






容量管理从本质来讲,主要需要解决的问题是系统“亚健康(有病,但还不影响生活和工作)”的情况下,我们能够及时知道,并做出对应策略,确保系统恢复到正常顺畅;本方案主要是讲的第一部分,“我们如何及时知道、并告警/预警”,不涉及到“容量处理策略”;
一.主要问题场景:
实时系统:
能提供服务,但是速度较慢;
随着业务的逐渐发展,一路上升都提供良好,但是离悬崖慢慢靠近(用一个举重运动员的话说,在压一块金牌在杠铃上,就倒了);
业务突发增长,导致短时间内,系统资源耗尽,服务质量严重下降;
离线系统:
随着业务的发展,在约定时间内逐渐无法完成任务(例如:1个小时跑一次的数据统计,随着业务增长,无法在1个小时内完成);
依据以上问题场景,数据容量系统定义以下目标,并以此目标为验收标准;
二.数据容量系统的目标:
核心目标:
容量实时监控;
容量按天日报,了解到目前系统在资源和业务方面的容量百分比,处理取于高负载的设备或者是模块;
附加目标:
成本控制,通过对低负载模块的展现,整合机器利用率,有效控制成本;
三.容量管理方案
针对实时系统,主要采用一下三种方式来达到要求:
自动化测试监控添加测速和时耗告警;(满足场景一、告警时间2分钟)
针对外网服务,自动化测试监控平台提供模拟用户角度从外网IP访问网页(目前主要是针对pay、积分、support、service四个外部网站),并且对时耗做了收集和告警;
针对后台服务,自动化测试监控平台提供模拟客户端从内网IP访问服务端,针对所有实时系统都添加了核心功能的自动化测试,并且对时耗也做了收集和告警;
针对基础资源的实时告警(满足场景三、告警时间5分钟)
针对基础资源的实时监控,主要有以下几种:
-
部门默认在tnm2平台上统一配置的告警策略
单机cpu使用率:使用率大于等于95%,连续20分钟,短信告警单机cpu负载: 负载大于等于4,连续20分钟,短信告警
单机应用内存使用率:使用率>85%,连续20分钟,短信告警
单机外网流量告警:
当前流量>=200%*上周同天同点,连续出现30分钟,则短信告警
当前流量<20%*上周同天同点,连续出现30分钟,则短信告警单机硬盘使用率:
使用率>95%,直接上报noc
使用率>90%, 预警发短信 -
针对OS层面,自行脚本资源配置
fd使用量:
单个进程,超过"ulimit -n"最大限定值的90%,则短信邮件告警机器负责人;内存使用量:
单个进程,物理内存使用量超过/bin/free | grep Mem | awk '{print $2}'的90%,则短信邮件告警机器负责人;swap使用量:
一台设备,若swap使用率超过1/2,则短信邮件告警机器负责人;共享内存使用量:
一台设备,若共享内存个数使用超过/usr/bin/ipcs -m -l | grep "number of segments"最大限定的90%,则短信邮件告警机器负责人;信号量使用量:
一台设备,若信号量使用超过/usr/bin/ipcs -s -l | grep "number of arrays"最大限定的90%,则短信邮件告警机器负责人;消息队列使用量:
一台设备,若消息队列使用超过/usr/bin/ipcs -q -l | grep "max queues system"最大限定的90%,则短信邮件告警机器负责人;消息队列未处理量:
一个消息队列,若未处理消息数>50个,则短信邮件告警机器负责人;tcp连接数数(
close_wait状态)
一台机器tcp连接数(close_wait状态)数量超过ulimit -n的最大限定值的60%,则短信邮件告警机器负责人;
采集容量数据,按天计算容量百分比,并预警已经取于高负载的模块和设备(满足场景二,预警时间1天)
-
容量采集数据以及方式:
硬件相关的基础资源:均可通过网管后台获取采样值。
关键指标:CPU使用率、CPU负载、外网入流量,外网出流量、应用内存使用率、磁盘利用率OS相关的基础资源:设备从本机作为特性上报到公司网管,容量从网管后台取得采样值;
关键指标:FD、TCP连接数、mysql连接数业务特性:设备从本机作为特性上报到公司网管,容量从网管后台取得采样值;
关键指标:请求量数、平均时耗、占用计算资源、失败率 -
计算每日负载值:
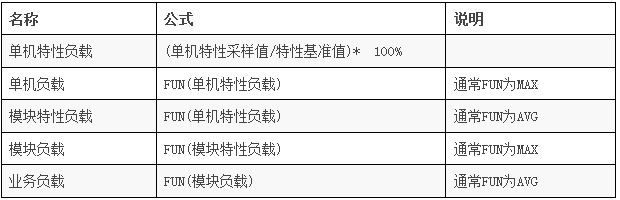
-
输出物:
设备负载日报(高负载管理、低负载管理)
业务模块负载日报
针对离线系统,主要采用以下方式要求:
离线任务执行时耗超过最大值,直接告警(满足场景五、告警时间2分钟;预警时间1天)
采用service收集离线任务开始时间、结束时间、执行时间标准
采用公共工具部署在每台服务器上,各自任务自行上报开始时间点,结束时间点
四.结束语
本方案仅仅涉及到“容量问题告警、预警”的内容,部门在这一块才刚刚起步,特别是问题出现之后的"定位、处理"还没有定论和统一解决方案,另外,容量管理系统的client端非常多,如何简单有效的管理这些client端也是个挑战。还希望大家能够有好的想法、建议,可以和hairy这边交流,让容量管理在“减少故障发生、降低故障影响”等方面发挥大作用。














 2261
2261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









