







目录
3.4 explain/desc 查看sql执行计划->评判性能
3.4.3 type 字段由好到差 null-system-const-eq_ref-ref-range-index-all
4.1.1 最左前缀法则 -> 必须包含最左边的索引->跳过中间索引后面索引失效
4.1.2 范围查询 (大于或小于)-> profession, age, status右边的会失效
4.2.1索引失效 -> key =null 表示没有用索引
4.4 or 连接 -> or两边都要有索引 ->解决 创建索引
4.6 SQL提示 ->单列索引和联合索引 ->自定义(use/ignore/force)
4.7 减少使用select * -> 容易产生回表查询 -> explain -> Extra中
4.7.1 检查是否回表查询 ->extra =null 没有回表
4.8.1 示例一 -> 多字段查询 建立联合查询 -> 避免回表查询
5.2 查询where 排序 order by 分组 group by 建索引
6.1.5 没有主键 没有唯一索引 自动生成rowid为聚集索引
2 索引语法
0 课程视频
1 查看索引
show index from user ;
show index from user\G ; -- 表竖向展示2 创建索引
-- 命名索引为 idx_user_name 默认B+TREE 显示为Btree
create index idx_user_name on user(name);
-- 创建唯一索引
create unique index idx_userphone on user(phone);
-- 创建联合索引 字段顺序有优先级?
create index idx_user_pro_age_sta on user(profession, age, status);
3 删除指令
drop index idx_user_phone on user;3 sql性能分析工具
3.1 指令查看分析 -> 查看频次
-- 七个下划线 代表七个字符
show global status like 'Com_______';
3.2 慢查询日志 ->定位出慢sql语句->修改
3.2.1 查看慢sql是否开启
-- 查看慢查询是否开启
show varialbes like 'slow_query_log' ; 3.2.2 修改配置文件
vi /etc/my.cnf
按 G 切换到 文档 末尾
#慢查询日志
#开启
slow_query_log=1
#超过两秒则记录
long_query_time=2
3.2.3 日志位置
cd /var/lib/mysql3.3 profile 展示sql耗时
3.3.1 设置profile
-- 查看当前是否支持profile
select @@have_profiling;
-- 打开
set profiling = 1;
3.3.2 使用profile
-- 显示各个sql语句耗时
show profiles ;
-- 显示指定sql语句的各个阶段的耗时情况 query_id 是上面查出来的id
show profile for query query_id;
-- 显示 某阶段的cpu 耗费情况
show profile cpu for query query_id; 3.4 explain/desc 查看sql执行计划->评判性能
3.4.0 课程视频
3.4.1 explain/desc 语法
desc select * from user where id = 1 ;
-- 或
explain select * from user where id = 1 ;3.4.2 多对多表的示例



3.4.3 type 字段由好到差 null->system->const->eq_ref->ref->range->index-all
优化往null 优化 -> 不查询表才会出现null ,一般位const 访问系统表是system
唯一索引 const
非唯一索引 ref
3.4.4 多对多表查询 分析 示例
-- 查询选修mysql 课程的学生
-- 1 course 中查课程id
select id from course c where c.name ='MySQL' ;
-- 2 student_coursex 中查学生id 通过上面查询到的id = 3
select studentid from student_course sc where sc.courseid = 3 ;
-- 3 strudent 中查询学生表 通过上面查询到的 1 2
select * from strudent s where s.id in(1,2) ;
-- 4 合并上面的语句查询
select * from strudent s where s.id in(select studentid from student_course sc where sc.courseid = select id from course c where c.name ='MySQL' ) ;
-- 5 分析执行语句的
explain select * from strudent s where s.id in(select studentid from student_course sc where sc.courseid = select id from course c where c.name ='MySQL' ) ;4 索引的使用
ps: 非索引字段 1000万数据耗时20s , 使用索引后0.001s
4.1 联合索引
4.1.1 最左前缀法则 -> 必须包含最左边的索引->跳过中间索引后面索引失效
-- 创建联合索引 字段顺序有优先级?
create index idx_user_pro_age_sta on user(profession, age, status);

 总结: 没有左边的第一个索引 就是全表查询
总结: 没有左边的第一个索引 就是全表查询
4.1.2 范围查询 (大于或小于)-> profession, age, status右边的会失效

ps:规避失效 大于等于 或 小于等于 就不会失效
4.2 索引列运算
4.2.1索引失效 -> key =null 表示没有用索引
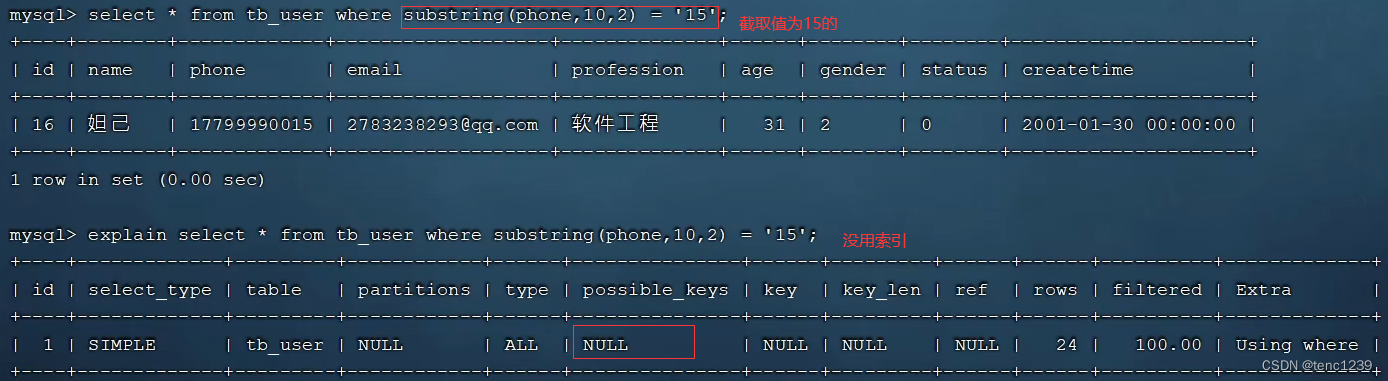
4.2.2 数据类型错误 不会用到索引
ps: 手机号字符串 但是查询是int 就不会用索引查询
4.2.3 数据类型错误例子
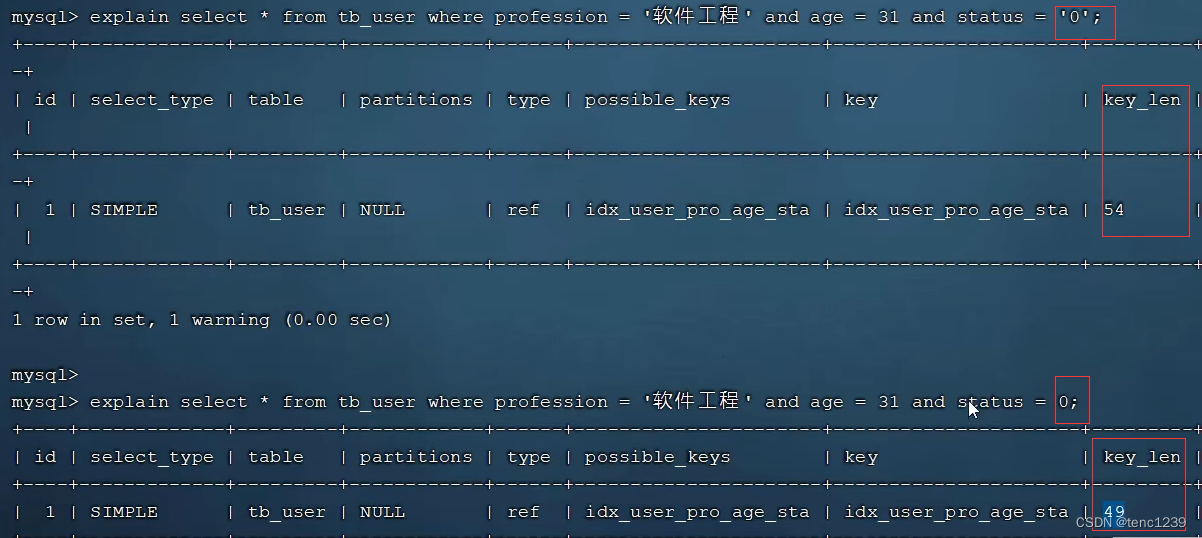
4.3 模糊查询
4.3.1 后模糊 走索引
select * from user where profession like '软件%' ;
-- 执行完查询后再执行
explain select * from user where profession like '软件%' ;4.3.2 前模糊/ 前后模糊 不走索引
--前模糊
select * from user where profession like '%工程' ;
-- 执行完查询后再执行
explain select * from user where profession like '%工程' ;
-- 前后模糊
select * from user where profession like '%工%' ;
-- 执行完查询后再执行
explain select * from user where profession like '%工%' ;4.4 or 连接 -> or两边都要有索引 ->解决 创建索引
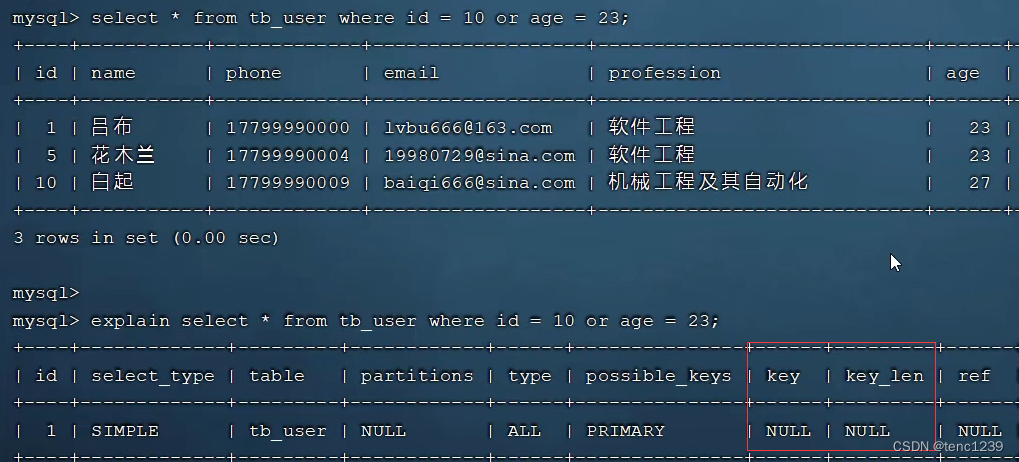
4.5 数据分布 会影响索引是否生效->引擎自动分析
4.6 SQL提示 ->单列索引和联合索引 ->自定义(use/ignore/force)
-- 指定建议用 sql不一定会用
use index ;
explain select * from user use(index idx_user_pro) where profession = 'java' ;
-- 忽略
ignore index ;
explain select * from user ignore index(index idx_user_pro)where profession = 'java' ;
-- 强制
force index ;
explain select * from user force index(index idx_user_pro) where profession = 'java' ;4.7 减少使用select * -> 容易产生回表查询 -> explain -> Extra中
4.7.1 检查是否回表查询 ->extra =using index condition 回表查询
Extra -->
Using where; Using index
-- 回表查询了
Extra --> Using where; Using condition4.7.2 覆盖查询 -> 二级索引查询没有回表查询

4.7.3 回表查询

4.7.4 聚集查询 用主键id查询
-- 聚集查询
select * from user where id = 1;
-- 二级索引查询返回 * -> 回表查询 -> 因为二级索引只能查到id 要返回* 就得回表查询
select * from user where name = 'jack' ;4.8 查询分析 与 查询语句设计
4.8.1 示例一 -> 多字段查询 建立联合查询 -> 避免回表查询
select id, username, password from user where username = 'jack' ;
--> id 不是主键?
--> username, password 建立联合索引
--> 返回 id 就不会 回表查询 4.9 前缀索引 -> 大文本/长字符串
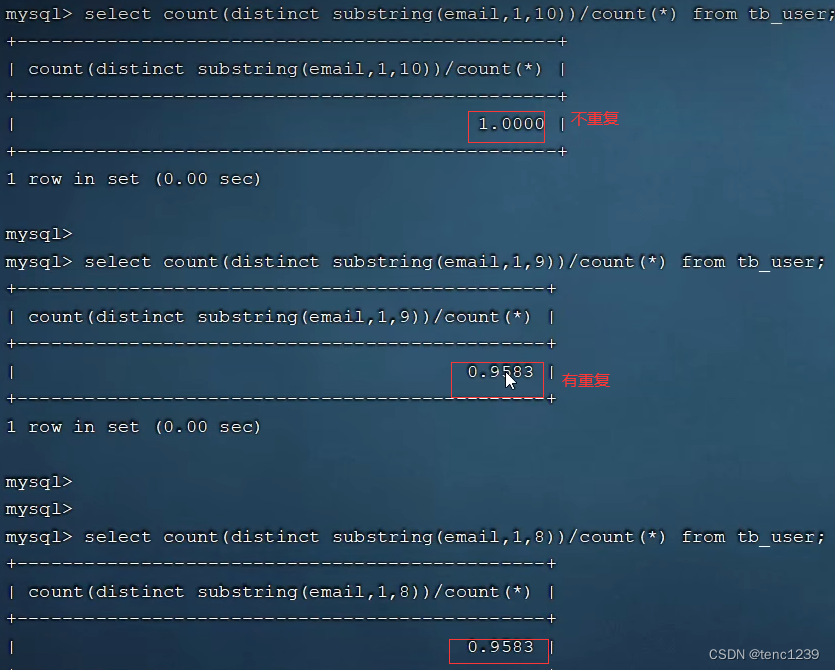
4.9.1 截取前缀计算方法
-- 计算不重复得个数
select count(distinct email) from user ;
-- 截取 从第一个字符 截取4个字符
substring(email,1,4)
-- 计算截取字符后 重复率 1为不重复 , 越小越重复
select count(distinct substring(email,1,4))/count(*) from user ;
4.9.2 前缀索引语法 / 使用
create index inx_email_5 on user(email(5));
-- 完整得email -> 自动截取 -> 查询结果和完整email 匹配
select * from user where email = 'xxxxx@qq.com';4.10 联合索引B+TREE图示

ps: 覆盖索引 查phone , name ,id 就不会回调查询















 1155
1155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









