







Spark 学习之路三——Spark 的核心之 RDD 进阶
文章目录
一、Spark 优化
1.1 常用参数说明
## driver 内存大小,一般没有广播变量(broadcast)时,设置4g足够,如果有广播变量,视情况而定,可设置6G、8G、12G等均可
--driver-memory 4g
## 每个executor的内存,正常情况下是4g足够,但有时处理大批量数据时,容易内存不足,再多申请一点,如6G
--executor-memory 4g
## 总共申请的executor数目,普通任务十几个或者几十个足够了,若是处理海量数据如百G上T的数据时可以申请多一些,100,200等
--num-executors 15
## 每个executor内的核数,即每个executor中的任务task数目,此处设置为2,即2个task共享上面设置的6g内存,每个map或reduce任务的并## 行度是executor数目*executor中的任务数,yarn集群中一般有资源申请上限,如,executor-memory*num-executors < 400G等,所以调## 试参数时要注意这一点
--executor-cores 2
## Spark 作业的默认为500~1000个比较合适,如果不设置,spark会根据底层HDFS的block数量设置task的数量,这样会导致并行度减少,资源## 利用不充分。该参数设为num-executors * executor-core的2~3倍较合适。
--spark.default.parallelism 200
## 设置 RDD 持久化数据在 Executor 内存中能否占的最大比例。默认是 0.6
--spark.storage.memoryFraction 0.6
## 设置 Shuffle 过程中一个 task 拉取到上个 stage 的 task的输出后,进行聚合操作时能够使用的 Executor 的内存比例,默认是0.2.如## 果 Shuffle 聚合时使用的内存超过了这个 20% 的限制,多余数据会被溢写到磁盘文件中区,降低 Shuffle 性能
--spark.shuffle.memoryFraction 0.2
## executor 执行的时候,用的内存可能会超过 executor-memory,所以会为 executor 额外预留一部分内存,## spark.yarn.executor.memoryOverhead即代表这部分内存
--spark.yarn.executor.memoryOverhead 1G
1.2 Spark 常用编程建议
- 避免创建重复的
RDD,尽量复用同一份数据 - 尽量避免使用
shuffle类算子,因为shuffle操作是spark中最消耗性能的地方,reduceByKey,join,distinct,repartition等算子都会触发shuffle操作,尽量使用map类的非``shuffle`算子 - 用
aggregateByKey和reduceByKey替代groupByKey,因为前两个是预聚合操作,会在每个节点本地对相同的key做聚合,等其他节点拉取所有节点上相同的key时,会大大减少磁盘IO以及网络开销。 repartition适用于RDD[V],partitionBy适用于RDD[K,V]mapPartitions操作替代普通map,foreachPartitions替代foreachfilter操作之后进行coalesce操作,可以减少RDD的partition数量- 如果有
RDD复用,尤其是该RDD需要花费比较长的时间,建议对该RDD做cache,若该RDD每个partition需要消耗很多内存,建议开启Kryo序列化机制(据说可节省2到5倍空间),若还是有比较大的内存开销,可将storage_level设置为MEMORY_AND_DISK_SER - 尽量避免在一个
Transformation中处理所有的逻辑,尽量分解成map、filter之类的操作 - 多个
RDD进行union操作时,避免使用rdd.union(rdd).union(rdd).union(rdd)这种多重union,rdd.union只适合2个RDD合并,合并多个时采用SparkContext.union(Array(RDD)),避免union嵌套层数太多,导致的调用链路太长,耗时太久,且容易引发StackOverFlow spark中的Group/join/XXXByKey等操作,都可以指定partition的个数,不需要额外使用repartition和partitionBy函数- 尽量保证每轮
Stage里每个task处理的数据量>128M - 如果2个
RDD做join,其中一个数据量很小,可以采用Broadcast Join,将小的RDD数据collect到driver内存中,将其BroadCast到另外以RDD中, - 2个
RDD做笛卡尔积时,把小的RDD作为参数传入,如BigRDD.certesian(smallRDD) - 若需要
Broadcast一个大的对象到远端作为字典查询,可使用多executor-cores,大executor-memory。若将该占用内存较大的对象存储到外部系统,executor-cores=1,executor-memory=m(默认值2g),可以正常运行,那么当大字典占用空间为size(g)时,executor-memory为2*size,executor-cores=size/m(向上取整) - 如果对象太大无法
BroadCast到远端,且需求是根据大的RDD中的key去索引小RDD中的key,可使用zipPartitions以hash join的方式实现,具体原理参考下一节的shuffle过程 - 如果需要在
repartition重分区之后还要进行排序,可直接使用repartitionAndSortWithinPartitions,比分解操作效率高,因为它可以一边shuffle一边排序
二、Spark 中的两种依赖关系
2.1 宽依赖
子RDD的每个Partition都依赖于父RDD的所有Partition
对单个RDD基于key进行重组和reduce,如groupByKey,reduceByKey
对两个RDD基于key进行join和重组,如join
经过大量shuffle生成的RDD,建议进行缓存。这样避免失败后重新计算带来的开销。
2.2 窄依赖
子RDD的每个Partition只依赖一个或部分的Partition
输入输出一对一的算子,且结果RDD的分区结构不变。主要是map/flatmap
输入输出一对一的算子,但结果RDD的分区结构发生了变化,如union/coalesce
从输入中选择部分元素的算子,如filter、distinct、substract、sample
2.3 DAG
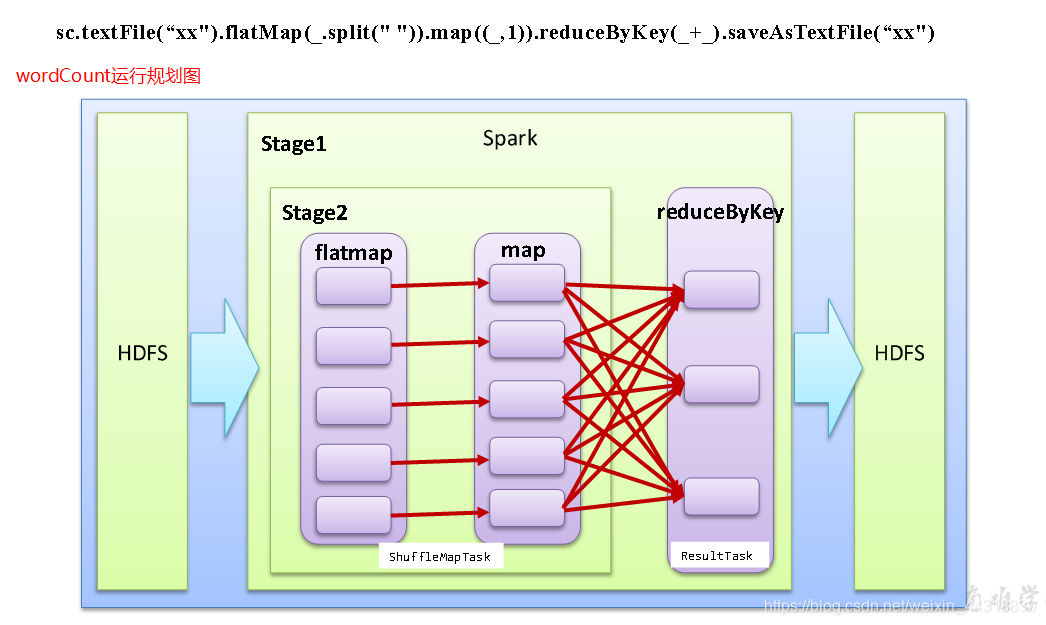
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
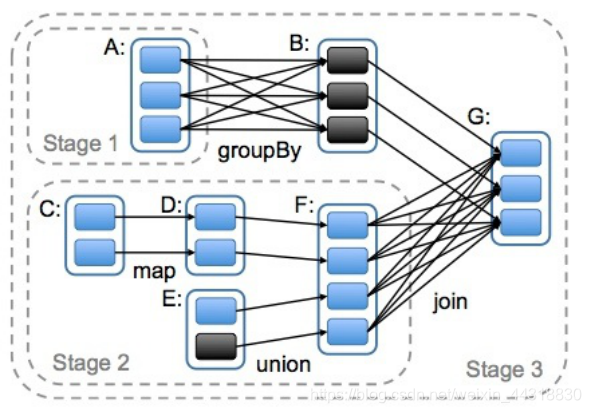
2.4 任务的划分(重点)
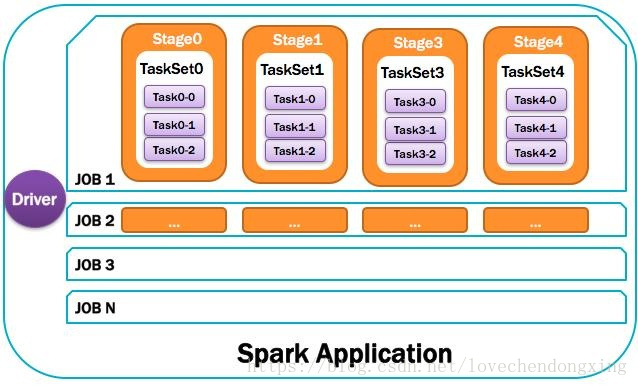
RDD任务切分中间分为:Application、Job、Stage和Task。
-
Application:初始化一个SparkContext即生成一个Application -
Job:一个Action算子就会生成一个Job -
Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。 -
-
Task:Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即为一个Task。注意: Application -> Job-> Stage-> Task 每一层都是 1对n 的关系。
2.5 RDD的缓存与检查点
2.5.1 RDD 缓存
RDD的缓存通过persist方式或cache方法将前面的计算结果缓存,默认情况下persist()会把数据序列化的形式缓存在JVM的堆空间中- 但是并不是这两个方法被调用立刻缓存,而是触发后面的
action行动算子时,该RDD将会缓存在计算节点的内存中,并供后面使用 - 缓存有可能丢失,或者存储于内存的数据由于内存不足时而被删除,
RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重用,由于RDD的各个partition丑姑娘预分区是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部partition
2.5.2 RDD 检查点
spark中对于数据的保存处理持久化操作之外,还提供了一种检查点机制,检查点本质是通过RDD写入disk(磁盘)做检查点,是为了通过lineage做容错的辅助,lineage过长会导致容错成本过高,这样就不如在中间点做检查点容错,如果之后有节点出现问题而丢失分区,从检查点RDD未开始重做lineage,就会减少开销,检查点通过将数据写入到HDFS文件系统实现了RDD的检查功能。RDD缓存和检查点一般用于RDD血缘关系较长时。- 缓存存在内存中,检查点存在磁盘中。
2.6 累加器和广播变量
2.6.1 累加器
- 累加器只写共享变量
- 累加器用来对信息进行聚合,通常在想
spark传递函数时,比如使用map()或者filter()传条件时,可以使用驱动器程序定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。如果我们想实现所有分片处理时更新共享变量的功能,那么累机器就可以实现我们的需求。
2.6.2 广播变量
- 广播变量是只读共享变量
- 广播变量用来高效分发较大对象,向所有工作节点发送一个较大的只读值,以供一个活多个
spark操作使用,比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是及其学习算法中的一个很大的特征向量,广播变量用起来都很顺手。在多个并行操作中使用同一个变量,spark会为每个任务分别发送
三、Spark 的原理
3.1 Spark 的运行流程
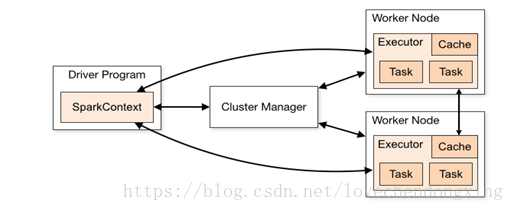
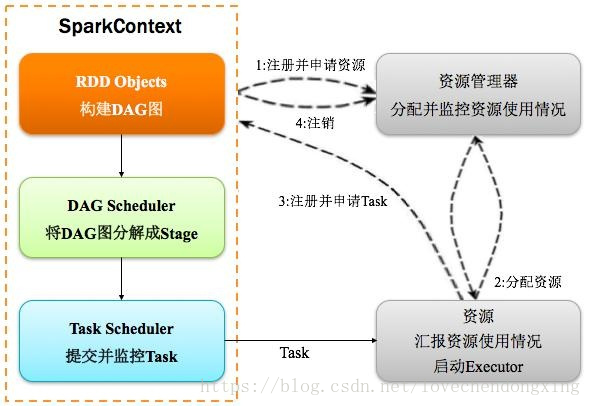
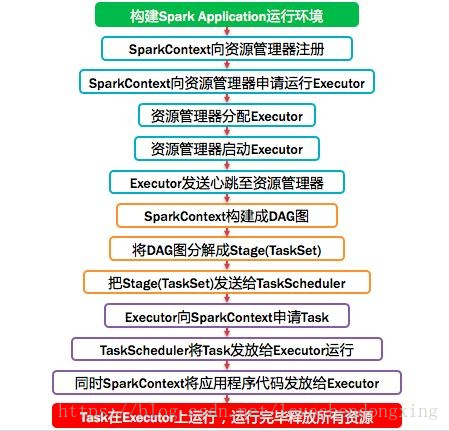
Spark应用程序以进程集合为单位在分布式集群上运行,通过driver程序的main方法创建的SparkContext对象与集群交互。
Spark通过SparkContext向Cluster manager(资源管理器)申请所需执行的资源(cpu、内存等)Cluster manager(资源管理器)分配应用程序执行需要的资源,在Worker节点上创建ExecutorSparkContext将程序代码(jar包或者python文件)和Task任务发送给Executor执行,并收集结果给Driver
3.2 Spark 的运行涉及概念
3.2.1 Application:Spark应用程序
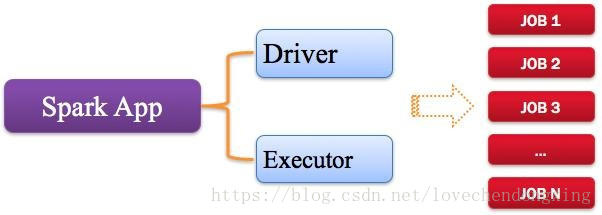
指的是用户编写的Spark应用程序,包含了Driver功能代码和分布式在集群中多个节点上运行的Executor代码。
Spark应用程序,由一个活多个作业JOB组成,如下图所示:
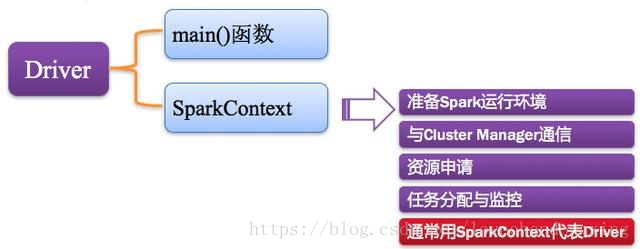
3.2.2 Driver:驱动程序
Spark中的Driver即运行上述Application的Main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常SparkContext代表Driver,如下图所示。
3.2.3 Cluster Manager:资源管理器
指的是在集群上获取资源的外部服务,常用的有:Standalone,Spark原生的资源管理器,由Master负责资源的分配;Hadoop Yarn,由Yarn中的ResourceManager负责资源的分配;Messos,由Messos中的Messos Master负责资源管理
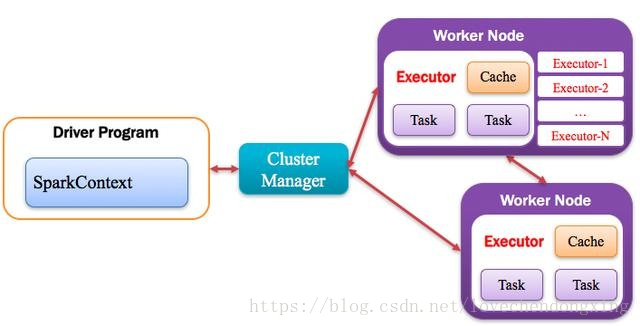
3.2.4 Executor:执行器
Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor,如下图所示。
3.2.5 Worker:计算节点
集群中任何可以运行Application代码的节点,类似于Yarn中的NodeManager节点。在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点,在Spark on Messos模式中指的就是Messos Slave节点,如下图所示。
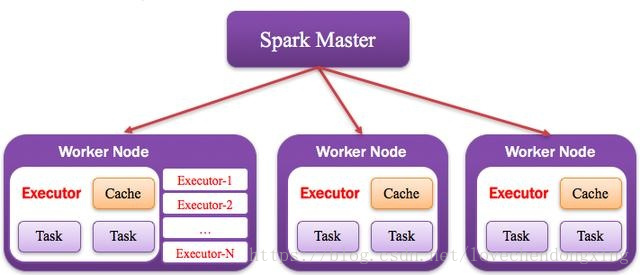
3.2.6 DAGScheduler:有向无环图调度器
基于DAG划分Stage并以TaskSet的形式提交Stage给TaskScheduler;负责将作业拆分成不同阶段的具有依赖关系的多批任务;最重要的任务之一就是:计算作业和任务的依赖关系,指定调度逻辑、在SparkContext初始化的过程中被实例化,一个SparkContext对应创建一个DAGScheduler。
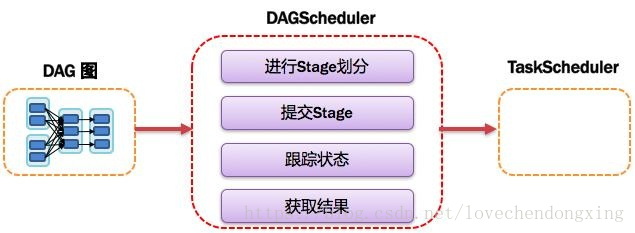
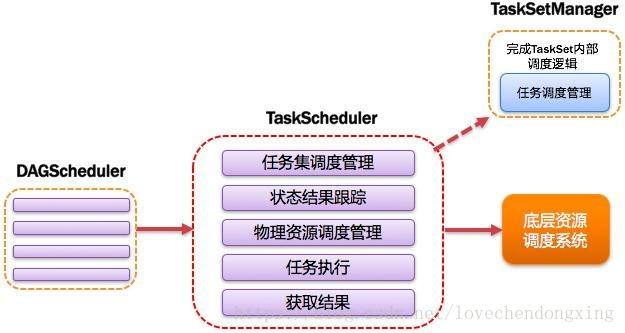
3.2.7 TaskScheduler:任务调度器
将TaskSet提交给worker(集群)运行并回报结果;负责每个具体任务的物理调度。如果所示:
3.2.8 Job:作业
由一个或多个调度阶段所组成的一次计算作业;包含多个Task组成的并行计算,往往由Spark Action催生,一个JOB包含多个RDD及作用于相应RDD上的各种Operation。如图所示:
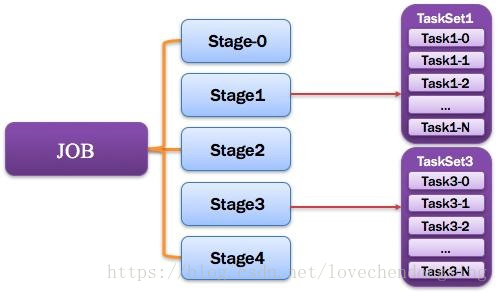
3.2.9 Stage:调度阶段
一个任务集对应的调度阶段;每个Job会被拆分很多组Task,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段;Stage分成两种类型ShuffleMapStage,ResultStage。如图所示:
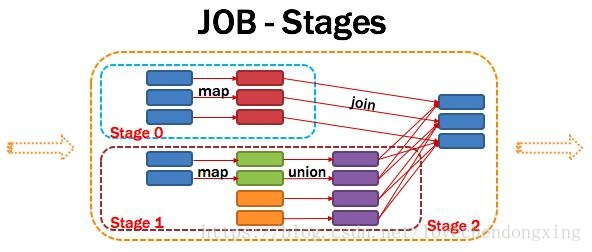
Application多个job多个stage:Spark Application中可以因为不同的Action触发众多的job,一个Application钟可以有很多的job,每个job是由一个或者多个Stage构成的,后面的Stage依赖于前面的Stage,也就是说只有前面依赖的Stage计算完毕后,后面的Stage才会运行。
划分依据:Stage划分的依据就是宽依赖,何时产生宽依赖,reduceByKey,groupByKey等算子,会导致宽依赖的产生。
核心算法:从后往前回溯,遇到窄依赖加入本Stage,遇见宽依赖进行Stage切分。Spark内核会从触发Action操作的那个RDD开始从后往前推,首先会为最后一个RDD创建一个Stage,然后继续倒推,如果发现对某个RDD是宽依赖,那么就会将宽依赖的那个RDD创建一个新的stage,那个RDD就是新的stage的最后一个RDD。然后依此类推,继续倒推,根据窄依赖或者宽依赖进行stage的划分,直到所有的RDD全部遍历完成为止。
3.2.10 TaskSet:任务集
由一组关联的,但相互之间没有Shuffle依赖关系的任务所组成的任务集。如图所示:
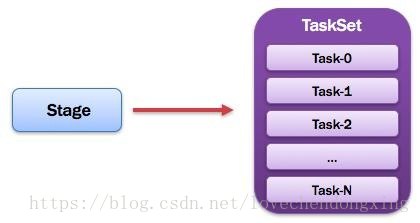
提示:
1)一个Stage创建一个TaskSet;
2)为Stage的每个Rdd分区创建一个Task,多个Task封装成TaskSe
3.2.11 Task:任务
被送到某个Executor上的工作任务;单个分区数据集上的最小处理流程单元(单个stage内部根据操作数据的分区数划分成多个task)。如图所示。
小结:
四、Spark 的 Shuffle
五、Spark SQL
5.1 Spark SQL 概述
5.1.1 Spark SQL 官方概述
5.1.1.1 官网 地址
5.1.1.2 什么是 Spark SQL
Spark SQL 是 Spark 用来处理结构化数据的一个模块
Spark SQL 还提供了多种使用方式,包括DataFrames API和DataSets API等
但无论是哪种 API 或者是编程语言,它们都是基于同样的执行引擎,因此你可以在不同的 API 之间随意切换,它们各有各的特点
5.1.1.3 Spark SQL 的特点
-
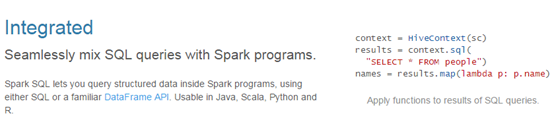
易整合
将sql查询与spark程序无缝混合,可以使用java、scala、python、R等语言的API操作
-
统一的数据访问
以相同的方式连接到任何数据源

-
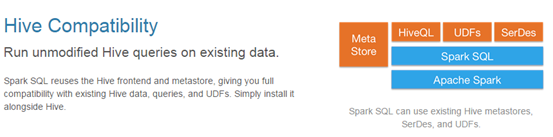
兼容 Hive
支持 hive HQL 的语法
兼容 hive (元数据库、SQL 语法、UDF、序列化、反序列化机制)
-
标准的数据连接
可以使用行业标准的JDBC或ODBC连接

5.1.1.4 Spark SQL 的优缺点
-
优点
表达清晰,难度低,易学习
-
缺点
复杂分析、SQL 嵌套较多;机器学习较难
5.1.2 Spark SQL 数据抽象
5.1.2.1 DataFrame
与RDD类似,DataFrame也是一个分布式数据容器,然而DataFrame更像传统数据库的二维表格,处理表格以外,还记录数据的结构信息,即schema。
同时,与hive类似,DataFrame也支持嵌套数据类型(struct,array,map)。
从API易用性的角度上看,DataFrame API提供的是一套高层的关系操作,比函数式RDD API要更加友好,门槛更低。
5.1.2.2 DataSet
与RDD相比,保存了更多的描述信息,概念上等同于关系型数据库中的二维表
是DataFrame API的一个扩展,是spark最新的数据抽象
用户友好API风格,既具有类型安全检查也具有DataFrame的查询优化特性
DataSet支持编解码器,当需要访问非堆上的数据时可以避免反序列化整个对象,提高了效率
样例类备用在DataSet中定义数据的结构信息,样例类中的每个属性的名称直接映射到DataSet中的字段名称
调用DataSet的方法会先生成逻辑计划,然后被spark的优化器进行优化,最终生成物理计划,然后提交到集群中运行
DataSet包含了DataFrame的功能,Spark 2.0 中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。DataFrame其实就是DataSet[Row]
5.1.2.3 DF,DS的创建
-
DS的创建- 由
Range创建
package cn.lagou.sparksql import org.apache.spark.SparkContext import org.apache.spark.sql.functions.desc import org.apache.spark.sql.{ Dataset, SparkSession} import java.lang /** * @className Create_DS_DF * @Description $description * @Author liut * @Date 2021/10/28 13:47 */ object Create_DS_DF { def main(args: Array[String]): Unit = { // 准备环境 val spark: SparkSession = SparkSession .builder() .appName("spark_sql_demo") .master("local[*]") .getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("warn") // range 创建 DS val ds: Dataset[lang.Long] = spark.range(5, 100, 3) // show 方法默认显示 20 个值 ds.orderBy(desc("id")).show() // 统计信息 ds.describe().show() // 使用 rdd 显示统计信息 println(ds.rdd.map(_.toInt).stats) // 显示分区数 println(ds.rdd.getNumPartitions) // 显示 schema 信息 ds.printSchema() // 关闭资源 spark.stop() } } +---+ | id| +---+ | 98| | 95| | 92| | 89| | 86| | 83| | 80| | 77| | 74| | 71| | 68| | 65| | 62| | 59| | 56| | 53| | 50| | 47| | 44| | 41| +---+ only showing top 20 rows +-------+------------------+ |summary| id| +-------+------------------+ | count| 32| | mean| 51.5| | stddev|28.142494558940577| | min| 5| | max| 98| +-------+------------------+ (count: 32, mean: 51.500000, stdev: 27.699278, max: 98.000000, min: 5.000000) 8 root |-- id: long (nullable = false)- 由集合创建
DS
package cn.lagou.sparksql import org.apache.spark.SparkContext import org.apache.spark.sql.functions.desc import org.apache.spark.sql.{ Dataset, SparkSession} import java.lang /** * @className Create_DS_DF * @Description $description * @Author liut * @Date 2021/10/28 13:47 */ case class OPerson(name: String, age: Int, height: Int) object Create_DS_DF { def main(args: Array[String]): Unit = { // 准备环境 val spark: SparkSession = SparkSession .builder() .appName("spark_sql_demo") .master("local[*]") .getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("warn") import spark.implicits._ val seq1 = Seq(OPerson("Tom", 22, 180), OPerson("Jackie", 29, 177)) val ds: Dataset[OPerson] = spark.createDataset(seq1) ds.printSchema() ds.show() val seq2 = Seq(("Marry", 23, 172), ("Lily", 22, 167)) val ds2: Dataset[(String, Int, Int)] = spark.createDataset(seq2) ds2.show() ds2.printSchema() // 关闭资源 spark.stop() } } root |-- name: string (nullable = true) |-- age: integer (nullable = false) |-- height: integer (nullable = false) +------+---+------+ | name|age|height| +------+---+------+ | Tom| 22| 180| |Jackie| 29| 177| +------+---+------+ +-----+---+---+ | _1| _2| _3| +-----+---+---+ |Marry| 23|172| | Lily| 22|167| +-----+---+---+ root |-- _1: string (nullable = true) |-- _2: integer (nullable = false) |-- _3: integer (nullable = false) - 由
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1534
1534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









