







numpy可以处理数值型数据。pandas可以处理其他的数据类型。pandas对数值类型处理时,也是调用numpy。
官方文档
pandas常用数据类型
Series 一维带标签的数组
DataFrame二维,Series容器
创建数组
通过Series与列表创建一维数组
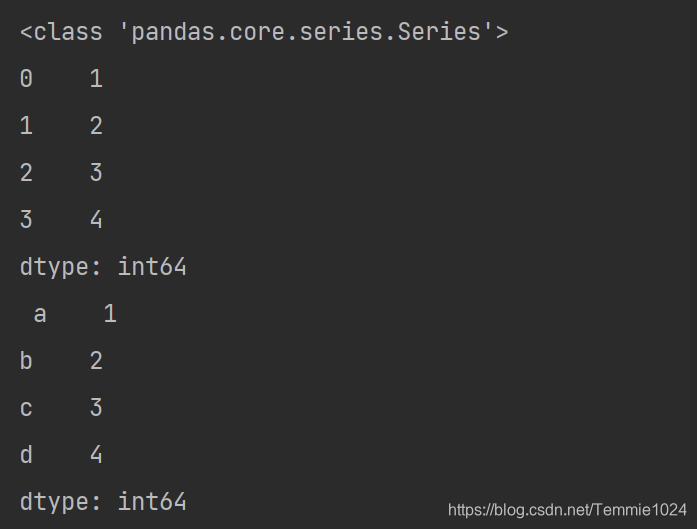
import pandas
a=pandas.Series([1,2,3,4])#默认第一列索引0到n-1
b=pandas.Series([1,2,3,4],index=['a','b','c','d'])#索引设置为index中的内容
print(type(a))
print(a,'\n',b)
结果里第一列就是标签
通过Series与字典创建一维数组
import pandas
b={'name':'temmie','age':20,'type':'dog'}
a=pandas.Series(b)#使用字典创建
print(a)
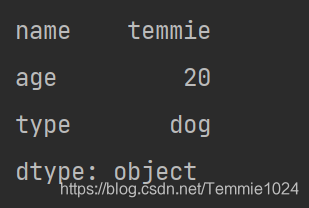
你看到了每一次输出,后面都有类型,这个语句也可以进行numpy一样的类型赋予和类型修改,语句是一样的
Series的切片与索引
索引
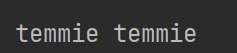
import pandas
b={'name':'temmie','age':20,'type':'dog'}
a=pandas.Series(b)#使用字典创建
print(a['name'],a[0])#使用索引或直接输入第几行
import pandas
b={'name':'temmie','age':20,'type':'dog'}
a=pandas.Series(b)#使用字典创建
print(a[['name','type']],'\n','********')#使用索引取不连续的内容
print(a[[0,2]],'\n','********')
print(a[:2],'\n','********')#取前两个
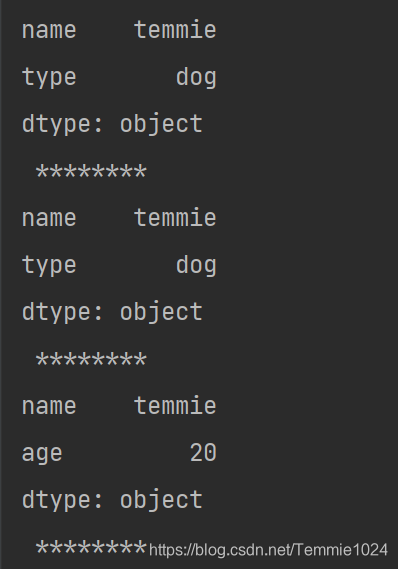
如果索引的内容没有对应的,会返回nan
布尔索引同numpy中的方式,a[a>4]即取内容大于4的部分。
取数组的索引 a.index可以取出a数组索引。
取数组的值 a.values可以取出a数组的内容。
通过DataFrame与列表创建多维数组
内容写入方法与numpy相同
import pandas
a=pandas.DataFrame([[1,2,3,4],[2,3,4,5],[3,4,5,6]])
print(a)

注意,第一列 (index行索引)axis=0与第一行(columns列索引)axis=1,内容时里面的块。
你也可以指定索引内容。
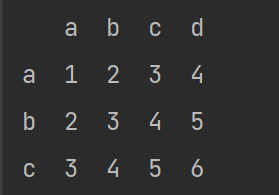
import pandas
a=pandas.DataFrame([[1,2,3,4],[2,3,4,5],[3,4,5,6]],index=list('abc'),columns=list('abcd'))
print(a)
通过DataFrame与字典创建多维数组
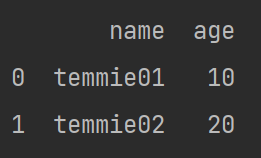
import pandas
b={'name':['temmie01','temmie02'],'age':[10,20]}
a=pandas.DataFrame(b)
print(a)
b也可以写作:
b=[{'name':'temmie01','age':10},{'name':'temmie02','age':20}]
如果数值缺失,缺的地方会自动用nan补全。
DataFrame的索引
前面已经说了DataFrame是Series的容器,也就是说它可以拆成Series在单独在一列中索引。方括号写数字是行操作,写字符串是列操作。
import pandas
b={'name':['temmie01','temmie02'],'age':[10,20],'type':['dog','dog'],'num':[122,133]}
a=pandas.DataFrame(b)
print(a['name'][0])

a.sort_values按照某一列进行排序。
a.loc 通过标签索引行数据
a.iloc 通过位置获取行数据
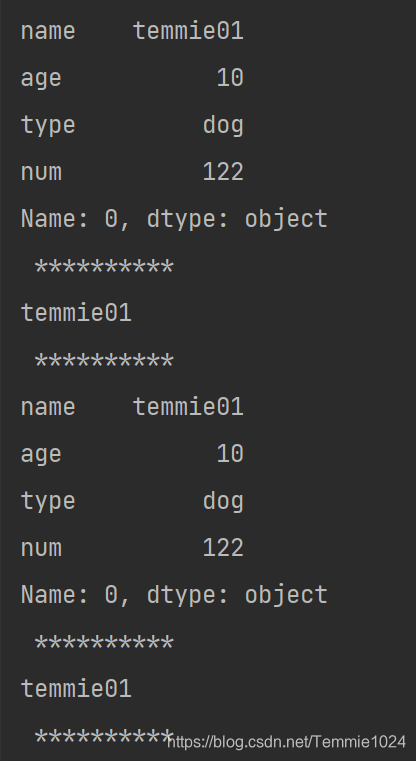
import pandas
b={'name':['temmie01','temmie02'],'age':[10,20],'type':['dog','dog'],'num':[122,133]}
a=pandas.DataFrame(b)
print(a.loc[0],'\n','**********')#这里的0是标签
print(a.loc[0,'name'],'\n','**********')#这里的0是标签
print(a.iloc[0,:],'\n','**********')#这里的0是位置
print(a.iloc[0,0],'\n','**********')#这里的0是位置
布尔索引
同前面的使用方法
a[a[指定的列名]>条件]
这里面不能使用连续的条件了(例如<内容<),这里需要分别判断再通过逻辑关系组合。

pandas读取外部数据
读取csv文件
pandas.read_csv(‘路径’)
pandas.read还有很多选项,可以在输入read时根据提示选择。
mongodb的这里先不记录了,还没用到。
处理nan数据
pandas在计算均值等内容时,不会像numpy一样计算时考虑nan。
pandas.isnull(数组) 可以判断数组中是否有nan,返回数组中True的地方为nan,False不是nan。(notnull与之相反)
数组.dropna(axis=0,how=‘any’,inplace=内容) 删除nan的行或列。axis=0删除行,axis=1删除列。how用于设定删除条件,any表示只要出现nan则删除,all表示行(或列)全是nan才会删除。inplace用来替换nan位置的内容,是可选项。
数组.fillna(值) 可以把数组中nan的位置填充为 值 。值也可以写入表达式。例如: 数组.mean 表示均值。
数据合并
join
默认情况会把行索引相同的数据合并到一起
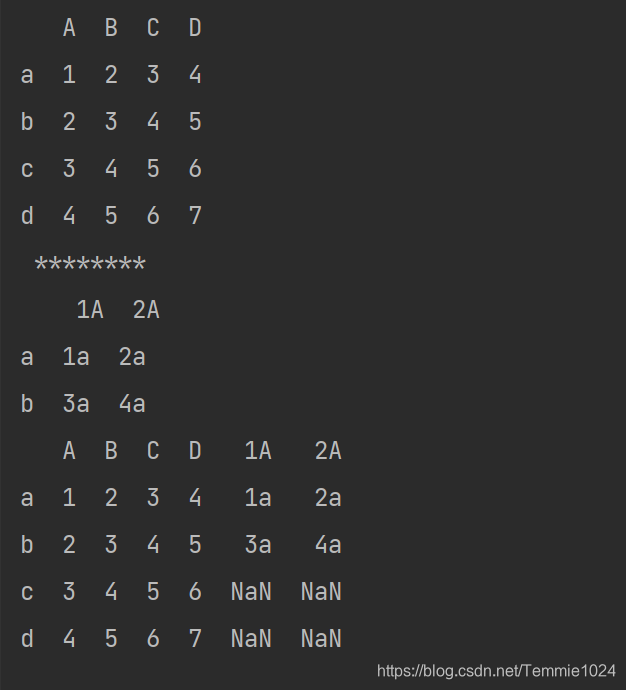
import pandas
b=[[1,2,3,4],[2,3,4,5],[3,4,5,6],[4,5,6,7]]
c=[['1a','2a'],['3a','4a']]
a=pandas.DataFrame(b,index=list('abcd'),columns=list('ABCD'))
d=pandas.DataFrame(c,index=list('ab'),columns=['1A','2A'])
print(a,'\n','********','\n',d)
e=a.join(d)
print(e)
merge
这里视频讲的有些乱,直接查api
pandas.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(’_x’, ‘_y’), copy=True, indicator=False, validate=None)
left表示要合并的数组1。right表示要合并的数组2。
how{‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, default ‘inner’,合并的方式,默认内部合并。left仅使用左框架中的键,类似于SQL左外部联接;保留关键顺序;right仅使用右框架中的键,类似于SQL右外部联接;保留关键顺序;outer使用两个框架中键的并集,类似于SQL完全外部联接;按字典顺序对键进行排序;inner使用两个框架中关键点的交集,类似于SQL内部联接;保留左键的顺序;cross从两个框架创建笛卡尔乘积,保留左键的顺序。
on label or list
left_on label or list, or array-like
suffixes list-like, default is (“_x”, “_y”)
例子:
on的默认值为None,对于inner合并方式,在两个数组之间寻找交集
import pandas
b=[[1,2,3],[2,3,4],[3,4,5]]
c=[[1,2],[1,1]]
a=pandas.DataFrame(b,columns=list('ABC'))
d=pandas.DataFrame(c,columns=list('AD'))
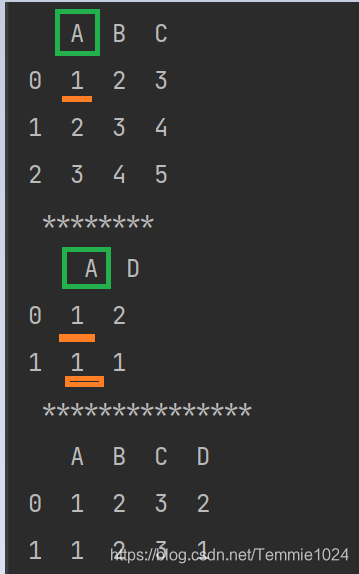
print(a,'\n','********','\n',d,'\n','***************')
e=pandas.merge(a,d,how='inner',on=None)
print(e)
对共有的A进行交集,数组1中1只有第一列。
改变数组,
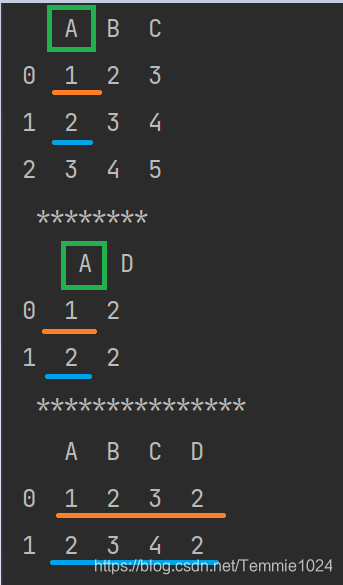
改变数组

如果是outer则向外补齐
import pandas
b=[[1,2,3],[2,3,4],[3,4,5]]
c=[[1,2],[1,1]]
a=pandas.DataFrame(b,columns=list('ABC'))
d=pandas.DataFrame(c,columns=list('AD'))
print(a,'\n','********','\n',d,'\n','***************')
e=pandas.merge(a,d,how='outer',on=None)
print(e)
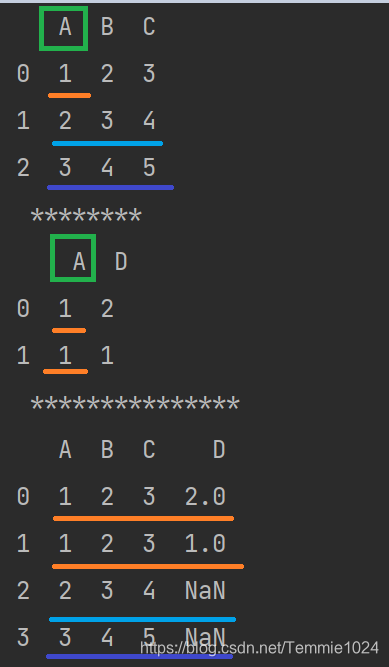
改变数组
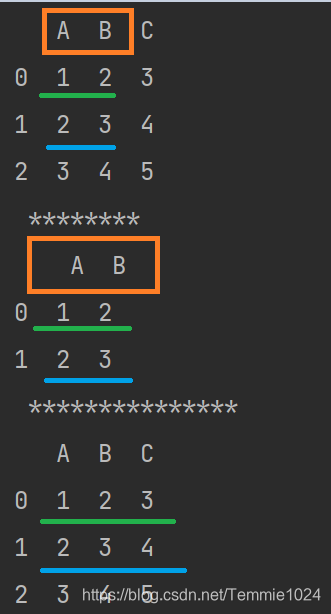
on ‘A’则只对A进行并集,即便其他的列也有相同的,但不考虑。
outer的
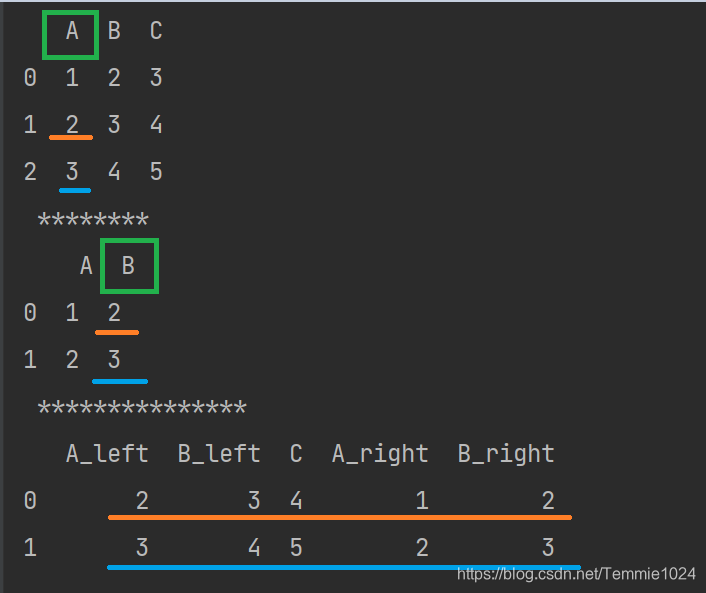
import pandas
b=[[1,2,3],[2,3,4],[3,4,5]]
c=[[1,2],[2,3]]
a=pandas.DataFrame(b,columns=list('ABC'))
d=pandas.DataFrame(c,columns=list('AB'))
print(a,'\n','********','\n',d,'\n','***************')
e=pandas.merge(a,d,how='outer',on='A')
print(e)
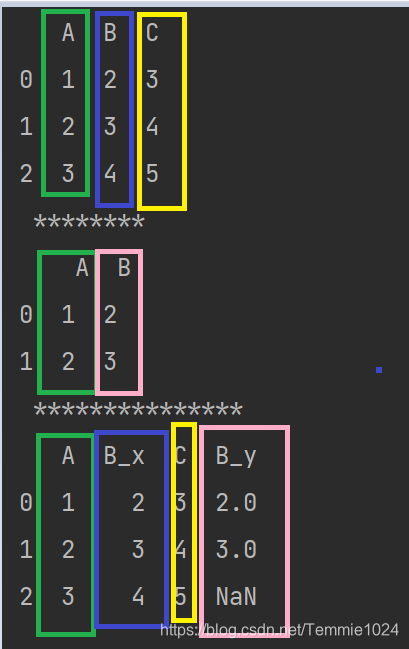
inner的
你也可以看到两个B被重命名为B_x B_y,你可以自定义重命名的方式
suffixes
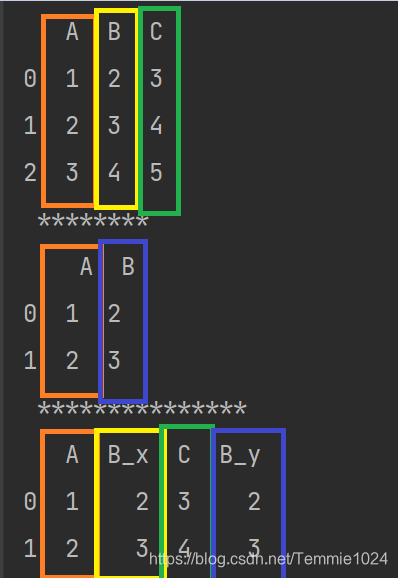
import pandas
b=[[1,2,3],[2,3,4],[3,4,5]]
c=[[1,2],[2,3]]
a=pandas.DataFrame(b,columns=list('ABC'))
d=pandas.DataFrame(c,columns=list('AB'))
print(a,'\n','********','\n',d,'\n','***************')
e=pandas.merge(a,d,how='inner',on='A',suffixes=('_left','_right'))
print(e)
left_on与right_on,指定对比的列
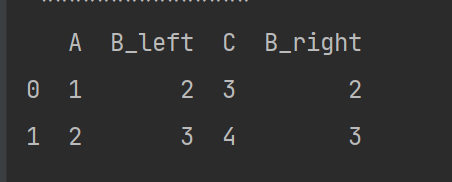
import pandas
b=[[1,2,3],[2,3,4],[3,4,5]]
c=[[1,2],[2,3]]
a=pandas.DataFrame(b,columns=list('ABC'))
d=pandas.DataFrame(c,columns=list('AB'))
print(a,'\n','********','\n',d,'\n','***************')
e=pandas.merge(a,d,how='inner',left_on='A',right_on='B',suffixes=('_left','_right'))
print(e)
merge总结
outer与inner,outer会向外扩展,数组行列可能增加;inner对内取交集,数组行列可能减小。
on决定对比的标签,两个数组必须同时包含此标签
left_on与right_on指定第1个数组与第2个数组对比的标签,两者可以不同,相同则效果等同于on
suffixes指定重复标签时左侧标签与右侧标签的附加内容
分组与聚合
使用groupby进行分组。
import pandas
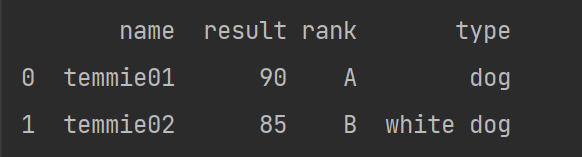
b=[['temmie01',90,'A','dog'],['temmie02',85,'B','white dog'],['temmie03',80,'B','white dog'],['temmie04',50,'C','white dog'],['temmie05',70,'C','dog'],['temmie06',83,'B','dog']]
a=pandas.DataFrame(b,columns=['name','result','rank','type'])
print(a,'\n','**********')
c=a.groupby(by='rank')
print(c)
返回的不是datagroup,是datagroupby

这是一个可以遍历的对象,这里用list显示一下看看。
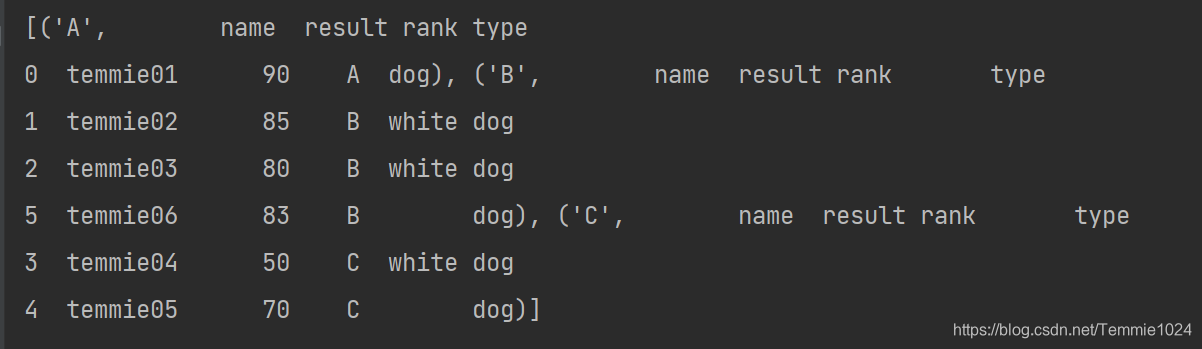
可以看到它按我的要求根据type进行了分类。
多个标签分类:
c=a.groupby(by=['rank','type'])

对datagroupby的操作:
**count()**统计分类后数目,是条数。
print(c.count())

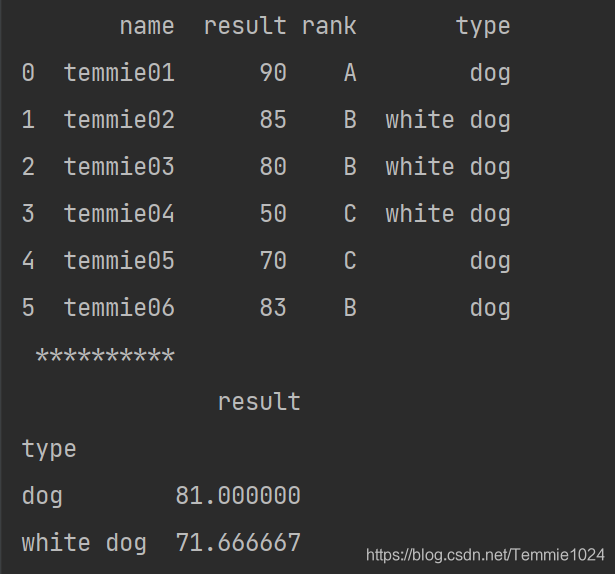
**mean()**求取平均值
print(c.mean())
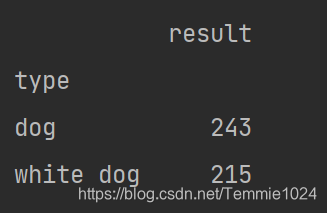
**sum()**求和
print(c.sum())
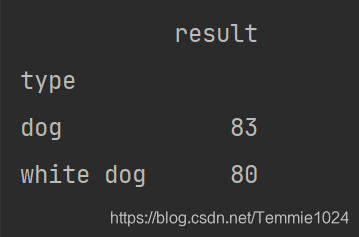
median取算数中位数
print(c.median())
std取标准差
print(c.std())
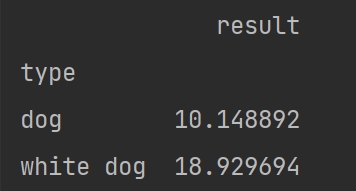
var取方差
print(c.var())
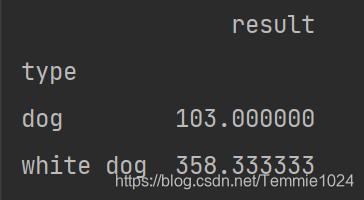
min取最小值,max取最大值同理。
print(c['result'].min())
==为什么这里加了标签?==字符串依旧可以比较大小,直接算min的话会把所有标签最小的保留,每个标签是独立计算的。
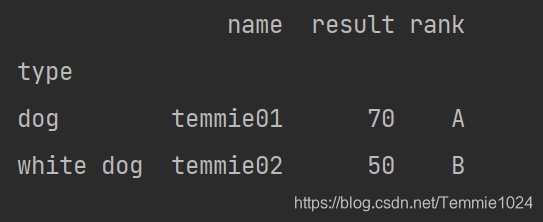
然而原始数据不是这样的。
索引和复合索引
获取index:a.index
import pandas
b=[['temmie01',90,'A','dog'],['temmie02',85,'B','white dog'],['temmie03',80,'B','white dog'],['temmie04',50,'C','white dog'],['temmie05',70,'C','dog'],['temmie06',83,'B','dog']]
a=pandas.DataFrame(b,index=list(x for x in range(1,7,1)),columns=['name','result','rank','type'])
print(a)
print(a.index)
行标签
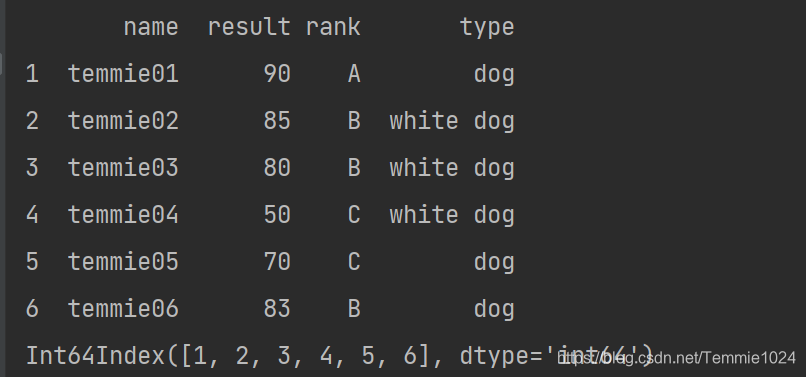
指定index :a.index =list(x for x in range(11,17,1))
import pandas
b=[['temmie01',90,'A','dog'],['temmie02',85,'B','white dog'],['temmie03',80,'B','white dog'],['temmie04',50,'C','white dog'],['temmie05',70,'C','dog'],['temmie06',83,'B','dog']]
a=pandas.DataFrame(b,index=list(x for x in range(1,7,1)),columns=['name','result','rank','type'])
a.index =list(x for x in range(11,17,1))
print(a)
print(a.index)
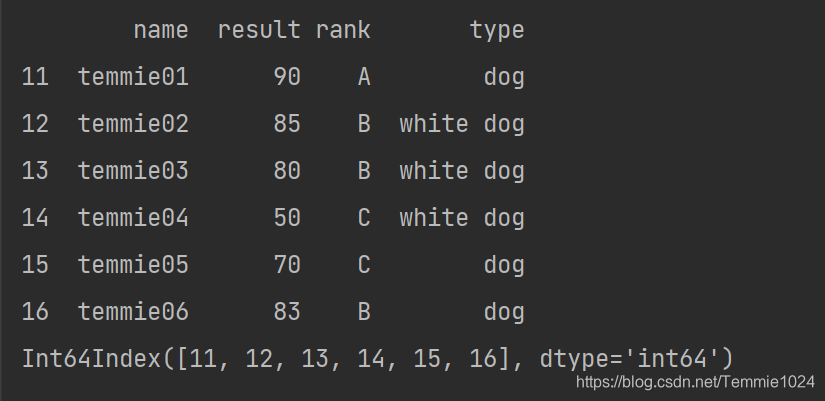
还有一种方法:重新设置index : a.reindex(list(“1b3e5f”))
注意,这种方法是对照前面的index,如果有则取出,没有会写入nan
import pandas
b=[['temmie01',90,'A','dog'],['temmie02',85,'B','white dog'],['temmie03',80,'B','white dog'],['temmie04',50,'C','white dog'],['temmie05',70,'C','dog'],['temmie06',83,'B','dog']]
a=pandas.DataFrame(b,index=[1,2,3,4,5,6],columns=['name','result','rank','type'])
print(a)
b=a.reindex([1,'b',3,'c',5,'f'])
print(b)
注意index的属性,我在前面赋值的时候使用了range是数字1234,后面如果reindex中输入字符串1234,二者会因为类型不同而写入依旧是nan
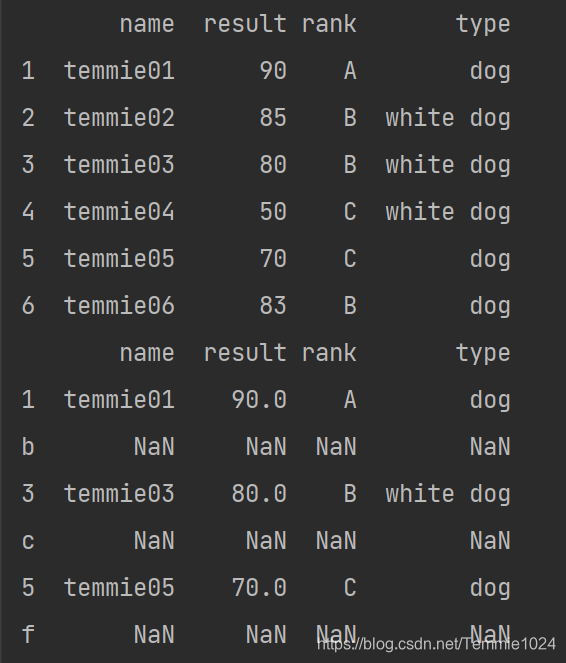
指定某一列作为index :a.set_index(‘name’)
import pandas
b=[['temmie01',90,'A','dog'],['temmie02',85,'B','white dog'],['temmie03',80,'B','white dog'],['temmie04',50,'C','white dog'],['temmie05',70,'C','dog'],['temmie06',83,'B','dog']]
a=pandas.DataFrame(b,index=[1,2,3,4,5,6],columns=['name','result','rank','type'])
print(a)
b=a.set_index('name')
print(b)
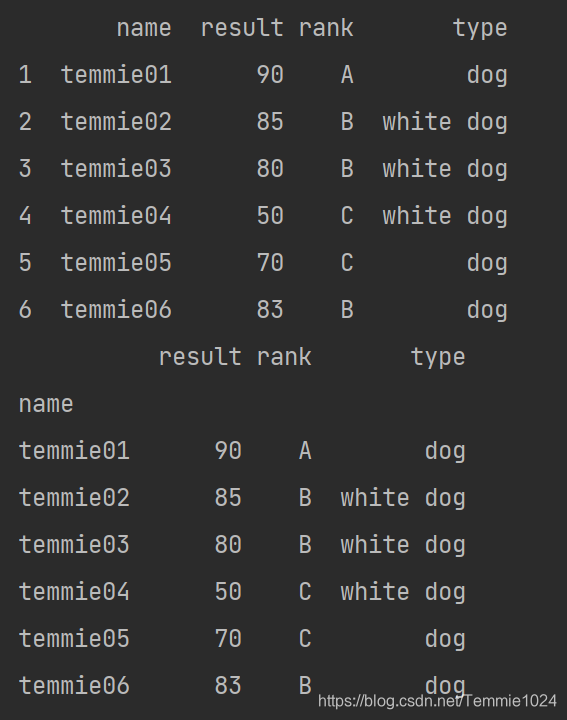
如果你希望这一列做标签的同时保留在内容中,在后面添加drop=False
b=a.set_index('name',drop=False)
这样就保留了

复合索引出现在多个index label的时候,在set_index时你可以传入一个列表,列表中包含多个label就可以。
b=a.set_index(['name','type'])
现在name 和 type都是index_label
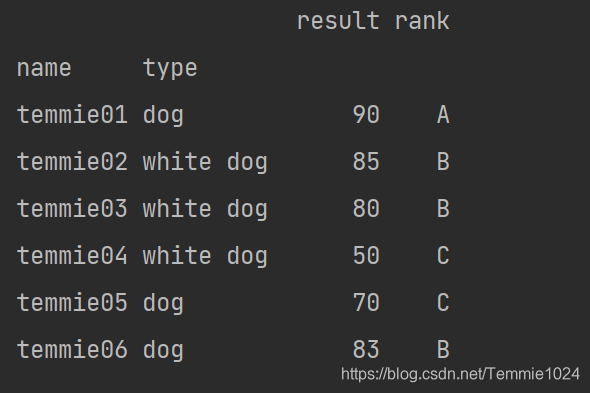
对于Series的复合索引
import pandas
b=[['temmie01',90,'A','dog'],['temmie02',85,'B','white dog'],['temmie03',80,'B','white dog'],['temmie04',50,'C','white dog'],['temmie05',70,'C','dog'],['temmie06',83,'B','dog']]
a=pandas.DataFrame(b,index=[1,2,3,4,5,6],columns=['name','result','rank','type'])
b=a.set_index(['type','name','rank'])['result']
print(b)
print('********************')
print(b['dog','temmie01','A'])
注意set_index后只取了一列变成了series
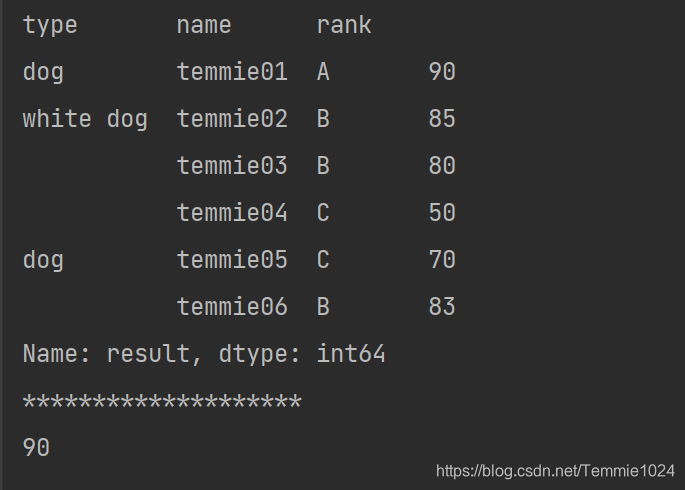
对于DataFrame的复合索引
import pandas
b=[['temmie01',90,'A','dog'],['temmie02',85,'B','white dog'],['temmie03',80,'B','white dog'],['temmie04',50,'C','white dog'],['temmie05',70,'C','dog'],['temmie06',83,'B','dog']]
a=pandas.DataFrame(b,index=[1,2,3,4,5,6],columns=['name','result','rank','type'])
b=a.set_index(['type','name'])
print(b)
print('********************')
print(b.loc['dog'].loc['temmie01'])
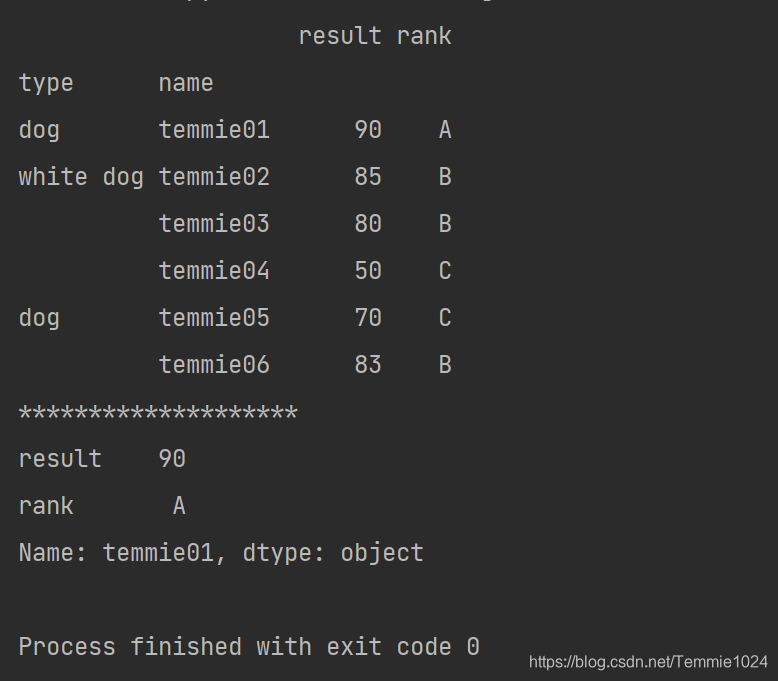
注意,这里和前面相比,type和name的顺序调换了,这一变化可以用a.sweeplevel()来实现。
时间序列
pandas.date_range(start= ,end= ,periods= ,freq= )
start和end以及freq生成从start到end范围以频率freq的一组时间索引。
start和periods以及freq生成从start开始频率为freq的periods个时间索引。
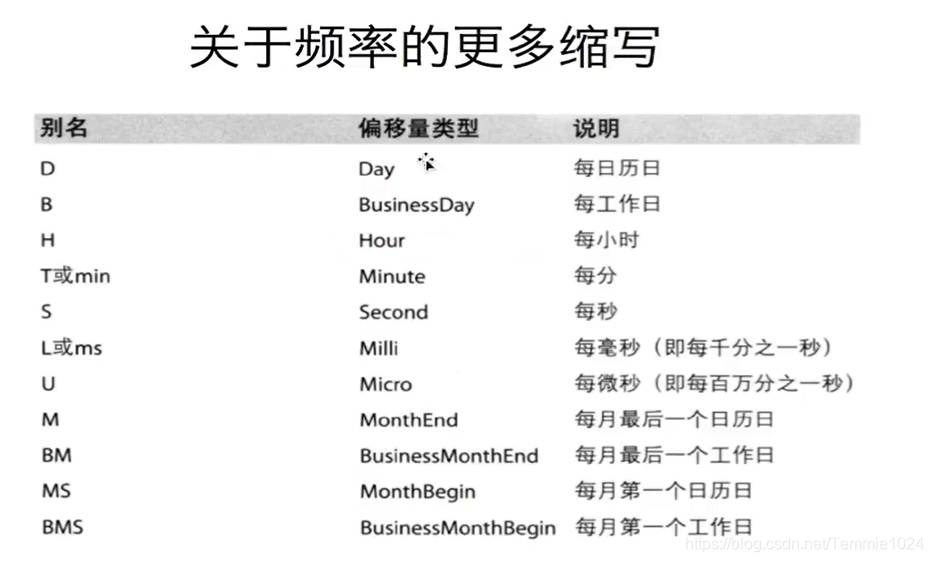
fre可以选择
将时间字符串转化为时间序列,使用pandas.to_datetime()
如果你写的时间格式pandas没有识别出来,你可以在pandas.to_datetime中添加formate=来格式化。
文档链接
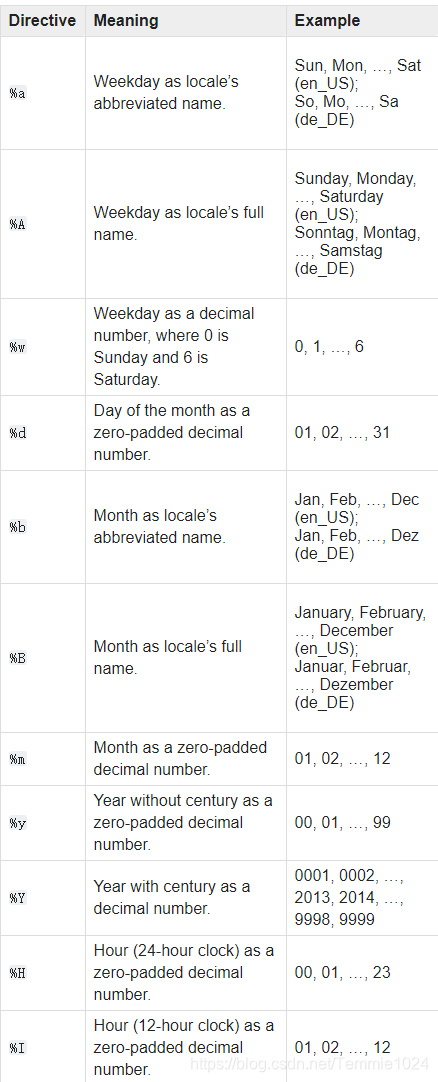
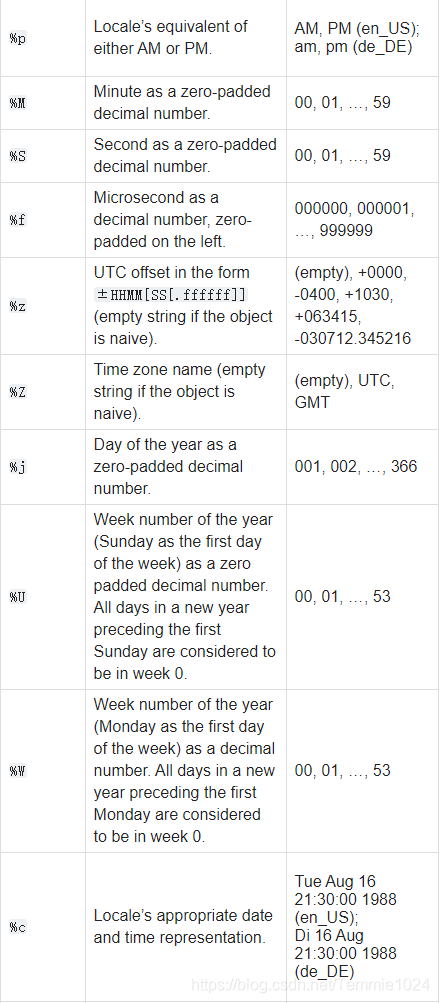

时间重采样
将一个时间序列从用频率转化到另一个频率。
高频数据转化为低频称为降采样,低频率转化为高频为升采样。使用resample方法来实现频率的转化。
resample相当于前面groupby这样的操作,返回的也是那种东西,之后可以进行聚合操作,例如mean、count…。a.resample(‘M’)就相当于按月重采样,这里的字母填写同上面创建时间序列。
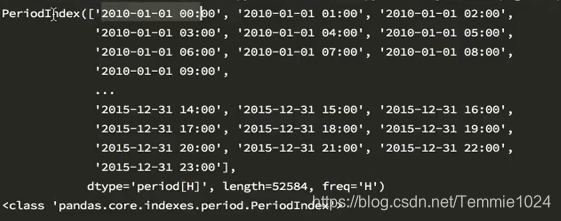
PeriodIndex
如果日期是这样的形式,可以使用PeriodIndex来合并
pandas.PeriodIndex(year=data[“year”],month=data[“month”],day=data[“day”],hour=data[“hour”],freq=“H”))
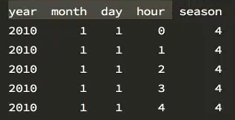

可以生成这样一个序列














 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









