






相信对深度学习工作比较熟悉的小伙伴一定对 Pytorch 框架不陌生,开源的深度学习框架,适合研究和开发神经网络模型。
不过只要涉及人工智能的开发,就一定和算力脱不了干系。CUDA 允许开发者利用 NVIDIA GPU 进行通用计算任务,广泛应用于 Pytorch 和 Tensorflow 等深度学习框架的 GPU 加速中。近些年越来越有一种趋势,想玩 AI,你就得用 CUDA,就得买英伟达的 GPU。毕竟一直还没有什么能和 CUDA 掰掰手腕的“同行”出现,英伟达也就基本实现了行业垄断,网上戏称 NVIDIA GPU 提供算力,就犹如AI时代的原油,只要一句话断供,大企业们至少有一半要地震。

不过近日,Pytorch 开发团队官方发文,他们要实现「无 CUDA 计算」,100%使用 OpenAI 的 Triton 语言。
在博客中,开发团队就讨论了使用 Meta 的 Llama3-8B 和 IBM 的 Granite-8B Code 等流行 LLM 模型实现 FP16 推断的方法,其中所有计算都是使用 Triton 语言进行的。
开发团队说到:
为什么要探索使用 100% Triton?Triton 提供了一条途径,使 LLM 可以在不同类型的 GPU(英伟达™(NVIDIA®)、AMD™(AMD®)以及未来的英特尔™(Intel®)和其他基于 GPU 的加速器)上运行。它还在 Python 中为 GPU 编程提供了一个更高的抽象层,使我们能够比使用供应商特定的 API 更快地编写高性能内核。
团队从生成单个 token 的时间进行比较,对于使用基于 Triton 内核的模型,Pytorch 在 Nvidia H100 上将 Llama 和 Granite 的性能提高到 CUDA 内核主导工作流的 0.76-0.78 倍,在 Nvidia A100 上提高到 0.62-0.82 倍。
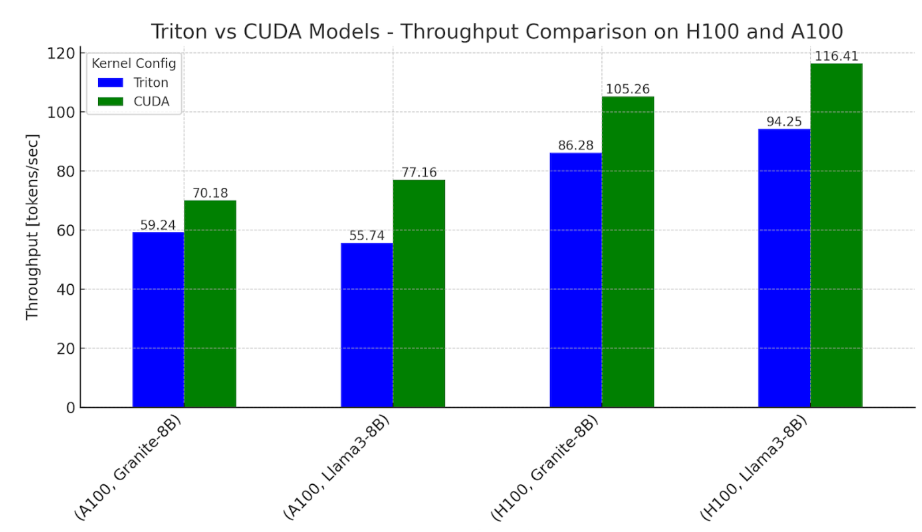
这次 Pytorch 开发团队的官宣,是否会对英伟达的统治地位造成威胁?还是说,Triton 与 CUDA 之间的差距仍是天堑,无法在短期内得到大规模应用呢?让我们拭目以待。
原文链接:
https://pytorch.org/blog/cuda-free-inference-for-llms/















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









