










一、软件概述
Apache Livy is an open source REST interface for interacting with Apache Spark from anywhere. It supports executing snippets of code or programs in a Spark context that runs locally or in Apache Hadoop YARN.
- Interactive Scala, Python and R shells
- Batch submissions in Scala, Java, Python
- Multiple users can share the same server (impersonation support)
- Can be used for submitting jobs from anywhere with REST
- Does not require any code change to your programs
Apache Livy 是一个为 Apache Spark 提供的强大而灵活的 RESTful 接口,旨在让开发者无论在何处,都能轻松地与 Spark 进行交互。这个开源项目支持执行代码片段或程序,并且可以在本地 Spark 环境或 Apache Hadoop YARN 集群中运行。
Livy 的核心功能包括:
- 交互式 Shell:提供 Scala、Python 和 R 语言的交互式 shell。
- 批处理提交:支持 Scala、Java 和 Python 语言的批处理作业提交。
- 共享服务器:多用户可以安全地共享同一个 Livy 服务实例(支持身份冒充)。
- REST API 支持:无需修改代码,即可通过 RESTful API 方便地提交任务。
- 兼容性广泛:适配各种 Spark 版本,无需重新编译。
应用场景
- 大数据分析:开发人员可以通过 Livy 快速向分布式 Spark 集群提交数据处理任务,无需直接操作集群。
- Web 应用集成:将 Livy 集成到 Web 应用中,实现前端直连 Spark 进行实时数据分析。
- 远程协作:远程团队可以利用 Livy 的 REST API 在同一平台上进行合作,提高协同效率。
- 教学环境:教育者可以利用 Livy 创建一个互动的 Spark 学习平台,让学生通过 REST 请求提交作业并查看结果。
总的来说,Apache Livy 是一个强大、开放且易于使用的工具,对于那些希望在 Spark 上构建更高效、更灵活的数据处理系统的开发者而言,它是一个理想的选择
二、资料地址
1、官网地址
2、代码地址
3、下载地址
4、接口文档
三、执行流程
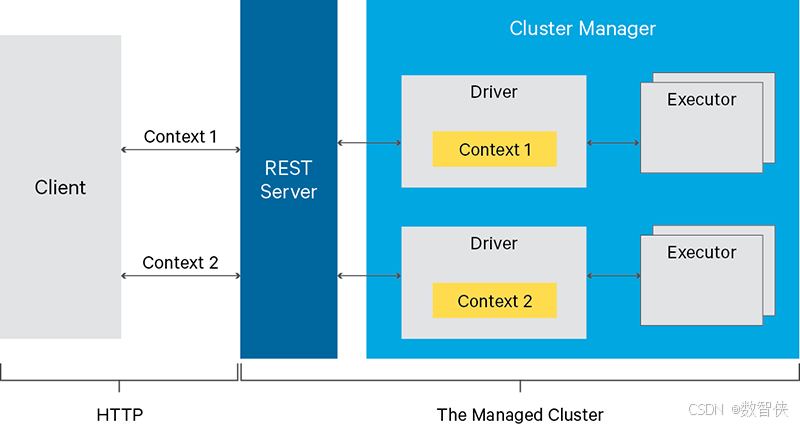
Livy把spark交互式和批处理都搬到了web上,提供restful接口,Livy一方面接收并解析客户端提交的REST请求,转换成相应的操作,另一方面它管理着客户端所启动的spark集群
Livy会为用户运行多个session,每个session就是一个常驻的spark context也可以成为一个spark集群。用户通过restful接口在对应的spark context执行代码,Livy服务端通过RPC协议与Spark集群进行通信。根据交互方式不同,Livy将会话分成两种类型:
- 交互式会话(interactive session):交互式会话在其启动后可以接收用户所提交的代码片段,在远端spark集群中编译并执行。
- 批处理会话(batch session):用户可以通过Livy以批处理的方式启动Spark应用。
这两种方式与原生spark是类似的,其中交互式会话它们的主要不同点是,spark-shell会在当前节点上启动REPL来接收用户的输入,而Livy交互式会话则是在远端的Spark集群中启动REPL,所有的代码、数据都需要通过网络来传输。
四、软件安装
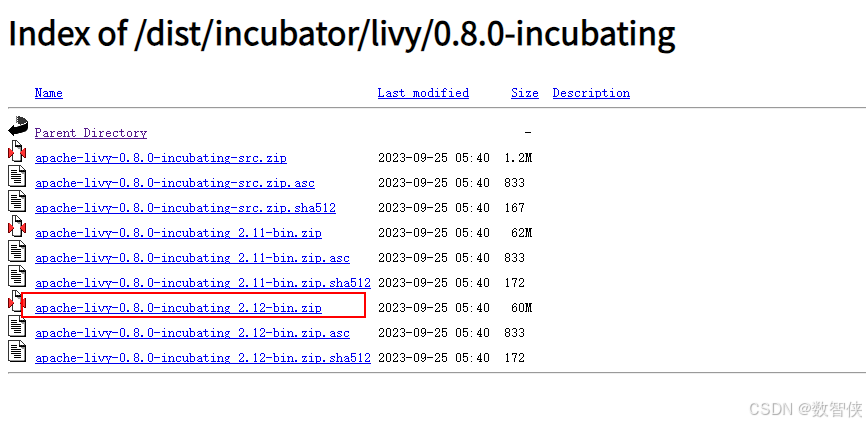
1、软件下载
Index of /dist/incubator/livy/0.8.0-incubating
2、上传
将软件上传到Linux系统的目录下/usr/local/soft/
3、解压
cd /usr/local/soft/
unzip apache-livy-0.8.0-incubating_2.12-bin.zip4、拷贝配置文件
cd /usr/local/soft/apache-livy-0.8.0-incubating_2.12-bin
mkdir log
cd conf
cp livy.conf.template livy.conf
cp livy-env.sh.template livy-env.sh5、修改livy.conf配置文件
livy.spark.master = yarn
livy.spark.deploy-mode = client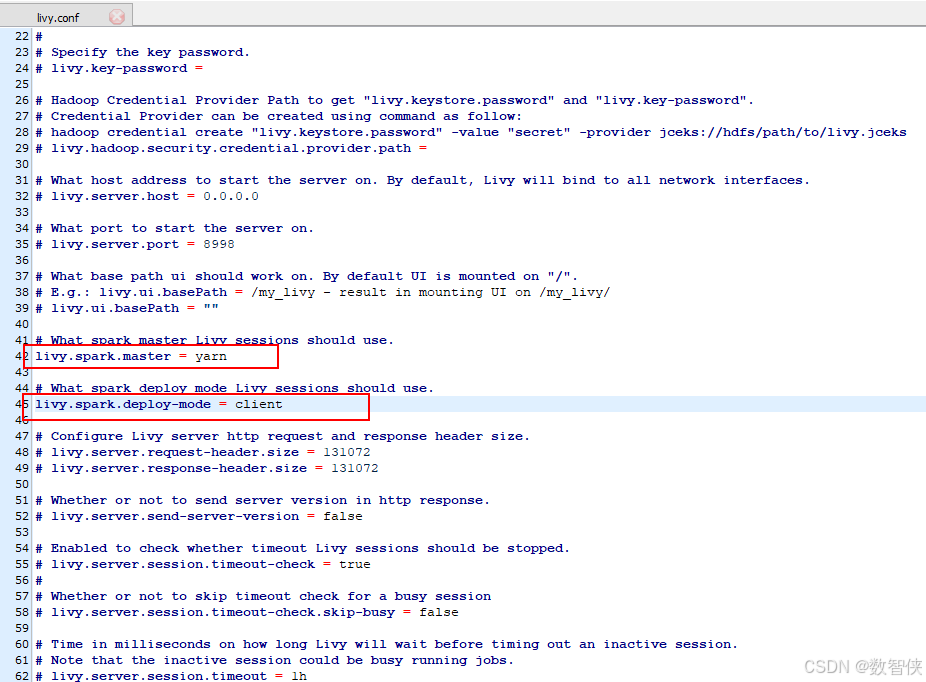
6、修改livy-env.sh文件
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-3.4.0/etc/hadoop
export SPARK_HOME=/usr/local/soft/spark-3.5.1-bin-hadoop3
export JAVA_HOME=/usr/local/soft/jdk1.8.0_381
export LIVY_LOG_DIR=/usr/local/soft/apache-livy-0.8.0-incubating_2.12-bin/log 注:hadoop、spark安装请参考其它部署文章
7、启动
cd /usr/local/soft/apache-livy-0.8.0-incubating_2.12-bin/
bin/livy-server start
查看状态
bin/livy-server status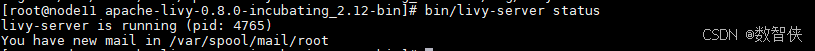
关闭
bin/livy-server stop8、访问
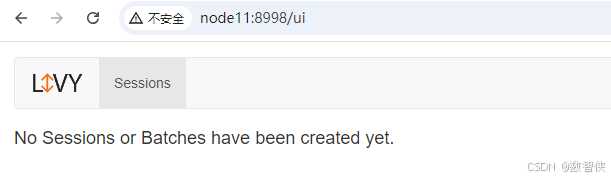
参考:


















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











