







python爬虫初识
写在前面
既然能搜索到这里,那么对爬虫应该有了相当的了解和认识,这里也就不再累赘的介绍什么是爬虫?爬虫有什么用?爬虫到底合不合法?诸如此类的问题,读者自行把握。
在开始讲解学习之前,首先明确两个概念,抓取与爬取,在一定情况下,可以理解它们是同一个东西,但严格来说,它们的差别还是蛮大的,那么它们有什么区别呢?
网络抓取通常针对特定网站,并在这些站点上获取指定信息。网络抓取用于访问这些特定的页面,如果站点发生变化或者站点中的信息位置发生变化的话,则需要进行修改。
与之不同的是,网络爬取通常是以通用的方式构建的,其目标是一系列顶级域名的网站或是整个网络。爬取可以用来收集更具体的信息,不过更常见的情况是爬取网络,从许多不同的站点或页面中获取小而通用的信息,然后跟踪链接到其他页面中。
简单来说,抓取重在抓,即特定数据的提取,爬虫重在爬,即顺着链接不断的获取网络信息。
开始网络爬虫
1. urllib简易演示
要想抓取网页,我们首先需要将其下载下来,当然这里的下载并不是常规意义的下载,更准确的应该是把网页内容加载进来,以便后续操作。虽然爬虫库requests更加简单、强大,但为了更好的理解,循序渐进的学习,先使用urllib库演示。
def download(url,num_retries=2):
print('Downloading:', url)
request = urllib.request.Request(url)
try:
html = urllib.request.urlopen(request).read()
except (URLError, HTTPError, ContentTooShortError) as e:
print('Download error:', e.reason)
html = None
if num_retries > 0:
if (hasattr(e, 'code') and 500 <= e.code < 600):
# recursively retry 5xx HTTP errors
return download(url, num_retries - 1)
return html
# http://httpstat.us/500 作为测试网站
download("http://httpstat.us/500",num_retries=2)
代码说明:
代码实现对目标网址的抓取,当目标网址返回5XX状态码时,递归重试,重试次数为2次
函数定义定义两个参数:url和num_retries,分别表示访问网址和重试次数
hasattr() 函数用于判断对象是否包含对应的属性。
urllib现在最新的是urllib3,功能也更加强大。可以设置cookie,代理,发送post请求,对结果也可以指定编码读取…
实际中,页面有各种反爬机制,如动态加载、IP限制、验证码、爬虫陷阱等很多手段,显然,上面的例子并不能通过上述的各种限制帮助我们获得想要的数据,所以,让我们接着往下看。
2. 使用 requests 库
尽管我们只使用 urllib 就已经实现了一个相对高级的解析器,不过目前 Python 编写的主流爬虫一般都会使用 requests 库来管理复杂的 HTTP 请求。它可用的一些功能包括内置的编码处理、对SSL和安全的重要更新以及对POST请求、JSON、cookie和代理的简单处理。
正如requests说明文档介绍的那样,Requests是一个优雅而简单的Python HTTP库,为人类而建。废话不多说,开始吧!
1.安装
requests库是第三方库,所以必须先安装,安装代码如下:
pip install requests
2. 简单使用
requests的使用超简单,这也正是其强大之处,同时,它支持多种请求类型的访问:
# get请求
r = requests.get('https://api.github.com/events')
# post请求
r = requests.post('https://httpbin.org/post', data={'key': 'value'})
# 其他类型请求
r = requests.put('https://httpbin.org/put', data={'key': 'value'})
r = requests.delete('https://httpbin.org/delete')
r = requests.head('https://httpbin.org/get')
r = requests.options('https://httpbin.org/get')
上面介绍的都是各类请求最简单的使用方法,比如,对于post请求,data参数通常是自定类型的数据,但对于一键多值的数据,可以使用元组或者列表传递;当data是json格式时,可以直接传送json数据;甚至可以传送文件数据。
# 一键多值的传递
payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
payload_dict = {'key1': ['value1', 'value2']}
r2 = requests.post('https://httpbin.org/post', data=payload_dict)
# json参数传递
url = 'https://api.github.com/some/endpoint'
payload = {'some': 'data'}
r = requests.post(url, data=json.dumps(payload))
3. 请求头参数
请求头参数的作用其实就一个,假装自己的请求是一个正常用户的请求,防止访问被限制,说白了,就是反反爬。请求头的内容有很多,但对于大多数请求,最重要的是user-agent键值对,它告诉服务器,请求来自哪个系统(win|os|unix)以及使用什么浏览器进行的访问等。示例如下:
url = 'https://api.github.com/some/endpoint'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'}
r = requests.get(url, headers=headers)
关于请求头的获取,打开网址,F12打开开发者工具,刷新出以下界面,就可以根据下图流程,找到头信息了:
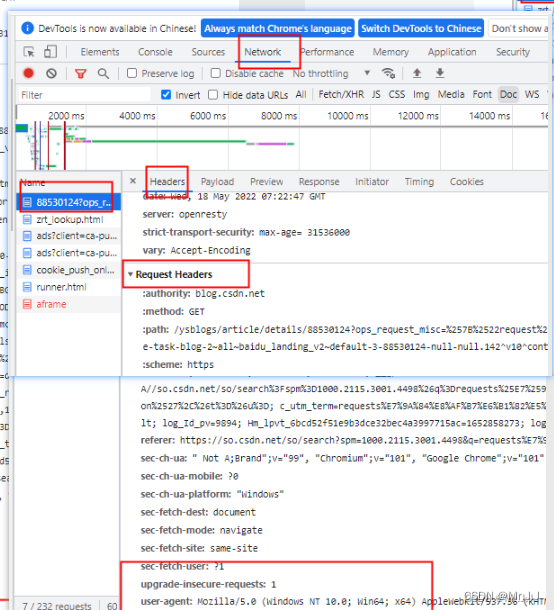
注意:所有的头信息值必须是字符串、字节串或unicode。虽然允许,但建议避免传递unicode头值。
4. Cookies参数
在讲解Cookies参数之前,首先解决下面两个问题。
什么是Cookies
cookie的中文翻译是曲奇,小甜饼的意思。cookie其实就是一些数据信息,类型为“小型文本文件”,存储于电脑上的文本文件中。
cookie有什么作用
记录一些用户信息,当用户再次访问同一个网址时,快速响应。比如用户第一次登录了csdn网站,之后再访问,就不需要登陆了,这就是cookie的作用。
知道了Cookie的作用,其实就明白了Cookies参数也是伪造真实访客手段,还是为了反反爬。其使用示例如下:
url = 'https://httpbin.org/cookies'
cookies = dict(cookies_are='working')
r = requests.get(url, cookies=cookies)
5. Timeouts参数
想象一个场景,你访问一个服务器,一直没得到响应,它是不是一直会挂起,寻求访问?当然不是,在等待一段时间后没有响应,直接返回404或者5XX错误,这就是访问超时的作用。
所以我们也应该在我们的请求中,添加该参数,使得在给定的秒数后停止等待响应,并返回一个访问超时错误提示。几乎所有的生产代码都应该在几乎所有的请求中使用这个参数。如果不这样做,会导致你的程序无限期地挂起。
requests.get('https://github.com/', timeout=0.001)
...
ConnectTimeout: HTTPSConnectionPool(host='github.com', port=443): Max retries exceeded with url: / (Caused by ConnectTimeoutError(<urllib3.connection.VerifiedHTTPSConnection object at 0x0000011D05AEA988>, 'Connection to github.com timed out. (connect timeout=0.001)'))
6. Proxies参数
如果你需要使用代理,你可以用任何请求方法的proxies参数配置单个请求。
import requests
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
requests.get('http://example.org', proxies=proxies)
7. Response 的查看
既然有了请求,那必然有响应,而响应的查看与提取也是我们获取数据的重点。
回复状态码:status_code
状态码有很多种,但与我们来说,200是指访问内容得到正确回复,4XX是指客户端错误,5XX是指服务器错误,所以爬取获得回复之后,首先通过状态码判断是否正确。
r = requests.get('https://httpbin.org/get')
r.status_code
200
当然如果我们做了一个错误的请求(4XX客户端错误或5XX服务器错误响应),我们可以用Response.raise_for_status()来手动报错。该方法对200状态码返回None。
bad_r = requests.get('https://httpbin.org/status/404')
bad_r.raise_for_status()
HTTPError: 404 Client Error: NOT FOUND for url: https://httpbin.org/status/404
回复编码:r.encoding
从HTTP header中猜测的响应内容编码方式,但很多时候,猜测的并不准确,所以为了正确获取内容,需要指定编码格式,指定语法也是这个,具体请看下面的示例:
# 猜测
r = requests.get('https://www.baidu.com/')
r.encoding
'ISO-8859-1'
# 指定
r = requests.get('https://www.baidu.com/')
r.encoding = "utf8"
r.encoding
'utf8'
回复内容:
响应内容的返回有两种方法,分别是text 和content 方法,不同在于text 返回响应内容的字符串形式,即url对应的页面内容,而content 返回响应内容的二进制形式。
很多时候,text 方法获取内容会因为编码格式没猜测对而无法读取,所以应该先指定编码格式,再使用text方法获取内容(比如百度首页)。
从内容分析编码:r.apparent_encoding
当我们使用用猜测的编码并不能读取响应,且我们不知道该使用什么编码时,使用apparent_encoding方法,可以根据内容,返回最适合的编码格式。
r = requests.get('https://www.baidu.com/')
r.apparent_encoding
'utf-8'















 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









