







1:从搜狗下载选择的细胞词库,这里下载动漫区的火影忍者词库
http://pinyin.sogou.com/dict/
2:用深蓝词库转换工具提取出txt文本,深蓝词库的下载地址
https://github.com/studyzy/imewlconverter/releases

转换后会获得这一的一个文件

3:用ultraedit将txt文本保存为无bom utf-8格式
从这里开始有歧义,先来看Lucene里怎么使用:
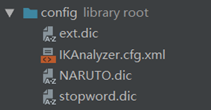
将文件名修改为后缀为.dic的英文名文件,丟到项目的配置文件夹中,在IKAnalyzer.cfg.xml文件里链接该文件就好,比如这里改名为NARUTO.dic
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<entry key="ext_dict">NARUTO.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典,就是配置那些词不要了-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
执行的时候虽然后台打印是这样的,但实际上ext和NARUTO都加在了

这边是在Solr里如何用
4:在solr的WEB-INF下创建classes目录
5:将utf-8格式的txt词库拷贝到solr的WEB-INF/classes目录
6:在WEB-INF/classes创建IKAnalyzer.cfg.xml,内容:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer ????</comment>
<!--????????????????
<entry key="ext_dict">/mydict.dic;</entry>
-->
<!--???????????????????-->
<entry key="ext_dict">/mydict.dic;</entry>
<entry key="ext_stopwords">/ext_stopword.dic</entry>
</properties>















 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









