







Hadoop
Hadoop 技术细节
HDFS
-
HDFS 是Hadoop提供的一套用于分布式存储的文件系统
-
为了方便使用 仿照Liunx系统设计的文件系统
-
HDFS的基本结构是典型的的主从结构- NameNode(主节点) 和 DataNode(从节点)
-
HDFS在存储文件的时候会将文件进行物理切分 - Hadoop2.0版本之后所切分的每一个Block是 128MB 1.0: 64MB
-
在HDFS中会自动的对数据进行备份, 这个备份称之为副本, 在完全分布式中默认的副本数量为3, 但在伪分布式场景中副本数量只能为1
-
常用命令
命令 功能 hadoop fs -put /home/hello.txt /hello.txt 将当前目录下的test.txt上传到HDFS的根目录下 hadoop fs -get /hello.txt /home/ 将HDFS根目录中的hello.txt 下载/home/文件夹下 hadoop fs -mkdir /log 在HDFS的根目录下创建一个名为log的文件夹 hadoop fs -mv /hello.txt /world.txt 重命名文件 hello.txt 为 world.txt hadoop fs -cp /hello.txt /hello.txt.bak 复制粘贴并重命名 hadoop fs -ls / 查看根目录下所有文件 hadoop fs -rmdir /log 删除文件夹(需该文件夹为空) hadoop fs -rm /log/test1.txt 删除文件
Block
- Block是HDFS中数据存储的基本单位, 即一个文件在HDFS中是由一个或者多个Block组成
- Block的大小默认是128MB
- 如果一个文件本身不到Block的大小, 那么这个文件是多大对应的BLock就是多大
- HDFS会对Block进行编号 — BlockID
- 切块的意义:
- 能够存储操大文件
- 能够快速的备份
NameNode
- NameNode 是HDFS中的主节点(核心)
- NameNode的职责:
- 管理DataNode
- 记录元数据(metadata)
- 元数据包含:
- 文件的存储位置
- 文件的权限
- 文件的大小
- Block的大小
- BlockID
- 副本数量
- BlockID和DataNode的映射关系
- 元数据是存储在磁盘和内存中
- 在内存中的目的是查询块
- 在磁盘中的目的是为了崩溃恢复
- NameNode通过心跳机制来管理DataNode
- 默认情况下DataNode发送心跳每隔3s给NameNode 发送心跳
DataNdoe - 从节点
- 负责数据的存储 - 存储的是 Block
- DataNode将Block村粗在磁盘上, 在磁盘上的位置是有hadoop.tmp.dir属性决定的, 会在dfs/data目录下存储
- DataNode会定时的向NameNOde发送心跳
SecondaryNameNode
- 到目前位置HDFS集群只能是NameNode + SecondaryNameNode结构或者双NameNode结构
- 实际开发中 采用的是双 NameNode结构
垃圾回收机制
-
在HDFS中回收站策略默认是不开启的, 即意味着删除文件这个操作会立即生效, 无法撤回
-
如果需要开启回收站策略那么需要在core-site.xml文件中配置
<!-- 配置回收站清理垃圾的间隔时间 --> <property> <!-- 表示垃圾放入回收站会暂存 --> <name>fs.trash.interval</name> <!-- 1440分钟 表示垃圾会放入回收站暂存一天 如果超过一天还没有被还原, 那么原则上就会被清理掉 --> <value>1440</value> </property> -
如果需要还原, 则需要执行命令
hadoop fs -mv hdfs://hadoop01:9000/user/root/.Trash/Current/text.txt /
Hadoop伪分布式配置
进入Hadoop的安装子目录 /etc/hadoop 配置hadoop
进入 hadoop 配置文件路径
配置静态ip
# 编辑网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
# 编辑文件内容
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static # 将dhcp(动态获取) 更改为static(静态ip)
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=a744833b-cd92-4d98-ad1c-a499148cb68e
DEVICE=ens33
ONBOOT=yes
HWADDR=00:0C:29:F2:5C:9D
# 设置静态ip信息
IPADDR=192.168.168.128
NETMASK=255.255.255.0
GATEWAY=192.168.168.2
DNS1=114.114.114.114
DNS2=8.8.8.8
# 重启网卡服务
service network restart
更改配置文件
配置hadoop-env.sh
# 进入编辑
vi hadoop-env.sh
更改内容
# 1. 配置JAVA_HOME的路径: 25
export JAVA_HOME=/home/software/jdk1.8
# 2. 配置HADOOP_CONF_DIR的路径: 33
export HADOOP_CONF_DIR=/home/software/hadoop-2.7.6/etc/hadoop
配置完成之后保存并退出之后重新生效:
source hadoop-env.sh
配置core-site.xml
-
编辑core-site.xml文件
添加配置:
<property> <!-- 指定HDFS的主节点 --> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <property> <!-- 执行hadoop运行时的数据存储目录 --> <name>hadoop.tmp.dir</name> <value>/home/software/hadoop-2.7.6/tmp</value> </property>
配置hdfs-site.xml
-
编辑hdfs-site.xml文件
-
添加配置:
<property> <!-- 设置HDFS的副本数量 --> <!-- 在伪分布式的场景下副本数量只能为1 --> <name>dfs.replication</name> <value>1</value> </property>
配置mapred-site.xml
-
将mapred-site.xml.template复制为mapred-site.xml:
cp mapred-site.xml.template mapred-site.xml -
编辑mapred-site.xml并且添加配置
<property> <!-- 指定将MapReduce程序在Yarn上运行 --> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
编辑yarn-site.xml
-
编辑yarn-site.xml:
vim yarn-site.xml -
添加配置:
<property> <!-- 指定Yarn的主节点 --> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <!-- NodeManager的数据获取方式 --> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
编辑slaves
-
添加从节点信息:
hadoop01
配置profile
编辑hadoop的环境变量
# hadoop
export HADOOP_HOME=/home/software/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使其重新生效
source /etc/profile
格式化NameNode
hadoop namenode -format
启动Hadoop
start-all.sh
hadoop启动后进程
10449 Jps
9907 SecondaryNameNode
9620 NameNode
9718 DataNode
10056 ResourceManager
10152 NodeManager
可以通过在浏览器上输入http://192.168.112.128:50070/访问web监控页面.
zookeeper
安装
单机模式
1. 关闭防火墙
2. 解压Zookeeper的安装包
1. tar
3. 进入配置目录
```shell
cd /home/software/zookeeper-3.4.7/conf
```
4. 编辑配置文件
1. 编辑 **zoo_sample.cfg**
1. 复制并重命名 cp zoo_sample.cfg zoo.cfg
2. 编辑**zoo.cfg**文件
```shell
:12
dataDir=/home/software/zookeeper-3.4.7/tmp
```
5. 启动zookeeper
```shell
sh zkServer.sh start
```
6. 检查zookeeper状态
```shell
sh zkServer.sh status
```
7. 进入客户端
```shell
sh zkCli.sh
```
8. 查看文件目录
```shell
ls /
# [zookeeper]
```
9. 关闭zookeeper进程
```shell
sh zkServer.sh stop
```
完全分布式
# 主节点分发zookeeper文件
# 默认分发的zookeeper已经配置好了zoo.cfg 的 datadir字段
scp -r zookeeper-3.4.7 root@hadoop03:/home/software/
# 编辑conf/zoo.cfg:
# 在最下方添加内容
server.1=192.168.61.130:2888:3888
server.2=192.168.61.128:2888:3888
server.3=192.168.61.129:2888:3888
# 编辑tmp/myid:
添加每个节点的序号
# 启动集群
# 进入bin目录同时执行以下命令
sh zkServer.sh start
# 查看集群状态
sh zkServer.sh status
# 如果出现两种mode: 俩follower 和一个 leader 即为成功启动
Hadoop完全分布式
1. 三个节点关闭防火墙
2. 三个节点修改主机名称
1. 编辑文件**hostnames**:
```shell
# 打开并编辑对应文件
vi /etc/hostnames
# 修改为对应的主机名
hadoop01
hadoop02
hadoop03
```
2. 编辑文件**hosts**, 设置地址映射
```shell
# 打开并编辑对应文件
vim /etc/hosts
# 添加内容
192.168.61.130 hadoop01
192.168.61.128 hadoop02
192.168.61.129 hadoop03
```
3. 三个节点重新启动用于加载系统配置
4. 三个节点需要配置免密互通
# 三个节点同时操作
# 生成秘钥
ssh-keygen
# 分发秘钥
ssh-copy-id root@hadoop01
ssh-copy-id root@hadoop02
ssh-copy-id root@hadoop03
# 测试 依次执行
ssh hadoop02
ssh hadoop03
ssh hadoop01
# 退出
exit
5. 更改配置文件
编辑hadoop-env.sh
# 进入编辑
vi hadoop-env.sh
更改内容
# 1. 配置JAVA_HOME的路径: 25
export JAVA_HOME=/home/software/jdk1.8
# 2. 配置HADOOP_CONF_DIR的路径: 33
export HADOOP_CONF_DIR=/home/software/hadoop-2.7.6/etc/hadoop
配置完成之后保存并退出之后重新生效:
source hadoop-env.sh
编辑slaves
-
添加从节点信息:
hadoop01 hadoop02 hadoop03
编辑core-site.xml
-
编辑core-site.xml文件
添加配置:
<property> <!-- 指定在Zookeeper上注册的节点名称 --> <name>fs.defaultFS</name> <value>hdfs://ns</value> </property> <property> <!-- 执行hadoop运行时的数据存储目录 --> <name>hadoop.tmp.dir</name> <value>/home/software/hadoop-2.7.6/tmp</value> </property> <property> <!-- 制定Hadoop数据存储的目录 --> <name>ha.zookeeper.quorum</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property>
编辑hdfs-site.xml
-
编辑hdfs-site.xml文件
-
添加配置:
<property> <!-- 绑定在Zookepser上注册的节点名称 --> <name>dfs.nameservices</name> <value>ns</value> <!-- 与core-site.xml中配置的fs.defaultFS的value相同 --> </property> <property> <!-- ns集群下有两个namenode,分别为nn1, nn2 --> <name>dfs.ha.namenodes.ns</name> <value>nn1,nn2</value> </property> <property> <!-- nn1的RPC通信 --> <name>dfs.namenode.rpc-address.ns.nn1</name> <value>hadoop01:9000</value> </property> <property> <!-- nn1的http通信 --> <name>dfs.namenode.http-address.ns.nn1</name> <value>hadoop01:50070</value> </property> <property> <!-- nn2的RPC通信地址 --> <name>dfs.namenode.rpc-address.ns.nn2</name> <value>hadoop02:9000</value> </property> <property> <!-- nn2的http通信地址 --> <name>dfs.namenode.http-address.ns.nn2</name> <value>hadoop02:50070</value> </property> <property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <name>dfs.journalnode.edits.dir</name> <value>/home/software/hadoop-2.7.6/tmp/journal</value> </property> <property> <!-- 指定namenode的元数据在JournalNode上存放的位置, 这样,namenode2可以从journalnode集群里的指定位置上获取信息, 达到热备效果 --> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/ns</value> </property> <property> <!-- 开启NameNode故障时自动切换 --> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <!-- 配置失败自动切换实现方式 --> <name>dfs.client.failover.proxy.provider.ns</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <!-- 配置隔离机制 --> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <!-- 使用隔离机制时需要ssh免登陆 --> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <!--配置namenode存放元数据的目录,可以不配置,如果不配置则默认放到hadoop.tmp.dir下--> <name>dfs.namenode.name.dir</name> <value>file:///home/software/hadoop-2.7.6/tmp/hdfs/name</value> </property> <property> <!--配置datanode存放元数据的目录,可以不配置,如果不配置则默认放到hadoop.tmp.dir下--> <name>dfs.datanode.data.dir</name> <value>file:///home/software/hadoop-2.7.6/tmp/hdfs/data</value> </property> <property> <!--配置副本数量--> <name>dfs.replication</name> <value>3</value> </property> <property> <!--设置用户的操作权限,false表示关闭权限验证,任何用户都可以操作--> <name>dfs.permissions</name> <value>false</value> </property>
编辑yarn-site.xml
-
编辑yarn-site.xml:
vim yarn-site.xml -
添加配置:
<!--配置yarn的高可用--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--指定两个resourcemaneger的名称--> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!--配置rm1的主机--> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop01</value> </property> <!--配置rm2的主机--> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop03</value> </property> <!--开启yarn恢复机制--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--执行rm恢复机制实现类--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <!--配置zookeeper的地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property> <!--执行yarn集群的别名--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>ns-yarn</value> </property> <!-- 指定nodemanager启动时加载server的方式为shuffle server --> <property> <!-- NodeManager的数据获取方式 --> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定resourcemanager地址 --> <property> <!-- 指定Yarn的主节点 --> <name>yarn.resourcemanager.hostname</name> <value>hadoop03</value> </property>编辑mapred-site.xml
-
将mapred-site.xml.template复制为mapred-site.xml:
cp mapred-site.xml.template mapred-site.xml -
编辑mapred-site.xml并且添加配置
<property> <!-- 指定将MapReduce程序在Yarn上运行 --> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
-
编辑mapred-site.xml
-
将mapred-site.xml.template复制为mapred-site.xml:
cp mapred-site.xml.template mapred-site.xml -
编辑mapred-site.xml并且添加配置
<property> <!-- 指定将MapReduce程序在Yarn上运行 --> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
编辑profile
编辑hadoop的环境变量
# hadoop
export HADOOP_HOME=/home/software/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使其重新生效
source /etc/profile
6. 将配置好的hadoop分发给其余节点
scp -r hadoop-2.7.6 root@hadoop02:/home/software/
scp -r hadoop-2.7.6 root@hadoop03:/home/software/
7. 集群启动
1. 启动Zookeeper集群
cd /bin
sh zkServer.sh start
2. 在第一个节点格式化Zookeeper
hdfs zkfc -formatZK
3. 在三个节点上启动JournalNode
hadoop-daemon.sh start journalnode
4.在第一个节点上格式化NameNode
# 如果节点中存在tmp目录
# 则删除对应目录
hadoop namenode -format
5. 在第一个节点上启动NameNode
hadoop-daemon.sh start namenode
6. 在第二个节点上格式化NameNode
hadoop namenode -bootstrapStandby
7.在第二个节点上启动NameNode
hadoop-daemon.sh start namenode
8.三个节点启动DataNode
hadoop-daemon.sh start datanode
9.在第一个节点和第二个节点启动FailOverController
hadoop-daemon.sh start zkfc
10.在第三个节点上启动Yarn
start-yarn.sh
11.在第一个节点上启动Resourcemanager
yarn-daemon.sh start resourcemanager
15.查看进程
第一个节点jps数据
在这里插入图片描述
第二个节点jps数据
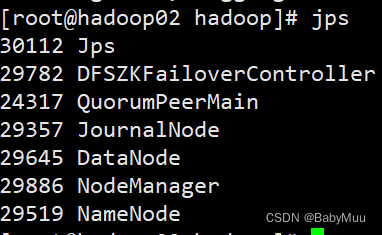
第三个节点jps数据
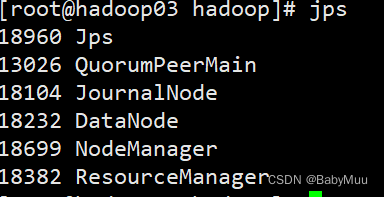
8. 集群关闭
1. stop-all.sh
关闭Hadoop服务
2. 进入Zookeeper的bin目录
执行 sh zkServer.sh stop 关闭Zookeeper服务















 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









