









1、x * = (y=z=5)
int x = 2,y,z;
x * = (y=z=5);
cout<<x<<endl;解答:x = 2*(5) = 10
2、理解函数的内层作用
int fun(int x)
{
int count = 0;
while(x)
{
count++;
x = x&(x-1);
}
return count;
}
cout<<fun(9999)<<endl;解析:该fun函数的作用:count返回了形参x二进制1的个数。
9999:10011100001111
3、for循环 i++
for(x=1; !x++;) //先判断!x为假,将不执行花括号里的语句,但x++还是得执行
{
} j = 2;
while(j++ < 3) //慎用
{
do_something_1;
}
if(j == 3)
{
do_something_2;
}分析过程为:
j = 2 满足j<3, 然后j++,变成3,do_something_1
j = 3 判断j<3,不满足,然后j++,此时j已经变成4了,永远不会进到if判断句里执行。
4、浮点型内存表示 (int&)a
float类型数据存储格式:
浮点数规则:1+8+23 = 32
尾数的整数部分恒为1,不够23位其后面补0。
阶偏移为127。
double类型数据存储格式:
浮点数规则:1+11+52 = 64
尾数的整数部分恒为1,不够52位其后面补0。
阶偏移为1023。
题1:
#include <iostream>
#include <string>
using namespace std;
int _tmain(int argc, _TCHAR* argv[])
{
float fa = 1.0f;
cout<<&fa<<endl; //0x0012ff60
cout<<(int)fa<<endl; //1
cout<<(float&)fa<<endl;//1
cout<<*((float*)(&fa))<<endl;//1
cout<<(int&)fa<<endl;//1065353216
return 0;
}float fa = 1.0f; 默认定义是double型(64位),float(32位)
float fa = 1.0; 此处会抛异常,(貌似没有抛)
里面出现了一个很奇怪的输出形式就是(int&)a.
其实,(int&)a就是 * (int*)(&a)
首先对float型变量取地址
强制类型转换为整型变量的地址(地址的值并没有变)
将该地址指向的变量输出(但是由于整型和浮点型数据存储方式的不同,输出结果是不同的)
下面说一下整型变量和浮点型变量的存储区别:

十进制的浮点数转换为二进制的过程:
下面以浮点数125.5为例来说明:
125二进制表示形式为1111101,小数部分表示为二进制为 1,则125.5二进制表示为1111101.1
由于规定尾数的整数部分恒为1,则表示为1.1111 011*2^6
计算阶码:阶码为6,加上127为133,则表示为10000101
计算尾数:对于尾数将整数部分1去掉,为1111 011,在其后面补0使其位数达到23位,则为11110110000000000000000
则其二进制表示形式为:
0 10000101 11110110000000000000000,则在内存中存放方式为:
00000000 低地址
00000000
11111011
01000010 高地址
对于将一个浮点型数据(double)赋值给整型数据(int)是怎样截断的?
float fa = 1.0f;
cout<<(int)fa<
float a = 1.0f;
cout << sizeof(int) <<endl;//4
cout << sizeof(float) <<endl;//4
cout << (int)a << endl;//1
cout << &a << endl; /*取a的地址十六进制0012FF7C*/
cout << (int)&a << endl;/*(int)&a:把a的地址强制转换成十进制的整型1245052*/
cout << (int&)a << endl;
/*(int&)a:将a的引用强制转换为整型,意思是a所在的内存,本来定义的时候为float类型,并初始为1.0f, 但现在我要按int类型解释这段内存(也就是说a所在的内存地址中的数据本来是按float型存储表示的,你非要按int型来解释不可)。 1.0f 在内存中的存储为
0 011 1111 1000 0000 0000 0000 0000 0000.
把他按整型数解释为2^29+2^28+2^27+2^26+2^25+2^24+2^23=1065353216
题2、
printf("%f\n",5); ??????
printf("%d\n",5.01);输出结果:
0.000000
1889785610
知识点:printf函数不会进行任何类型转换,它只是从内存中读出你所提供的元素的值(按照%d,%f等控制字符提示的格式),在printf中,float会自动转换成64位的double。
5作为整型值在内存中存储方式为(占4个字节):0x 00 00 00 05
按%f输出还必须加入4字节的0:0x 00 00 00 00 05 写成浮点型的 符号+阶码+尾数的形式为:
0 00000000000 0000000000000000000000000000000000000000000000000000000000000101
然后应该打印这样的一个值:1.0000000000000000000000000000000000000000000000000000000000000101 × 2(-1023)???
double类小数点后面只保留6位,所以不可能取到有非0的101处
5.01是默认为double型,在内存中的存储方式为:
0 10000000001 010000….0000
5、位运算技巧
P 39
下面代码:
int f(int x,int y)
{
return (x&y)+((x^y)>>1);
}
f(729,271)= 分析:x&y是取相同的位与,这个结果是x和y相同位的一半,x^y是取不同的位,右移相当于除以2,所以这个函数的功能是取两个数的平均值。
(x&y)+((x^y)>>1),把x和y里对应的每一位(指二进制位)都分成三类,每一类分别计算平均值,最后汇总。
其中, 一类是x,y对应位都是1,用x&y计算其平均值;
一类是x,y中对应位有且只有一位是1,用(x^y)>>1计算其平均值;
最后一类是x,y中对应位均为0,无须计算。
下面我再分别说明一下前两种情况是怎样计算的:
第一部分,x,y对应位均为1,相加后再除以2还是原来的数,如两个00001111相加后除以2仍得00001111,即x&y == (x+y)/2,因为1&1=1 == (1+1)/2
第二部分,对应位有且只有一位为1,用“异或”运算提取出来(0^1 = 1, 1^0 = 1),然后>>1(右移一位,相当于除以2),即到到第二部分的平均值。
第三部分,对应位均为零,因为相加后再除以二还是0,所以不用计算。
三部分汇总之后就是(x&y)+((x^y)>>1)
顺便解释一下前面说到可以避免溢出。
假设x,y均为unsigned char型数据(0~255,占用一字节),显然,x,y的平均数也在0~255之间,但如果直接x+y可能会使结果大于255,这就产生溢出,虽然最终结果在255之内,但过程中需要额外处理溢出的那一位,在汇编中就需要考虑这种高位溢出的情况,如果(x&y)+((x^y)>>1)计算则不会。
6、printf压栈从右到左
int a[]={6,7,8,9,10};
int *p = a;
*(p++) += 123;
printf("%d %d\n",*p,*(++p));*(p++) += 123; 这条语句拆分成两条语句: *p += 123; p++; 结果为a[0] = 129 p指向a[1]
printf(“%d %d\n”,* p,(++p)); 从右到左运算,第一个是 (++p) : 先p++,再取值,为8;答案为 8 8
7、类型转换
double sqrt(double);
sqrt(2); //2被提升为double类型2.0。
double diff(int a, int b)
{
return a-b; //返回值被提升为double类型。
} 类型提升:long double > double > float > int > char short int …..
P38
unsinged char a = 0xA5;
unsinged char b =~a>>4+1;
printf("b=%d\n",b);1:优先级问题
算术运算 > 移位运算 > 比较运算 > 位运算 > 和/或
8、sizeof(a = b+1)
int a = 0,b = 0;
value = sizeof(a = b+1); //不对括号内求值,a依然为09、利用位运算实现加法
P40
定理1:设a,b为两个二进制数,则a+b = a^b + (a&b)<<1。
证明:a^b是不考虑进位时加法结果。当二进制位同时为1时,才有进位,因此 (a&b)<<1是进位产生的值,称为进位补偿。将两者相加便是完整加法结果。
定理2:使用定理1可以实现只用位运算进行加法运算。
证明:利用定理1中的等式不停对自身进行迭代。每迭代一次,进位补偿右边就多一位0,因此最多需要加数二进制位长度次迭代,进位补偿就变为0,这时运算结束。
在嵌入式领域中定义
unsigned int cmpzero = 0xFFFF; //对于一个非16位的处理器来说是不正确的。
unsigned int cmpzero = ~0;
10、sizeof()
P55
sizeof()功能:计算数据空间的字节数
1.与strlen()比较
strlen()计算字符数组的字符数,以”\0”为结束判断,不计算为’\0’的数组元素。
而sizeof计算数据(包括数组、变量、类型、结构体等)所占内存空间,用字节数表示。
2.相关常数
sizeof char:1
sizeof short:2
sizeof int:4
sizeof long:4
sizeof float:4
sizeof p:4
sizeof double:8
sizeof WORD:2
sizeof DWORD:4
3.经典问题
double* (*a)[3][6];
cout<<sizeof(a)<<endl;
cout<<sizeof(*a)<<endl;
cout<<sizeof(**a)<<endl;
cout<<sizeof(***a)<<endl;
cout<<sizeof(****a)<<endl;a是一个很奇怪的定义,他表示一个指向double*[3][6]类型数组的指针。既然是指针,所以sizeof(a)就是4。
既然a是执行double*[3][6]类型的指针,
a表示一个 double**[3][6]
*a表示一个 double*[3][6] 的多维数组类型,所以sizeof(*a)=3*6*sizeof(double*)=72。
**a表示一个 double*[6] 类型的数组,所以sizeof(**a)=6*sizeof(double*)=24。
***a表示一个 double* 类型的数组,所以sizeof(***a)=sizeof(double*)=4。
****a,就是一个 double ,所以sizeof(****a)=sizeof(double)=8。
4、sizeof(a=6)
int a = 8;
sizeof(a); //4
sizeof(a = 6); //一样转换为a的类型,4;但是a=6是不被编译的,所以执行完sizeof(a = 6)后,a的值还是8.5、有符号只影响符号的正负,数据长度不变
sizeof(unsigned int) == sizeof(int)
6、操作数是函数中的数组形参
char a[10];
int test(char a[])
{
return sizeof(a); //此时,a是一个数组形参,所有返回的值是一个指针的大小4.
}11、宏定义
P45
使用UL表示无符号长整型
#define SECONDS_PER_YERA (60*60*24*256)UL12、extern “C”
#ifndef __INCvxWorksh //防止该头文件被重复引用
#define __INCvxWorksh
#ifdef __cplusplus
extern "C" {
#endif
/*...*/
#ifdef __cplusplus
}
#endif
#endif /* __INCvxWorksh */1、通常,在模块的头文件中对本模块提供给其它模块引用的函数和全局变量以关键字extern声明。例如,如果模块B欲引用该模块A中定义的全局变量和函数时只需包含模块A的头文件即可。这样,模块B中调用模块A中的函数时,在编译阶段,模块B虽然找不到该函数,但是并不会报错;它会在连接阶段中从模块A编译生成的目标代码中找到此函数。
例如,假设某个函数的原型为:void foo( int x, int y );
该函数被C编译器编译后在符号库中的名字为_ foo,而C++编译器则会产生像_foo_int_int之类的名字(不同的编译器可能生成的名字不同,但是都采用了相同的机制,生成的新名字称为“mangled name”)。
_ foo_int_int这样的名字包含了函数名、函数参数数量及类型信息,C++就是靠这种机制来实现函数重载的。例如,在C++中,函数void foo( int x, int y )与void foo( int x, float y )编译生成的符号是不相同的,后者为_foo_int_float。
同样地,C++中的变量除支持局部变量外,还支持类成员变量和全局变量。用户所编写程序的类成员变量可能与全局变量同名,我们以”.”来区分。而本质上,编译器在进行编译时,与函数的处理相似,也为类中的变量取了一个独一无二的名字,这个名字与用户程序中同名的全局变量名字不同。
参考:http://www.cnblogs.com/rollenholt/archive/2012/03/20/2409046.html
2、extern有两个作用:
第一个,当它与”C”一起连用时,如: extern “C” void fun(int a, int b);则告诉编译器在编译fun这个函数名时按着C的规则去翻译相应的函数名而不是C++的,C++的规则在翻译这个函数名时会把fun这个名字变得面目全非。
第二,当extern不与”C”在一起修饰变量或函数时,如在头文件中: extern int g_Int; 它的作用就是声明函数或全局变量的作用范围的关键字,其声明的函数和变量可以在本模块活其他模块中使用,记住它是一个声明不是定义。
3、
在一个源文件里定义了一个数组:char a[6];
在另外一个文件里用下列语句进行了声明:extern char *a;
请问,这样可以吗?
答案与分析:
1)、不可以,程序运行时会告诉你非法访问。原因在于,指向类型T的指针并不等价于类型T的数组。extern char *a声明的是一个指针变量而不是字符数组,因此与实际的定义不同,从而造成运行时非法访问。应该将声明改为extern char a[ ]。
2)、例子分析如下,如果a[] = “abcd”,则外部变量a=0x61626364 (abcd的ASCII码值),*a显然没有意义
显然a指向的空间(0x61626364)没有意义,易出现非法内存访问。
3)、这提示我们,在使用extern时候要严格对应声明时的格式,在实际编程中,这样的错误屡见不鲜。
4)、extern用在变量声明中常常有这样一个作用,你在.c文件中声明了一个全局的变量,这个全局的变量如果要被引用,就放在.h中并用extern来声明。
13、CONST常量
const double a; //错误,常量定义时必须同时初始化。14、char *c与char c[]
P 69
char c1[] = "hello"; //局部
char *c2 = "hello"; //全局
c1[0] = 't'; //局部数据可以修改。
*c2 = 't'; //错误,全局变量保存在普通数据段(静态存储区)。以下为正确做法:
char * STR()
{
//static char str[] = "hello world!";
char *str = "hello world!";
return str;
}以下为错误做法:
char * STR()
{
char str[] = "hello world!";
return str;
}15、指针分配
int *p;
p = (int *)0x80000; //没有下一行不会错。会给指针分配一个随意的地址,非常危险,显然给其内存空间赋值时会段错误。
*p = 0xaabb; //错误,运行时错误。16、函数指针/指针函数
P75
long (* fun)(int) //fun为函数指针
long * fun (int) //fun为指针函数
int *((*b)[10]);
int * (*b)[10]; //两式相同,b是一个指针,它指向一个一维数组,该数组的元素都是int *
int (*(*fun)(int, int ))(int) //*(*fun)(int, int )是一个函数指针,参数为int,返回值为一个指针
int (* p)(int) //该指针又是一个函数指针。17、指向数组的指针 int *p[5] & int ( *p)[5]
P76 C和指针:P158
1、声明一个指向整型数组的指针:
int (*p)[10];
该p是一行一行的移动,如需要一个一个整数移动,则需如下定义。
int m[3][10];
int * p = &m[0][0];
int * p = m[0];
int (*p)[10] = m; //*p为第一行的地址 *(p+1)为第二行的地址
//*p+1为第一行第二个数的地址。2、例题:
一个有10个指针的数组,该指针指向一个函数,该函数有一个整型参数和返回值。
int (* fun)(int) //函数指针
* a[10] //10个指针的数组
int (* a[10])(int) int a[] = {1,2,3,4,5,6};
int *p = (int *)(&a + 1); //此时p指向a[5]的后面一个整型数,即&a+1相当于移动一个数组的长度。&a其实变成了一个二维指针,相当于一个二维数组。
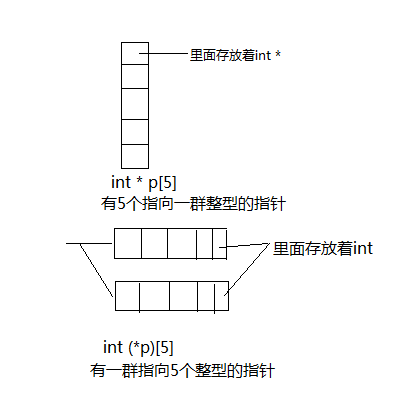
printf("%d\n",*(p - 1));3、int *p[5] & int ( *p)[5]的区别
int* p[5]: 表示有5个指向一群整型的指针。
int (*p)[5]::表示有一群指向5个整型的指针。 指向数组的指针。
18、进制转换
P162
13作为一个X进制的数,转换为10进制为:1×X(1) + 3×X(0)
19、中断服务子程序 ISR
P169
1) ISR 不能返回一个值。
2) ISR 不能传递参数。
3) 在许多的处理器/编译器中,浮点一般都是不可重入的。有些处理器/编译器需要让额处的寄存器入栈,有些处理器/编译器就是不允许在ISR中做浮点运算。此外,ISR应该是短而有效率的,在ISR中做浮点运算是不明智的。
4) 与第三点一脉相承,printf经常有重入和性能上的问题。
不能在中断服务程序中执行类似操作的原因是运算时间太长,不能在中段中作复杂的工作,你可以在中断服务程序中置一个标志位.然后在主程序中查询此位,判断是否执行计算子程序.当然这样做会在中断产生与实际的中断响应之间产生一定的延迟,如果你的系统对时间不太敏感还好,如果非常敏感可以考虑采用rtos。否则。。。多加几句对中断标志位的判断语句。。。。
在主程序中监测是否被置位来决定子程序是否执行.可能存在以下问题,就是,中断返回后要执行几个耗时比较长的子程序才能执行判断标志位的语句,这样,可能会有太长的时间间隔.如果你在几个耗时比较长的子程序之间加上一句判断语句,就会减小中断产生与中断响应之间的时间延迟.
中断活动的全过程大致为:
1、中断请求:中断事件一旦发生或者中断条件一旦构成,中断源提交“申请报告”,与请求CPU暂时放下目前的工作而转为中断源作为专项服务
2、中断屏蔽:虽然中断源提交了“申请报告”,但是,是否得到CPU的响应,还要取决于“申请报告”是否能够通过2道或者3道“关卡”(中断屏蔽)送达CPU(相应的中断屏蔽位等于1,为关卡放行;反之相应的中断屏蔽位等于0,为关卡禁止通行);
3、中断响应:如果一路放行,则CPU响应中断后,将被打断的工作断点记录下来(把断点地址保护到堆栈),挂起“不再受理其他申请报告牌”(清除全局中断标志位GIE=0),跳转到中断服务子程序
4、保护现场:在处理新任务时可能破坏原有的工作现场,所以需要对工作现场和工作环境进行适当保护;
5、调查中断源:检查“申请报告”是由哪个中断源提交的,以便作出有针对性的服务;
6、中断处理:开始对查明的中断源进行有针对性的中断服务;
7、清除标志:在处理完毕相应的任务之后,需要进行撤消登记(清除中断标志),以避免造成重复响应;
8、恢复现场:恢复前面曾经被保护起来的工作现场,以便继续执行被中断的工作;
9、中断返回:将被打断的工作断点找回来(从堆栈中恢复断点地址),并摘下“不再受理其他申请报告牌”(GIE=1),继续执行原先被打断的工作。
20、C中的volatile用法
P170
volatile 影响编译器编译的结果,指出,volatile 变量是随时可能发生变化的,与volatile变量有关的运算,不要进行编译优化,以免出错,(VC++ 在产生release版可执行码时会进行编译优化,加volatile关键字的变量有关的运算,将不进行编译优化。)。
例如:
volatile int i=10;
int j = i;
…
int k = i;
volatile 告诉编译器i是随时可能发生变化的,每次使用它的时候必须从i的地址中读取,因而编译器生成的可执行码会重新从i的地址读取数据放在k中。
而优化做法是,由于编译器发现两次从i读数据的代码之间的代码没有对i进行过操作,它会自动把上次读的数据放在k中,而不是重新从i里面读。这样以来,如果i是一个寄存器变量或者表示一个端口数据就容易出错,所以说volatile可以保证对特殊地址的稳定访问,不会出错。
使用volatile变量的几个例子:
1) 并行设备的硬件寄存器(如:状态寄存器)
2) 一个中断服务子程序中会访问到的非自动变量(Non-automatic variables)
3) 多线程应用中被几个任务共享的变量
我认为这是区分C程序员和嵌入式系统程序员的最基本的问题。搞嵌入式的家伙们经常同硬件、中断、RTOS(实时操作系统)等等打交道,所有这些都要求用到volatile变量。不懂得volatile的内容将会带来灾难。
嵌入式编程中经常用到 volatile这个关键字,用法可以归结为以下两点:
一:告诉compiler**不能做任何优化**
比如要往某一地址送两指令:
int *ip =...; //设备地址
*ip = 1; //第一个指令
*ip = 2; //第二个指令 以上程序compiler可能做优化而成:
int *ip = ...;
*ip = 2; //第一个指令丢失结果第一个指令丢失。如果用volatile, compiler就不允许做任何的优化,从而保证程序的原意:
volatile int *ip = ...;
*ip = 1;
*ip = 2; 即使你要compiler做优化,它也不会把两次付值语句间化为一。它只能做其它的优化。这对device driver程序员很有用。
二:表示用volatile定义的变量会在程序外被改变,每次都必须从内存中读取,而不能把他放在cache或寄存器中重复使用。
如
volatile char a;
a=0;
while(!a)
{
//do some things;
}
do_other(); 如果没有 volatile do_other()不会被执行
1)一个参数既可以是const还可以是volatile吗?解释为什么。
2); 一个指针可以是volatile 吗?解释为什么。
3); 下面的函数有什么错误:
int square(volatile int *ptr)
{
return *ptr * *ptr;
} 下面是答案:
1)是的。一个例子是只读的状态寄存器。它是volatile因为它可能被意想不到地改变。它是const因为程序不应该试图去修改它。
2); 是的。尽管这并不很常见。一个例子是当一个中服务子程序修该一个指向一个buffer的指针时。
3) 这段代码有点变态。这段代码的目的是用来返指针* ptr指向值的平方,但是,由于*ptr指向一个volatile型参数,编译器将产生类似下面的代码:
int square(volatile int *ptr)
{
int a,b;
a = *ptr;
b = *ptr;
return a * b;
} 由于*ptr的值可能被意想不到地该变,因此a和b可能是不同的。
正确的代码如下:
long square(volatile int *ptr)
{
int a;
a = *ptr;
return a * a;
} 21、大端/小端
P174
小端:对操作数的存放方式是从操作数的低字节到高字节存放,依地址增大的顺序存放。
大端:对操作数的存放方式是从操作数的高字节到低字节存放,依地址增大的顺序存放。
例如:操作数 0x1234 (12为高字节,34为低字节)
小端:
地址 内容
0x4000 0x34 先存放 低字节 数
0x4001 0x12
大端:
地址 内容
0x4000 0x12 先存放 高字节 数
0x4001 0x34
22、static的作用
P176
23、指针常量
*100 = 25; 不合法
(int )100 = 25; 合法;将100强制转换成整形指针,从整形转换为指向整形的指针
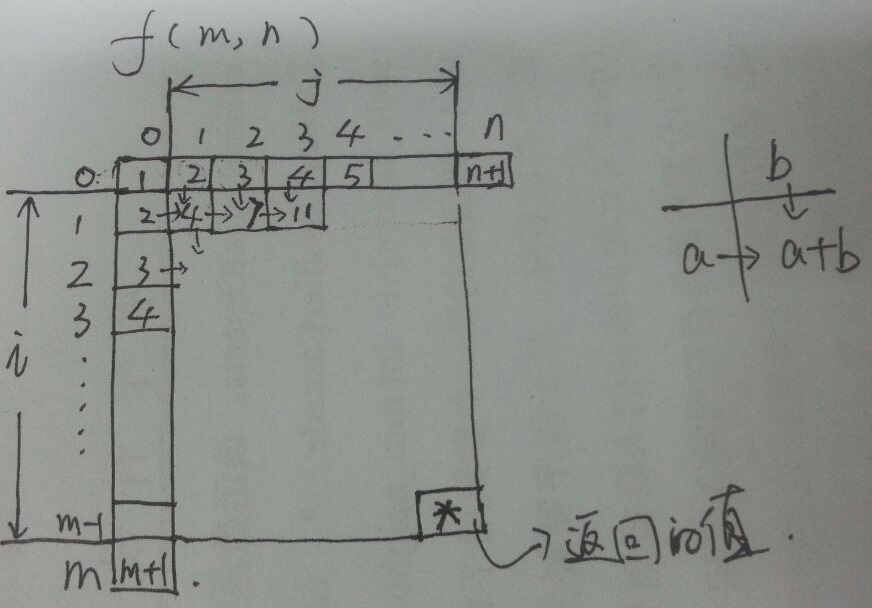
24、非递归实现递归算法
P90
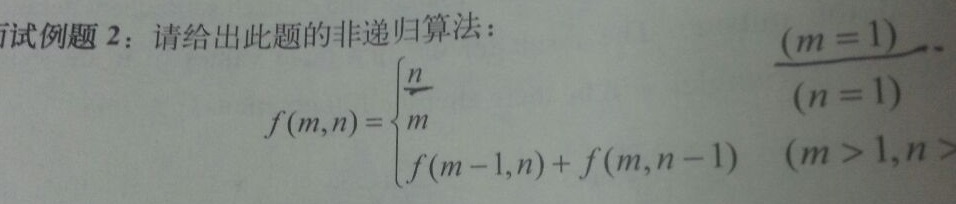
25、C++问题
空类产生4个成员函数: 默认构造/析构函数、拷贝构造函数、赋值函数
struct默认的访问控制方式是public
静态成员变量,可以在一个类的所有实例中共享数据,可以声明为保护或者私有。
26、函数压栈过程
P196
27、字符、字符串问题
指出下面的问题,并改正。 P236
#define MAX 255
int main()
{
char p[MAX+1];
char ch;
for(ch=0; ch <= MAX; ch++)
{
p[ch] = ch;
printf("%c\n",ch);
}
}【答案】
一个是char的范围是-128~127 当ch=127再加一后,变成-128,然后继续循环。
该位unsigned char,范围是0~255,但是当达到255后,再加一,变成了0,还是死循环,因此将小于等于该为小于。
问题例题
P72
P162 C++ dynamic_cast















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









