







在大语言模型(LLM)飞速发展的当下,其预训练数据成为决定模型性能的关键因素。虽然 LLM 缺乏完善的理论分析与数据定义,但多数研究人员认可预训练数据对模型效果和泛化能力影响重大。接下来,让我们深入探讨大语言模型预训练数据的各个方面。
一、数据来源
大语言模型预训练数据主要分为通用数据和专业数据。
(一)通用数据
通用数据规模庞大、类型多样且易于获取,对模型的语言建模和泛化能力意义非凡。
- 网页数据:网页是通用数据的主要组成部分。互联网的普及催生了海量网页数据,像 2016 年 Google 搜索引擎索引处理的网页超 130 万亿。不过,爬取和处理这些数据颇具挑战,为此研究人员构建了 ClueWeb09、CommonCrawl 等开源数据集。但网络数据质量参差不齐,过滤低质量文本对模型训练至关重要。
- 对话数据:对话数据涵盖书面对话、聊天记录等,能提升模型对话和问答能力。但其收集和处理难度大、数量少,常见的数据集有 PushShift.io Reddit、Ubuntu Dialogue Corpus 等。此外,还有使用大语言模型自动生成对话数据的 UltraChat 方法。
- 书籍数据:书籍承载丰富知识,包含多样化词汇、复杂文本结构和多种写作风格。通过书籍数据训练,模型可提升对不同领域的理解能力。但受版权限制,开源书籍数据集较少,常见的有 Pile 数据集中的 Books3 和 Bookcorpus2。
(二)专业数据
专业数据虽在通用大语言模型中占比低,但对提升模型特定任务能力不可或缺。
- 多语言数据:多语言数据对增强模型语言理解和生成多语言能力极为关键。如 BLOOM 预训练语料包含 46 种语言,PaLM 包含 122 种。多语言混合训练能提升翻译、多语言问答等任务能力,还可增加数据多样性。
- 科学文本数据:科学文本数据包括教材、论文等,有助于提升模型理解科学知识的能力。其来源广泛,因科学领域数据格式复杂,常需对公式、化学式等进行特定符号标记和预处理。
- 代码数据:代码数据是程序生成任务的必备训练数据。代码包含程序代码和注释信息,具有独特的格式化语言特点。其主要来源是编程问答社区和公共软件仓库,这些数据提供了丰富的代码使用场景和高质量开源代码。
二、数据处理
数据质量对大语言模型影响巨大,收集数据后需进行处理,主要包括质量过滤、冗余去除、隐私消除和词元切分。以下为典型大语言模型数据处理流程图

(一)低质过滤
低质量数据过滤方法主要有基于分类器和基于启发式的方法。基于分类器的方法通过训练文本质量判断模型过滤低质量数据,如 GPT-3、PaLM 等模型采用此方法,但可能会误删高质量的方言或口语文本。基于启发式的方法则通过精心设计的规则消除低质量文本,如语言过滤、指标过滤等,BLOOM 和 Gopher 模型使用了该方法。此外,自然语言处理领域的文章质量判断方法也可应用于大语言模型预训练数据过滤。
(二)冗余去除
文本冗余会降低模型多样性,导致训练不稳定。在句子级别,重复单词或短语的句子会影响模型预测;在文档级别,大部分模型依靠表面特征相似度检测并删除重复文档。如 RefinedWeb 在构造过程中进行了句子级别的过滤,LLaMA 采用 CCNet 的处理模式进行文档级别的重复判断。
(三)隐私消除
由于预训练数据多源于互联网,易包含敏感或个人信息,存在隐私泄露风险。删除隐私数据最直接的方法是基于规则的算法,如 BigScience ROOTS Corpus 利用命名实体识别算法检测并删除或替换个人信息。
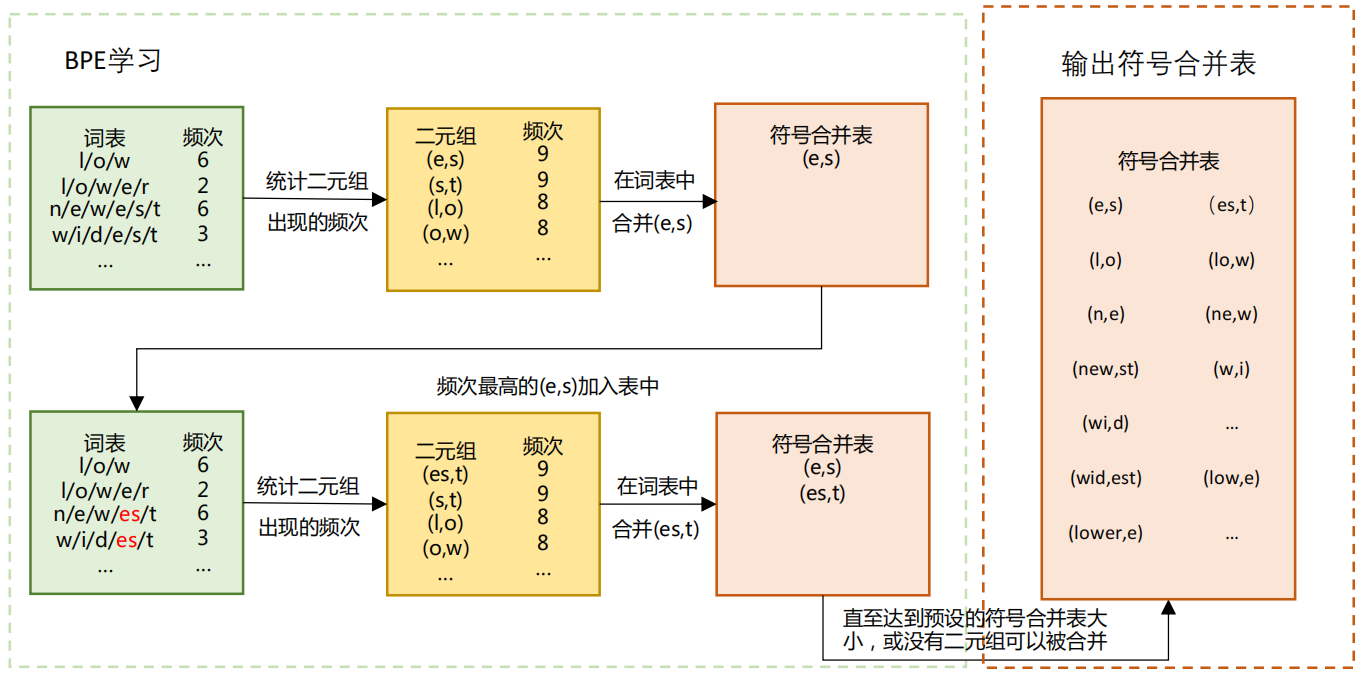
(四)词元切分
传统自然语言处理以单词为基本单元,存在未登录词问题。为解决此问题,研究人员提出子词词元化方法。常见的词元分析算法有字节对编码(BPE)、WordPiece 和 Unigram 词元分析。BPE 通过合并高频字节对构建词表,降低未登录词比例;WordPiece 通过训练语言模型选择似然概率增加最多的词元对进行合并;Unigram 词元分析则从大词元集合中迭代删除词元构建词表。BPE 模型中词元词表的计算过程如下:
三、数据影响分析
在训练大语言模型前,构建优质预训练语料库至关重要。下面从数据规模、质量和多样性三方面分析其对模型性能的影响。
(一)数据规模
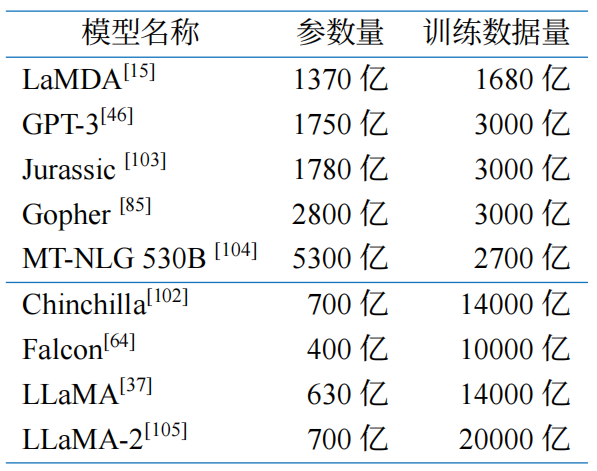
随着模型参数规模增加,需要足够数量的高质量数据进行有效训练。DeepMind 研究发现,模型大小和训练词元数量应等比例缩放以达到计算最优。例如,Chinchilla 语言模型为 700 亿参数,使用 1.4 万亿词元训练,在下游评估任务中表现优异。LLaMA 模型训练也表明,增加训练数据量可提升模型性能,较小模型使用更多数据和更长训练时间也能实现良好性能。不同任务类型对训练数据量的需求不同,模型获取常识知识和在下游自然语言理解任务取得好成绩需要更多数据训练。
(二)数据质量
数据质量是影响大语言模型训练效果的关键因素。包含大量重复的低质量数据会导致训练不稳定、模型不收敛。如 Gopher 语言模型在不同质量数据集上训练效果差异明显,使用经过过滤和去重的数据训练的模型表现更好。以下为Gopher 语言模型使用不同数据质量训练效果分析
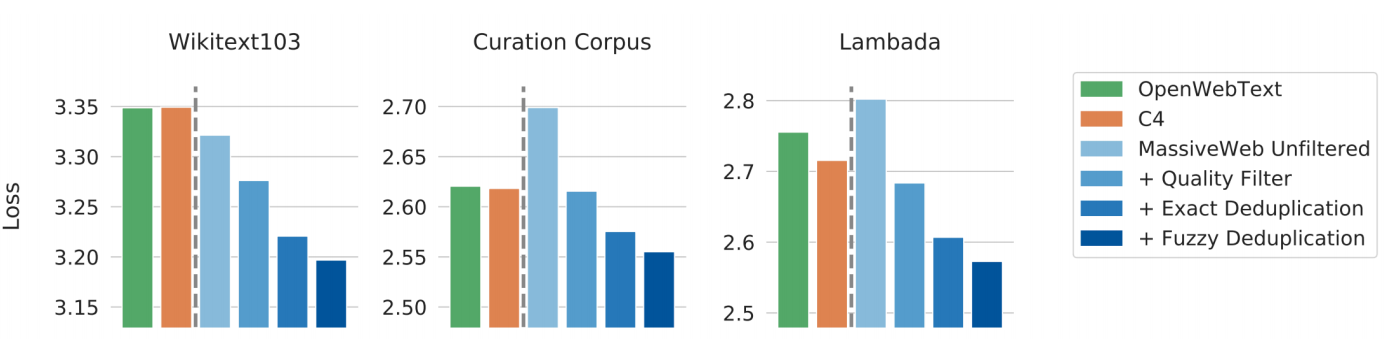
数据构建时间、噪声、有害信息和重复率等因素都会影响模型性能。训练数据和测试数据的时间错配会影响模型效果,数据集中的重复数据可能导致训练损失增加,影响模型性能和泛化能力。
(三)数据多样性
不同领域、语言和场景的训练数据能让大语言模型获得广泛知识。Gopher 模型训练过程对数据分布进行消融实验,结果表明不同子集采样权重训练得到的模型效果差别很大。采用不同采样权重训练得到的 Gopher 语言模型在下游任务上的性能如下
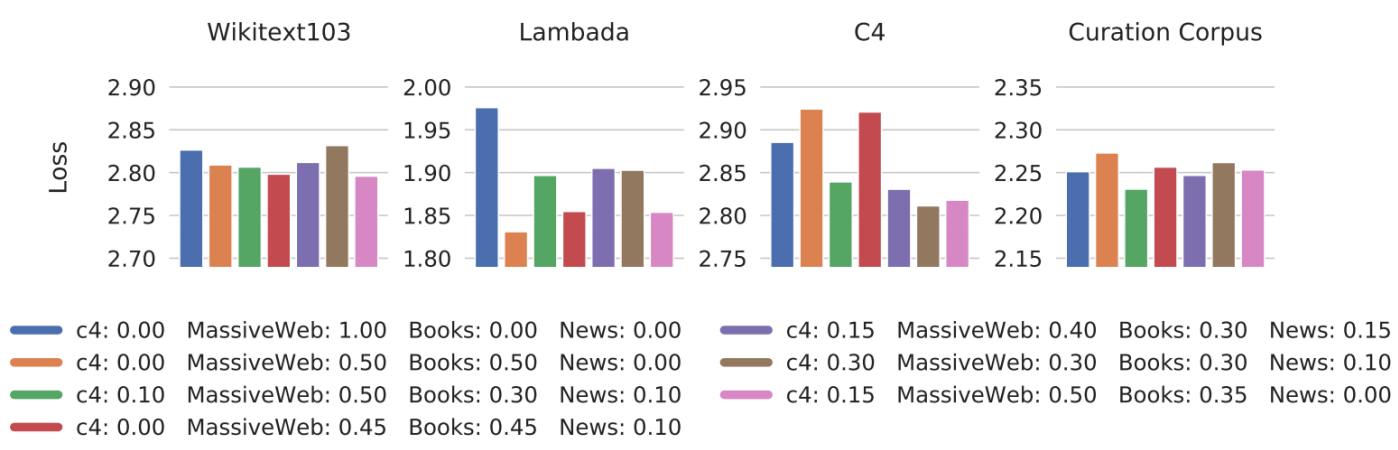
例如,增加书籍数据比例可提高模型捕获长期依赖关系的能力,使用更高比例的 C4 数据集有助于在 C4 验证集上获得更好表现。
总结
在大语言模型预训练过程中,数据准备和处理是工程量最大且花费人力最多的部分。当前模型训练采用的词元数量都很大,LLaMA-2 训练使用了2 万亿词元,Baichuan-2 训练使用了2.6 万亿词元,对应的训练文件所需硬盘存储空间近10TB。这些数据还是经过过滤的高质量数据,原始数据来源更是可以达到数百TB。 原始数据获取需要大量网络带宽和存储空间。对原始数据进行分析和处理,产生能够用于模型训练的高质量纯文本内容,则需要花费大量的人力。这其中,看似简单的文本内容提取、质量判断、数据去重等都需要很多精细化处理。例如,大量的图书数据采用PDF 格式进行存储,虽然很多PDF 文本并不是扫描件,但是PDF 文件协议是按照展示排版进行设计的,从中提取纯文本内容并符合人类阅读顺序,并不是直接使用PyPDF2、Tika 等开源工具就可以高质量完成的。
海量数据处理过程仅靠单服务器需要花费很长时间,因此需要使用多服务器并行处理,需要利用Hadoop、Spark 等分布式编程框架完成。此外,很多确定性算法的计算复杂度过高,即便使用大量服务器也没有降低总体计算量,仍然需要大量的时间。为了进一步加速计算,还需要考虑使用概率性算法或概率性数据结构。 例如,判断一个URL 是否与已有数据重复,如果可以接受一定程度上的假阳性,那么可以采用布隆过滤器(Bloom Filter),其插入和测试操作的时间复杂度都是O(k),与待查找的集合中的URL 数量无关。虽然其存在一定的假阳性概率,但是对于大语言模型数据准备这个问题,非常少量的数据因误判而丢弃,并不会影响整体的训练过程。
大语言模型预训练数据的来源、处理和质量对模型性能影响深远。在未来的研究和实践中,我们需不断优化数据处理方法,构建更优质的预训练语料库,推动大语言模型技术持续发展。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











