







wordCount
/**
* Following sample is adopted from original wordcount sample from
* http://wiki.apache.org/hadoop/WordCount.
*/
package chapter1;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
* <p>The word count sample counts the number of word occurrences within a set of input documents
* using MapReduce. The code has three parts: mapper, reducer, and the main program.</p>
* @author Srinath Perera (srinath@wso2.com)
*/
public class WordCount {
/**
* <p>
* The mapper extends from the org.apache.hadoop.mapreduce.Mapper interface. When Hadoop runs,
* it receives each new line in the input files as an input to the mapper. The �map� function
* tokenize the line, and for each token (word) emits (word,1) as the output. </p>
*/
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
//new一个IntWritable存储数值
private final static IntWritable one = new IntWritable(1);
// new一个Text 存储单词作为key
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
/**
* <p>Reduce function receives all the values that has the same key as the input, and it output the key
* and the number of occurrences of the key as the output.</p>
*/
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
/**
* <p> As input this program takes any text file. Create a folder called input in HDFS (or in local directory if you are running this locally)
* <ol>
* <li>Option1: You can compile the sample by ant from sample directory. To do this, you need to have Apache Ant installed in your system.
* Otherwise, you can use the complied jar included with the source code. hange directory to HADOOP_HOME, and copy the hadoop-cookbook.jar to the HADOOP_HOME.
* Then run the command > bin/hadoop jar hadoop-cookbook.jar chapter1.WordCount input output.</li>
* <li>As an optional step, copy the �input� directory to the top level of the IDE based project (eclipse project) that you created for samples. Now you can run
* the WordCount class directly from your IDE passing �input output� as arguments. This will run the sample same as before. Running MapReduce Jobs from IDE in this manner is very useful
* for debugging your MapReduce Jobs. </li>
* </ol>
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
//Uncomment this to
//job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}build后运行
hadoop jar hadoop-cookbook-chapter1.jar chapter1.WordCount hdfs://localhost:9000/test/word.txt hdfs://localhost:9000/test/output2结果
[clz@localhost lib]$ hadoop fs -cat /test/output2/part*
"But 1
"I 1
"It 1
"My 2
"On 1
"There 1
"Today, 1
"We 1
"When 1
"a 1
"in 1
"one 1
'this 1
- 1
110 2
130 1
131 4工作原理
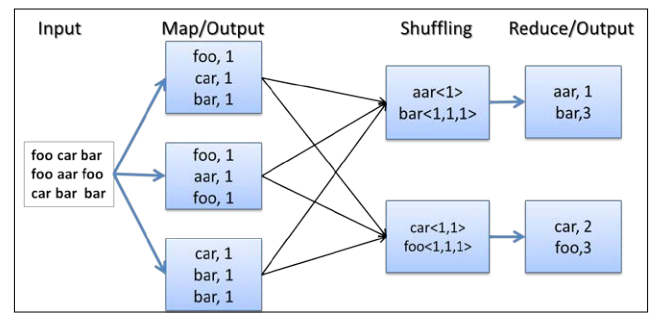
1. Hadoop读取输入,以新行(\n)所谓分隔符,将line nummber以及每行数据作为输入
2. map函数对每行进行分词,并生成键值对(word,1)
3. hadoop收集所有键值对,按照key即(word)排序,将所有values即(1)收集到一起:
word<1,1,...> 然后将(key,values)传递给ruduce进行操作
4. reduce对values加和输出word<sum(values)>
5. 写入输出路径add a combiner step
在map阶段每个map输出的key-value会有许多key是相同的,如果直接进入shuffle阶段会造成不必要的资源浪费,在将map结果持久化到磁盘进行shuffle过程前可以加入一个combiner 在map阶段先将每个map中相同key的value执行操作,一般combiner与reduce
的操作相同,在这里的wordcount是sum操作。
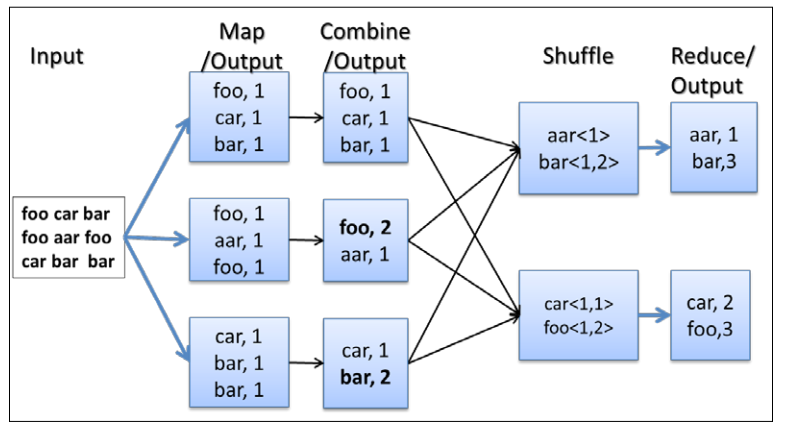
attention
将reduce函数作为combiner时,只有在reduce函数的输入和输出是一样的情况下才可以使用。当然,也可以写一个专用的reducer作为combiner,此时combiner的输入和输出key-value必须与mapper的输出key-value相同。在分布式环境下combiner能够大大提升效率。
HDFS
hdfs是块结构的分布式系统,它支持在多节点存储大容量的数据和高通量的访问。高容错。hdfs有namenode和datanode,namennode存储的是元数据信息,datanode存储的是实际数据。hdfs的快数据是粗粒度的并在大规模流数据读取表现更好。
#启动
$ $HADOOP_HOME/sbin/start-dfs.sh
#信息
$ $HADOOP_HOME/bin/hadoop dfsadmin -report
#stop
$ $HADOOP_HOME/sbin/stop-dfs.shHadoop v2 YARN
YARN包含:
ResourceManager: masternode 控制所有集群的资源
NodeManager:slavenodes 控制单个节点的资源
MR app 可以在YARN上运行, 通过 ApplicationMaster将每个作业与资源容器resource contianers协调来运行map与reduce任务。
some command line
$ hdfs dfs -ls
$ hdfs dfs -mkdir test
$ hdfs dfs -copyFromLocal README.txt test
$ hdfs dfs –copyToLocal \
test/README.txt README-NEW.txt
# help
hdfs dfs -help
hdfs dfs -help du当输入command line后HDFS客户端会从NAMENODE得到configurations信息即
HADOOP_HOME/etc/hadoop/conf 。当然也可以强制指定一个NAMENODE的位置
例如,
hdfs://bar.foo.com:9000/data 这样会指定使用bar.foo.com的namenode
How it works
当提交一个作业, YARN会安排ApplicationMaster协调并执行计算。AppMaster从ResourceManager获取必要的资源, 并使用从resource请求到的containers进行MR计算
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









