







最近做得爬虫相关的work较多、就此来聊聊关于python爬虫吧!爬虫一般分为垂直爬虫和通用爬虫。
通用爬虫:比如我们常见的爬取新闻网站、各种论坛帖子、财经类信息等都是属于通用爬虫。
此类爬虫的特点是量大、简单,有规律可循。技术难点在于怎么样优雅得去适配需要提取的内容,以及翻页的逻辑。因为你不可能每一个详情页都去写一个匹配规则。
所以对于通用爬虫,我们更注重于它的框架层面上的东西。至于框架的考虑,爬虫调度逻辑。去重、翻页、解析、存储、失败重试、代理ip、数据清洗等。比较好用的框架我是推荐scrapy<Scrapy 2.6 documentation Scrapy 2.6.1 documentation>。它适合高并发,而且功能多,也支持自己扩展功能等。是一个可以快速上手的,功能全面的框架!
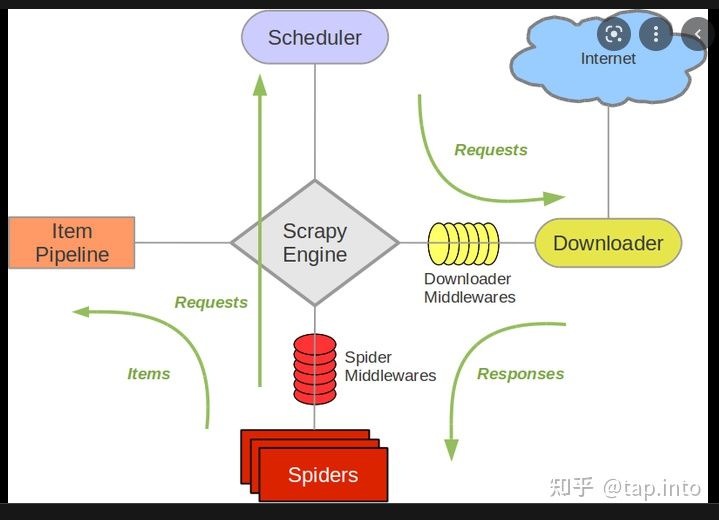
scrapy架构图
至于垂直爬虫:
一般特点是一个应用一个爬虫,其中应用指的是app、一个网站等!难点在于与反爬虫做斗
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









