手写笔记

KMeans 算法实现
""" @File : k_means
@Author : BabyMuu
@Time : 2022/4/16 21:54
"""
import numpy as np
class KMeans:
def __init__(self, data, n_clusters, random_state=None):
self.data = data
self.n_clusters = n_clusters
self.n_examples = self.data.shape[0]
self.random_state = random_state
def train(self, max_iter=50):
centroids = self.center_init()
closest_centroid_ids = np.empty((self.n_examples, 1))
for _ in range(max_iter):
closest_centroid_ids = self.centroids_find_closest(centroids)
centroids = self.centroids_update(closest_centroid_ids)
return centroids, closest_centroid_ids
def center_init(self):
np.random.seed(self.random_state)
random_ids = np.random.permutation(self.n_examples)
centroids = self.data[random_ids[:self.n_clusters], :]
return centroids
def centroids_find_closest(self, centroid):
n_centroids = centroid.shape[0]
closest_centroids_ids = np.zeros((self.n_examples, 1))
for examples_index in range(self.n_examples):
distance = np.zeros((n_centroids, 1))
for centroid_index in range(n_centroids):
distance_diff = self.data[examples_index, :] - centroid[centroid_index, :]
distance[centroid_index] = np.sum(distance_diff ** 2)
closest_centroids_ids[examples_index] = np.argmin(distance)
return closest_centroids_ids
def centroids_update(self, closest_centroid_ids):
n_features = self.data.shape[1]
centroids = np.zeros((self.n_clusters, n_features))
for centroid_id in range(self.n_clusters):
closest_ids = closest_centroid_ids == centroid_id
centroids[centroid_id] = np.mean(self.data[closest_ids.flatten(), :], axis=0)
return centroids
聚类结果可视化
""" @File : draw_kmeans
@Author : BabyMuu
@Time : 2022/5/8 12:42
"""
import numpy as np
import pandas as pd
from scipy.cluster.vq import vq
def draw_kmeans(features, centroids, plt, k, title=None):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
code, distance = vq(features, centroids)
unique_code = pd.Series(code).unique()
for i in unique_code:
ndx = np.where(code == i)[0]
plt.plot(features[ndx, 0], features[ndx, 1], '*')
plt.plot(centroids[:, 0], centroids[:, 1], 'bo')
if title:
plt.title(title)
else:
plt.title(f'2维数据点聚类 k = {k}')
简单测试
""" @File : Demo
@Author : BabyMuu
@Time : 2022/5/8 12:15
# """
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from numpy.random import randn
from sklearn.datasets import make_circles, make_moons
from k_means import KMeans
from handwritten_algorithm_model.template.draw.draw_kmeans import draw_kmeans
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
FIGSIZE = (16, 12)
class1 = 12.5 + 5.6 * np.random.randn(500, 2)
class2 = np.random.randn(500, 2)
class3 = 5.6 * np.random.randn(500, 2)
features = np.vstack((class1, class2, class3))
features_2, target_2 = make_circles(n_samples=1000, factor=0.5, noise=0.1)
features_3, target_3 = make_moons(n_samples=1000, noise=0.1)
plt.figure(figsize=FIGSIZE)
feature_index = 0
title = ['球形', '环形', '半环形']
for feature in (features, features_2, features_3):
for i in range(2, 6):
kmeans = KMeans(feature, i)
centroids, variance = kmeans.train()
plt.subplot(3, 4, (i - 1) + feature_index * 4)
plot_title = f'{title[feature_index]}簇, k={i}'
draw_kmeans(feature, centroids, plt, i, plot_title)
feature_index += 1
plt.show()
可视化结果
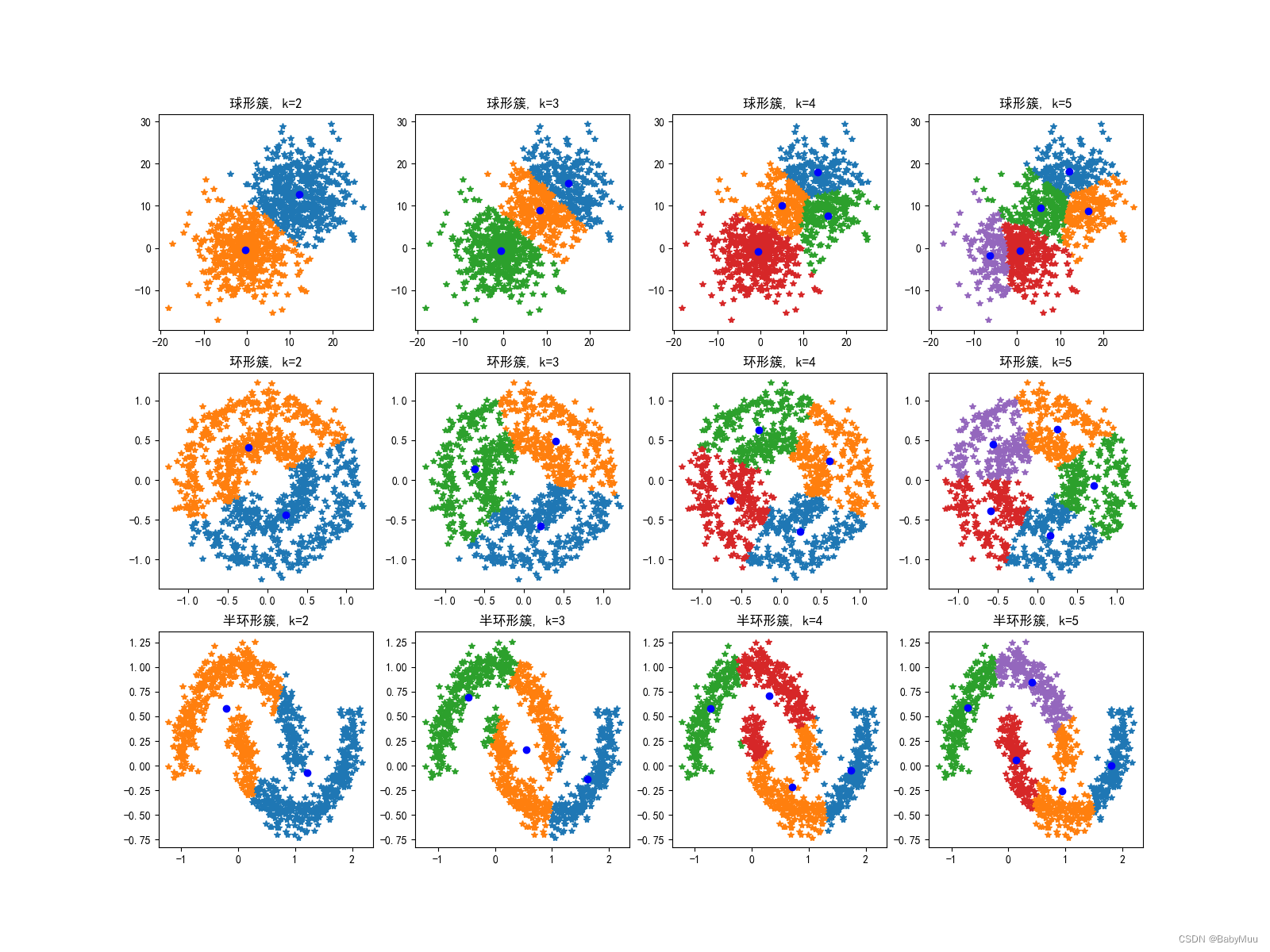
聚类结果分析
- 聚类的好坏与样本簇的形状有着很大的关系, 无法正确分辨环型簇, 半环型簇等非球形簇的形状样本























 253
253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









