







在看基本例子时候我就迷糊了
select *
from your_table
start with parent_id = :your_parent_id --这里替换为你的起始节点条件
connect by prior child_id = parent_id;
让我们解释一下这个查询:
START WITH parent_id = :your_parent_id:这个子句指定了起始节点的条件。:your_parent_id 是你要查询的起始节点的值。
CONNECT BY PRIOR child_id = parent_id:这个子句建立了父子节点之间的连接关系。它告诉数据库如何递归地沿着父子关系遍历数据。在这个例子中,它指定了子节点的 child_id 等于父节点的 parent_id。
看完gtp的解释更迷糊了
实践是检验真理的唯一标准
表结构
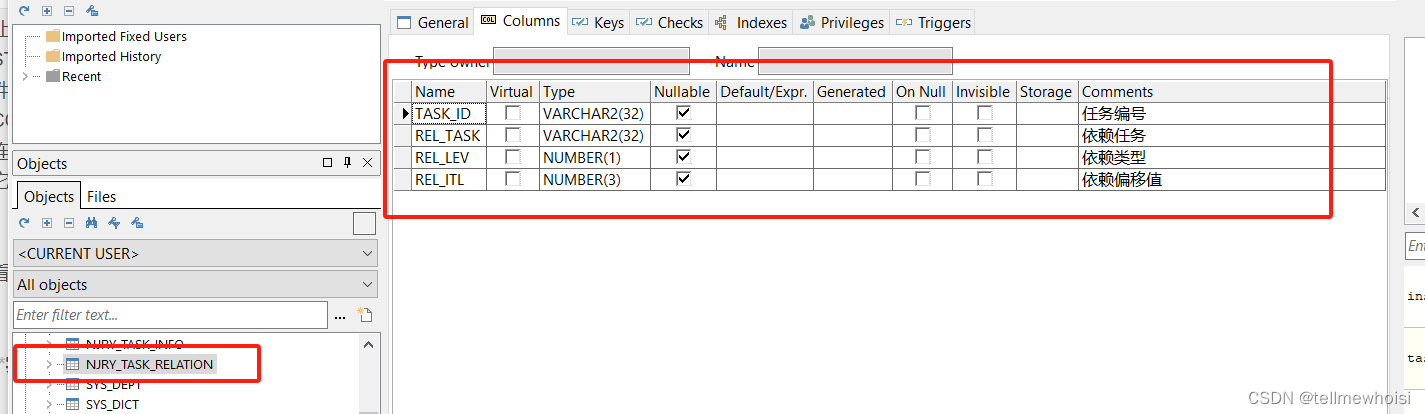
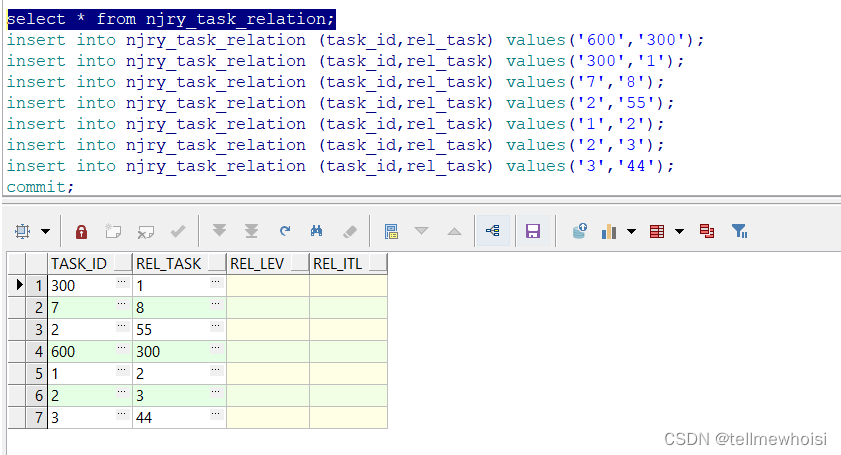
插入一些数据测试
insert into njry_task_relation (task_id,rel_task) values('600','300');
insert into njry_task_relation (task_id,rel_task) values('300','1');
insert into njry_task_relation (task_id,rel_task) values('7','8');
insert into njry_task_relation (task_id,rel_task) values('2','55');
insert into njry_task_relation (task_id,rel_task) values('1','2');
insert into njry_task_relation (task_id,rel_task) values('2','3');
insert into njry_task_relation (task_id,rel_task) values('3','44');
commit;
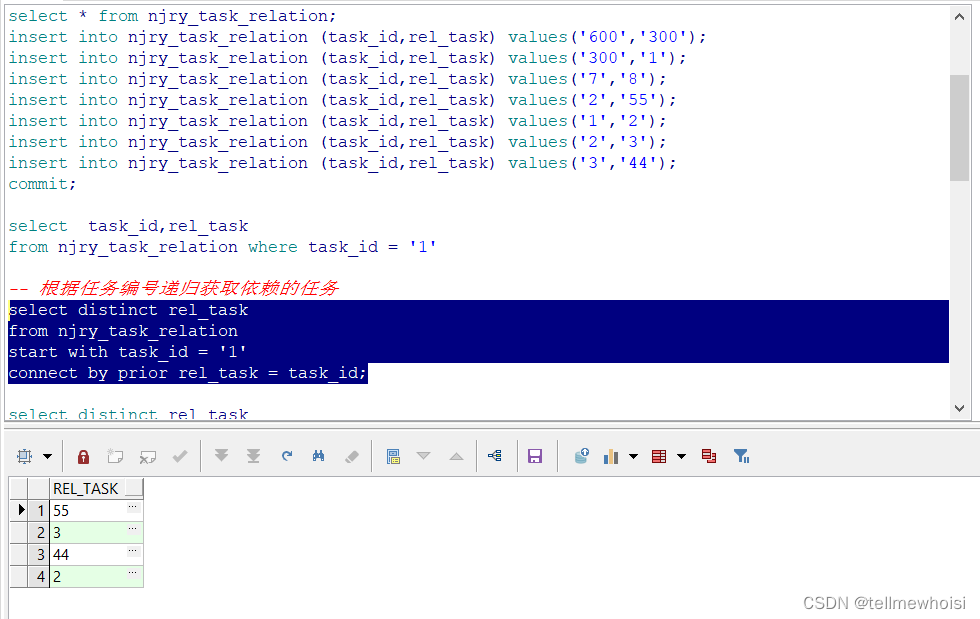
结果
递归获取任务编号是1依赖的任务
select distinct rel_task
from njry_task_relation
start with task_id = '1'
connect by prior rel_task = task_id;
查询结果
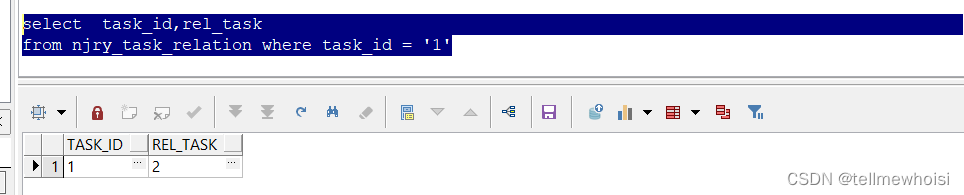
逐步解析
先初始化执行
select task_id,rel_task
from njry_task_relation where task_id = '1'
关键是
connect by prior rel_task = task_id;
个人理解就是上一句sql的执行结果里面的rel_task的值作为下一轮循环的task_id
select task_id,rel_task
from njry_task_relation where task_id = '2'
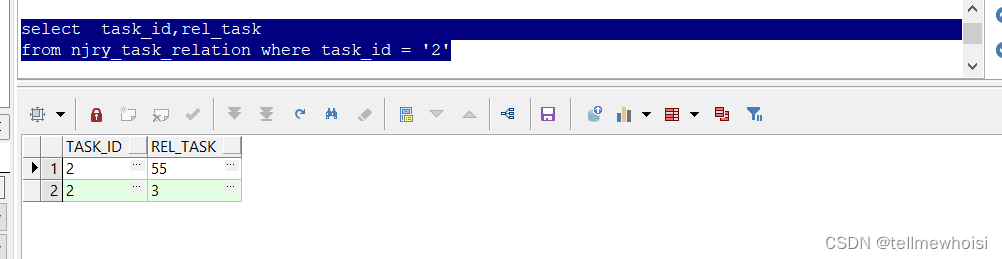
select task_id,rel_task
from njry_task_relation where task_id = '55'
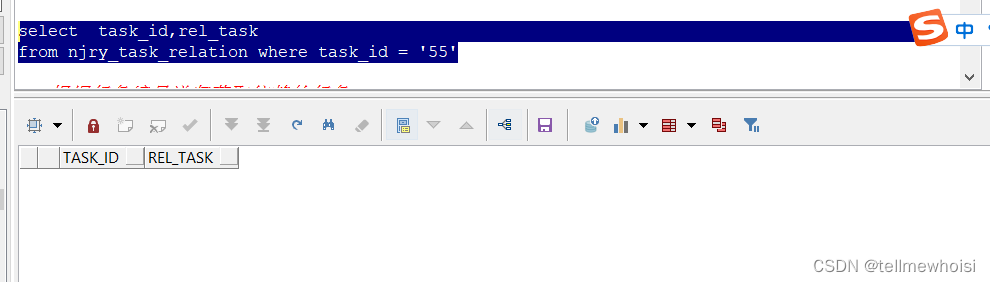
select task_id,rel_task
from njry_task_relation where task_id = '3'
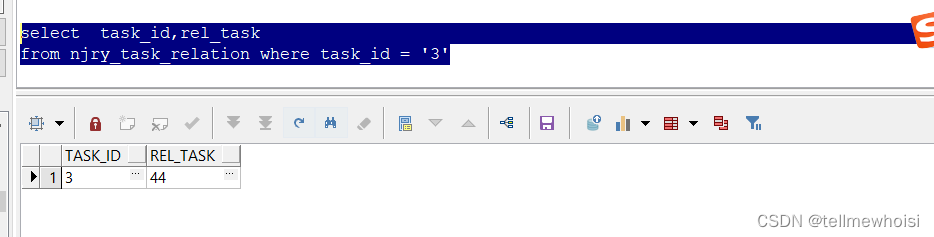
最后执行(没有结果结束递归)
select task_id,rel_task
from njry_task_relation where task_id = '44'
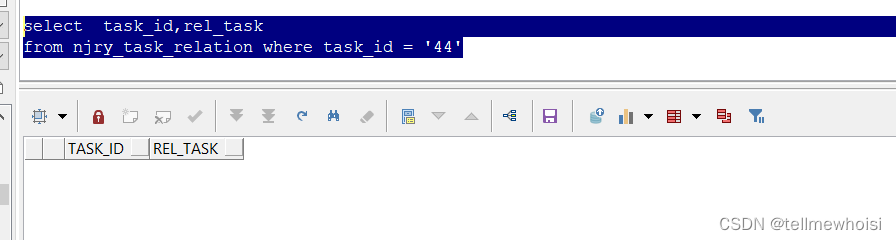
重点就是我想知道如果connect by prior 后面赋值换个位置
select distinct rel_task
from njry_task_relation
start with task_id = '1'
connect by prior task_id = rel_task;
那执行结果是啥?
当第一次初始化时候
select task_id,rel_task
from njry_task_relation where task_id = '1'
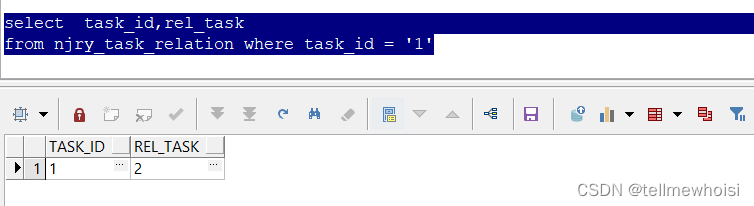
关键是
connect by prior task_id = rel_task;
我还是个人理解上一句的sql执行结果中的task_id 赋值给rel_task 这里下次循环条件也变了(纯属猜测,请大佬评论指正)
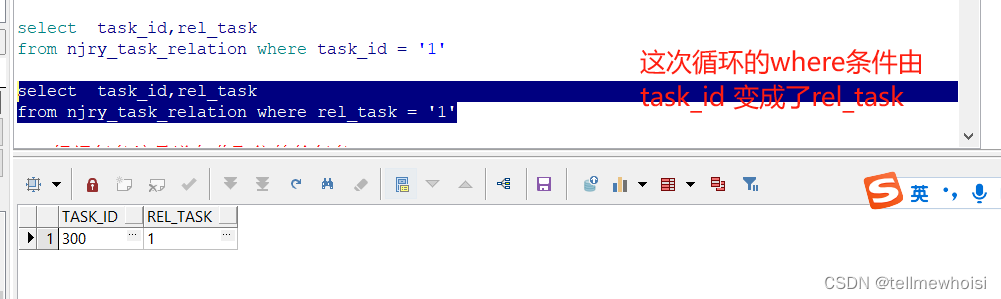
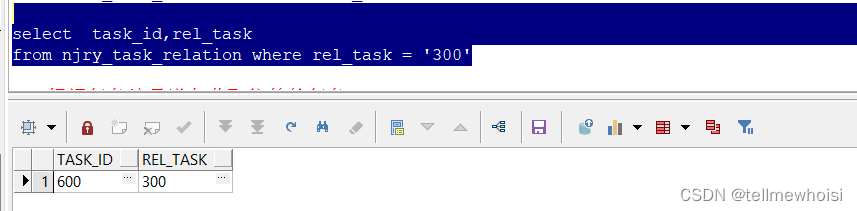
最后执行(没有结果结束递归)
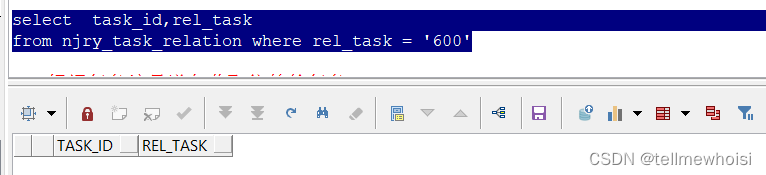















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









