






 文章介绍了Z分值模型在预测企业偿还能力中的应用,通过Python对数据进行处理,包括读取Excel数据、处理缺失值、计算Z分值五个关键指标,并依据这些指标判断企业是否可能违约。Z分值低于1.81被视为违约风险高,大于2.675则风险较低。文章强调了数据清洗和理解模型步骤的重要性。
文章介绍了Z分值模型在预测企业偿还能力中的应用,通过Python对数据进行处理,包括读取Excel数据、处理缺失值、计算Z分值五个关键指标,并依据这些指标判断企业是否可能违约。Z分值低于1.81被视为违约风险高,大于2.675则风险较低。文章强调了数据清洗和理解模型步骤的重要性。
Z分值模型
Z分值模型数据.xlsx【https://www.aliyundrive.com/s/6Kw2rjjNELP提取码: 3u2y】
点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视频原画倍速播放。
引言:
预测企业的偿还能力属于信用风险管理的问题,当前有很多信用风险测量的模型,如KMV模型、莫顿模型,但其中最简单的就是Z分值模型。
介绍
Z分值模型采用的是分离分析的方法,根据数理统计中的辨别分析技术,对银行过去贷款案例进行统计分析,选择部分最能反映借款人财务状况、对贷款质量影响最大、最具预测或分析价值的比率,设计出一个能最大程度区分贷款风险度的数学模型,对贷款人申请人进行信用风险及资信评估。
P.S:完整的Z分支模型还区分上市公司、非上市公司和非制造业企业三种类型,每一类都有不同的参数作为评价标准。
内容

式中:
运营资金=期末流动性资产-期末流动性负债
期末留存收益=权益资产总额-实收资本-资本公积
息税前利润=税前利润+利息支出
其它指标就等于相应的会计科目的数值
爱特曼经过统计分析和计算最后确定了借款人违约的临界值Z=2.675:
如果Z<2.675,借款人被划入违约组;反之,如果Z>=2.675,则借款人被划入非违约组
但是当1.81<Z<2.675时,判断失误较大,成该区域为灰色区域或未知区域
因此实践中长将Z<1.81作为违约组的明确分界线
python程序结构分析

按照计算Z分值的步骤,从提取数据、处理缺失值、计算五个指标、计算Z分值和区分样本的步骤做下去就可以
这里提到的五个指标也是我们后面会把Z分辨模型的公式进行拆分,分别为:

等等 ,后面直接将五个指标代入Z模型,进而得出Z分值。
读取数据(对比xlsx)
import pandas as pd
data = pd.read_excel("Z分值模型数据.xlsx",index_col=0)
#index_col=0将excel中第一列(1,2,3....)去掉
data.head(3)
#.head()不输入数字则默认输入前6行,不受限制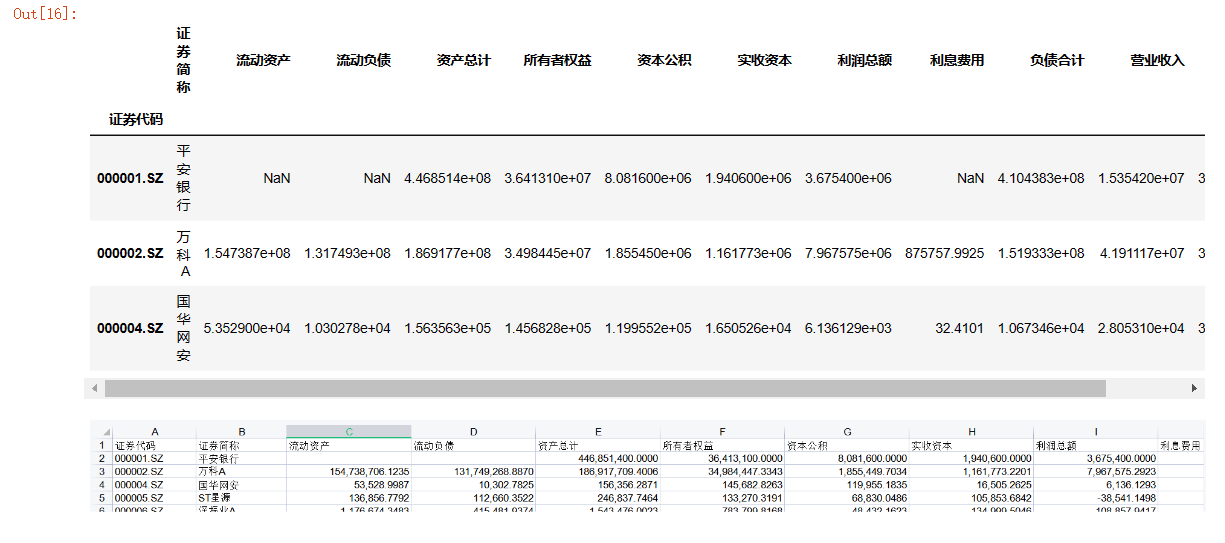
查看数据大小
data.shape #4475行12列(4475, 12)
去除缺失值
在前面显示前三行的时候就看到了第一个数值就是缺失值,数据当中肯定有大量缺失值存在。在这里我们直接将缺失值剔除,因为我们要使用财务数据计算财务指标,用任何方法去填充都是不合理的,都无法真正替代企业的该财务指标值。
data.dropna(inplace=True) #可以看到有缺失值的数据直接整个被丢掉了
data.head(3)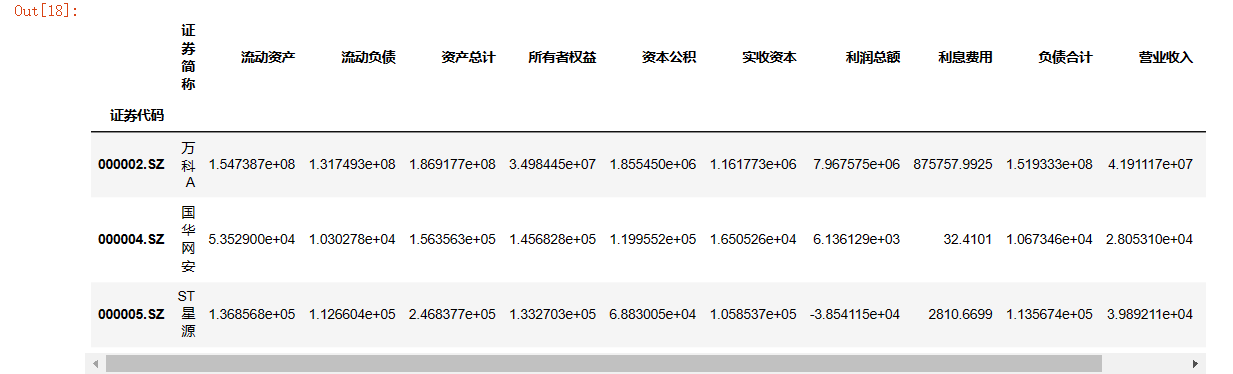
#再次查看数据大小
data.shape(3629, 12)
查看描述性统计
data.describe().T
#加个.T转置是为了更好的观看数据,
#依次看到统计数据组数、平均值、标准差、最大小值、四分位数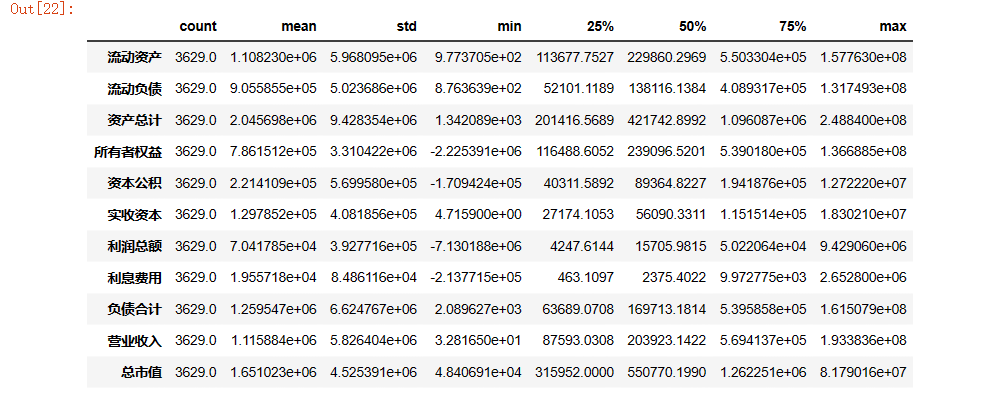
准备Z分值模型的指标
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。. DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共同用一个索引)。
z_scores = pd.DataFrame(data=data[['证券简称']])
z_scores['运营资金/总资产'] = (data['流动资产']-data['流动负债'])/data['资产总计']
z_scores.head(3)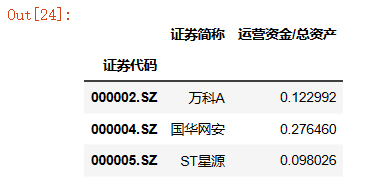
z_scores['留存收益/总资产'] = (data['所有者权益']-data['资本公积']-data['实收资本']
)/data['资产总计']
z_scores['息税前利润/总资产'] = (data['利润总额']+data['利息费用'])/data['资产总计']
z_scores['股东权益市值/负债'] = (data['总市值'])/data['负债合计']
z_scores['营业收入/总资产'] = (data['营业收入'])/data['资产总计']
z_scores.head(3)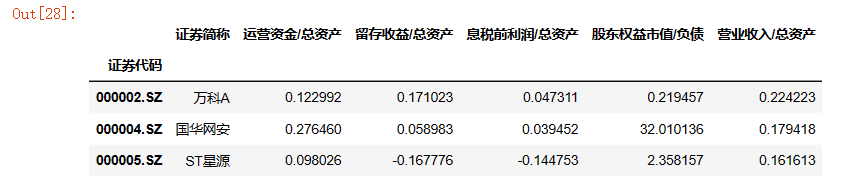
计算Z分值
z_scores['Z分值'] = 1.2*z_scores['运营资金/总资产']+1.4*z_scores['留存收益/总资产']+3.3*z_scores['息税前利润/总资产']+0.6*z_scores['股东权益市值/负债']+0.999*z_scores['营业收入/总资产']
z_scores.head(3) 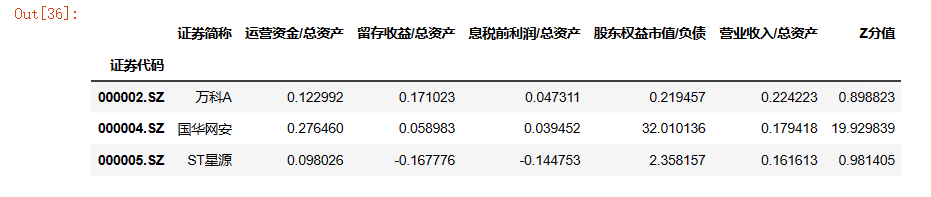
筛选数据
red_alerm = z_scores[z_scores['Z分值']<1.81] #违约组
red_alerm.head(10)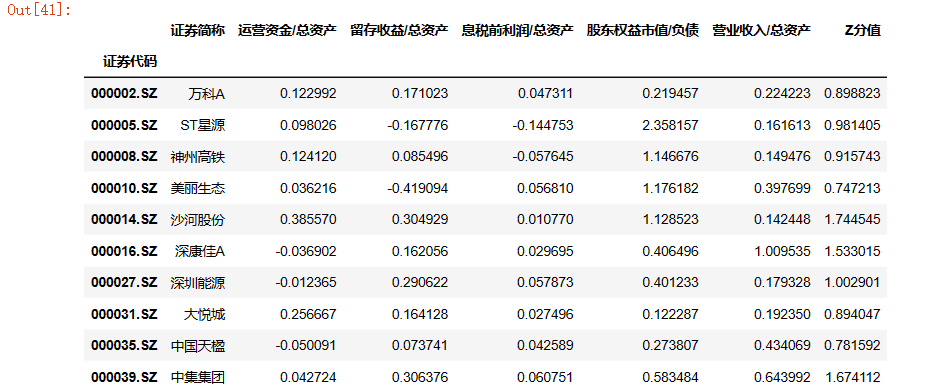
perfect = z_scores[z_scores['Z分值']>2.675] #非违约组
perfect.head(5)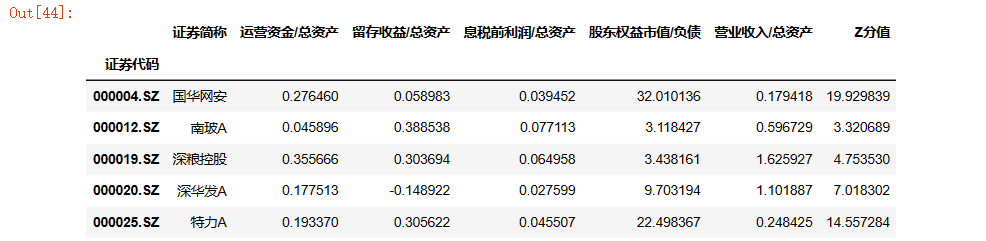
#也可以通过.decribe再看看描述性统计
perfect.describe().T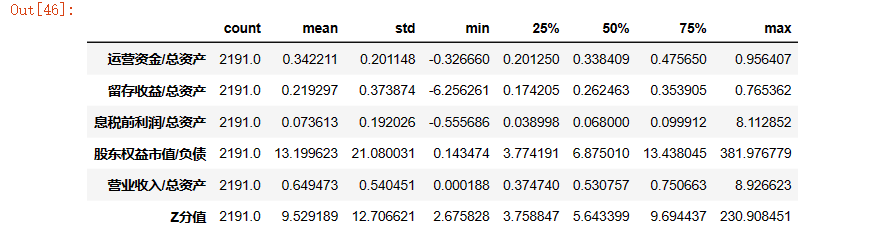
疑惑:
上文中这个证券代码是.DataFrame自己读取的嘛?
这个代码书写过程的缩进问题有好的文章推荐嘛?
总结:
上述文章中,Z分值模型对数据处理的流程还是比较简单的,值得学习的是这种对数据的一步步清洗的思路。学习过程中还是建议多敲,这样才能更好的理解和熟练运用,掌握方法后在此基础上进一步思考,才能真正转为自己的知识。
文章仅供参考学习,欢迎交流,共同进步。

|


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









