







在人工智能飞速发展的当下,大语言模型(LLMs)展现出了令人惊叹的能力,从智能问答到内容创作,其应用场景日益广泛。但随着模型参数量和训练数据量呈指数级增长,传统单设备训练方式已难以满足需求,分布式训练(Distributed Training)技术应运而生,成为推动大语言模型发展的核心驱动力。今天,就和大家深入探讨一下分布式训练的方方面面。
一、分布式训练:解决资源瓶颈的必然选择
随着语言模型参数量和所需训练数据量的急速增长,单个机器的资源就显得捉襟见肘。以 2022 年拥有 5400 亿参数的 PalM 模型为例,其对算力和内存的需求远远超出了单台设备的承载能力。分布式训练(Distributed Training)正是为了解决这一难题而诞生,它将机器学习或深度学习模型训练任务分解成多个子任务,然后在多个计算设备上并行训练。这里的计算设备可以是 CPU、GPU、TPU 或 NPU 。
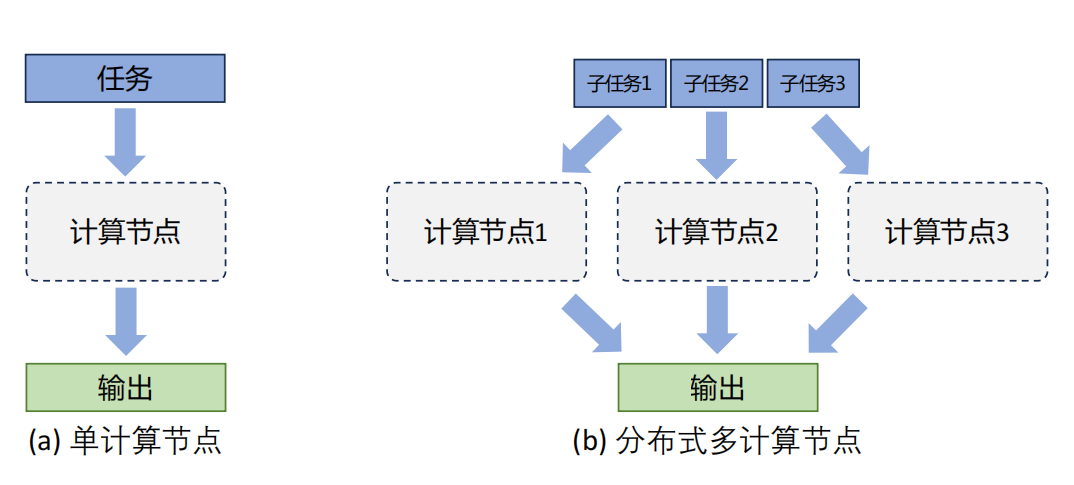
上图给出了单个计算设备和多个计算设备的示例,这里计算设备可以是中央处理器(Central Processing Unit,CPU)、图形处理器(Graphics Processing Unit,GPU)、张量处理器(Tensor Processing Unit,TPU)也可以是神经网络处理器(Neural network Processing Unit,NPU)。
从系统架构角度看,即使同一服务器内的多个计算设备,其内存也可能不共享,所以无论是在同一服务器还是多个服务器中的计算设备,都属于分布式系统范畴。
一个模型训练任务往往会有大量的训练样本作为输入,可以利用一个计算设备完成,也可以将整个模型的训练任务拆分成子任务,分发给不同的计算设备,实现并行计算。
此后,还需要对每个计算设备的输出进行合并,最终得到与单个计算设备等价的计算结果。由于每个计算设备只需要负责子任务,并且多个计算设备可以并行执行,因此其可以更快速地完成整体计算,并最终实现对整个计算过程的加速。
促使分布式训练系统发展的关键因素是单设备算力的局限。从 2013 年的 AlexNet 到 2022 年的 PalM 模型,机器学习模型的参数规模每 18 个月增长 56 倍,而训练数据量也呈指数级增长,这使得对算力的需求急剧攀升。
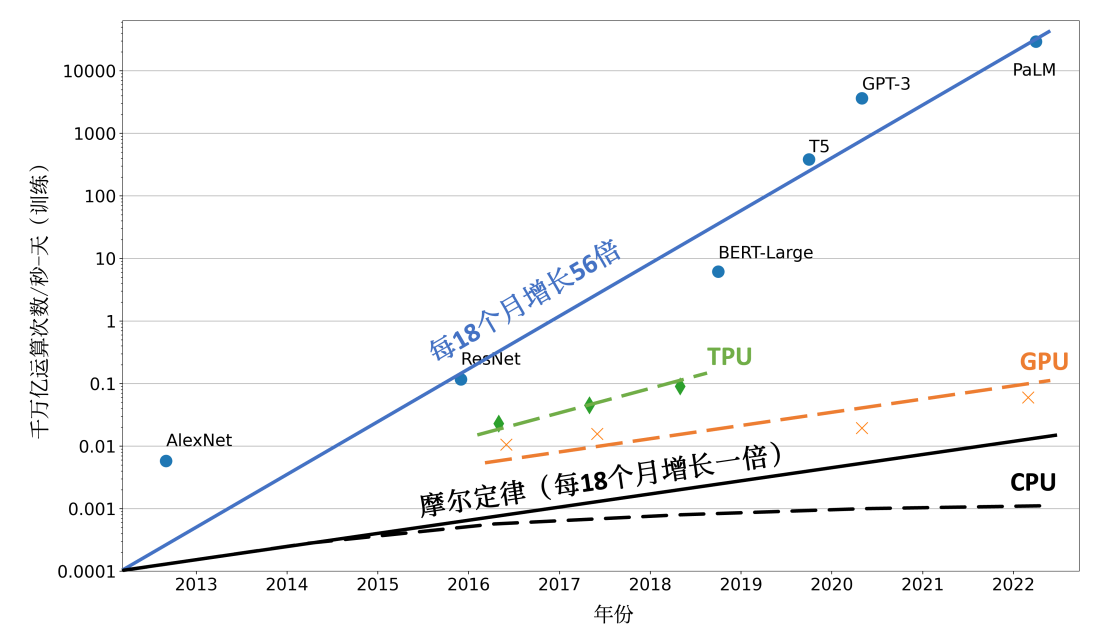
然而,近几年 CPU 的算力增长远低于摩尔定律,即便 GPU、TPU 等计算加速设备提供了额外算力,但其增长速度仍未突破每 18 个月翻倍的摩尔定律。因此,为了能够满足机器学习模型的发展,只有通过分布式训练系统才可以匹配模型不断增长的算力需求。
二、分布式训练的目标与核心要素
分布式训练的总体目标很明确,就是提升总的训练速度,减少模型训练的总体时间。总训练速度可以用公式简略估计:
总训练速度 ∝ 单设备计算速度 X 计算设备总量 X 多设备加速比。
a、单设备计算速度主要取决于单块计算加速芯片的运算速度和数据 I/O 能力。为优化单设备训练效率,常见的技术手段有混合精度训练、算子融合、梯度累加等。
b、计算设备数量增多时,理论峰值计算速度会提高,但受通信效率影响,加速比会降低。
c、多设备加速比由计算和通讯效率决定,这需要结合算法和网络拓扑结构进行优化,也是分布式训练并行策略的主要目标。
三、大语言模型中的分布式训练实践
大语言模型因其巨大的参数量和数据量,都采用了分布式训练架构。
☘️OPT 模型,训练时使用了 992 块 NVIDIA A100 80G GPU,采用全分片数据并行(Fully Sharded Data Parallel)以及 Megatron-LM 张量并行(Tensor Parallelism),整体训练时间将近 2 个月。
☘️BLOOM 模型训练花费 3.5 个月,使用 48 个计算节点,每个节点包含 8 块 NVIDIA A100 80G GPU(总计 384 个 GPU)。节点内部 GPU 之间通过 4*NVLink 通信,节点之间则采用四个 Omni-Path 100 Gbps 网卡构建的增强 8 维超立方体全局拓扑网络进行通信。
☘️LLaMA 模型训练同样采用 NVIDIA A100-80GB GPU,不同规模的模型训练所需的 GPU 小时数差异巨大,如 LLaMA-7B 模型训练需要 82432 GPU 小时,而 LLaMA-65B 模型训练花费则高达 1022362 GPU 小时。
四、分布式训练面临的挑战
虽然分布式训练为大语言模型训练提供了可行方案,但仍面临诸多挑战。
🔔计算墙方面,单个计算设备的计算能力与大语言模型所需总计算量差距悬殊。例如,2022 年 3 月发布的 NVIDIA H100 SXM 单卡 FP16 算力为 2000 TFLOPs,而 GPT-3 需要 314 ZFLOPs 的总计算量,两者相差 8 个数量级。
🔔显存墙也不容忽视,单个计算设备无法完整存储大语言模型的参数。以 GPT-3 为例,其包含 1750 亿参数,推理阶段若采用 FP32 格式存储,需要 700GB 内存空间,而 NVIDIA H100 GPU 只有 80GB 显存。
🔔通信墙同样是个大问题。分布式训练系统中各计算设备之间频繁进行参数传输和同步,通信延迟和带宽限制可能成为训练瓶颈。在 GPT-3 训练过程中,如果分布式系统中有 128 个模型副本,每次迭代至少需要传输 89.6TB 的梯度数据,而截至 2023 年 8 月,单个 InfiniBand 链路仅能提供不超过 800Gb/s 的带宽。
五、总结
分布式训练是大语言模型训练的关键技术,尽管面临诸多挑战,但随着技术的不断发展和创新,相信这些问题都将逐步得到解决,为人工智能的发展注入更强大的动力。希望本文的分享能让大家对分布式训练有更深入的理解,欢迎在评论区留言讨论。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











