







大家好,我是peachesTao,今天跟大家聊一聊go语言中的内存对齐,这个知识点涉及到计算机运行原理,也是go面试中经常被问的问题
通过这篇文章你可以了解到go语言中内存是怎么对齐的,以及代码怎么写才能更有效的利用内存。
本次分享分为4个部分
-
什么是内存对齐?
-
为什么要内存对齐?
-
如何做才能内存对齐?
-
对于内存对齐,程序员能做点什么
什么是内存对齐?
以下定义来源于网络
现代计算机中内存空间都是按照字节(byte)进行划分的,所以从理论上讲对于任何类型的变量访问都可以从任意地址开始,但是在实际情况中,在访问特定类型变量的时候经常在特定的内存地址访问,所以这就需要把各种类型数据按照一定的规则在空间上排列,而不是按照顺序一个接一个的排放,这种就称为内存对齐,内存对齐是指首地址对齐,而不是说每个变量大小对齐。
为什么要内存对齐?
CPU把内存看成一块一块的,一块内存可以是2、4、8、16个字节,CPU访问内存也是一块一块的访问,cpu一次访问一块内存的大小我们定义为粒度,
32位CPU访问粒度是4个字节,64位CPU访问粒度是8个字节。
内存对齐是为了减少访问内存的次数,提高CPU读取内存数据的效率,如果内存不对齐,访问相同的数据需要更多的访问内存次数。
我们用一个int32类型的变量a
var a int32 = 88分别以内存不对齐和内存对齐来说明两者之间的差异,此处以32位CPU为基准
-
当内存不对齐时
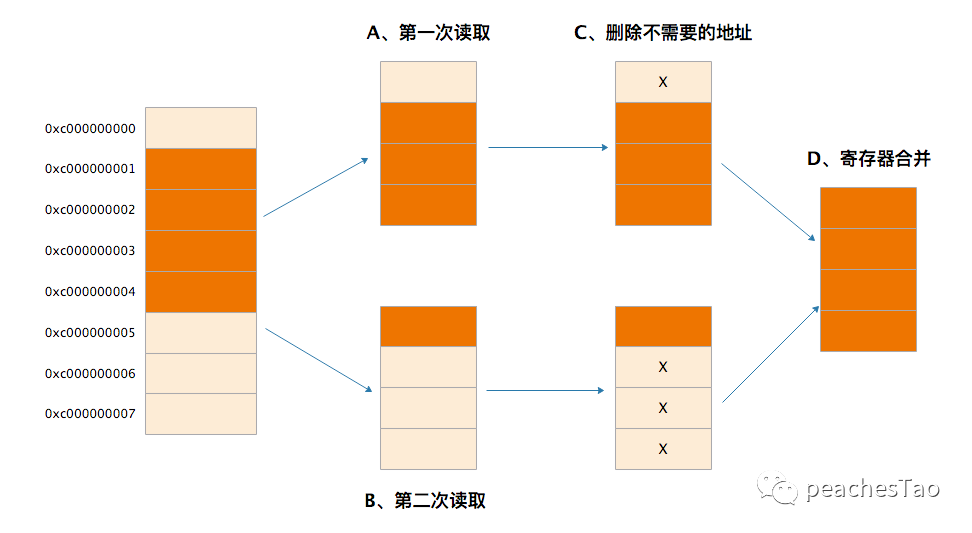
假设有一段地址0xc000000000-0xc000000007,0xc000000000中已经存放数据,不对齐时变量a中的4个字节的数据被一个接一个的放在0xc000000000的后面地址空间0xc000000001-0xc000000004中。
访问a时CPU按照访问粒度4个字节从内存读取,当发现第一个地址0xc000000001不在对齐边界上,它属于0xc000000000-0xc000000003这个粒度块中,于是就从当前块的对齐边界地址0xc000000000处开始读取4个字节,即0xc000000000-0xc000000004。
由于这次读取只读到了我们要的0xc000000001-0xc000000003地址空间的三个字节数据,还有一个字节数据没有读到,于是CPU又对内存进行第二次读取,读到了0xc0000000041-0xc000000007空间的4个字节数据。
然后CPU将第一次读到的0xc000000000和第二次读到的0xc000000005-0xc000000007空间上的数据删除,最后在寄存器中将剩余的数据合并,得到了我们最终想要的数据0xc000000001-0xc000000004,见下图
-
当内存对齐时:
对齐时地址0xc000000000后面的三个字节的空间会被填充(为什么会被填充?这是对齐规则决定的,后面会详细解释),变量a中的4个字节的数据被存放在0xc000000004-0xc000000007空间中。
取出时CPU按照访问粒度4个字节进行读取,当发现第一个地址0xc000000004在对齐边界上,于是直接读取0xc000000004-0xc000000007空间中4个字节数据。
我们看到当内存对齐时只读一次内存就能拿到的变量a的数据,见下图

如何做才能内存对齐
在前面的例子中我们看到当内存不对齐时会填充,其实这部分工作是由编译器完成的,程序员并不需要关心,但作为一名合格的码农来说,我们还是有必要知道编译器内存对齐的原理。
这部分分三个点来讲
-
编译器对齐系数
-
数据类型的大小和对齐系数
-
编译器内存对齐规则
编译器对齐系数
对于常见的CPU
-
32位CPU,对齐系数为4
-
64位CPU,对齐系数为8
另外要注意,不同硬件平台占用的大小和对齐值都可能是不一样的。因此本文的值不是唯一的,用的时候需按实际情况考虑
在C语言中可以通过预编译指令#pragma pack(n)来修改对齐参数
#pragma pack(2)
typedef struct
{
char e_char;
long double e_ld;
}S1;不过在go语言中没有办法修改默认对齐参数,这个在这篇文章有介绍 https://github.com/golang/go/wiki/cgo#struct-alignment-issues
数据类型的大小和对齐系数
在unsafe包中有三个函数
func Sizeof(x ArbitraryType) uintptr
func Offsetof(x ArbitraryType) uintptr
func Alignof(x ArbitraryType) uintptrunsafe.Sizeof 返回变量x的占用字节数,但不包含它所指向内容的大小,对于一个string类型的变量它的大小是16字节,一个指针类型的变量大小是8字节(基于64位机器,下文中的例子也是,不再说明)
unsafe.Offsetof 返回结构体成员地址相对于结构体首地址相差的字节数,称为偏移量,注意:x必须是结构体成员
unsafe.Alignof 返迴变量x需要的对齐倍数,它可以被x地址整除
这三个方法只有方法的声明,实现是在编译期间执行的,编译期间源码在
/usr/local/go/src/cmd/compile/internal/gc/unsafe.go中,感兴趣的朋友可以去看下,这里不做介绍。
注意:以上三个函数计算结果跟硬件平台、编译器实现有关,具体值以实际情况为准
下面列出常见数据类型的大小和对齐值
func main() {
fmt.Printf("bool size:%d align: %d\n", unsafe.Sizeof(bool(true)), unsafe.Alignof(bool(true)))
fmt.Printf("byte size:%d align: %d\n", unsafe.Sizeof(byte(0)), unsafe.Alignof(byte(0)))
fmt.Printf("int8 size:%d align: %d\n", unsafe.Sizeof(int8(0)), unsafe.Alignof(int8(0)))
fmt.Printf("int16 size:%d align: %d\n", unsafe.Sizeof(int16(0)), unsafe.Alignof(int16(0)))
fmt.Printf("int32 size:%d align: %d\n", unsafe.Sizeof(int32(0)), unsafe.Alignof(int32(0)))
fmt.Printf("int64 size:%d align: %d\n", unsafe.Sizeof(int64(0)), unsafe.Alignof(int64(0)))
fmt.Printf("string size:%d align: %d\n", unsafe.Sizeof("peachesTao"), unsafe.Alignof("peachesTao"))
}它们的大小和对齐系数如下
bool size:1 align: 1
byte size:1 align: 1
int8 size:1 align: 1
int16 size:2 align: 2
int32 size:4 align: 4
int64 size:8 align: 8
string size:16 align: 8编译器内存对齐规则
考虑到结构体方便举例,这里只介绍结构体的对齐规则,其实其他的所有类型都需要做内存对齐
-
规则一:结构体第一个成员变量偏移量为0,后面的成员变量的偏移量等于成员变量大小和成员对齐系数两者中较小的那个值的最小整数倍,如果不满足规则,编译器会在前面填充值为0的字节空间
-
规则二:结构体本身也需要内存对齐,其大小等于各成员变量占用内存最大的和编译器默认对齐系数两者中较小的那个值的最小整数倍
我们用一个实例解释一下
type Demo1 struct {
a bool
b string
c int16
}
func main() {
demo1 := Demo1{}
fmt.Printf("demo1 size:%d\n", unsafe.Sizeof(demo1))
}先看结果
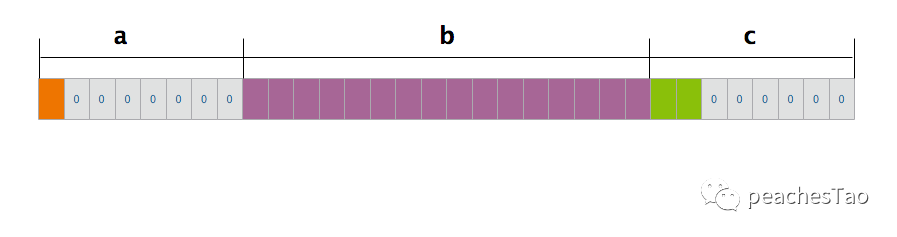
demo1 size:32demo1占用32个字节大小,分析如下:
首先根据第一条规则:
-
a成员,bool类型,占用1个字节大小,对齐系数为1,因为是第一个成员,偏移量为0,所有不需要填充,直接排在内存空间的第一位
-
b成员,string类型,占用16个字节大小,对齐系数为8,当前偏移量为2,根据规则一,其偏移量为两者中较小的8,所以调整后的偏移量为8,b的前面要填充7个字节,从第9位开始占用16个字节空间
-
c成员,int16类型,占用2个字节大小,对齐系数为2,当前偏移量为24,根据规则一,其偏移量为两者中较小的,为2,24满足条件2的倍数条件,所以不需要填充,从第25位开始占用2个字节空间
第一条规则算下来结构体占用大小=8+16+2=26
接下来看第二条规则
通过上面分析结构体最大成员变量大小为16,编译器默认对齐系数为8,取两者最小值8的最小整数倍,因本身结构体当前大小为26,所以最后结构体大小=4*8=32
如果我们把成员a和b的位置调换一下情况会怎样?
type Demo2 struct {
a string
b bool
c int16
}
func main() {
demo2 := Demo2{}
fmt.Printf("demo2 size:%d\n", unsafe.Sizeof(demo2))
}结果如下
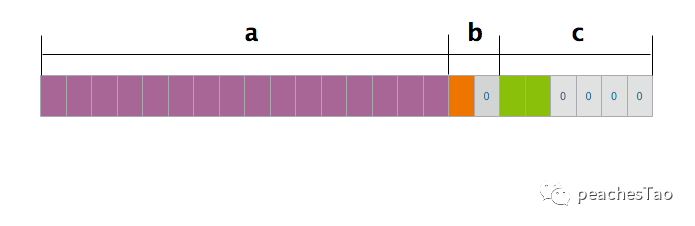
demo2 size:24占用24个字节空间,为什么少了8个字节大小?接着分析:
首先根据第一条规则:
-
a成员,string类型,占用16个字节大小,对齐系数为8,当前偏移量为0,不需要填充,从第1位开始占用16个字节空间
-
b成员,bool类型,占用1个字节大小,对齐系数为1,当前偏移量为16,根据规则一,其偏移量为两者中较小的,为1,16满足条件1的倍数,所以不需要填充,从第17位开始占用1个字节空间
-
c成员,int16类型,占用2个字节大小,对齐系数为2,当前偏移量为17,根据规则一,其偏移量为两者中较小的2的最小倍数,所以偏移量调整为2*9=18,c的前面需要填充1个字节,从第19位开始占用2个字节空间
第一条规则算下来结构体占用大小=16+2+2=20
接下来看第二条规则
通过上面分析结构体最大成员变量大小为16,编译器默认对齐系数为8,取两者最小值16的最小整数倍,因本身结构体当前大小为20,所以最后结构体大小=3*8=24
通过demo1和demo2分析对比,结构体成员变量的顺序会影响整个结构体的占用内存大小
对于内存对齐,程序员能做点什么
编译器已经对变量做了内存对齐,程序员可以通过调整成员变量顺序减少结构体占用大小,节省内存,对性能要求很高的场景还是有必要做的,如果对性能要求不那么高,记住一个大原则:将大的变量放在前面,如果你完全不care性能,则可以略过此篇文章。
有人可能会问,编译器能把内存对齐的工作做了,为什么不接着在编译期把结构体成员变量顺序优化呢?这样可以降低程序员的心智负担。
如果编译器自动优化了结构体成员变量顺序,数据经过网络传输后怎么能正确的还原回原来的结构体呢?
reference
https://zhuanlan.zhihu.com/p/53413177
https://ms2008.github.io/2019/08/01/golang-memory-alignment/
https://blog.csdn.net/EDDYCJY/article/details/119769942
https://www.xhyonline.com/?p=1238
https://blog.csdn.net/weixin_33769207/article/details/91699678)
https://stackoverflow.com/questions/381244/purpose-of-memory-alignment
https://developer.ibm.com/articles/pa-dalign/
https://github.com/golang/go/wiki/cgo#struct-alignment-issues
https://www.cnblogs.com/qcrao-2018/p/10964692.html















 1102
1102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









