







1.摘要
手机应用推荐有一个不同于传统商品推荐的显著特点:用户会考虑用新的app来取代旧的。于是带来现有app的目前实用价值和备选app的吸引价值的竞争。
2.我的想法
针对此特点,我可能会想做两种类型的推荐:(1)同一类型的app推荐,如类似的天气预报软件,考虑满意度和吸引度;(2)根据其使用的app分析其特征(性格,职业,爱好等),根据特征推荐app。
第二种类型可用传统的基于用户的协同过滤算法。第一种可在传统的基于物品的协同过滤算法上改进。
满意度和吸引度对选择的影响衡量问题。
3.具体操作
(1)计算两个app功能的重叠程度
假设功能来自app的描述,用余弦相似度表示。
(2)对一个app的评分
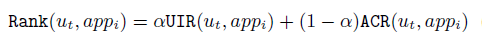
UIR感兴趣程度,ACR吸引度。
(3)下载一个app的概率密度分布函数——贝塔分布
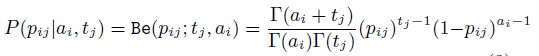
(4)1)针对已有的一个app和推荐的一个app相比的概率
服从伯努利过程
2)针对用户所有app和推荐的一个app相比的概率
将用户已有的每个app与推荐的app的相似度作为权重,累乘作为综合概率。
(5)数据格式为形如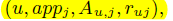
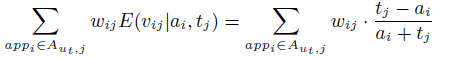
(6)从数据中发现AV和TV。
app的平均评分和app的actual value作图发现其大致成正比;用一个app的下载概率(下载/浏览)和app的tempting value作图发现其也大致成正比。
(7)求解AV/TV的比值。
1)负比,AV小。类似书籍,属于一次性消费。
2)0左右。类似说明和指南,确定性消费。
3)正比,AV大。功能强大型app,难以被取代。
(8)数据预处理。
选取最近25%的记录作为测试集。
(9)评测指标。
使用相对准确率和召回率。经过处理,两者相同,只需计算其中一个。
(10)选取collaborative filtering (CF) and content-based recommendation (CBR). Specifically we use probabilistic matrix factorization (PMF) [22] to realize CF and support vector machine (SVM), implemented by LIBSVM [5] to realize CBR.多个模型进行对比评测。
(11)对测试集的大小,参数的选择,迭代次数等进行评测。
4.不足
(1)忽略了稀疏集的处理。数据集预处理时剔除了稀疏数据。(We remove users who have conducted less than 100 actions and then remove apps that have less than 10 visitors.)
(2)稳定性测试??















 29万+
29万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









