







 DataFrame 提供了 applymap 方法,它会将一个函数应用到每一个元素上,在 NumPy 没有提供所需的 ufunc 时,这是非常有用的。获得一个反映对应位置上是否是 NaN 的布尔 DataFrame 或 Series,可以使用 isna 方,True代表是NaN,False代表不。df.reset_index().set_index(‘xxx’) (链式调用,reset_index()返回一个DataFrame)要在变量后面加一个冒号,然后跟上具体的格式化字符串,这里使用的是 ,.2f。
DataFrame 提供了 applymap 方法,它会将一个函数应用到每一个元素上,在 NumPy 没有提供所需的 ufunc 时,这是非常有用的。获得一个反映对应位置上是否是 NaN 的布尔 DataFrame 或 Series,可以使用 isna 方,True代表是NaN,False代表不。df.reset_index().set_index(‘xxx’) (链式调用,reset_index()返回一个DataFrame)要在变量后面加一个冒号,然后跟上具体的格式化字符串,这里使用的是 ,.2f。
Pands数据分析
DataFrame
Pandas读xlsx文件(从excel创建DataFrame文件)
安装pandas、openpyxl库。
import pandas as pd
p = pd.read_excel("./Book_Code/xl/course_participants.xlsx")
print(p)
运行结果如下:

Pandas开创xlsx文件(不从excel创建一个DataFrame)
data = [["Mark",55,"Italy",4.5,"Europe"],
["Joh",33,"USA",6.7,"America"],
["TIm",41,"USA",3.9,"America"],
["Jenny",12,"Germany",9.0,"Europe"]]
df = pd.DataFrame(data = data,
columns=['name','age','country','score','continent'],
index=[1001,1000,1002,1003]
)
print(df)
结果如下

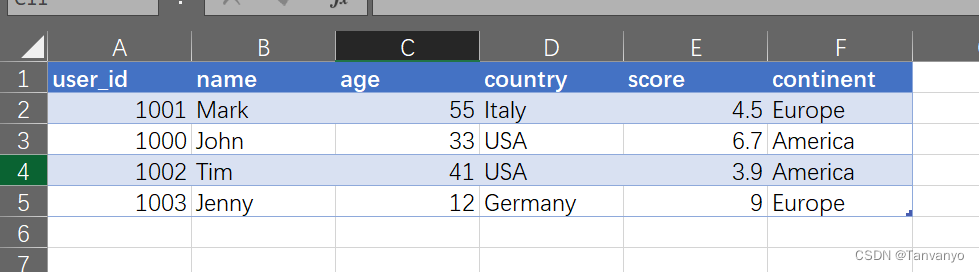
df.info()可以获得DataFrame的基本信息
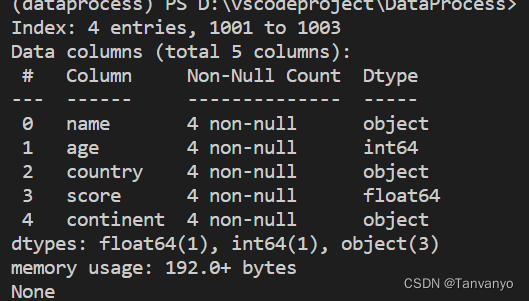
index索引
索引查看 df.index 索引命名 df.index.name=‘xxx’
索引重置(吧索引列变为普通列)df.reset_index() (调用的是DataFrame副本) 索引重新设置
df.reset_index().set_index(‘xxx’) (链式调用,reset_index()返回一个DataFrame)
df.index.name = 'usr_id'
print(df)
print(df.reset_index())
print(df.reset_index().set_index('name'))
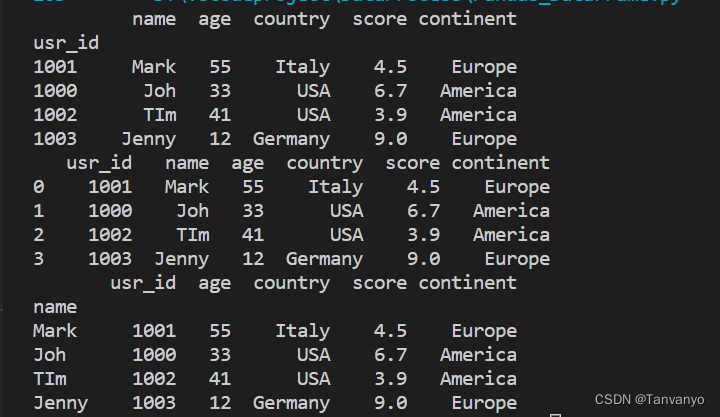
更换索引 df.reindex
print(df.reindex([999,1000,1001,1004]))
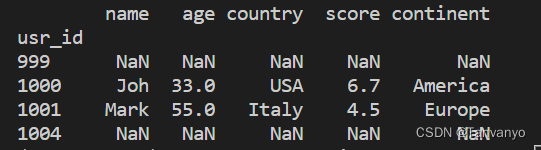
索引排序:df.sort_values
print(df.sort_values(['continent','age'])) #多个
print(df.sort_values(&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3414
3414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









