







简单介绍
在进行数据分析时,经常需要按照一定条件创建新的数据列,然后进行一步一步分析,常用的有四种新增数据列
1.直接赋值
2.df.apply
3.df.assign
4.按条件选择分组分别赋值
读取csv数据到dataFrame
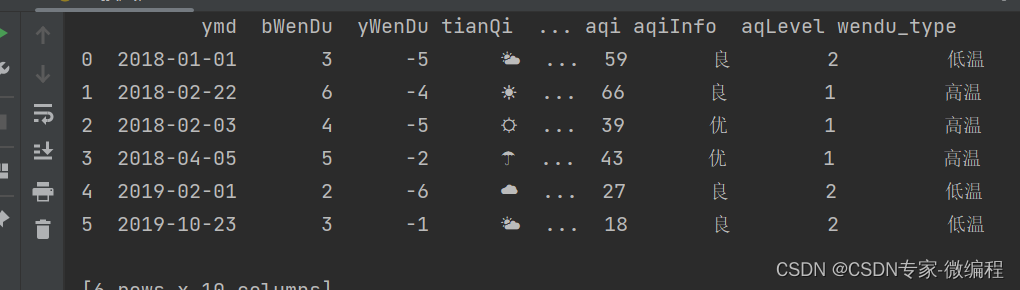
数据如下
ymd,bWenDu,yWenDu,tianQi,fengXiang,fengJi,aqi,aqiInfo,aqLevel
2018-01-01,3°C,-5°C,🌤,东北风,1-2级,59,良,2
2018-02-22,6°C,-4°C,☀,西南风,2-3级,66,良,1
2018-02-03,4°C,-5°C,☼,西风,5-6级,39,优,1
2018-04-05,5°C,-2°C,☂,北风,1-2级,43,优,1
2019-02-01,2°C,-6°C,☁,南风,1-2级,27,良,2
2019-10-23,3°C,-1°C,🌤,东风,1-2级,18,良,2
读取代码
import pandas as pd
fpath = "../data/tianqi.csv"
df = pd.read_csv(fpath)
print(df.head())
直接赋值方法
案例:计算温差
# 处理数据,先将温度后缀去掉,变成数字类型
df.loc[:, "bWenDu"] = df["bWenDu"].str.replace("°C", "").astype('int32')
df.loc[:, "yWenDu"] = df["yWenDu"].str.replace("°C", "").astype('int32')
# 计算温差
# df["bWenDu"] 其实是一个Series,后面的减法返回的也是一个Series
# df["wencha"] = df["bWenDu"] - df['yWenDu']
df.loc[:,"wencha"] = df["bWenDu"] - df['yWenDu']
print(df)

使用df.apply方法
案例:添加一列温度类型
1.如果最高温度大于3度就是高温
2.低于-2度就是低温
3.否则就是常温
代码如下
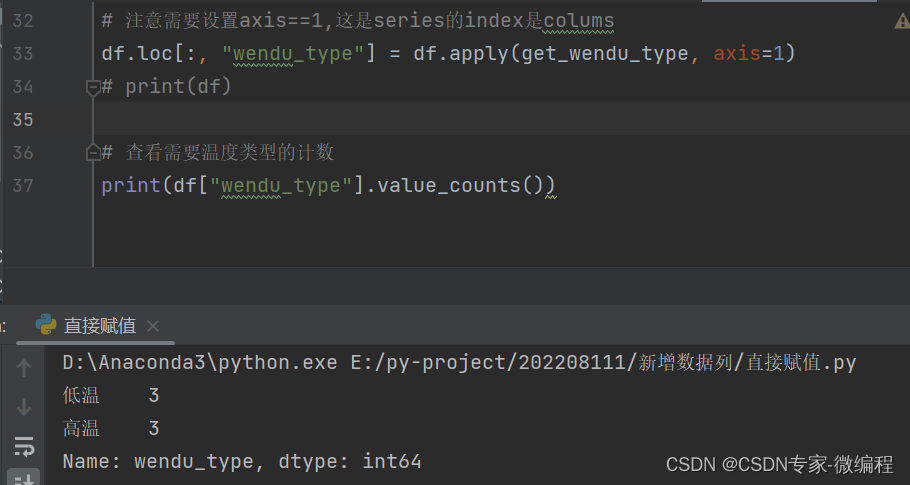
def get_wendu_type(x):
if x["bWenDu"] > 3:
return "高温"
if x["yWenDu"] > -10:
return "低温"
return "常温"
# 注意需要设置axis==1,这是series的index是colums
df.loc[:, "wendu_type"] = df.apply(get_wendu_type, axis=1)
print(df)
使用df.assign方法
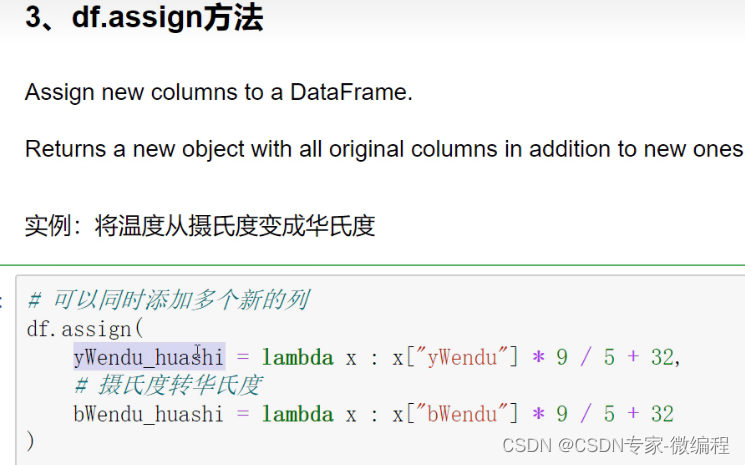
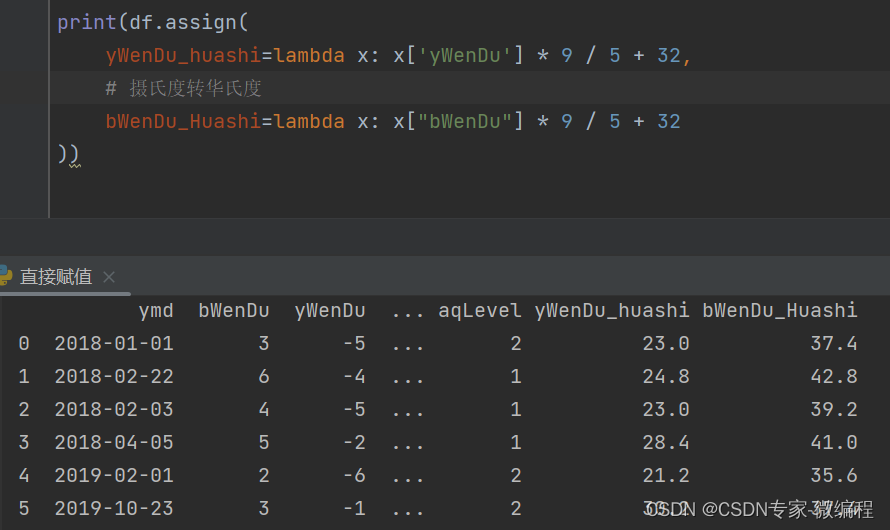
df.assign(
yWenDu_huashi=lambda x: x['yWenDu'] * 9 / 5 + 32,
# 摄氏度转华氏度
bWenDu_Huashi=lambda x: x["bWenDu"] * 9 / 5 + 32
)
print(df.head())
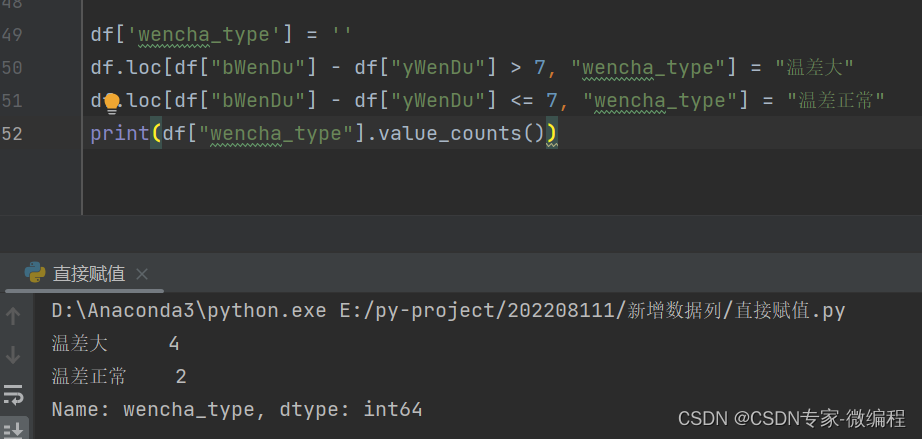
按条件选择分组分别赋值

df['wencha_type'] = ''
df.loc[df["bWenDu"] - df["yWenDu"] > 7, "wencha_type"] = "温差大"
df.loc[df["bWenDu"] - df["yWenDu"] <= 7, "wencha_type"] = "温差正常"
print(df["wencha_type"].value_counts())















 1937
1937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









