






本文是写自约10年前的旧文,请酌情参考
是的, 在前两天的Google IO大会上推出的Android L上,ART已取代dalvik成为首选运行时环境,这似乎表示dalvik的时日已经不多了。但看了一半总不能半途而废,无论如何还是总结下吧。
在阅读dalvik代码过程中参考了一些资料,在本文最后列出。这些资料从不同角度对dalvik内存相关做了分析,但有的片面或过于概括,本文主要对整体主要流程作下梳理,并对个人较感兴趣的细节进行探究。能力有限,仅供参考,如果发现错误,还烦请告知,多谢。
一.初始化及内存布局
我们知道android系统的启动是从app_process进程开始的,并且将这个进程命名为“zygote”,在app_process:main()这个方法中调用了AndroidRuntime:start()开始了一系列的初始化操作,其中便包括构建虚拟机对象(startVM()),在zygote进程构建dvm对象并初始化相关内存后, 随后其通过fork孵化出的app进程的dvm直接拷贝了这个dvm的内存。 要了解Dalvik的内存原理,就zygote创建虚拟机开始。
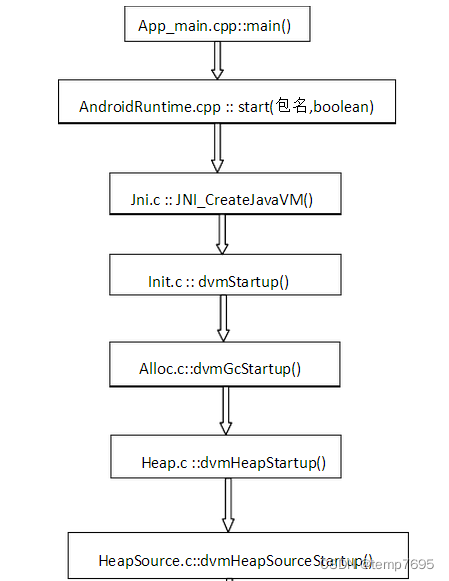
最终会调用到HeapSource.c的dvmHeapSourceStartup方法。
代码如下:
GcHeap* dvmHeapSourceStartup(size_t startSize, size_t maximumSize,
size_t growthLimit)
{
GcHeap *gcHeap;
HeapSource *hs;
mspace msp;
size_t length;
void *base;
assert(gHs == NULL);
if (!(startSize <= growthLimit && growthLimit <= maximumSize)) {
ALOGE("Bad heap size parameters (start=%zd, max=%zd, limit=%zd)",
startSize, maximumSize, growthLimit);
return NULL;
}
/*
* Allocate a contiguous region of virtual memory to subdivided
* among the heaps managed by the garbage collector.
*/
length = ALIGN_UP_TO_PAGE_SIZE(maximumSize);
base = dvmAllocRegion(length, PROT_NONE, "dalvik-heap");
if (base == NULL) {
return NULL;
}
/* Create an unlocked dlmalloc mspace to use as
* a heap source.
*/
msp = createMspace(base, kInitialMorecoreStart, startSize);
if (msp == NULL) {
goto fail;
}
gcHeap = (GcHeap *)calloc(1, sizeof(*gcHeap));
if (gcHeap == NULL) {
LOGE_HEAP("Can't allocate heap descriptor");
goto fail;
}
hs = (HeapSource *)calloc(1, sizeof(*hs));
if (hs == NULL) {
LOGE_HEAP("Can't allocate heap source");
free(gcHeap);
goto fail;
}
hs->targetUtilization = DEFAULT_HEAP_UTILIZATION;
hs->startSize = startSize;
hs->maximumSize = maximumSize;
hs->growthLimit = growthLimit;
hs->idealSize = startSize;
hs->softLimit = SIZE_MAX; // no soft limit at first
hs->numHeaps = 0;
hs->sawZygote = gDvm.zygote;
hs->hasGcThread = false;
hs->heapBase = (char *)base;
hs->heapLength = length;
if (!addInitialHeap(hs, msp, growthLimit)) {
LOGE_HEAP("Can't add initial heap");
goto fail;
}
if (!dvmHeapBitmapInit(&hs->liveBits, base, length, "dalvik-bitmap-1")) {
LOGE_HEAP("Can't create liveBits");
goto fail;
}
if (!dvmHeapBitmapInit(&hs->markBits, base, length, "dalvik-bitmap-2")) {
LOGE_HEAP("Can't create markBits");
dvmHeapBitmapDelete(&hs->liveBits);
goto fail;
}
if (!allocMarkStack(&gcHeap->markContext.stack, hs->maximumSize)) {
ALOGE("Can't create markStack");
dvmHeapBitmapDelete(&hs->markBits);
dvmHeapBitmapDelete(&hs->liveBits);
goto fail;
}
gcHeap->markContext.bitmap = &hs->markBits;
gcHeap->heapSource = hs;
gHs = hs;
return gcHeap;
fail:
munmap(base, length);
return NULL;
}在阅读这个方法前, 先看一下这个方法的几个参数:startSize, maximumSize, growthLimit, 向其调用上级看去, 传入的值分别为gDvm.heapStartingSize, gDvm.heapMaximumSize, gDvm.heapGrowthLimit, 分别代表进程的初始内存分配大小, 最大内存大小,初始大小不够用后可扩展为的最大内存大小。这几个值都可以在prop中进行配置, 默认情况下一般为2M、16M、0(这几个值在代码中可找到), 而运行过程中heapGrowthLimit为0的话会将其赋值为heapMaximumSize。
从这个方法中我们可以看到,在构建虚拟机对象的过程中会初始化虚拟机内存布局, 申请几大块内存地址,其中有一块称为所谓的“dalvik堆”,android应用java层的内存操作主要就是在这个堆上进行的。其他还有几块内寸主要用于对这个堆进行维护。大概分布如下:
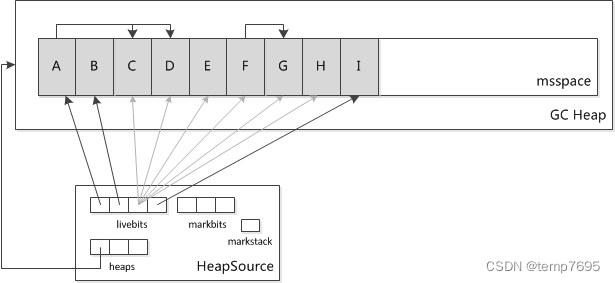
如图, 这几块内存分别是heaps(dalvik-heap), livebits(dalvik-bitmap-1), markbits(dalvik-bitmap-2), markstack(dalvik-mark-stack), 他们由一个成为HeapSource的数据结构维护。Java层的内存都是在heaps(dalvik-heap)中进程管理的。Heaps维护了一个Heap结构的数组,即HeapSource->heaps[], 也就是说dalvik内存堆里面包含多个Heap,Heap里面包含java对象。 一共会有三个Heap。为什么是三个稍后说。
看代码:
base = dvmAllocRegion(length, PROT_NONE, "dalvik-heap");
申请一块名为dalvik-heap的内存, 就是我们所说的dalvik堆, 他是怎么申请的呢?看一下Misc:dvmAllocRegion():
void *dvmAllocRegion(size_t byteCount, int prot, const char *name) {
void *base;
int fd, ret;
byteCount = ALIGN_UP_TO_PAGE_SIZE(byteCount);
fd = ashmem_create_region(name, byteCount);
if (fd == -1) {
return NULL;
}
base = mmap(NULL, byteCount, prot, MAP_PRIVATE, fd, 0);
ret = close(fd);
if (base == MAP_FAILED) {
return NULL;
}
if (ret == -1) {
return NULL;
}
return base;
}原来是用“匿名共享内存ashmem”和mmap的方式直接申请了一块用户进程私有内存, ashmem可参见http://blog.csdn.net/luoshengyang/article/details/6651971, 这里应该主要是更好的对内存进行管理。我们注意到在mmap的几个参数, byteCount是按页对齐后的maximumSize, 也就是最大可用内存16M(默认情况下), 而prop是PROT_NONE, 也就是说这块内存目前还是不可操作的。
再回来看dvmHeapSourceStartup函数,下面调用了
msp = createMspace(base, kInitialMorecoreStart, startSize);
Base是刚刚申请的那块内存的首地址, kInitialMorecoreStart是个全局常量,为SYSTEM_PAGE_SIZE,也就一个页的长度,一般为4K(当然不是一定的), startSize是gDvm.heapStartingSize也就是2M。从createMspace的注释可以看到这个方法实际上是基于dlmalloc的。Dlmalloc的介绍参见这里:
dlmalloc解析错误列表_lenky0401-ChinaUnix博客
总的来说, 就是在刚刚向系统申请了那一大块堆后, 这个堆具体如何分配java对象是通过mspace来管理的。我们看上面的图,Heap里被分了A、B、C等等小块,这一个小块代表一个对象,这些对象正是通过mspace分配的。
我们看createMspace方法内部:
static mspace createMspace(void* begin, size_t morecoreStart, size_t startingSize)
{
// Clear errno to allow strerror on error.
errno = 0;
// Allow access to inital pages that will hold mspace.
mprotect(begin, morecoreStart, PROT_READ | PROT_WRITE);
// Create mspace using our backing storage starting at begin and with a footprint of
// morecoreStart. Don't use an internal dlmalloc lock. When morecoreStart bytes of memory are
// exhausted morecore will be called.
mspace msp = create_mspace_with_base(begin, morecoreStart, false /*locked*/);
if (msp != NULL) {
// Do not allow morecore requests to succeed beyond the starting size of the heap.
mspace_set_footprint_limit(msp, startingSize);
} else {
ALOGE("create_mspace_with_base failed %s", strerror(errno));
}
return msp;
}注意到mprotect(begin, morecoreStart, PROT_READ | PROT_WRITE);
Mprotect()是linux方法,是改变前morecoreStart的长度,也就是前4K的内存的操作状态,将其改为可读写。
也就是说,我们现在有4K的内存可用了,下面看
mspace msp = create_mspace_with_base(begin, morecoreStart, false /*locked*/)
这句话看起来是创建了一个名为msp的mspace对象, 这个msp可已看作是一个mspace内存分配方式的管理者。从mspace结构体的各个字段名称上可见一斑,这里先不展开,下面遇到了再说。
在malloc.c中:
mspace create_mspace_with_base(void* base, size_t capacity, int locked) {
mstate m = 0;
size_t msize;
ensure_initialization();
msize = pad_request(sizeof(struct malloc_state));
if (capacity > msize + TOP_FOOT_SIZE &&
capacity < (size_t) -(msize + TOP_FOOT_SIZE + mparams.page_size)) {
m = init_user_mstate((char*)base, capacity);
m->seg.sflags = EXTERN_BIT;
set_lock(m, locked);
}
return (mspace)m;
}这些其实都是基于dlmalloc的代码,具体细节就不考究了,大概是通过pad_request获取到mspace结构体的长度, 通过init_user_mstate初始化morecoreStart这段长度的内存,并返回初始化后的mspace结构体对象。看一下init_user_mstate
static mstate init_user_mstate(char* tbase, size_t tsize) {
size_t msize = pad_request(sizeof(struct malloc_state));
mchunkptr mn;
mchunkptr msp = align_as_chunk(tbase);
mstate m = (mstate)(chunk2mem(msp));
memset(m, 0, msize);
(void)INITIAL_LOCK(&m->mutex);
msp->head = (msize|INUSE_BITS);
m->seg.base = m->least_addr = tbase;
m->seg.size = m->footprint = m->max_footprint = tsize;
m->magic = mparams.magic;
m->release_checks = MAX_RELEASE_CHECK_RATE;
m->mflags = mparams.default_mflags;
m->extp = 0;
m->exts = 0;
disable_contiguous(m);
init_bins(m);
mn = next_chunk(mem2chunk(m));
init_top(m, mn, (size_t)((tbase + tsize) - (char*)mn) - TOP_FOOT_SIZE);
check_top_chunk(m, m->top);
return m;
}我们看通过pad_request算出malloc_state结构体(最后会转换成mspace)的长度,注意因为这里都是基于dlmalloc的,所以所有操作都是以dlmalloc的角度来处理的(chunk计算转换什么的),然后mchunkptr msp = align_as_chunk(tbase);mstate m = (mstate)(chunk2mem(msp));这两句话大概可认为是msp指向大概堆的开始处(经过块对齐等处理后,会离开始处有一些偏移),memset(m, 0, msize);这句话初始化了从msp到morecoreStart这段内存,大概可认为是堆开头的一段内存。然后下面开始对malloc_state结构体的各个字段进行初始化。我们注意到 msp->head = (msize|INUSE_BITS);和m->seg.size = m->footprint = m->max_footprint = tsize;
Tsize是morecoreStart。也就是从head到footprint 是malloc_state结构体的末尾到morecoreStart这样一段距离。init_top(m, mn, (size_t)((tbase + tsize) - (char*)mn) - TOP_FOOT_SIZE);这句话是将malloc_state的top字段指向刚刚malloc_state的指针, 将m->topsize指向malloc_state的长度,而head字段指向了malloc_state的尾部。
回到createMspace方法。
mspace_set_footprint_limit(msp, startingSize);
这句话实际上是把startingSize赋值给了msp的footprint_limit字段。并没有做具体的内存分配。也就是说所谓的初始分配2M内存,只是设置了一个标识而已。
确实有点乱。先忍一下,这段代码最后返回了初始化过的mspace,并返回。现在我们回到dvmHeapSourceStartup(),继续往下看:
在创建问msp后, 申请并初始化了HeapSource结构体的内存, 将各个属性初始化。然后调用addInitialHeap();
在addInitialHeap方法里, 我们看到主要是对hs->heaps[0], 也就是第一个Heap对象进行初始化,确实, 目前来说只有一个Heap。在这个方法中hs->heaps[0].msp = msp;将msp字段指想了刚刚申请的mspace, hs->heaps[0].base = hs->heapBase;base字段指向堆的指针,hs->heaps[0].brk = hs->heapBase + kInitialMorecoreStart; brk字段标识当前已初始化内存的大小。hs->heaps[0].maximumSize = maximumSize;标识最大可用内存大小。
到这里,dalvik堆的初始话暂告一段落。总的来说,就是向系统申请了一块maximumSize(比如16M)的内存, 然后通过HeapSource数据结构对这块内存进行维护。HeapSource又细化了下,分成了几个Heap结构体对象,一共会有三个Heap,每个Heap会通过mspace(dmalloc)的方式进行java对象的分配。每个Heap头会有一个msp(malloc_state)对象,对mspce分配器进行管理。
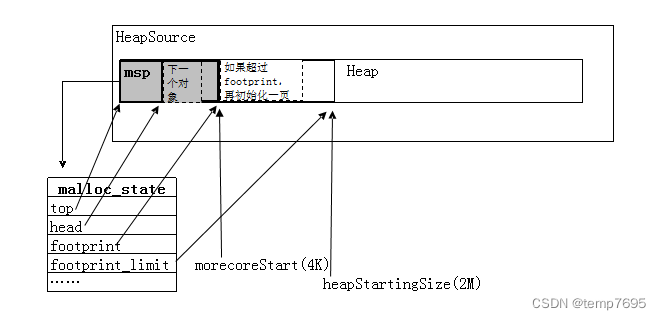
虽然总的内存会有16M, 并且初始的时候只分配2M(startSize), 但这2M的分配实际上只是逻辑的概念,并没有真的分配2M,它只是类似一种水线的东西,mspace分配器一开始只是分配了一页的内存,通过msp对象的top、head、brk等字段进行对象分配的控制。Top不断指向内存最后一个(也就是最新)的对象地址,每申请一个对象都会实时更新几个相关字段值,当这一页快要用完时(长度超过footprint字段值),会在堆上再申请并初始化一页的空间。
而这第一个一页内存的开始部分被msp管理对象本身给占了,所以java对象是从msp的结尾开始分配。
初始化后大概的样子是这样的:
继续往下看, 初始化dalvik对后,
dvmHeapBitmapInit(&hs->liveBits, base, length, "dalvik-bitmap-1")
dvmHeapBitmapInit(&hs->markBits, base, length, "dalvik-bitmap-2")
allocMarkStack(&gcHeap->markContext.stack, hs->maximumSize)
会再申请三块内存,他们主要用来GC过程中对对象的管理。
liveBits和markBits都是存的bites数组,每个元素对应一个heap堆里的java对象。liveBites如其名字,指活着的对象,就是每生成一个java对象都会向liveBite添加一个对应的标识元素。也就是说liveBite代表了当前已申请的所有对象。markBits是GC过程中用到的,dalvik的垃圾收集器主要为标记清理(Mark-Sweep)收集器和拷贝(Copy)收集器,本文直说Mark-Sweep。而这个markBits如其名,代表已标识过(marked)的对象。markStatck也是在Gc过程中用到的, 主要是当作一个中间过度的容器,后面会说到。
到此, dvm的初始话基本完事了。
有一个问题, 刚才说到SourceHeap包含3个Heap,现在只有一个Heap,其他两个呢?
如文章开头的图,我们知道刚刚初始话的过程是在AndroidRuntime中进行的,在这个初始化方法后,紧接着会启动ZygoteInit.java, Zygote模式下,通过Sockt监听接到孵化进程的命令后,ZygoteInit会最终调用dalvik_system_Zygote.cpp的forkAndSpecializeCommon方法进行fork进程。
在fork之前,会调用dvmGcPreZygoteFork()方法, 而这个方法最终会调用HeapSource.cpp的addNewHeap()方法,这个方法里会再次创建一个新的Heap
其过程如图:
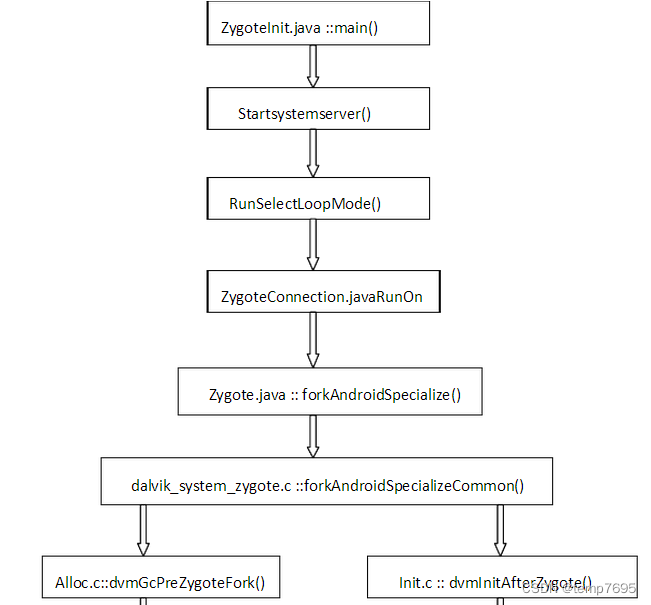
我们看下addNewHeap()方法:
static bool addNewHeap(HeapSource *hs)
{
Heap heap;
assert(hs != NULL);
if (hs->numHeaps >= HEAP_SOURCE_MAX_HEAP_COUNT) {
ALOGE("Attempt to create too many heaps (%zd >= %zd)",
hs->numHeaps, HEAP_SOURCE_MAX_HEAP_COUNT);
dvmAbort();
return false;
}
memset(&heap, 0, sizeof(heap));
/*
* Heap storage comes from a common virtual memory reservation.
* The new heap will start on the page after the old heap.
*/
char *base = hs->heaps[0].brk;
size_t overhead = base - hs->heaps[0].base;
assert(((size_t)hs->heaps[0].base & (SYSTEM_PAGE_SIZE - 1)) == 0);
if (overhead + HEAP_MIN_FREE >= hs->maximumSize) {
LOGE_HEAP("No room to create any more heaps "
"(%zd overhead, %zd max)",
overhead, hs->maximumSize);
return false;
}
size_t morecoreStart = SYSTEM_PAGE_SIZE;
heap.maximumSize = hs->growthLimit - overhead;
heap.concurrentStartBytes = HEAP_MIN_FREE - CONCURRENT_START;
heap.base = base;
heap.limit = heap.base + heap.maximumSize;
heap.brk = heap.base + morecoreStart;
heap.msp = createMspace(base, morecoreStart, HEAP_MIN_FREE);
if (heap.msp == NULL) {
return false;
}
/* Don't let the soon-to-be-old heap grow any further.
*/
hs->heaps[0].maximumSize = overhead;
hs->heaps[0].limit = base;
mspace_set_footprint_limit(hs->heaps[0].msp, overhead);
/* Put the new heap in the list, at heaps[0].
* Shift existing heaps down.
*/
memmove(&hs->heaps[1], &hs->heaps[0], hs->numHeaps * sizeof(hs->heaps[0]));
hs->heaps[0] = heap;
hs->numHeaps++;
return true;
}新建了一个Heap对象,并初始化其相关字段。最后我们看到:
memmove(&hs->heaps[1], &hs->heaps[0], hs->numHeaps * sizeof(hs->heaps[0]));
就是将SourceHeap->heaps[]的第一个元素向后移,然后第0个元素指向新建的Heap。也就是第0个元素始终指向最新的Heap。
而另一个fork是在zygote fork的过程中再次调用了addNewHeap(), 我们知道fork的本质是已cow的方式复制父进程的内存, 所以孵化出的新的app进程会拷贝zygote进程的内存结构。所以到这个新的app进程创建完毕的时候,SourceHeap会包含三个Heap, 而且heaps[0]指向的是最后创建的Heap。在后面我们可以看到, 对象的申请和Gc都是在heap[0]上进行的。
二、java对象内存分配过程
内存创建完了, 现在看一下怎么用。
首先看一下java对象的申请过程:
我们知道dalvik实际上是通过解释java字节码的方式运行的, 所以从源头找起的话, java对象new的语意被解释为了new_instance指令, 在OP_NEW_INSTANCE.cpp中看到:dvmAllocObject()。其实还有很多入口, 这里就不一一列举了。
在Alloc.cpp的dvmAllocObject()方法占用调用了Heap.cpp : dvmMalloc()方法, 继而调用了tryMalloc()方法。这里便是对象内存分配的所在了。这个方法中, 首先调用dvmHeapSourceAlloc()方法尝试分配对象内存, 如果失败, 则Gc, 同时调整相应的水线(也就是扩展一下可用内存), 然后再尝试申请,直到发现即使到了最大限度(比如16M)也无法分配成功,就会抛出OOM异常。
tatic void *tryMalloc(size_t size)
{
void *ptr;
//TODO: figure out better heuristics
// There will be a lot of churn if someone allocates a bunch of
// big objects in a row, and we hit the frag case each time.
// A full GC for each.
// Maybe we grow the heap in bigger leaps
// Maybe we skip the GC if the size is large and we did one recently
// (number of allocations ago) (watch for thread effects)
// DeflateTest allocs a bunch of ~128k buffers w/in 0-5 allocs of each other
// (or, at least, there are only 0-5 objects swept each time)
ptr = dvmHeapSourceAlloc(size);
if (ptr != NULL) {
return ptr;
}
/*
* The allocation failed. If the GC is running, block until it
* completes and retry.
*/
if (gDvm.gcHeap->gcRunning) {
/*
* The GC is concurrently tracing the heap. Release the heap
* lock, wait for the GC to complete, and retrying allocating.
*/
dvmWaitForConcurrentGcToComplete();
ptr = dvmHeapSourceAlloc(size);
if (ptr != NULL) {
return ptr;
}
}
/*
* Another failure. Our thread was starved or there may be too
* many live objects. Try a foreground GC. This will have no
* effect if the concurrent GC is already running.
*/
gcForMalloc(false);
ptr = dvmHeapSourceAlloc(size);
if (ptr != NULL) {
return ptr;
}
/* Even that didn't work; this is an exceptional state.
* Try harder, growing the heap if necessary.
*/
ptr = dvmHeapSourceAllocAndGrow(size);
if (ptr != NULL) {
size_t newHeapSize;
newHeapSize = dvmHeapSourceGetIdealFootprint();
//TODO: may want to grow a little bit more so that the amount of free
// space is equal to the old free space + the utilization slop for
// the new allocation.
LOGI_HEAP("Grow heap (frag case) to "
"%zu.%03zuMB for %zu-byte allocation",
FRACTIONAL_MB(newHeapSize), size);
return ptr;
}
/* Most allocations should have succeeded by now, so the heap
* is really full, really fragmented, or the requested size is
* really big. Do another GC, collecting SoftReferences this
* time. The VM spec requires that all SoftReferences have
* been collected and cleared before throwing an OOME.
*/
//TODO: wait for the finalizers from the previous GC to finish
LOGI_HEAP("Forcing collection of SoftReferences for %zu-byte allocation",
size);
gcForMalloc(true);
ptr = dvmHeapSourceAllocAndGrow(size);
if (ptr != NULL) {
return ptr;
}
//TODO: maybe wait for finalizers and try one last time
LOGE_HEAP("Out of memory on a %zd-byte allocation.", size);
//TODO: tell the HeapSource to dump its state
dvmDumpThread(dvmThreadSelf(), false);
return NULL;
}首先是dvmHeapSourceAlloc方法。
void* dvmHeapSourceAlloc(size_t n)
{
HS_BOILERPLATE();
HeapSource *hs = gHs;
Heap* heap = hs2heap(hs);
if (heap->bytesAllocated + n > hs->softLimit) {
/*
* This allocation would push us over the soft limit; act as
* if the heap is full.
*/
LOGV_HEAP("softLimit of %zd.%03zdMB hit for %zd-byte allocation",
FRACTIONAL_MB(hs->softLimit), n);
return NULL;
}
void* ptr = mspace_calloc(heap->msp, 1, n);
if (ptr == NULL) {
return NULL;
}
countAllocation(heap, ptr);
/*
* Check to see if a concurrent GC should be initiated.
*/
if (gDvm.gcHeap->gcRunning || !hs->hasGcThread) {
/*
* The garbage collector thread is already running or has yet
* to be started. Do nothing.
*/
return ptr;
}
if (heap->bytesAllocated > heap->concurrentStartBytes) {
/*
* We have exceeded the allocation threshold. Wake up the
* garbage collector.
*/
dvmSignalCond(&gHs->gcThreadCond);
}
return ptr;
}我们看到
Heap* heap = hs2heap(hs);
Hs2heap(hs)返回的是SouceHeap的第0个Heap, oid* ptr = mspace_calloc(heap->msp, 1, n);这句话是通过mspace分配器去申请一个对象的内存。这段内存的位置是由msp来管理的,之前已说过, 这里就不展开了。这里需要注意的是msp的footprint_limit字段值一开始为staringSize(2M),如果内存总量超过这个值的话,就会引发gc,如果gc后仍不能满足内存的分配,就要调整这个作为水线的值了。
另外在方法的一开始,会判断softLimit,也就是软限制: if (heap->bytesAllocated + n > hs->softLimit), 如果申请的内存大于软限制,会直接返回,引发gc,然后再次尝试申请。Soft limit我的理解一般会是heap[0](所谓的活动Heap)中已申请的内存大小,随着对象不断申请而不断增大,在真正达到限制之前,如果发现会超过soft limit,就先引发gc,因为gc后可能内存会缩减,这时再申请就有可能成功了,就不用再去扩充可用内存空间了。
随后countAllocation(heap, ptr);我们看一下这个方法:
static void countAllocation(Heap *heap, const void *ptr)
{
heap->bytesAllocated += mspace_usable_size(ptr) +
HEAP_SOURCE_CHUNK_OVERHEAD;
heap->objectsAllocated++;
HeapSource* hs = gDvm.gcHeap->heapSource;
dvmHeapBitmapSetObjectBit(&hs->liveBits, ptr);
}heap->bytesAllocated += mspace_usable_size(ptr) +HEAP_SOURCE_CHUNK_OVERHEAD;
heap->objectsAllocated++;
这两行是对当前Heap已使用的容量和对象数量做个记录。再看下一行:
vmHeapBitmapSetObjectBit(&hs->liveBits, ptr);
这个很重要, 进取看一下, 最终会调用HeapBitmapInlines.h : _heapBitmapModifyObjectBit()方法。
static unsigned long _heapBitmapModifyObjectBit(HeapBitmap *hb, const void *obj,
bool setBit, bool returnOld)
{
const uintptr_t offset = (uintptr_t)obj - hb->base;
const size_t index = HB_OFFSET_TO_INDEX(offset);
const unsigned long mask = HB_OFFSET_TO_MASK(offset);
if (setBit) {
if ((uintptr_t)obj > hb->max) {
hb->max = (uintptr_t)obj;
}
if (returnOld) {
unsigned long *p = hb->bits + index;
const unsigned long word = *p;
*p |= mask;
return word & mask;
} else {
hb->bits[index] |= mask;
}
} else {
hb->bits[index] &= ~mask;
}
return false;
}这时的setBit为true, returnOld为false。我们看到首先通过新对象的地址计算出了一个mask, 然后记录在hb->bits[index] |= mask;中, 这个hb->bits就是liveBites。
所以这里我们看到,所有的新对象都会在liveBites里有一个记录标识。
回到tryMalloc()。如果dvmHeapSourceAlloc申请内存失败, 则说明当前的内存不够用了, 需要GC, 于是会调用 gcForMalloc(false);进行垃圾回收, 这里我们先略过,接着往下看, 在gc之后, 会再次调用dvmHeapSourceAlloc(size);尝试分配内存,如果成功则返回,如果失败,则说明刚刚GC的效果不是很大, 就需要调整下相应的水线了:ptr = dvmHeapSourceAllocAndGrow(size);
这个方法在HeapSource.cpp中:
void* dvmHeapSourceAllocAndGrow(size_t n)
{
HS_BOILERPLATE();
HeapSource *hs = gHs;
Heap* heap = hs2heap(hs);
void* ptr = dvmHeapSourceAlloc(n);
if (ptr != NULL) {
return ptr;
}
size_t oldIdealSize = hs->idealSize;
if (isSoftLimited(hs)) {
/* We're soft-limited. Try removing the soft limit to
* see if we can allocate without actually growing.
*/
hs->softLimit = SIZE_MAX;
ptr = dvmHeapSourceAlloc(n);
if (ptr != NULL) {
/* Removing the soft limit worked; fix things up to
* reflect the new effective ideal size.
*/
snapIdealFootprint();
return ptr;
}
// softLimit intentionally left at SIZE_MAX.
}
/* We're not soft-limited. Grow the heap to satisfy the request.
* If this call fails, no footprints will have changed.
*/
ptr = heapAllocAndGrow(hs, heap, n);
if (ptr != NULL) {
/* The allocation succeeded. Fix up the ideal size to
* reflect any footprint modifications that had to happen.
*/
snapIdealFootprint();
} else {
/* We just couldn't do it. Restore the original ideal size,
* fixing up softLimit if necessary.
*/
setIdealFootprint(oldIdealSize);
}
return ptr;
}这个方法里,首先判断一下是否是softlimit引起的申请失败。如果是的话,则将softLimit指定为SIZE_MAX,也就相当于去除softlimit限制,再申请一次。如果还是不行,那只能是调用heapAllocAndGrow去修改footprint_limit,也就是真正扩充一下可用堆了。
static void* heapAllocAndGrow(HeapSource *hs, Heap *heap, size_t n)
{
/* Grow as much as possible, but don't let the real footprint
* go over the absolute max.
*/
size_t max = heap->maximumSize;
mspace_set_footprint_limit(heap->msp, max);
void* ptr = dvmHeapSourceAlloc(n);
/* Shrink back down as small as possible. Our caller may
* readjust max_allowed to a more appropriate value.
*/
mspace_set_footprint_limit(heap->msp,
mspace_footprint(heap->msp));
return ptr;
}我们看到,首先是调用mspace_set_footprint_limit将msp的footprint_limit字段更改为最大可用堆大小(比如16M),然后调用dvmHeapSourceAlloc再次申请内存。申请完毕后,再调用mspace_set_footprint_limit方法,把footprint_limit收缩回来,改为footprint字段的值,也就是当前真正已用(或者说是已申请并初始化)的内存。
返回上一级的dvmHeapSourceAllocAndGrow方法,继续往下看,如果对象内存分配成功的话,调用snapIdealFootprint();更改softlimit为当前已申请内存大小。
到此,这一步已经是个大招了,因为已经尝试过扩展可用内存为最大内存了,如果再不行,那真是没有内存可用了。回到tryMalloc,继续往下看,如果刚刚的方法还是没有分配成功,那么会再一次调用gcForMalloc(true),但这一次参数为true,我们先进取看一下,发现这个参数指定的是是否清理softReference,也就是软引用。也就是说,在刚才已经扩展到最大内存后仍然失败的情况下,会尝试清理一下softReference,然后最后尝试申请一次。这已经是最后的大招了。如果还是不行,那就返回失败。
好的,我们回到最初调用tryMalloc的dvmMalloc()方法里去。在这个方法的最后,我们看到,如果最终内存分配失败的话,会调用throwOOME();也就是我们熟知的抛出OOM异常。
三、GC
在java世界中不同的虚拟机有各种各样的垃圾回收策略,具体可参见《深入理解java虚拟机》一书。Android采用标记-清理(Mark-Sweep)或者拷贝(Copping)的策略进行垃圾回收。Copping策略还没有研究,先说Mark-Sweep。
关于Mark-Sweep的简介可参见http://www.cnblogs.com/killmyday/archive/2013/06/12/3132518.html
总的来说, 就是在gc过程中对root set可达的所有对象进行标记mark,然后把剩下没有mark过的对象释放掉。期间不做压缩整理、不分代。Root set分为几类,具体参见
Dalvik中mark-sweep流程大概如下:
1. 在对象申请过程中记录所有已创建对象,用liveBits记录
2. 在GC过程中,首先对所有Root Set对象进行标记,用markBits记录 并放入MarkStack中
3. 遍历MarkStack, 对其中每个对象(都是root set)进行检查,对其引用的对象,即所谓可达对象进行标记,用markBits记录。
4. 至此,liveBits是所有创建过的对象,markBits是已标记的不可清理的对象。将两个集合进行比对,则为垃圾对象。
5. 在清理垃圾对象前,将liveBits = markBits,这样在清理过后, liveBits直接就是剩下的已创建对象了,就不用再次额外处理了。
6. 释放所有垃圾对象。
具体实现从刚刚tryMalloc中调用的gcForMalloc入手。
static void gcForMalloc(bool clearSoftReferences)
{
if (gDvm.allocProf.enabled) {
Thread* self = dvmThreadSelf();
gDvm.allocProf.gcCount++;
if (self != NULL) {
self->allocProf.gcCount++;
}
}
/* This may adjust the soft limit as a side-effect.
*/
const GcSpec *spec = clearSoftReferences ? GC_BEFORE_OOM : GC_FOR_MALLOC;
dvmCollectGarbageInternal(spec);
}在申请过程中没有完全用完最大限度的情况下, clearSoftReferences为false,这时spec为GC_FOR_MALLOC。这个GC_FOR_MALLOC是不是很熟悉?就是我们在程序的dalvik log里看到的那个GC_FOR_MALLOC。这里先不展开。随后调用dvmCollectGarbageInternal, 这是GC实现的主要方法了。
void dvmCollectGarbageInternal(const GcSpec* spec)
{
GcHeap *gcHeap = gDvm.gcHeap;
……
rootStart = dvmGetRelativeTimeMsec();
dvmSuspendAllThreads(SUSPEND_FOR_GC);
dvmHeapMarkRootSet();
……
dvmHeapScanMarkedObjects();
……
dvmHeapProcessReferences(&gcHeap->softReferences,
spec->doPreserve == false,
&gcHeap->weakReferences,
&gcHeap->finalizerReferences,
&gcHeap->phantomReferences);
dvmHeapSourceSwapBitmaps();
dvmHeapSweepUnmarkedObjects(spec->isPartial, spec->isConcurrent,
&numObjectsFreed, &numBytesFreed);
dvmHeapFinishMarkStep();
if (spec->isConcurrent) {
dvmLockHeap();
}
LOGD_HEAP("Done.");
dvmHeapSourceGrowForUtilization();
currAllocated = dvmHeapSourceGetValue(HS_BYTES_ALLOCATED, NULL, 0);
currFootprint = dvmHeapSourceGetValue(HS_FOOTPRINT, NULL, 0);
dvmMethodTraceGCEnd();
gcHeap->gcRunning = false;
LOGV_HEAP("Resuming threads");
/*
* Move queue of pending references back into Java.
*/
dvmEnqueueClearedReferences(&gDvm.gcHeap->clearedReferences);
……
}这个方法本身很长, 有很多细节值得探究, 本文先就主要的流程进行分析。
首先dvmSuspendAllThreads,会挂起所有的线程,就是说gc的过程中进是要阻塞的。
dvmHeapMarkRootSet();是mark所有的root sets对象。具体的root sets种类这个方法的注释上也有说明,就不再赘述了。看下方法的实现:
MarkSweep.cpp : dvmHeapMarkRootSet()
void dvmHeapMarkRootSet()
{
GcHeap *gcHeap = gDvm.gcHeap;
dvmMarkImmuneObjects(gcHeap->markContext.immuneLimit);
dvmVisitRoots(rootMarkObjectVisitor, &gcHeap->markContext);
}
dvmVisitRoots是具体标注过程。进去看一下:
Visit.cpp : dvmVisitRoots()
void dvmVisitRoots(RootVisitor *visitor, void *arg)
{
assert(visitor != NULL);
visitHashTable(visitor, gDvm.loadedClasses, ROOT_STICKY_CLASS, arg);
visitPrimitiveTypes(visitor, arg);
if (gDvm.dbgRegistry != NULL) {
visitHashTable(visitor, gDvm.dbgRegistry, ROOT_DEBUGGER, arg);
}
if (gDvm.literalStrings != NULL) {
visitHashTable(visitor, gDvm.literalStrings, ROOT_INTERNED_STRING, arg);
}
dvmLockMutex(&gDvm.jniGlobalRefLock);
visitIndirectRefTable(visitor, &gDvm.jniGlobalRefTable, 0, ROOT_JNI_GLOBAL, arg);
dvmUnlockMutex(&gDvm.jniGlobalRefLock);
dvmLockMutex(&gDvm.jniPinRefLock);
visitReferenceTable(visitor, &gDvm.jniPinRefTable, 0, ROOT_VM_INTERNAL, arg);
dvmUnlockMutex(&gDvm.jniPinRefLock);
visitThreads(visitor, arg);
(*visitor)(&gDvm.outOfMemoryObj, 0, ROOT_VM_INTERNAL, arg);
(*visitor)(&gDvm.internalErrorObj, 0, ROOT_VM_INTERNAL, arg);
(*visitor)(&gDvm.noClassDefFoundErrorObj, 0, ROOT_VM_INTERNAL, arg);
}可以看到会对每种root sets分别进行mark,其过程基本是一样的,选一个看下:
visitHashTable(visitor, gDvm.loadedClasses, ROOT_STICKY_CLASS, arg);
我们知道在android加载解析dex文件的阶段, 会将dex映射到内存中的DexFile的内存结构中, 随后对用到的类(在程序尚未启动时,一般为静态变量等)进行解析,和jvm类似, 解析过程中类的查找实际上就是字符串匹配的过程,为效率考虑, 将字符串转化为hash值, 因此loadedClasses实际上是个HashTable
static void visitHashTable(RootVisitor *visitor, HashTable *table,
RootType type, void *arg)
{
assert(visitor != NULL);
assert(table != NULL);
dvmHashTableLock(table);
for (int i = 0; i < table->tableSize; ++i) {
HashEntry *entry = &table->pEntries[i];
if (entry->data != NULL && entry->data != HASH_TOMBSTONE) {
(*visitor)(&entry->data, 0, type, arg);
}
}
dvmHashTableUnlock(table);
}就是遍历所有的对象, 并执行visitor。Visitor是个函数指针,我们回到上一级里去找其实现, 发现是个名为rootMarkObjectVisitor的函数
static void rootMarkObjectVisitor(void *addr, u4 thread, RootType type,
void *arg)
{
Object *obj = *(Object **)addr;
GcMarkContext *ctx = (GcMarkContext *)arg;
if (obj != NULL) {
markObjectNonNull(obj, ctx, false);
}
}看一下markObjectNonNull
static void markObjectNonNull(const Object *obj, GcMarkContext *ctx,
bool checkFinger)
{
if (obj < (Object *)ctx->immuneLimit) {
return;
}
if (!setAndReturnMarkBit(ctx, obj)) {
/* This object was not previously marked.
*/
if (checkFinger && (void *)obj < ctx->finger) {
/* This object will need to go on the mark stack.
*/
markStackPush(&ctx->stack, obj);
}
}
}首先调用setAndReturnMarkBit对对象进行mark,其内部最终调用的是HeapBitmapInlines.h:_heapBitmapModifyObjectBit()。 这个方法在对象申请过程调用的那个标注方法是一样的,但注意这里传入的参数是ctx->bitmap, 这个变量是在虚拟机初始化的时候在HeapSource.cpp的dvmHeapSourceStartup()方法里指定的,实际上就是markbits, 也就是说是把相应对象标注在markBits上。而在对象申请过程中调用这个方法时传入的参数是liveBits。
在标注后, 会调用markStackPush(&ctx->stack, obj); 将对象压入markStatck栈中。
回到dvmCollectGarbageInternal, 继续往下走, 会调用dvmHeapScanMarkedObjects()
void dvmHeapScanMarkedObjects(void)
{
GcMarkContext *ctx = &gDvm.gcHeap->markContext;
dvmHeapBitmapScanWalk(ctx->bitmap, scanBitmapCallback, ctx);
ctx->finger = (void *)ULONG_MAX;
processMarkStack(ctx);
}dvmHeapBitmapScanWalk保证所有root set对象都已压入栈中,随后调用processMarkStack()处理栈内对象。
static void processMarkStack(GcMarkContext *ctx)
{
GcMarkStack *stack = &ctx->stack;
while (stack->top > stack->base) {
const Object *obj = markStackPop(stack);
scanObject(obj, ctx);
}
}markStackPop每次弹出是栈顶的记录,然后调用scanObject()对对象进行扫描。
static void scanObject(const Object *obj, GcMarkContext *ctx)
{
if (obj->clazz == gDvm.classJavaLangClass) {
scanClassObject(obj, ctx);
} else if (IS_CLASS_FLAG_SET(obj->clazz, CLASS_ISARRAY)) {
scanArrayObject(obj, ctx);
} else {
scanDataObject(obj, ctx);
}
}不同类型有不同的扫描方法,这里我们关注一下普通对象的扫描, 就是scanDataObject, 进取看一下:
static void scanDataObject(const Object *obj, GcMarkContext *ctx)
{
markObject((const Object *)obj->clazz, ctx);
scanFields(obj, ctx);
if (IS_CLASS_FLAG_SET(obj->clazz, CLASS_ISREFERENCE)) {
delayReferenceReferent((Object *)obj, ctx);
}
}首先会对对象本身进行标注。随后调用scanFields(), 个人感觉这个scanFields是关键。此时扫描的每个对象就是Root Set, 扫描其field便是找到其引用的对象,就是Root Set可达的对象了。 在scanFields()方法里, 首先会取出所有field的应用的对象, 然后调用markObject(ref, ctx);并最终调用heapBitmapModifyObjectBit将对象标记到markBits中。
至此主要的标注流程已完毕, 随后会调用dvmHeapProcessReferences对week、soft、phantom类型的应用队列和实现了finalize的对象进行处理。
随后调用dvmHeapSourceSwapBitmaps();将MarkBits和liveBits进行互换, 这样清理过后就不用再对liveBits进行处理了。
然后调用dvmHeapSweepUnmarkedObjects()方法进行未标注对象,也就是垃圾对象的清理工作。
在这个方法中,因为markBits和liveBits之前进行了互换,所以会
prevLive = dvmHeapSourceGetMarkBits();
prevMark = dvmHeapSourceGetLiveBits();
即把live当作mark, 把mark当作live。
这个方法最终会调用mspace的mspace_bulk_free()方法进行释放。这里就不展开了。随后会调用HeapSource的countFree(), 对dvmHeapBitmapClearObjectBit进行更新。
至此GC的大致过程就完成了, 其实期间还有很多细节, 这里只是展现了GC的主要流程, 顺着这个主流程, 如果对某个点想详细研究, 可以再单独展开。
参考资料:
android dalvik vm alloc_林伟的博客-CSDN博客
http://heaven.branda.to/~thinker/GinGin_CGI.py/show_id_doc/385
dlmalloc:















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









