




 本文探讨了Windows和Linux环境下UTF8编码的区别,特别是关于BOM(Byte Order Mark)的存在与否及其对文件编码识别的影响。
本文探讨了Windows和Linux环境下UTF8编码的区别,特别是关于BOM(Byte Order Mark)的存在与否及其对文件编码识别的影响。
编码-Windows中UTF8与BOM
之前有个同事写业务逻辑时出现了乱码。
乱码,本来不是问题,问题是如何去“以恰当的方式”去将乱码翻译成可读的内容。
我们部门的软件Linux/Unix上运行的,业务侧的同事很多时候不习惯使用这样的环境,他们通常在Windows下编辑业务文件,再使用一些工具将文件传输到Linux下。
假设在Windows下保存为UTF8,然后传到Linux下会是什么效果呢?
1.
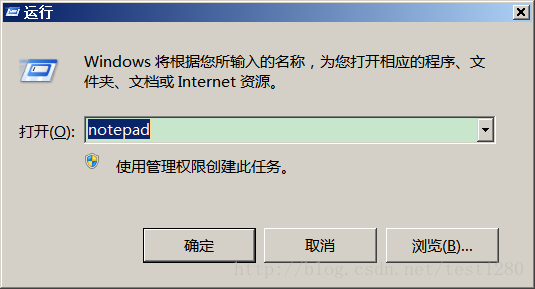
2.
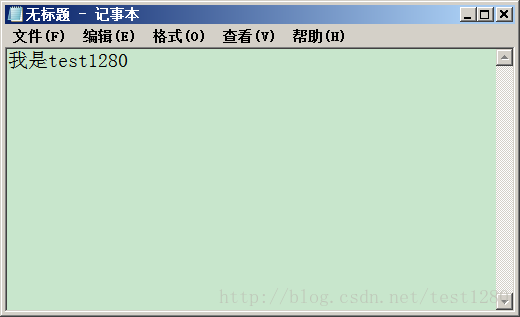
3.
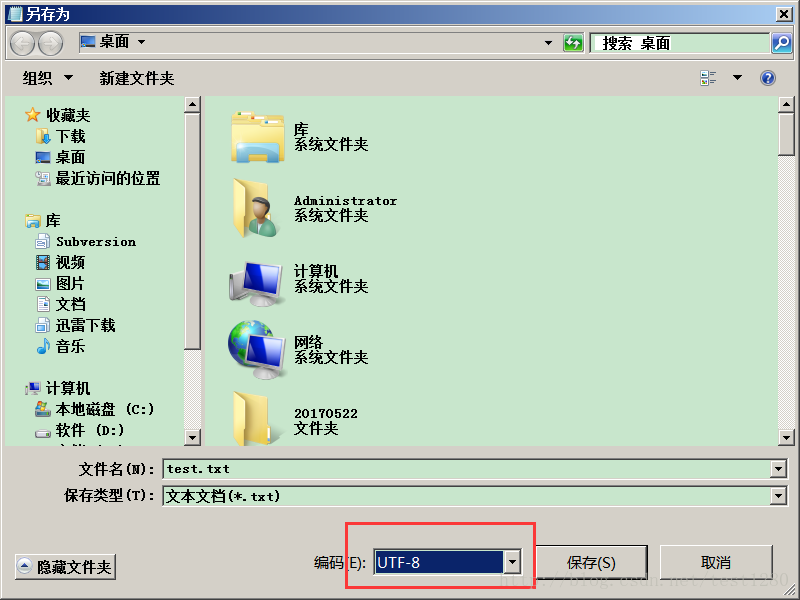
4.
上传test.txt到Linux下,然后使用file查看:
[jiang@eb50 ~]$ ll test.txt
-rw-r--r-- 1 jiang jiang 17 06-12 20:22 test.txt
[jiang@eb50 ~]$ file test.txt
test.txt: UTF-8 Unicode text, with no line terminators5.
使用vi打开,看到前面有:

6.
我们直接看十六进制:
:%!xxd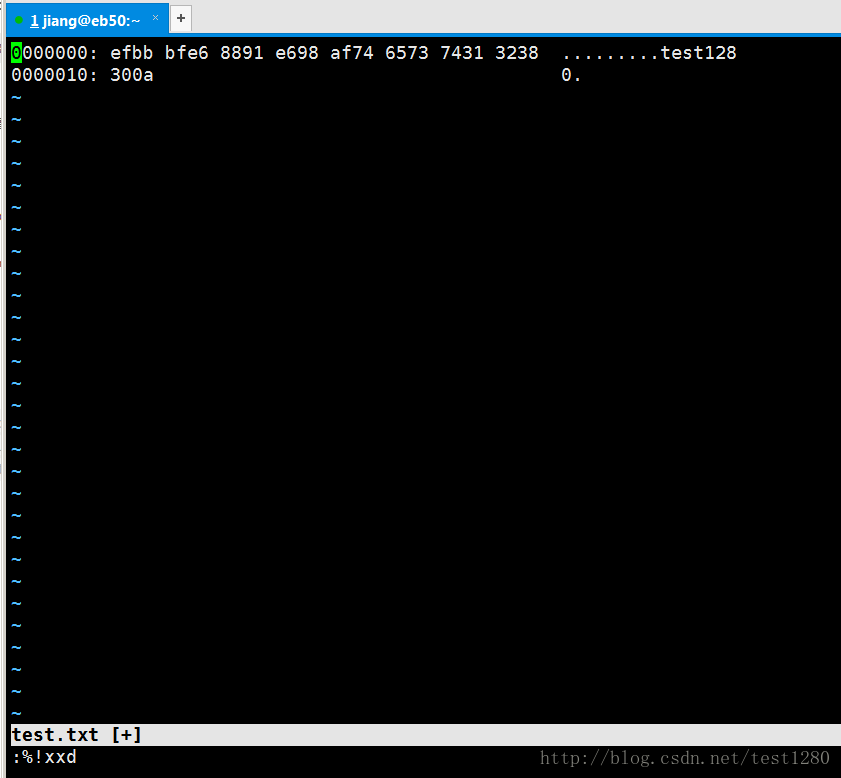
注意开头的三个字节:
EF BB BF。
这就是BOM标记(字节顺序标记—Byte Order Mark)。
注:实际上EF BB BF只是一种BOM标记。
所以要记得,在Windows下编辑的文件如果是Unicode,拉到Linux下,可能并不是纯粹的!
那什么是纯粹的?
我现在的环境是:
[jiang@eb50 ~]$ echo $LANG
en_US.UTF-8终端也是UTF8编码==》
[jiang@eb50 ~]$ echo "我是test1280" >> test_pure.txt
[jiang@eb50 ~]$ file test_pure.txt
test_pure.txt: UTF-8 Unicode text然后看看test_pure.txt的码流:
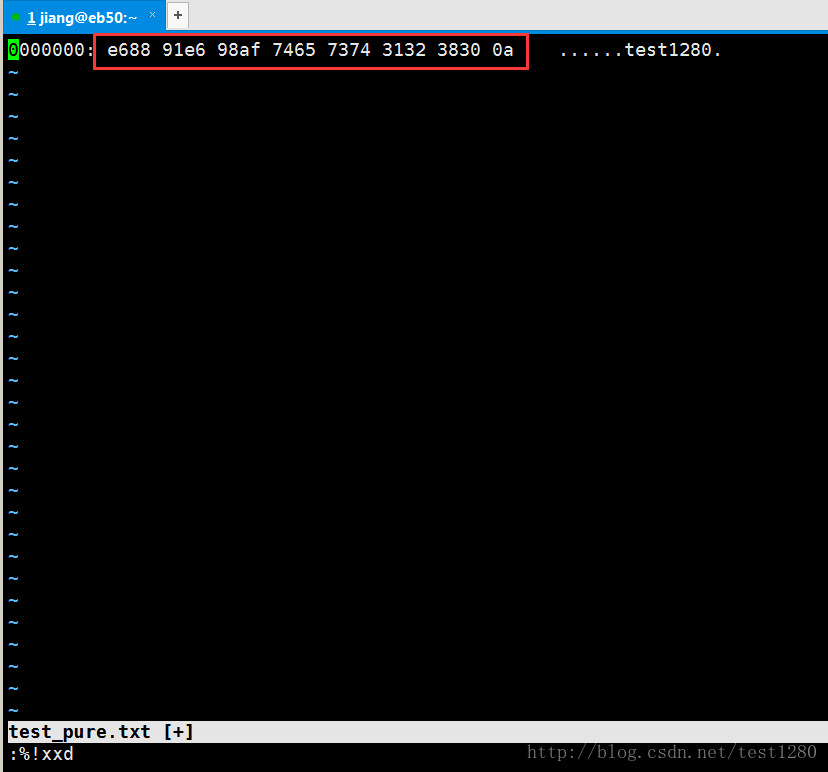
这下子更清楚了吧?在Linux直接编辑是没有BOM标记的。
BOM有啥用?
BOM是放在文件最开头的一段标记,通过这段标记可以知道文件是按大端还是小端编码的,主要是在类似UTF16编码中会使用,因为涉及到了字节序的问题。(具体过两天再写Blog专门讨论下)
UTF8的编码单元是单字节,本来不需要BOM作标记,因为UTF8在传输中没有大小端的问题。
可是,可是,你想过吗?
Windows中的文本都是txt作为后缀名,假设有一个文件是UTF8编码,有一个是GBK编码,那么Windows如何帮我们正确地显示出来呢?Windows是怎么知道文件是什么编码的呢?
这里就是使用了BOM来表明这个文件是UTF8编码的。
当我们从文件描述符中读取数据时,如果收到的前三个字节是EF BB BF,那么我们也就知道这一段文字是UTF8啦~
总结:
1.UTF8编码,在Windows下使用记事本编辑保存,实际上是携带BOM前缀的;
2.EF BB BF只是一种BOM,还有别的BOM标记;
3.Windows是通过对BOM的识别来确认是否是UTF8文件的;
疑问:
1.我发现个问题:如果把刚刚的test_pure.txt传回Windows下,使用记事本打开还是可以正确显示文本的,也就是说Windows可能不仅仅通过前三个字节是否是EF BB BF来决定文件编码,有可能是其他方式。

















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









