)
,并且文章基于bilinear方法提出了简化版的Attention模型,计算更加高效。
在机器翻译中,存在过翻译和欠翻译的现象,即有些词被多次翻译,有些词却被漏掉,这是因为Attention模型没有记忆翻译进程的机制,[14]一文增加了Coverage模型,用于记录哪些单词已被翻译,哪些尚未翻译,从而使Attention模型专注于未翻译的单词,忽略已经翻译的单词。
4. 总结
Attention模型虽然取得了广泛的应用,但是它自己并不是独立的框架,只是对其他框架的一些改进。在其他尚未使用Attention模型的领域可以继续引进,但是对于Attention模型本身,我认为发展空间已经不大。
[1] Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., … & Klingner, J. (2016). Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv preprint arXiv:1609.08144.
[2] Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in neural information processing systems (pp. 3104-3112).
[3] Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
[4] Rush, A. M., Chopra, S., & Weston, J. (2015). A neural attention model for abstractive sentence summarization. arXiv preprint arXiv:1509.00685.
[5] Shang, L., Lu, Z., & Li, H. (2015). Neural responding machine for short-text conversation. arXiv preprint arXiv:1503.02364.
[6] Mnih, V., Heess, N., & Graves, A. (2014). Recurrent models of visual attention. In Advances in Neural Information Processing Systems (pp. 2204-2212).
[7] Ba, J., Mnih, V., & Kavukcuoglu, K. (2014). Multiple object recognition with visual attention. arXiv preprint arXiv:1412.7755.
[8]Gregor, K., Danihelka, I., Graves, A., Rezende, D. J., & Wierstra, D. (2015). DRAW: A recurrent neural network for image generation. arXiv preprint arXiv:1502.04623.
[9]Mansimov, E., Parisotto, E., Ba, J. L., & Salakhutdinov, R. (2015). Generating images from captions with attention. arXiv preprint arXiv:1511.02793.
[10]Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhutdinov, R., … & Bengio, Y. (2015). Show, attend and tell: Neural image caption generation with visual attention. arXiv preprint arXiv:1502.03044, 2(3), 5.
[11]Chan, W., Jaitly, N., Le, Q. V., & Vinyals, O. (2015). Listen, attend and spell. arXiv preprint arXiv:1508.01211.
[12]Bahdanau, D., Chorowski, J., Serdyuk, D., & Bengio, Y. (2016, March). End-to-end attention-based large vocabulary speech recognition. In 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 4945-4949). IEEE.
[13] Luong, M. T., Pham, H., & Manning, C. D. (2015). Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025.
[14] Tu, Z., Lu, Z., Liu, Y., Liu, X., & Li, H. (2016). Modeling coverage for neural machine translation. ArXiv eprints, January.















 293
293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









