







欢迎来到涛涛聊AI!家人们,今天给大家带来一份超实用的指南——在腾讯云TI平台上快速部署和体验DeepSeek系列模型!不管你是初涉AI领域的小白,还是经验丰富的开发者,这篇文章都能帮你快速掌握DeepSeek模型的部署技巧,赶紧码住!
一、DeepSeek模型大揭秘
DeepSeek可是大语言模型界的“明星选手”,它由深度求索公司打造。其中,DeepSeek-V3就像一个知识渊博的“万事通”,在14.8万亿高质量token上完成预训练,手握6710亿参数,在知识问答、内容生成、智能客服等场景中表现超亮眼。DeepSeek-R1则是推理界的“高手”,基于DeepSeek-V3-Base训练而成,在数学、代码生成和逻辑推断这些复杂任务中,解题能力一流。而DeepSeek-R1-Distill是精打细算的“小机灵鬼”,用DeepSeek-R1生成的样本微调开源模型得到,参数规模小,推理成本低,在基准测试里也毫不逊色。
二、支持的模型清单如下
平台超给力,DeepSeek全系模型都安排上了!下面给大家看看具体的模型列表和推荐配置,方便大家按需选择。
| 模型名称 | 参数量 | 激活参数量 | 上下文窗口 | 推理资源推荐 |
| DeepSeek-V3 | 671B | 37B | 128K | 多机分布式部署,2个节点,单节点HCCPNV6机型 |
| DeepSeek-R1 | 671B | 37B | 128k | 多机分布式部署,2个节点,单节点HCCPNV6机型 |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | - | - | 12C44GB 1卡A10 |
| DeepSeek-R1-Distill-Qwen-7B | 7B | - | - | 12C44GB 1卡A10 |
| DeepSeek-R1-Distill-Llama-8B | 8B | - | 128K | 12C44GB 1卡A10 |
| DeepSeek-R1-Distill-Qwen-14B | 14B | - | - | 16C96G 1卡A100 |
| DeepSeek-R1-Distill-Qwen-32B | 32B | - | - | 32C192G 2卡A100 |
| DeepSeek-R1-Distill-Llama-70B | 70B | - | 128K | 164C948G 8卡A100 |
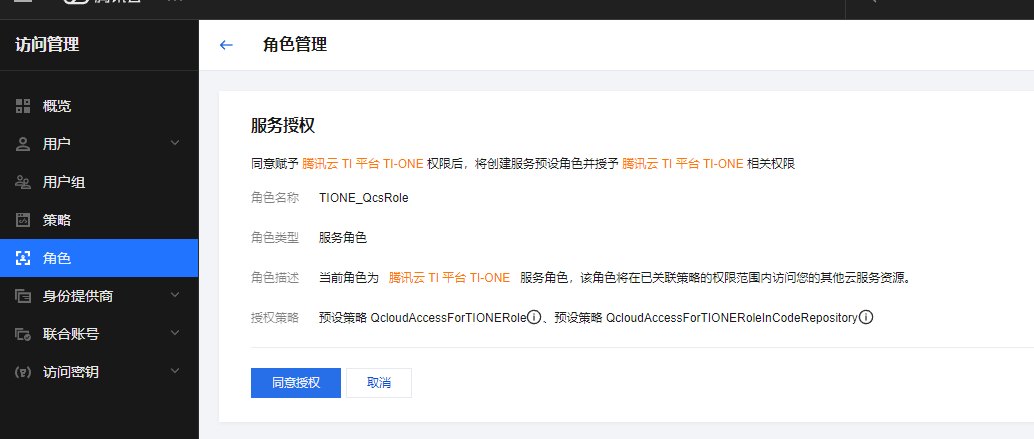
三、限时免费体验福利来袭
!平台限时开放DeepSeek-R1和DeepSeek-R1-Distill-Qwen-1.5B这两款模型的免部署在线体验。大家进入DeepSeek系列模型详情页面,切换上方Tab就能开启在线对话体验。这可是个绝佳机会,能直观感受“大杯”和“小杯”模型的性能差异,就像给模型来一场“实力大比拼”!
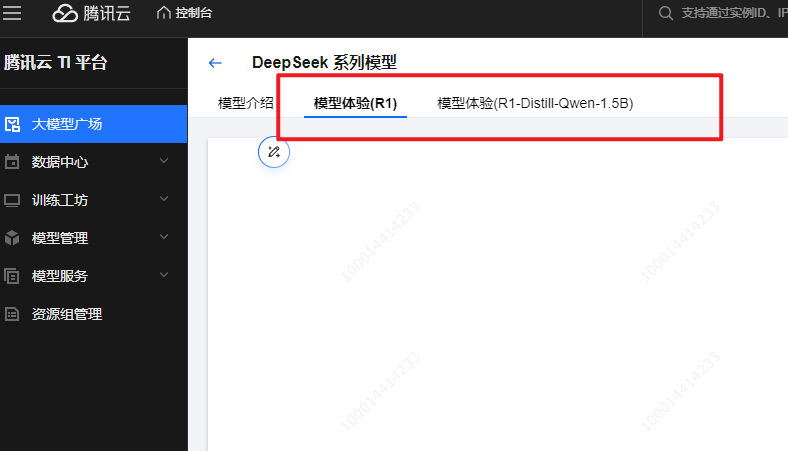
要是想体验其他模型,也别着急,
按照下面的部署实践步骤,自己动手部署就行。
注意以下的内容需要花米才能部署的呀。
四、模型部署实战教程
接下来就是大家最关心的部署环节啦!咱们以DeepSeek-R1-Distill-Qwen-1.5B模型为例,其他模型操作类似,主要就是算力资源配置有点不同。
(一)前置准备工作
模型方面,腾讯云TI平台超贴心,DeepSeek模型直接内置在大模型广场,一键就能选,就像在“模型超市”里购物一样方便!资源选择也很灵活,如果只是短期体验或者算力需求小,推荐选“从TIONE购买”的按量计费模式,即开即用,不用提前准备算力。
(二)步骤一:部署模型服务
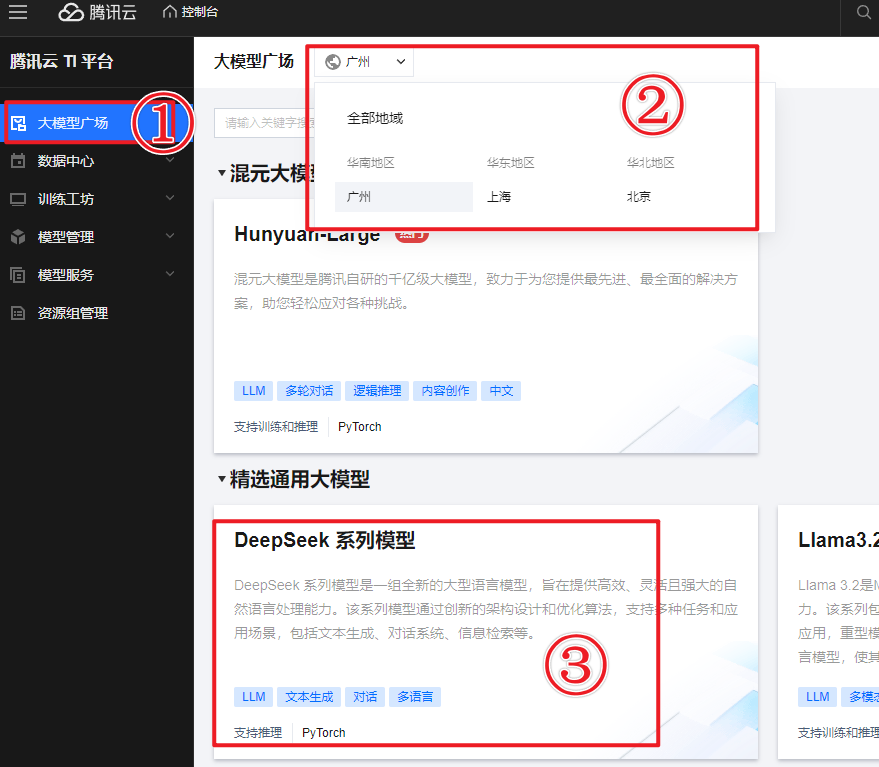
- 登录腾讯云TI平台,找到大模型广场,这里全是各种开源大模型的“宝藏卡片”。
- 点击进入“DeepSeek系列模型”卡片,先好好了解一下模型的“本领”。
- 在模型详情页,点击新建在线服务,进入配置部署参数的页面。
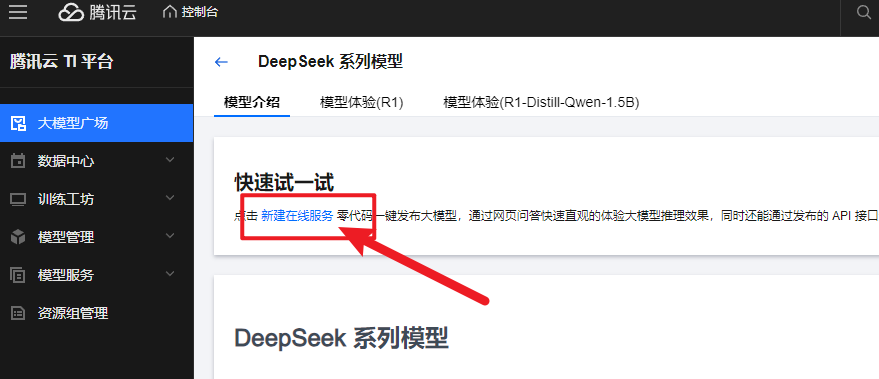
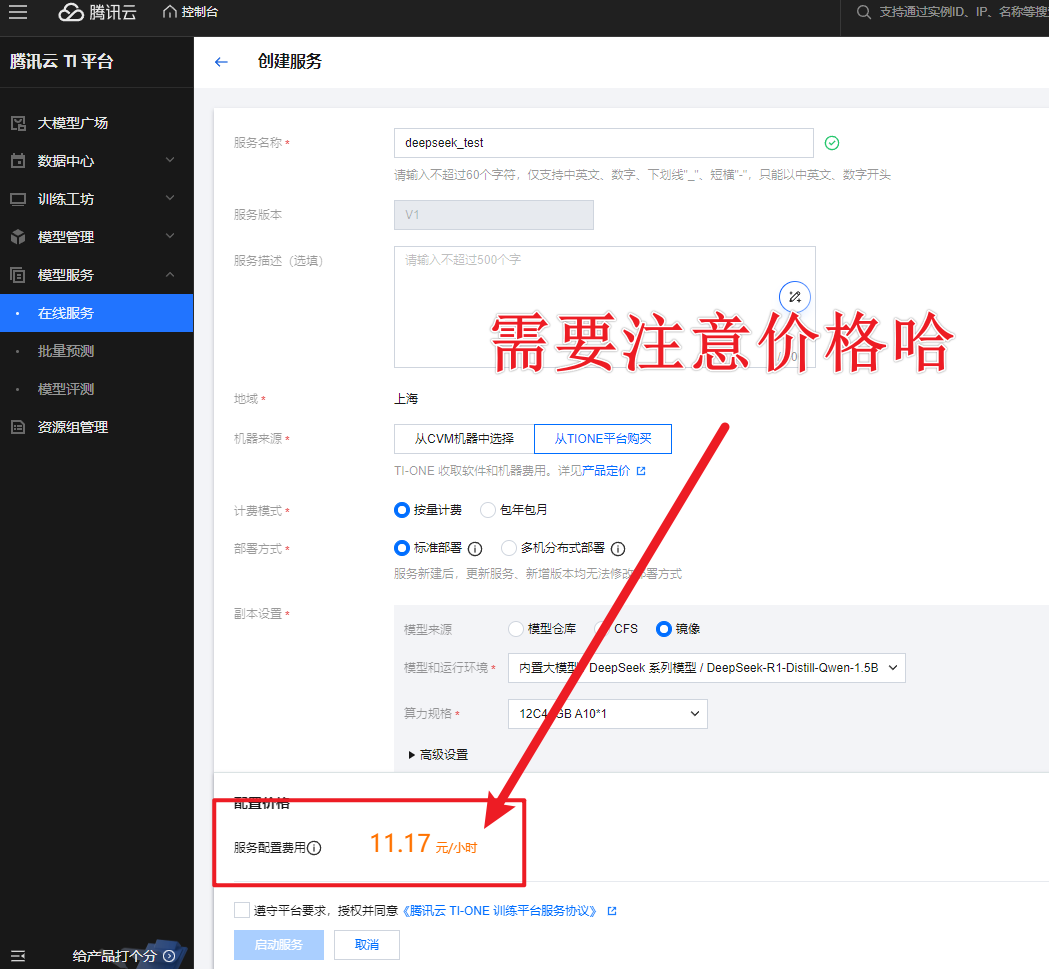
- 按照提示填写配置信息:
-
- 服务名称可以自己取,比如“demo-DeepSeek-R1-Distill-Qwen-1_5B”;
- 机器来源选“从TIONE平台购买-按量计费”(要是有自己的CVM机器,也可以选另一个);
- 部署方式选“标准部署”;
- 模型来源选“镜像”,模型和运行环境选“内置大模型/DeepSeek系列模型/DeepSeek-R1-Distill-Qwen-1.5B”,算力规格选12C44GB A10*1。
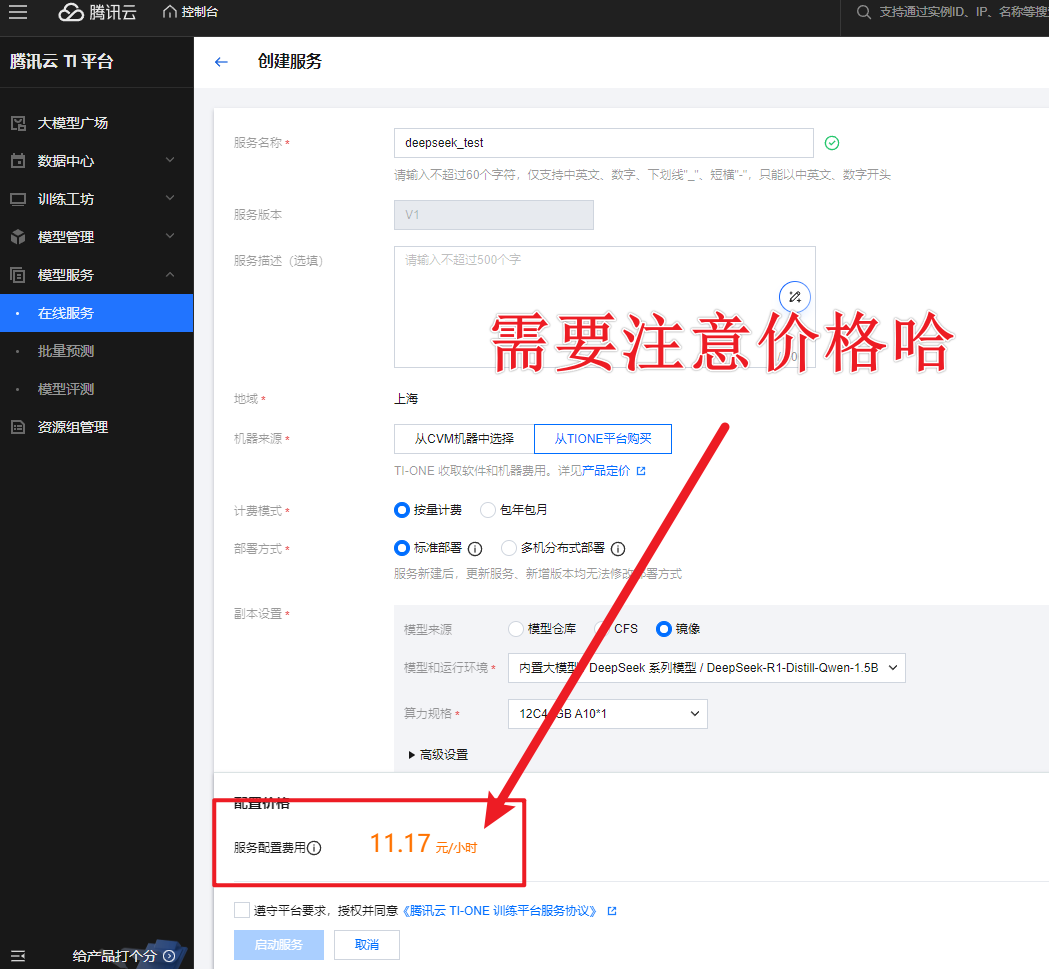
- 同意相关服务协议后,点击启动服务,就可以坐等模型部署完成啦!
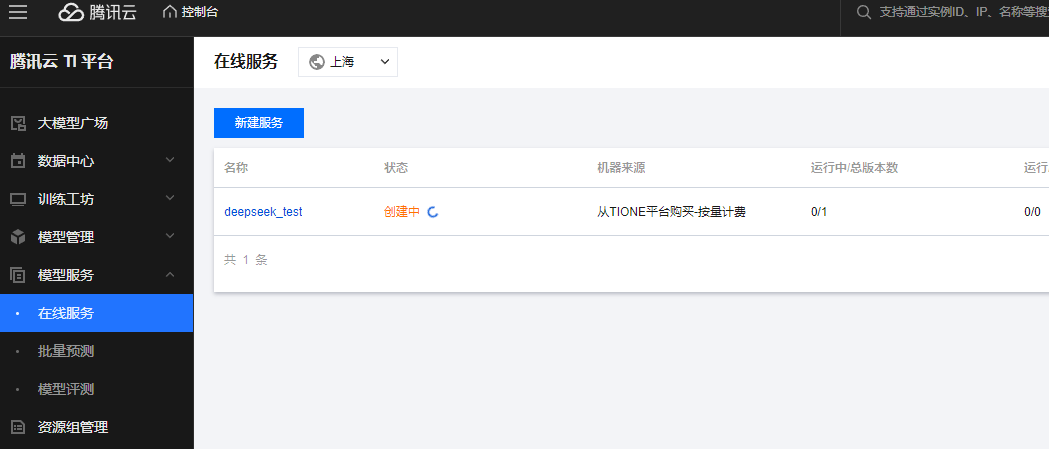
(三)步骤二:体验模型效果
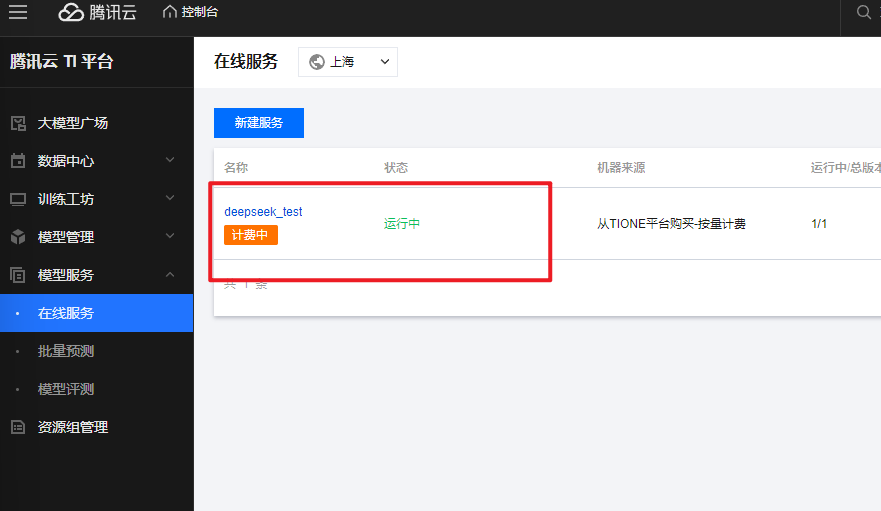
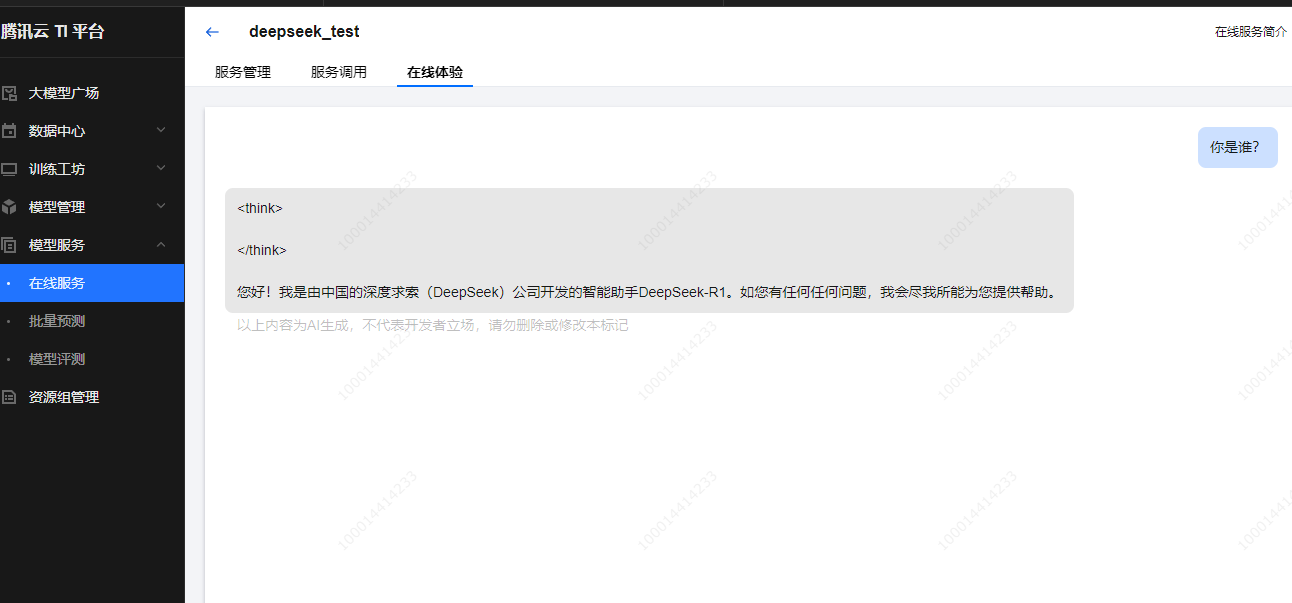
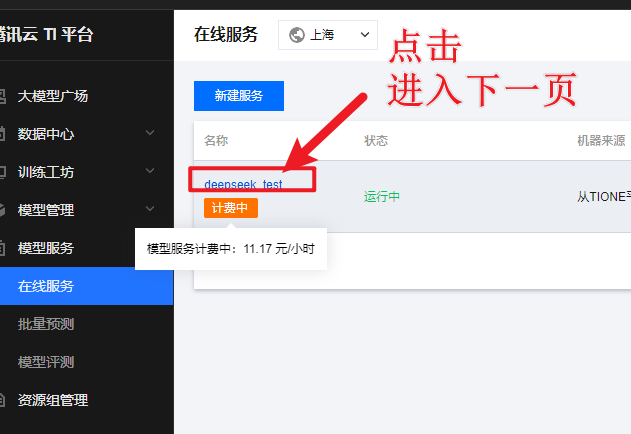
等服务部署完成,在“模型服务>在线服务”页面看到状态显示“运行中”,就可以去体验模型效果啦!DeepSeek-R1-Distill-Qwen-1.5B模型部署一般1 - 2分钟就能搞定。点击列表里的在线体验,进入体验页面,随便提个问题,比如“在我的厨房里……球在哪里?”,看看模型怎么回答,感受一下它的“聪明才智”。
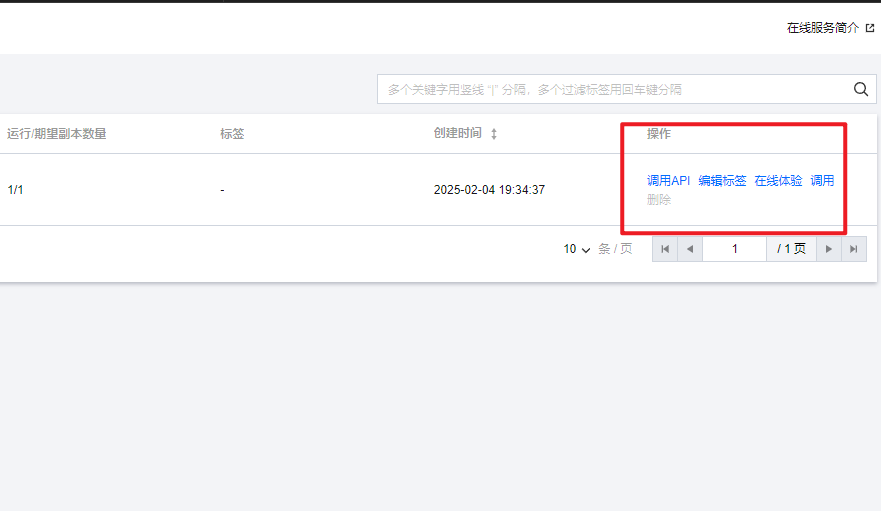
(四)步骤三:调用模型推理API
- 使用TI平台内置工具测试API调用:
-
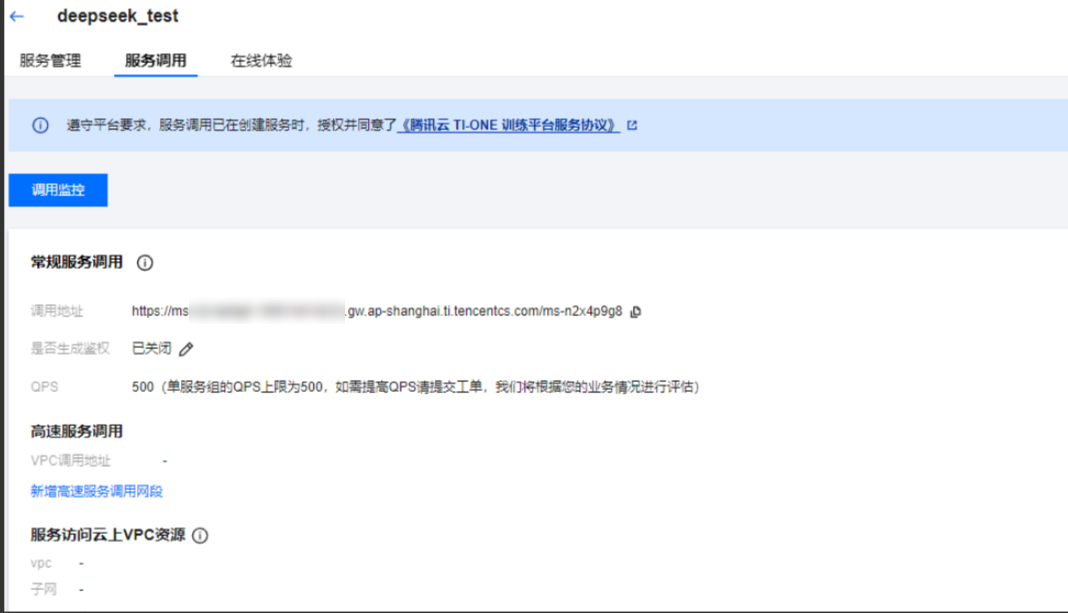
- 在“模型服务>在线服务”页面,点击部署好的服务名称,进入服务详情页,
- 找到“服务调用”Tab,
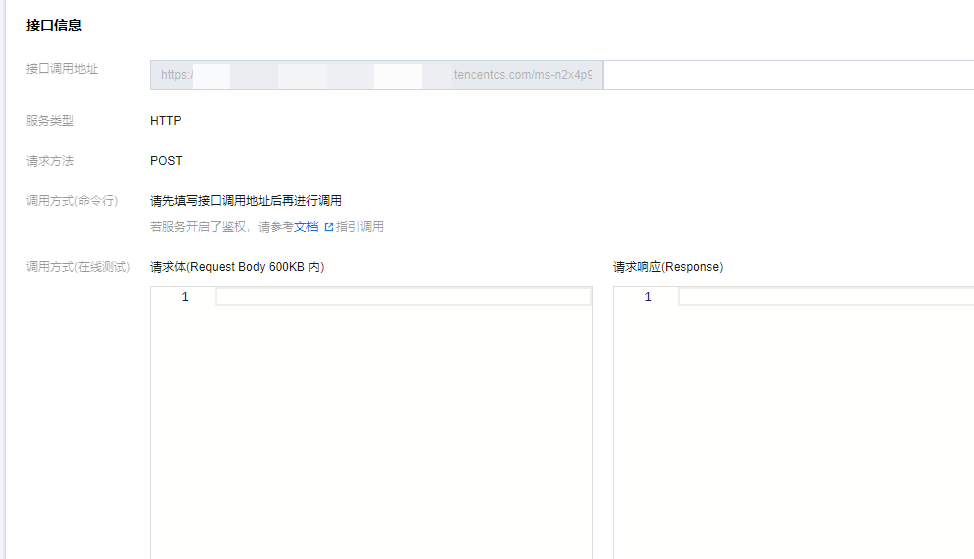
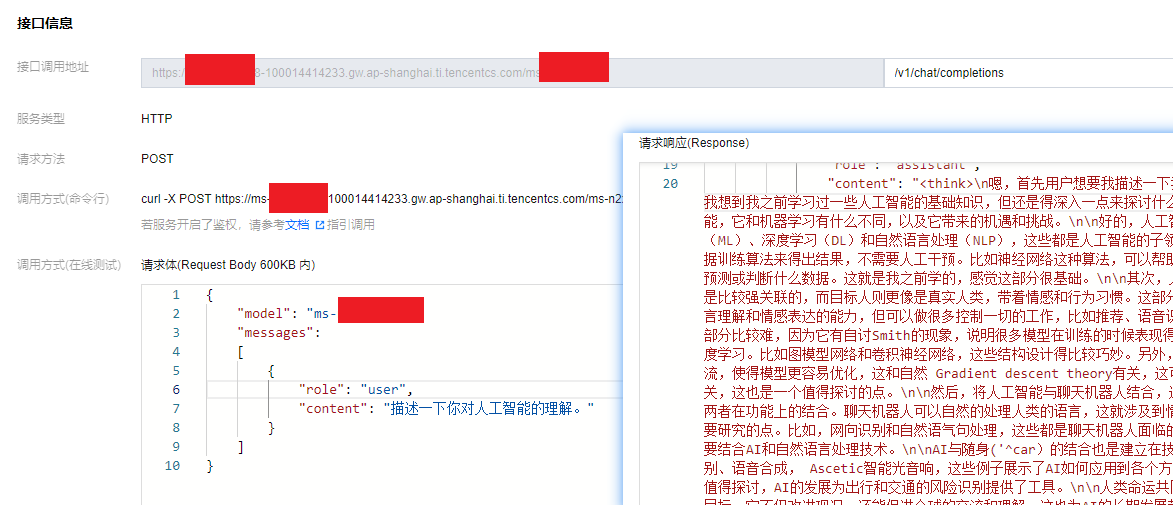
- 在底部“接口信息”版块输入接口和请求信息就能测试。接口名填/v1/chat/completions,
- 请求体按照格式填好服务组ID和问题就行,填完点击发送请求,就能看到模型的响应结果。
- 使用第三方应用开发工具调用API:以Cherry Studio为例,先在TI平台服务详情页复制调用地址,下载安装Cherry Studio后,在设置里添加提供商,选择OpenAI类型,填好相关信息后添加模型,配置好模型ID,就可以在对话页面选择模型进行聊天啦!
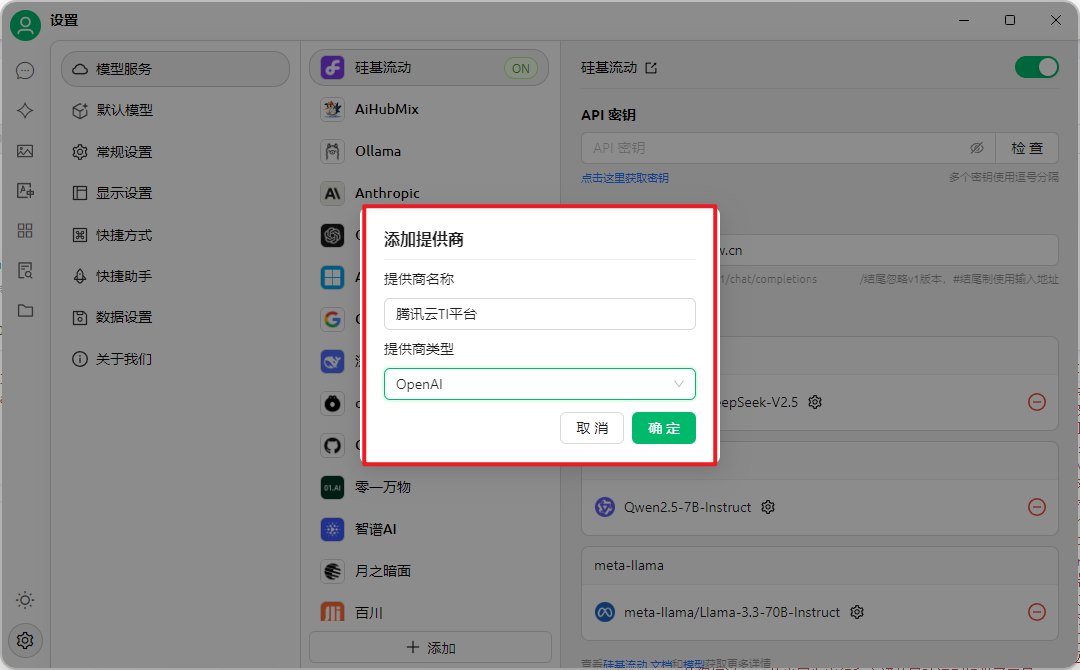
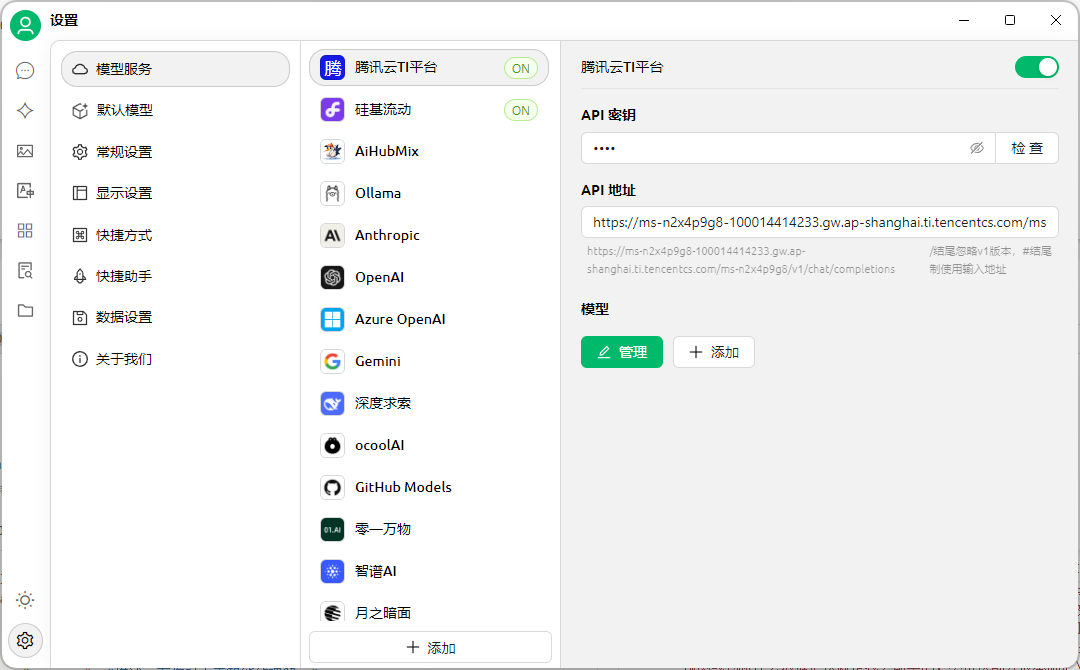
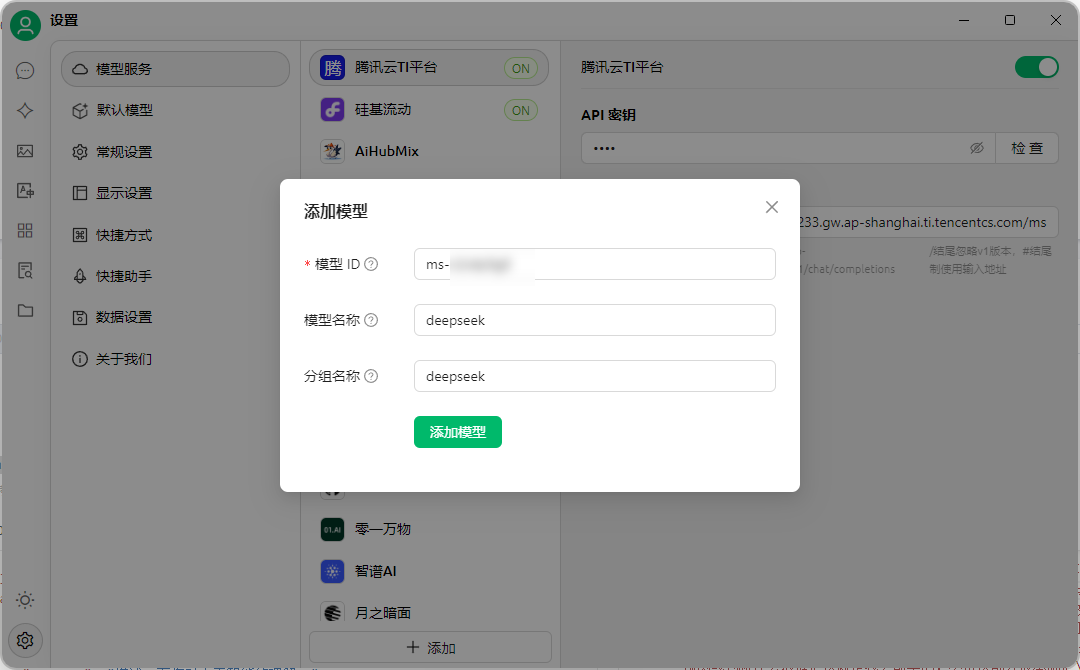
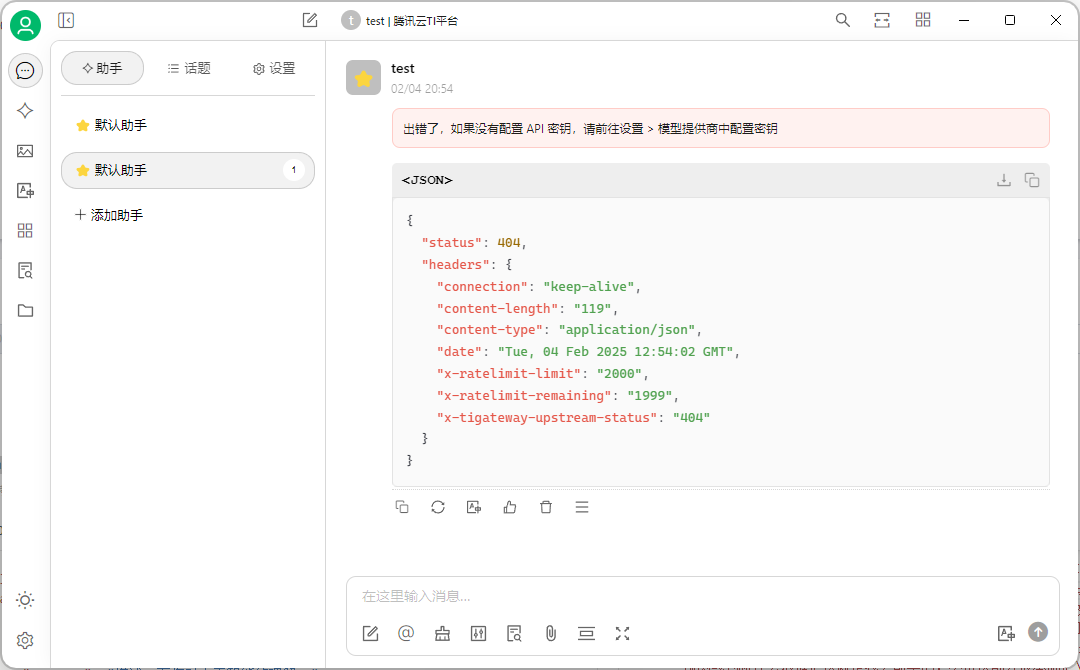
如果填写信息不对,就到出差哈。
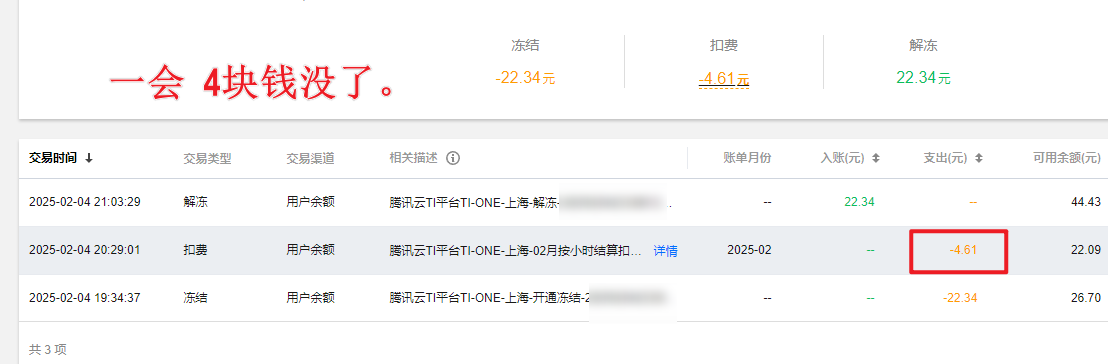
五、使用完成后一定要停止和删除,不然会持续扣费
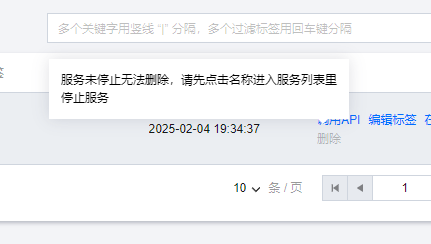
先停止
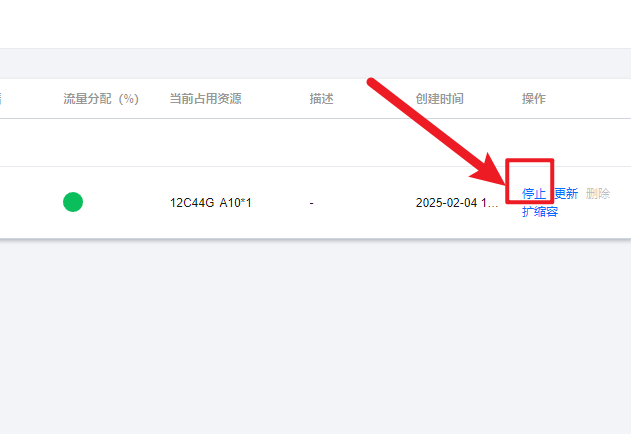
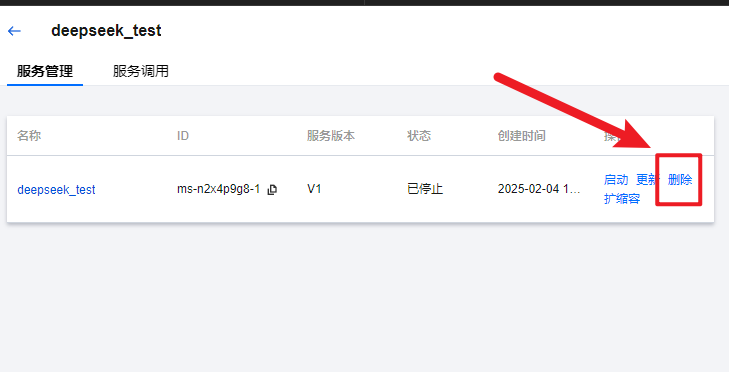
然后再删除
六、不同模型部署要点与大小模型对比
部署DeepSeek其他模型时,流程差不多,重点是根据模型选择合适的资源规格,大家可以参考大模型推理所需资源指南。在大小模型效果对比上,小模型也有优势,响应速度快、占用资源少、部署时间短,处理简单任务很合适。像DeepSeek-R1-Distill-Qwen-1.5B部署只要1 - 2分钟,DeepSeek-R1预计9 - 10分钟。
好啦,以上就是在腾讯云TI平台部署和体验DeepSeek系列模型的全部内容,大家赶紧动手试试吧!要是在过程中有问题,欢迎留言讨论。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









