






大家好我是阿道夫!!!早在几年前甚至是现在都流行着将真人照片转化为动漫风格的潮流,以前的方法是通过手绘或者PS等图像编辑工具来实现。
现在Stable Diffusion也能做到把一张真人的照片转绘成动漫风格,在保持人物大概形象不变的同时为图片添加合适的背景。

**时间仓促(有点糙)
**
WebUI的操作(流程演示)
这种操作在WebUI里面不算难,大概一分多钟就能完成这样的操作。
1、首先找一张想要进行转变的图,为了比较好进行操作我找了一张总体颜色比较素的照片。

**Merjic老师模型的经典封面
**
然后查看这张图片的原始尺寸比例,并且在WebUI中调节生成的尺寸。

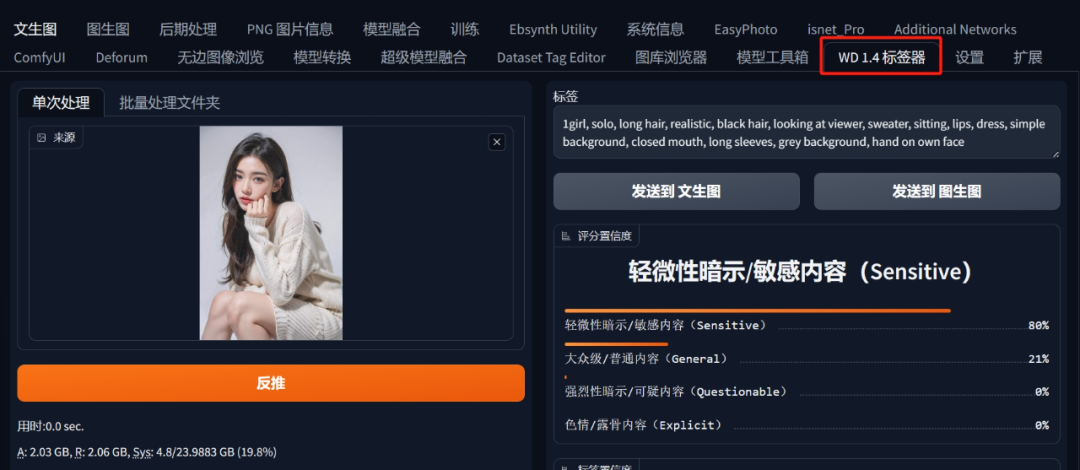
2、这里需要去到Tagger这类提示词反推工具里进行该图片的提示词识别,然后点击发生到文生图将结果直接导入到文生图界面中
3、在导入之后就可以更换一个想要的动漫画风的大模型,并且选择自己喜欢LoRA。
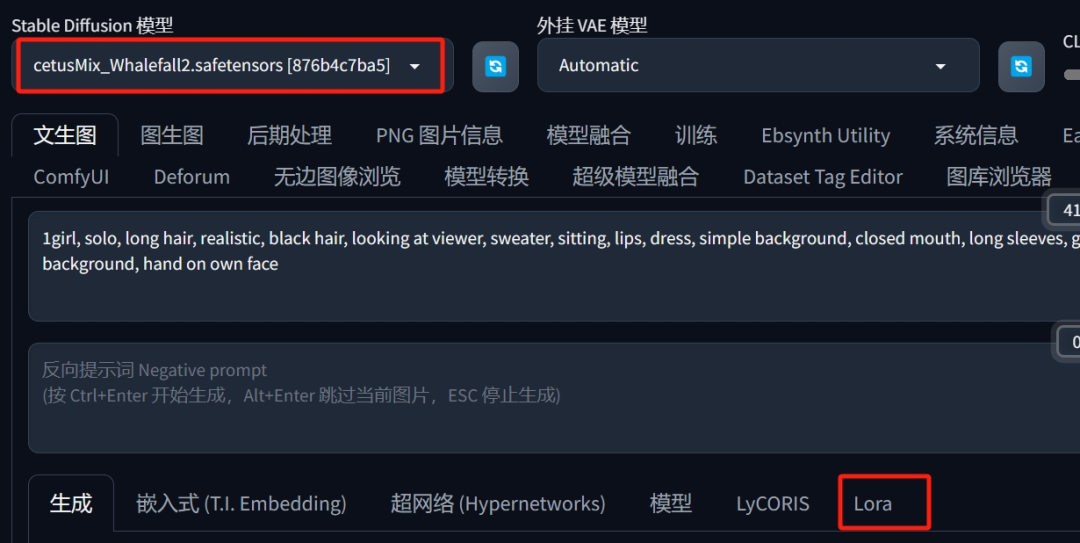
如果选择的LoRA模型不多的话就不需要花费太多时间在调节模型质感和权重上,由于我选的这个Checkpoint整体风格我蛮喜欢的,所以这里我就不额外添加LoRA了。
如果有额外添加风格类LoRA的话,还需要将触发的提示词粘贴到提示词框里。负面提示词不知道要怎么写的话可以直接照搬这个:
easynegative, lowres, text, error, extra digit, fever digits, cropped, (worst quality:1.2), low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, lowres graffiti,
4、一般的话需要开启ControlNet来控制诸如人物姿势、线条轮廓等图片的关键特征。
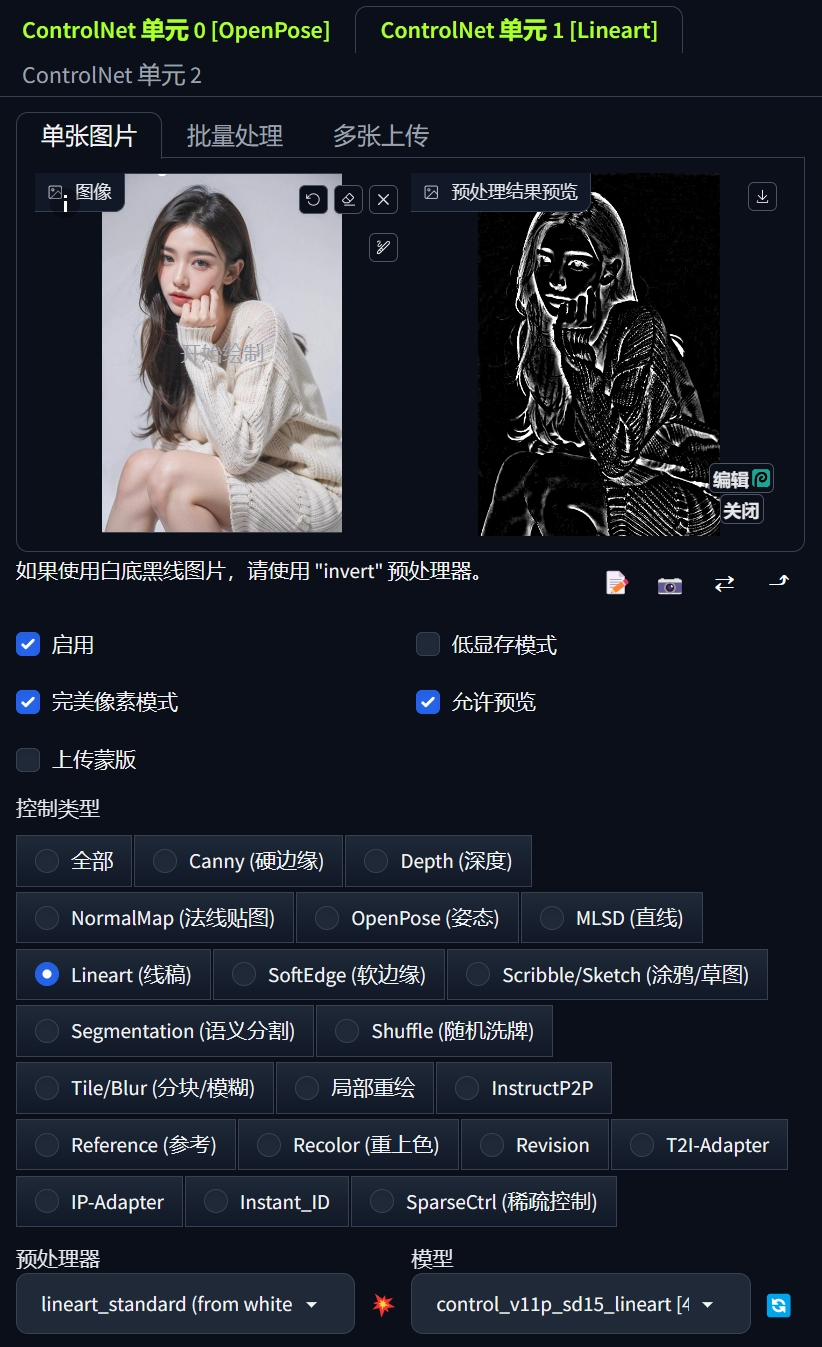
这里选择开启的是OpenPose和Lineart两个预处理器,权重可以根据自己的需要进行调节,没有的话维持默认就行。
5、点击生产,然后就可以在文生图里面得到一张成品图了。
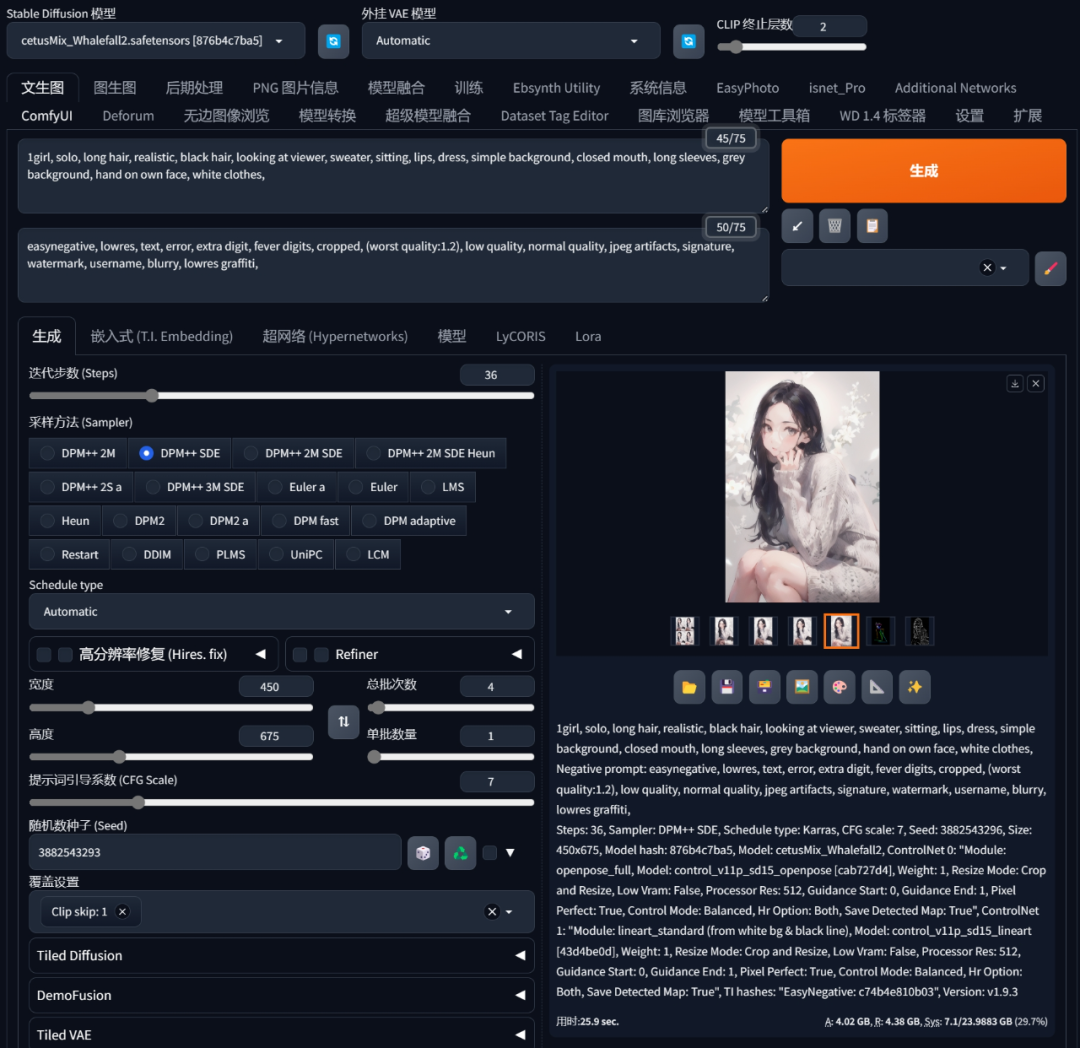
因为初始的图片分辨率并不高,所以还需要再做一个额外的放大处理。
6、点击图片下方的发送到图生图按钮。
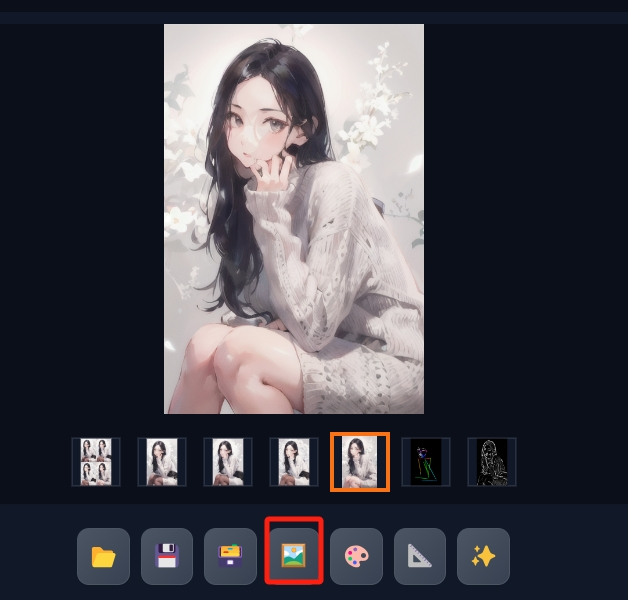
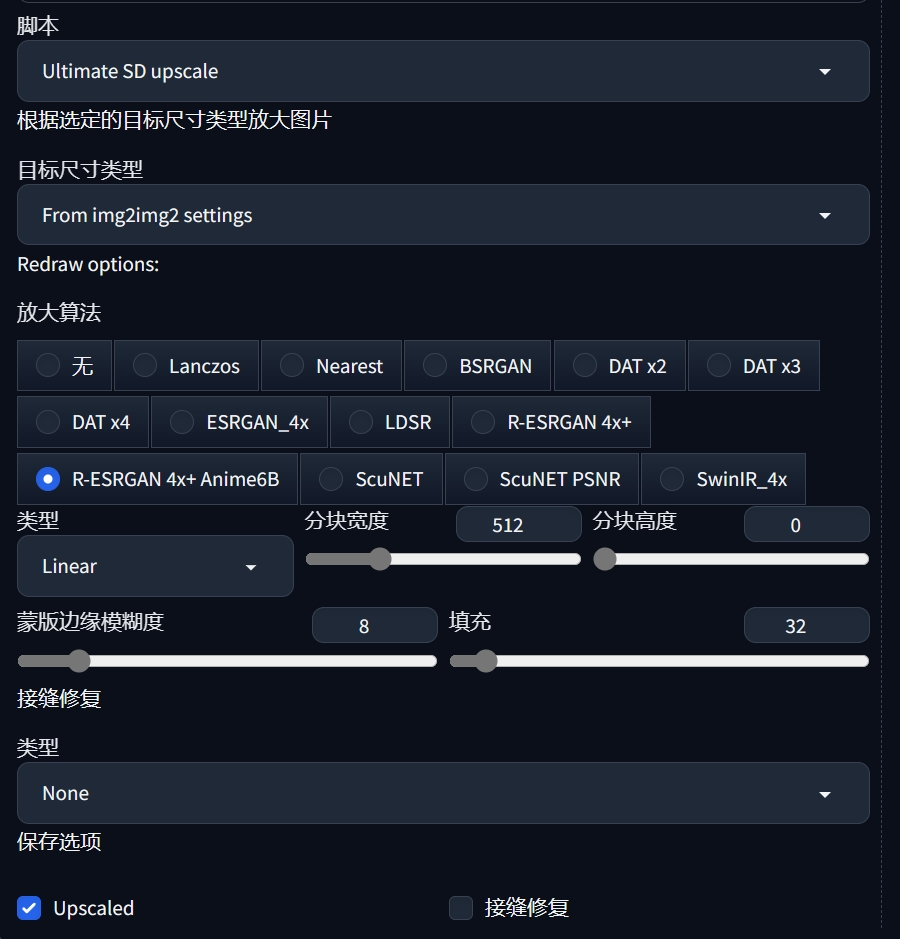
然后拉到最下方的脚本那里,选择Ultimate upscale或者ControlNet Tile这类工具进行参数的设置。
7、之后点击生成,这个过程大概持续一分钟左右。
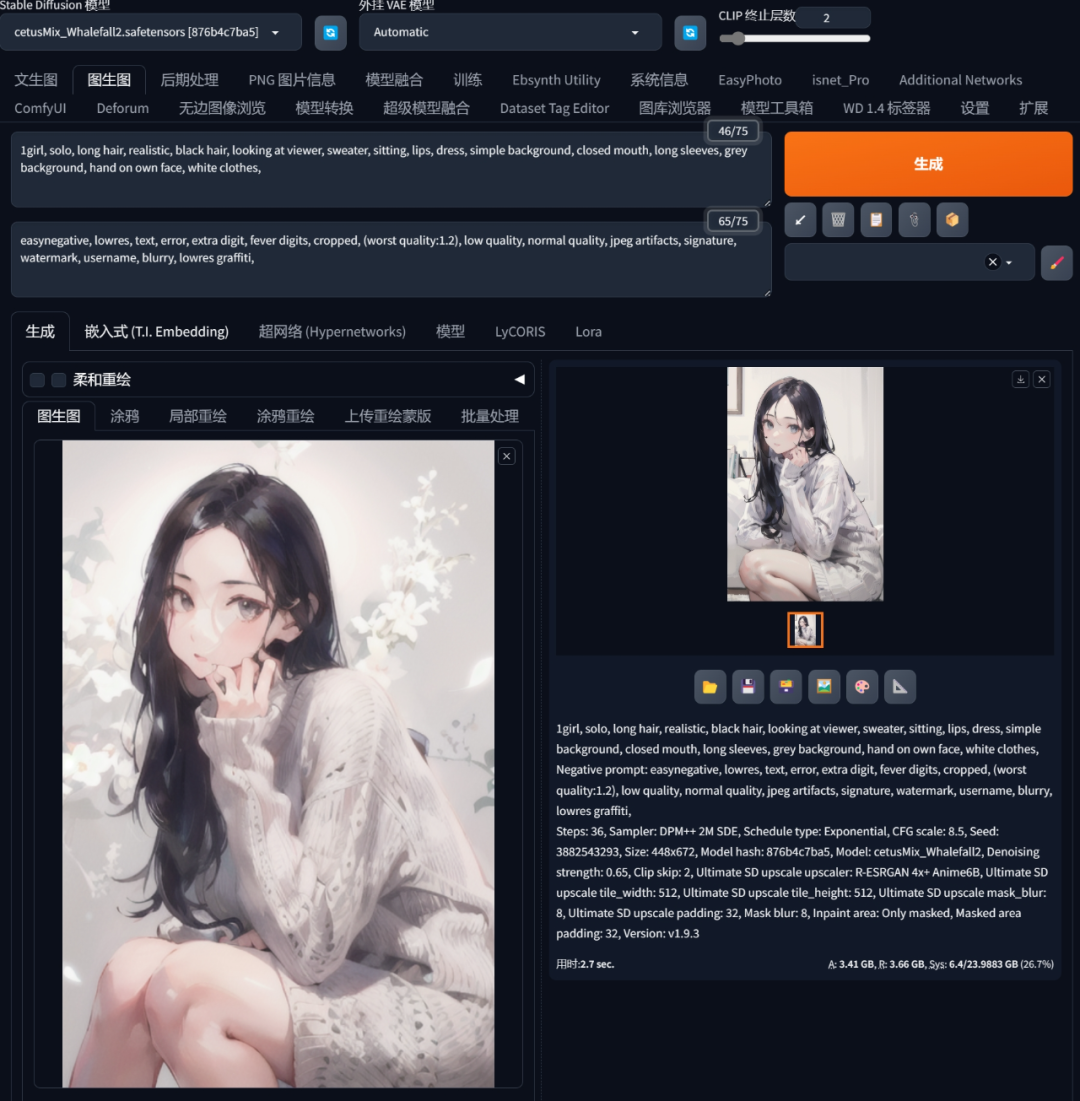
当然这个只是简单的流程演示,如果想要修改细节错误整体更好看的话还需要反复生成修改(我这一次性生成的细节就有问题,就需要再修改)。


如果后续要做几十张甚至近百张的话,这个时间成本其实是很高的。如果背景比较喜欢不想变动,只想改变人物风格的话还得去局部重绘里手动涂鸦一下蒙版。

ComfyUI的操作
(连线连得头大,需要的同学可以自行扫描获取)

在进入ComfyUI的时候都会自动加载上次做图的进度,这里直接选择Clear掉然后Load Default,这样ComfyUI就会自动加载出一个默认的文生图工作流。
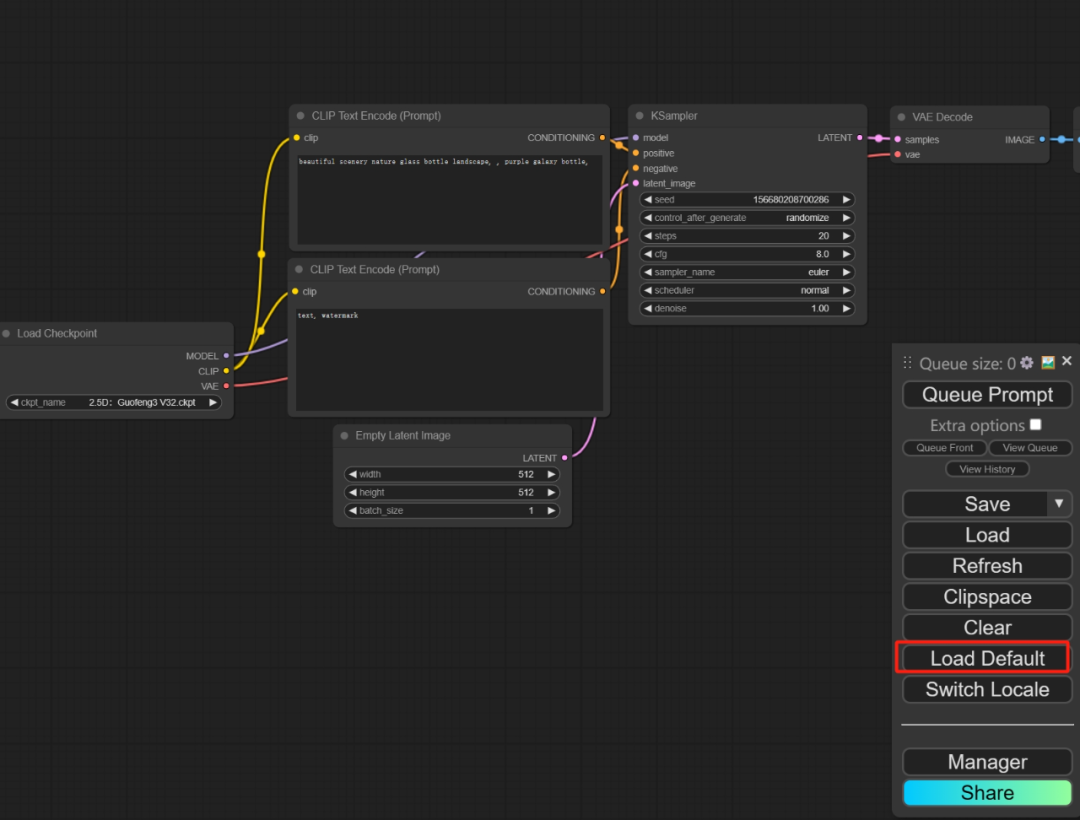
1、双击空白处搜索选择一个加载图片Load Image的节点,然后把初始图片导入其中。
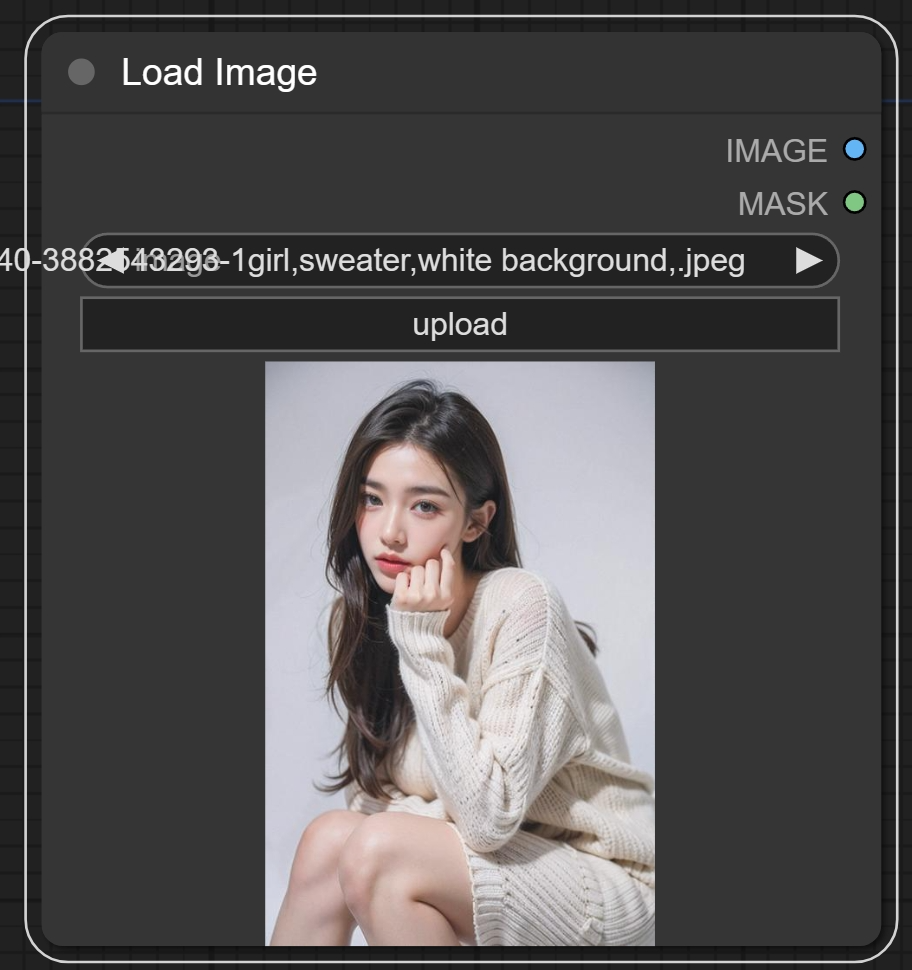
2、如果上篇文章中有下载额外的节点包的话,可以搜索一个Get Image Size节点,将Load Image的IMAGE与Get Image Size的image进行连接。
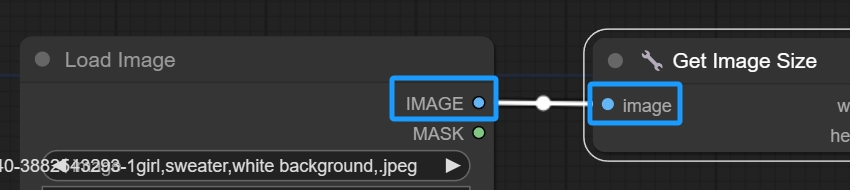
然后找到Empty Latent Image节点,这个节点是WebUI中的生成图片尺寸选项,在改节点鼠标右键选择Convert width to input和Convert heighty to input,这样就可以把宽和高转变为两个可以连接的点。
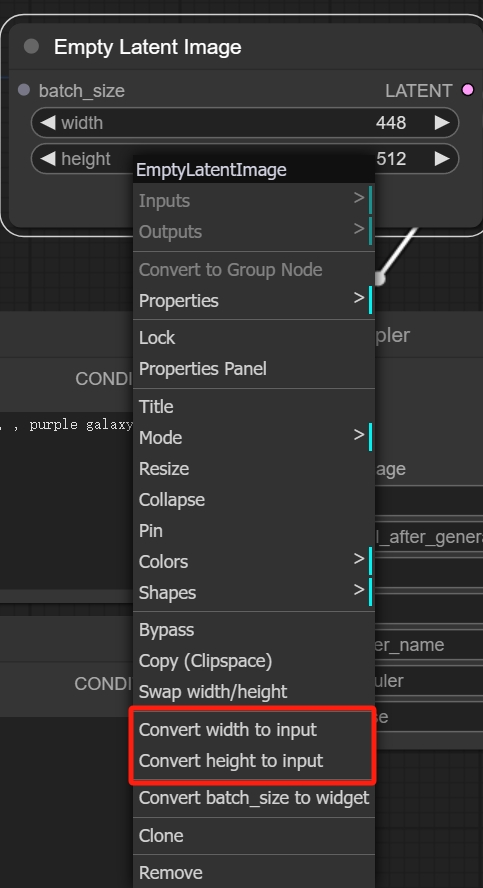
然后再将Empty Latent Image的width和height与Get Image Size的width和height连接。
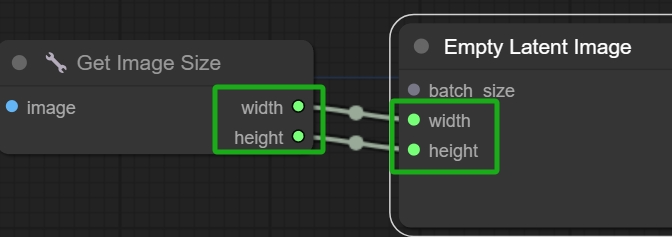
这样后续生成的尺寸就会自动与导入的图片尺寸“同步”了,当然没下载这个Set Image Size也没关系,直接自己调节尺寸参数也行。
3、如果有下载额外的节点包的话可以搜索一个Tagger节点,这个功能就类似于WebUI的图片反推提示词,可以刚好地帮助AI复现原图的内容。
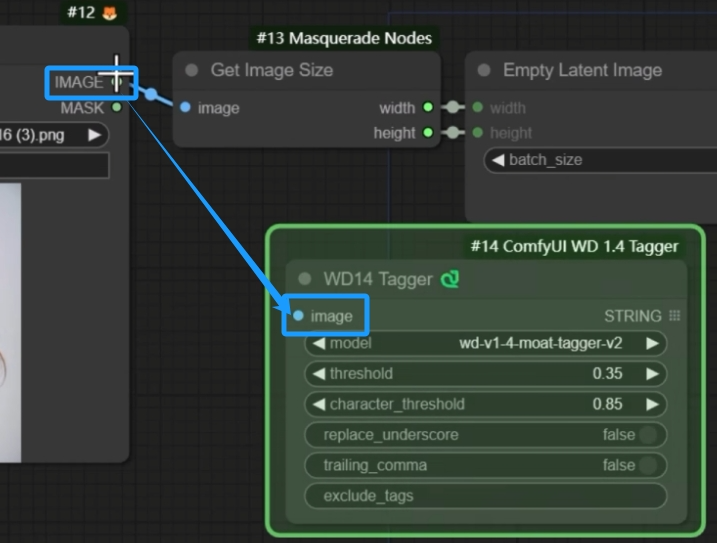
然后再将Tagger的STRING连接到CLIP TextEncode(Prompt)的text即可。
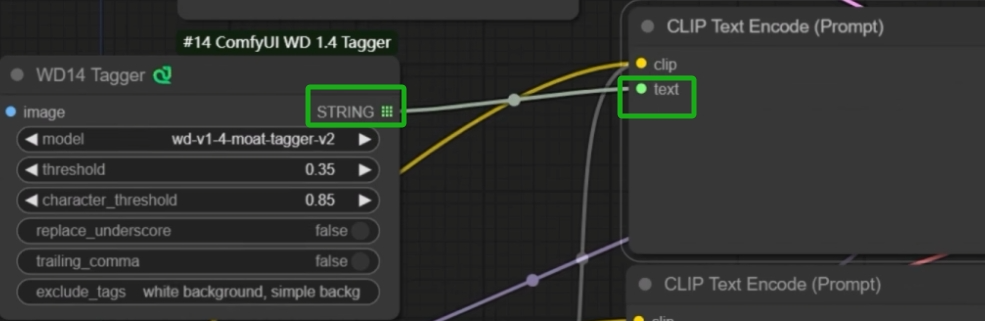
如果没有这个Tagger的话,就在提示词框像是在WebUI里面一样输入提示词就可以。
4、在ComfyUI中也需要选一个大模型和若干LoRA搭配来实现需要的转绘效果,CheckPoint是默认有的,LoRA的节点需要额外进行搜索加载
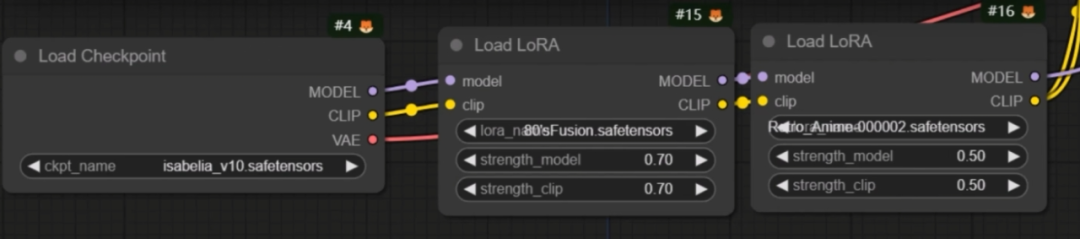
不过有一点要注意,LoRA是需要提示词里面加入触发词才能触发,但是选择了Tagger节点的小伙伴会发现提示词框是没法输入LoRA的。
这里就可以搜索一个条件合并(Conditioning Combine)的节点
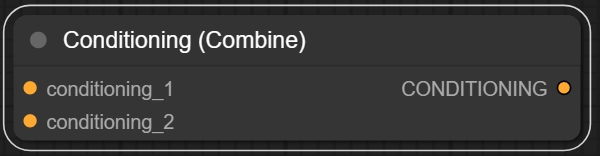
这个节点可以把两个文本编码器(或其他节点)输送的条件conditioning组合到一起。
而这里要做的就是额外添加一个CLIP Text Encode(Prompt)节点来输入LoRA提示词,然后与其他节点进行连接。

在这里Conditioning(Combine)的CONDITIONING节点并不能直接和KSampler进行连接,因为中间还有ControlNet。
5、关于ControlNet的节点怎么放置可以看看上一篇笔记,或者直接跟着我下图一样连接节点。
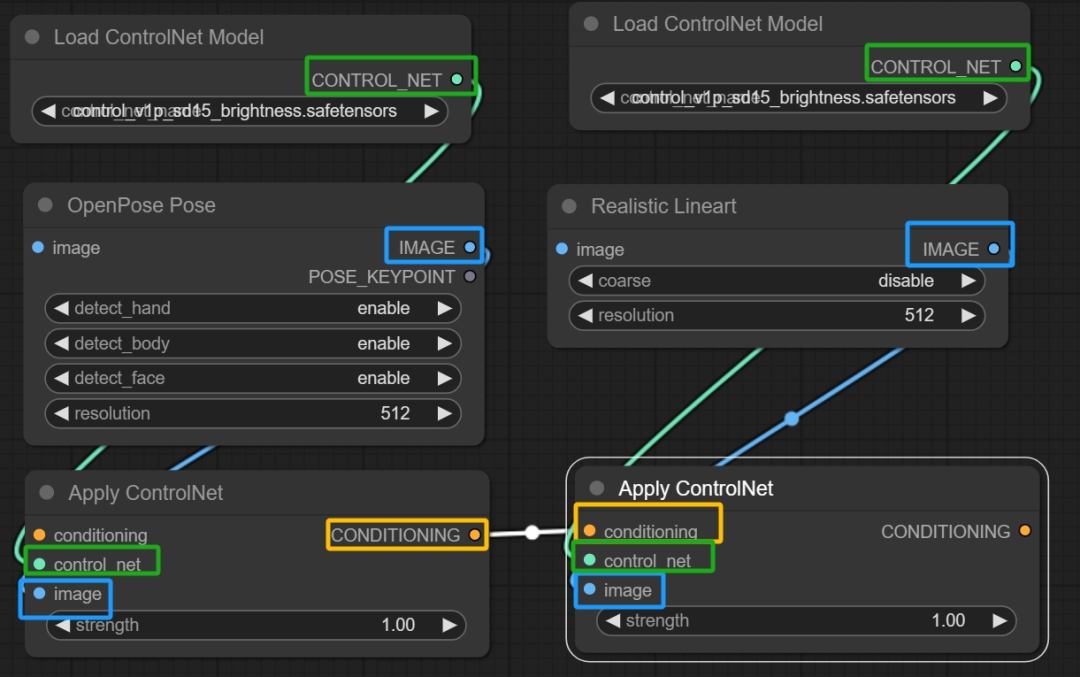
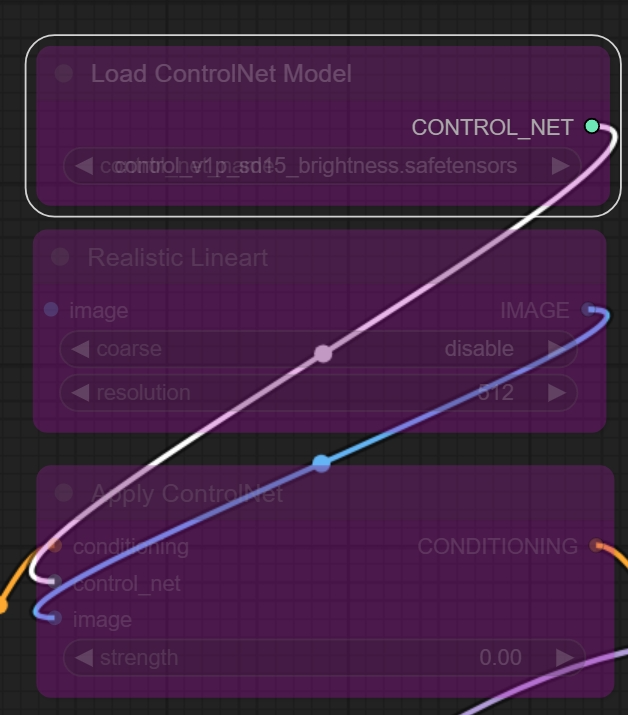
因为我就打算用两个ControlNet,所以就加载了两个Load ControlNet Model节点和两个Apply ControlNet节点。要用的ControlNet和WebUI用的一样,加载了OpenPose Pose和Realistic Lineart(真人风格原图)。
这里最后的一个Apply ControlNet节点的CONDITIONING就可以连接到KSampler上的positive了。
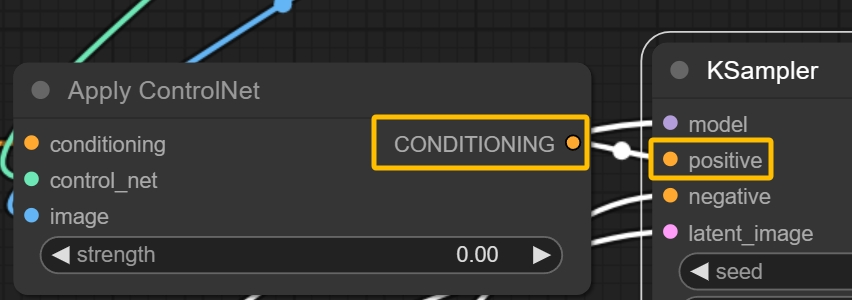
当同时加载了多个ControlNet并且只想使用其中的一到两个的时候,只需要把不用的ControlNet的权重(strength)设置为0即可。
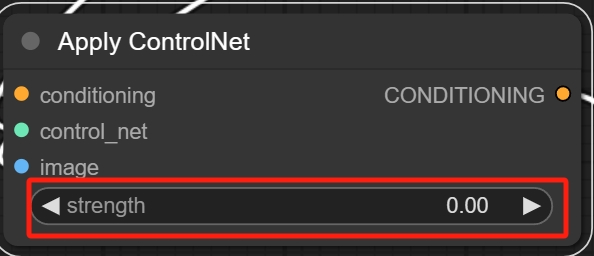
当然还有另一个方式,右键选择节点后找到Bypass(忽略)选项:

这样一来这个节点就会变成这种透明紫的颜色,这代表着工作流在运作的过程中仍会按照原本的方式进行,但在经过这个节点的时候会忽略掉,不会让其发挥工作。
像这样就忽略了整一组Lineart的节点了:
恢复也很简单,也是鼠标右键选择Bypass后就变回原本的颜色了。
6、最后在从最开始的Load Image节点那里将图片的信息都连接到用预处理器上:
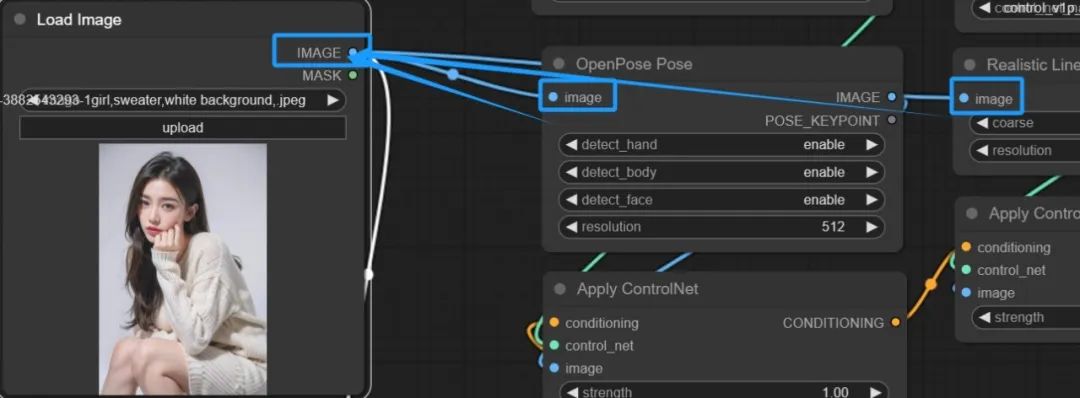
然后就可以点击生成了:

可能有点不像,这是因为ControlNet中我的ControlNet模型出现了一点问题。在这次使用ComfyUI中我的其他Openpose等模型加载不出来了,我会在后续解决:
不过这样一来就有了一个完整的图片生成流程了
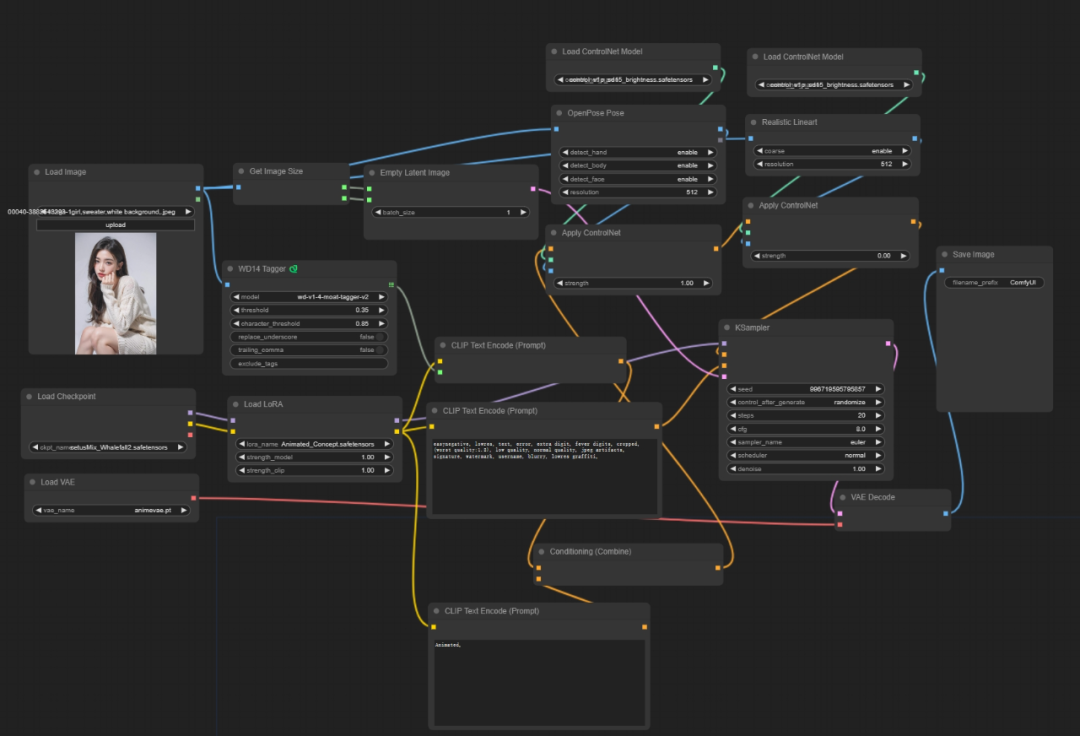
这样的生成好像和在WebUI里面没有什么区别,这样费劲吧啦创建一个工作流的作用就是在生成第二张图片的时候不需要进行任何额外操作,只需要把最左边Load Image节点里的图片更换一下就好了。
当然还有一些进阶的节点可以自动读取本地文件夹中的图片,然后自动进行批量转绘。甚至觉得生成的图片太小的话,可以在最后的VAE和Save Image节点中间添加个放大的节点。
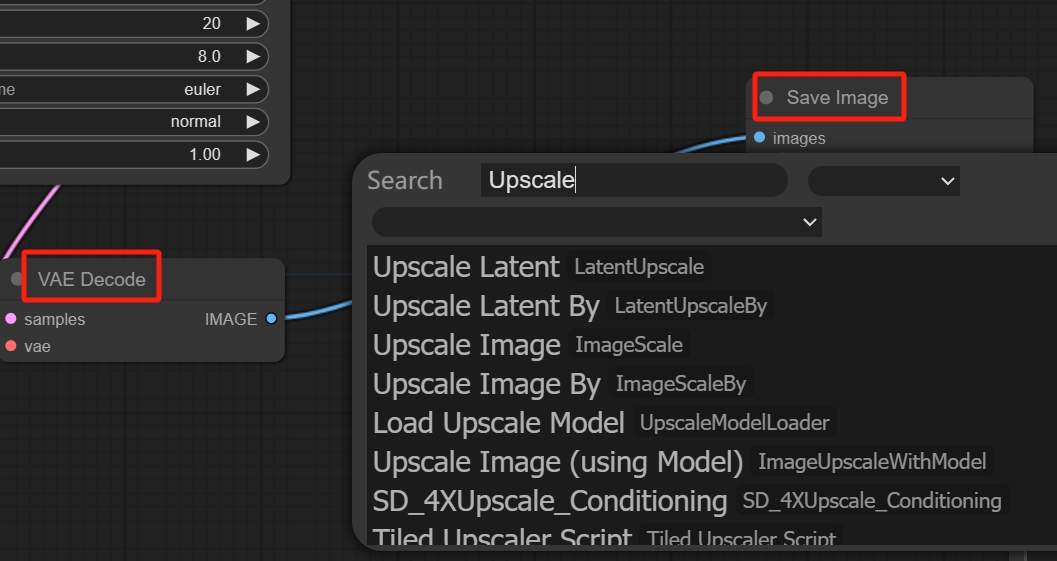
这个放大节点所需要的所有参数都可以从前面的节点调用,当然也可以在这个节点里自行设置放大模型和参数。
当然有小伙伴学到这里可能就麻了,这连线什么的真的好麻烦。
这里不得不提起原教程UP的贴心,直接在视频结尾放了一个完整的工作流。

这个下载链接我也放在了文末,不过运行这些节点仍然需要下载好对应的节点包和模型。
今天的内容就到这里啦!
这篇笔记里分别走了一次WebUI和ComfyUI的转绘流程,如果只是单张或少量图片的转绘肯定还是WebUI方便一些,但是如果是大批量的图片转绘ComfyUI会更有优势。
这还是要看小伙伴们根据自己的实际情况进行选择了,希望这篇笔记能够帮助到有需要的小伙伴。
ComfyUI的入门篇就暂告一段落,我会在下篇笔记中分享并上传我开始学Stable Diffusion以来所有的模型(包括CheckPoint、LoRA等),希望可以帮助到那些没法翻梯子去Civitai的小伙伴。
那就下篇笔记见啦,拜了个拜!

**节点包的下载方法:
**
1、在ComfyUI界面选择Manager:
然后选择Install Custom Nodes
2、在上方的搜索栏中分别搜索Ultimate SD upscale

**ComfyUI WD 1.4 Tagger
**

**Masquerade Nodes
**

**ComfyUI Essentials
**

WAS Node Suite

**Efficiency Nodes for ComfyUI Version 2.0+
**
3、将上述节点包都下载好后点击界面最下方的RESTART即可

资料软件免费放送
次日同一发放请耐心等待
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
需要的可以扫描下方CSDN官方认证二维码免费领取【保证100%免费】

**一、AIGC所有方向的学习路线**
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









