






转载公众号 | 东南COIN
题目:HeGTa: Leveraging Heterogeneous Graph-enhanced Large Language Models for Few-shot Complex Table Understanding
作者:金日辉1,2、李煜1、漆桂林1、胡楠1、李元放2、陈矫彦3、王佳楠4、陈永锐1、闵德海1、毕胜1
作者单位:1东南大学认知智能研究所、2蒙纳士大学、3曼彻斯特大学、4阿里巴巴
论文地址:https://arxiv.org/pdf/2403.19723

1 引言
表格理解(Table Understanding, TU)旨在通过机器学习和深度学习技术,使机器能够理解和处理包含复杂语义的表格数据。TU的应用场景包括表格问答、单元格类型分类和表格类型分类等任务。然而,TU在实际应用中面临两大挑战:一是缺乏足够的人类标注数据,二是表格结构的复杂性。这些挑战导致现有框架在少样本和复杂表格场景下的性能下降。
为解决这些问题,研究者提出了HeGTa,一种基于异构图增强的大型语言模型(LLM)框架。HeGTa通过以下方式应对挑战:
异构图建模:利用异构图(HG)捕捉复杂表格中单元格间的复杂关系,并通过表格图编码器生成包含结构化信息的向量。
指令调优与软提示:通过指令调优将表格图编码器的语义空间与LLM的语义空间对齐,并将表格向量作为软提示集成到LLM输入中,以提升少样本场景下的性能。
多粒度自监督任务:设计了三种针对表格和LLM的自监督任务进行预训练,使HeGTa能够利用LLM的泛化能力,以最少的数据样本适应下游任务。
实验结果表明,HeGTa在9个公开数据集上的表现优于当前的最先进方法(SOTA),尤其在少样本和复杂表格理解任务中展现了显著优势。
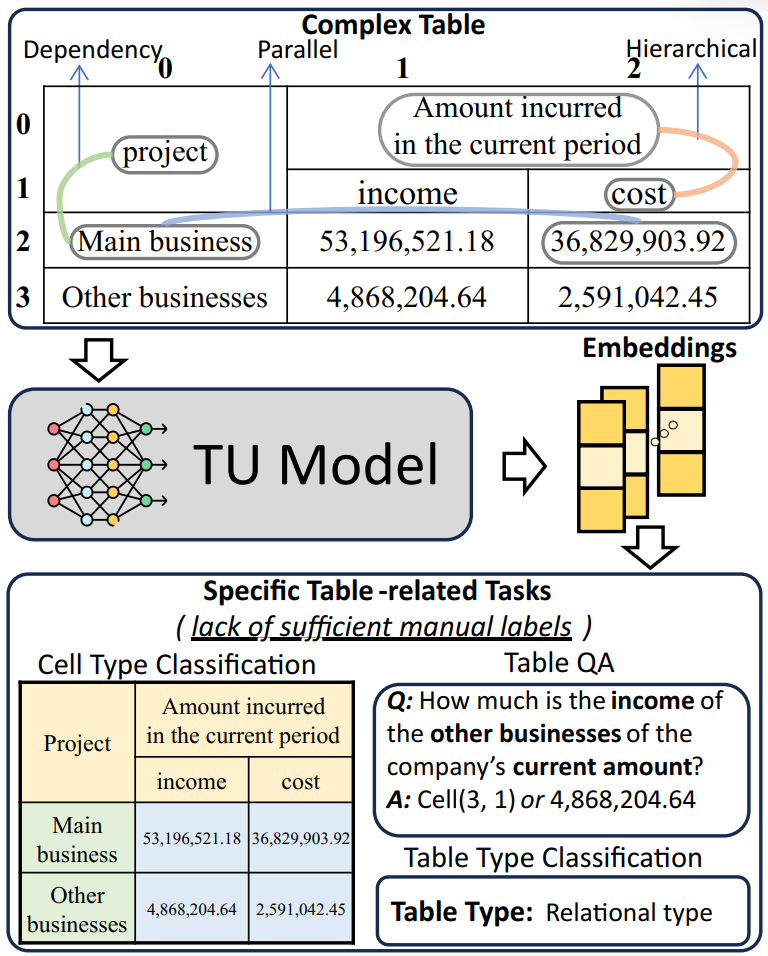
图 1 少样本复杂表格理解。复杂表格包含复杂的单元格间关系,包括依赖关系、层次关系和平行关系。
2 方法
2.1 概览
下文将介绍 HeGTa 的三个阶段:表格异质图的构建及两个调优阶段,如图 2所示。
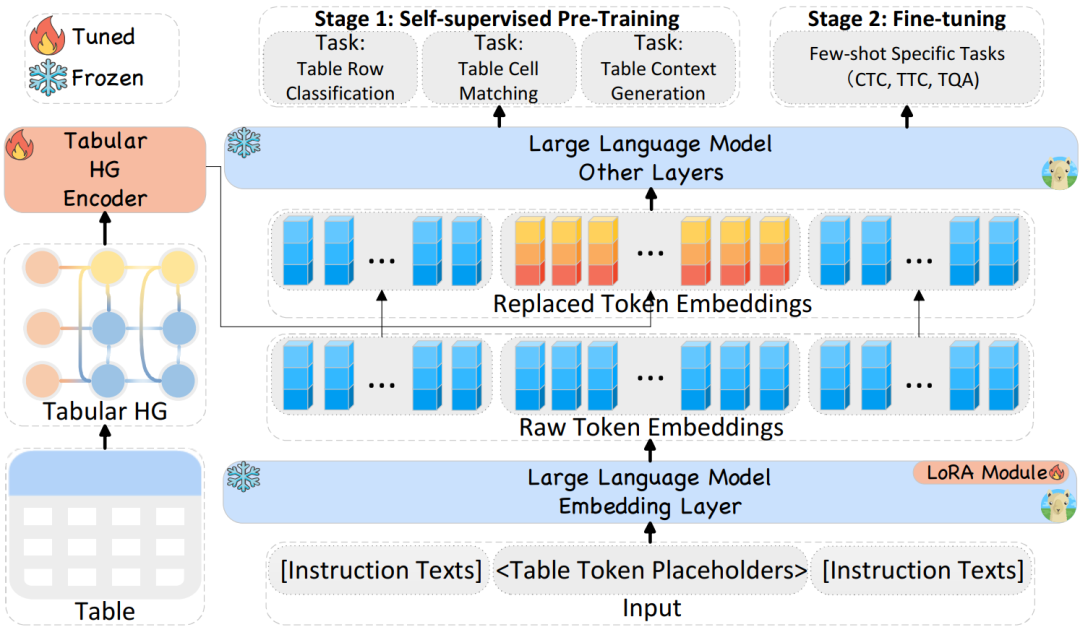
图 2 HeGTa 框架概述。HeGTa 将 <表格, 指令> 作为输入进行处理。首先,表格被转换为异质图,并通过表格异质图编码器生成每个表格节点的向量,同时大语言模型将指令文本转换为初始的词嵌入。随后,异质图编码器的输出作为软提示输入到 LLM 中,从而将占位符嵌入替换为实际的表格节点向量。修改后的嵌入序列随后由 LLM 的剩余层进行处理。在整个阶段 1 和阶段 2 中,仅调整红色组件的权重。
2.2 表格异质图构建
由于与同质图相比,异质图更擅长捕获多样的关系,我们使用具有启发式节点连接规则的异质图,来有效地建模复杂表格的结构。以下小节详细说明了将表格数据转换为异质图的过程,包括节点的创建以及用于在节点之间建立边的启发式规则。表格异质图的创建过程如图 3所示。
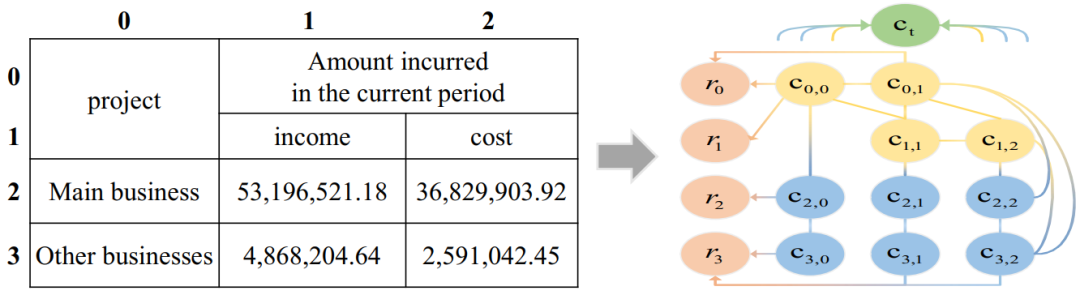
图 3
四种表格节点类型
图 3中绿色、红色、黄色和蓝色节点分别表示 TABLE、ROW、Header CELL 和 Data CELL 节点。
首先,为表格中的每个单元格创建 CELL 节点,每个节点记为Ci,j,其中 i 和 j 表示单元格在原表格中的坐标。如果 CELL 节点位于表头部分,或者属于横跨整个表格宽度的合并单元格,则被视为 Header CELL;否则,被视为 Data CELL。随后,根据表格行数创建对应数量的 ROW 节点,并创建一个 TABLE 节点。
表格节点嵌入的初始化
每个 HG 节点都需要一个初始化向量。对于 Header 和 Data CELL 节点,我们使用 S-BERT (Reimers 和 Gurevych,2019) 对单元格内的文本进行处理,获取其初始化向量。对于 ROW 节点 ri,我们将第 i 行的单元格文本拼接后输入 S-BERT,生成初始化向量。TABLE 节点则表示表格的整体内容,通过拼接表头中的单元格文本获得嵌入。
添加边
为了增强机器对表格语义的理解,我们设计了以下启发式规则来连接节点:
TABLE 节点应与所有 CELL 节点连接,以捕获全局语义。
ROW 节点需要从同一行中的 CELL 节点获取信息,因此 ri 应连接到每个 ci,* 。
Data CELL与同一列中的 Header CELL语义相关,因此需要连接。
同列中的 Data CELL 之间关系更紧密,因此需要相互连接。
所有 Header CELL 需要相互连接,以便理解跨列的 Data CELL 之间的关系。
边的类型根据连接的节点分类为:Table-Header、Table-Data、Header-Row、Data-Row、Header-Data、Data-Data 和 Header-Header 边。
2.3 阶段 1:自监督指令调优
如图 2 所示,HeGTa 将 HG 编码器的表格输出用作 LLM 输入中的软提示符(Li 和 Liang,2021)。通过自监督指令调优,调整两个模块的向量表示空间。本节详细介绍了包含三种粒度自监督任务的预训练过程。
表格 HG 编码器
在表格转换为 HG 后,HeGTa 引入异质图神经网络(HGNN,Hu et al.,2020)作为表格 HG 数据的编码器。该编码器以表格 HG 为输入,输出表格节点的向量表示。HGNN 使用消息传递机制,在每层中收集来自邻近单元格节点的语义和拓扑信息,并考虑不同的边类型。
多粒度自监督指令任务
借鉴 LLaVA(Liu et al.,2023)、Time-LLM(Jin et al.,2023a)和 GraphGPT(Tang et al.,2023)的方法,我们开发了一种有效对齐表格和自然语言两种模态数据向量空间的方法。通过软提示技术作为两个编码器之间的桥梁,重点微调表格图编码器和 LLM 中的 LoRA(Hu et al.,2021)模块。该轻量化过程使 LLM 能够通过语义指令调优理解表格的拓扑信息。
自监督训练任务
为了将 LLM 与 HG 编码器对齐,HeGTa 在词汇表中增加了以下额外标记:<tabular node>、<table start> 和 <table end>。<tabular node> 是表格任务中的占位符,用于在后处理时替换为实际表格节点向量;<table start> 和 <table end> 分别标记表格占位符的起始和结束位置。
HeGTa 的前向传播从 <Table, Instruction> 对输入开始,其中指令文本通过 LLM 的嵌入层,表格被转换为表格 HG 并由 HGNN 处理。随后,将表格占位符对应的嵌入替换为实际节点向量,形成调整后的嵌入序列,输入 LLM 的后续层。
为增强模型对表格的理解,设计了三个针对图增强 LLM 的任务,粒度各异:表格行分类(TRC)、表格单元格匹配(TCM)和表格上下文生成(TCG)。这些任务逐步提高模型理解表格语义信息的能力,详细描述如下:
表格行分类(TRC):训练模型准确分类表格行。利用 HG 编码器提供的行节点向量,模型判断节点是Header行还是Data行。该任务帮助模型掌握表格行结构的粗粒度信息。
表格单元格匹配(TCM):训练模型将每个单元格节点向量与其原始文本正确匹配。该任务对齐了 HG 编码器和 LLM 的语义空间。
表格上下文生成(TCG):训练模型使用表格节点的向量表示生成表格数据的上下文信息。
示例数据如图4所示。

图4 以下是三个自监督指令微调数据集的示例,每个数据集针对不同的任务设计:表格行分类、表格单元格匹配和表格上下文生成。
2.4 阶段 2:特定任务的指令微调
在阶段 1 的自监督预训练任务完成后,HeGTa 已成功对齐 HG 编码器和 LLM 的表示空间。结合 LLM 的固有能力,HeGTa 能有效理解复杂表格的拓扑细节。在具体任务(如 CTC、TTC、TQA)中,仅需少量训练样本即可掌握期望答案格式。微调时,仅调整 HG 编码器的参数。
为增强推理能力,我们在 k-shot TQA 样本中使用 Chain of Thought(CoT)进行推理过程标注(Wei et al.,2022)。受 Auto-CoT(Zhang et al.,2022)启发,我们首先对测试集中的表格样本进行聚类,然后对每个表格簇中的问题进行聚类,最后从每个问题簇中选择核心样本进行标注。此方法在有限注释数量下确保了上下文示例的多样性。
3 实验
3.1 数据集
下表显示了这些数据集的统计信息,展示了注释类型、主要涵盖的领域以及复杂表格的比例。鉴于关注于小样本表格理解(few-shot TU)场景,我们仅列出了测试集的大小。
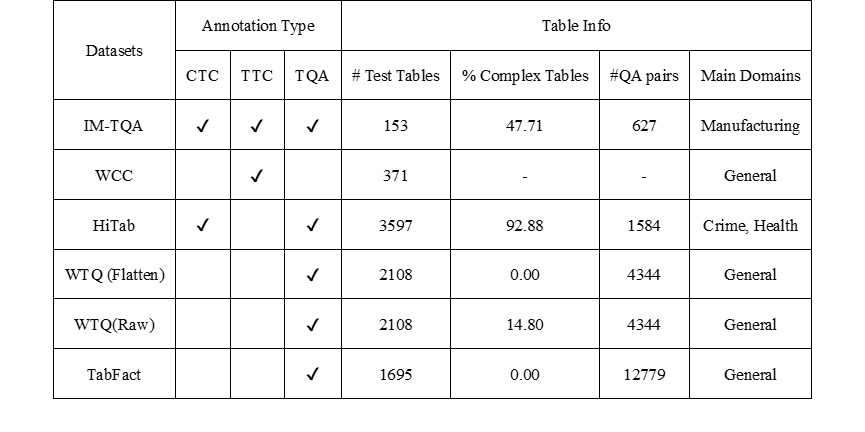
表1 数据集统计。“✓”表示数据集中包含该任务的注释类型。“# 测试表格”、“% 复杂表格”和“# 问答对”列分别显示了测试集中的表格数量、复杂表格的百分比以及问答对的数量。
3.2 结果和分析
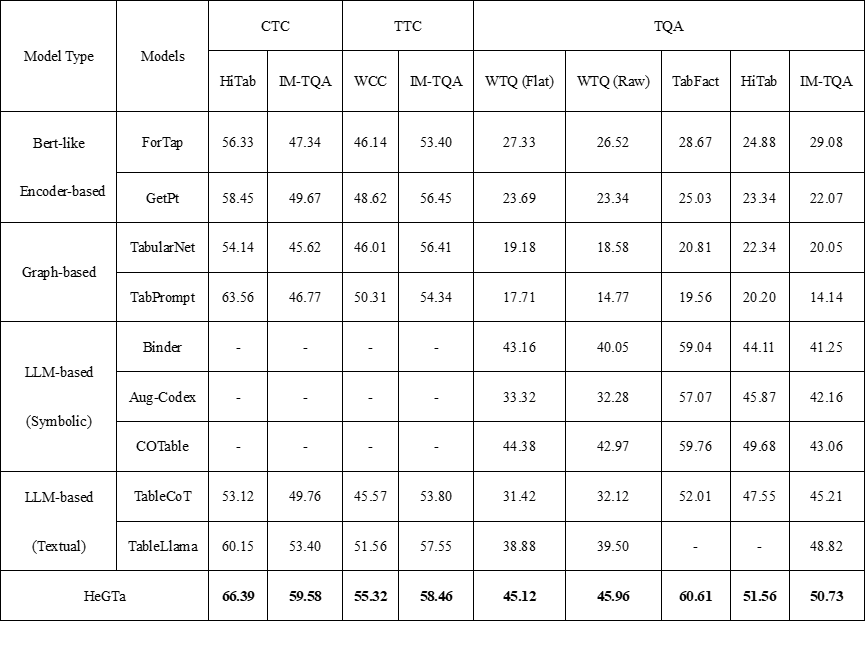
表2 实验结果
表2 比较了 HeGTa 和在 §4.1 中描述的所有数据集上的不同方法的性能。从结果中得出以下结论:
HeGTa 在 9 个数据集上均优于所有基线方法,展示了其在具有等效参数的非 LLM 方法和 LLM 方法上的优越性。此外,HeGTa 在 CTC 和 TTC 等嵌入相关任务中,即使与 SOTA GPT-4 相比,也表现出了竞争力。
LLM 的符号方法在 TQA 任务中表现出色,但由于其架构设计的限制,无法处理其他表格任务。具有 7B 参数的 LLM 在推理和生成可执行代码方面,通常比基于 ChatGPT 的方法表现更差。
WTQ(Raw)与 WTQ(Flatten)的性能差异显著。WTQ(Raw)保留了分层表头的复杂性,其他方法在 WTQ(Raw)上的性能下降,突显了 HeGTa 在处理复杂结构的关系表格方面的能力。
HeGTa 的优越性:与其他基于 LLM 的框架相比,HeGTa 在表格拓扑信息的利用上表现突出。其他框架(如 TableLlama 和 TableCoT)无法捕获这种拓扑信息,尽管它们采用了线性化表格的广泛训练(TableLlama)或 HTML 格式(TableCoT),但其性能仍不及 HeGTa。
LLM 模型的优缺点
HiTab 数据集中的所有 QA 样本可以分为基于查找的推理(L-R)和基于计算的推理(C-R)(例如,求和、最大值、计数等)。表3展示了三种基于 LLM 的方法在这两类 QA 样本上的性能表现。TableCoT在 L-R 样本上的表现优于 C-R 样本,这与 Chen 等人(2022 年)的结论一致,即 LLM 在数值计算方面存在困难。COTable通过利用 SQL 来弥补 LLM 在数值推理中的不足,从而在 C-R 样本中达到了最高的准确率。然而,层次化的表结构导致 SQL 性能有所下降。HeGTa通过引入异质图结构,解决了表格线性化后结构信息丢失的问题。结果表明,HeGTa 在 L-R 样本中取得了显著的性能提升。另外,即使不局限于 few-shot 设定(即用整个训练集对模型进行微调),HeGTa 依然能保持出色的性能,如附录所示。
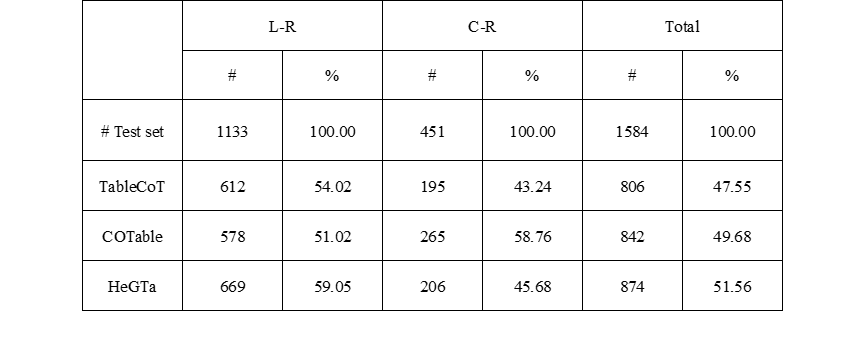
表3 三种方法在 HiTab 数据集上的进一步结果。“#”表示正确回答的样本数量,“%”表示正确回答样本的比例。
4 结论
在本文中,我们介绍了一种新颖的框架——HeGTa,专为少样本复杂表格理解任务设计。HeGTa的有效性在多个表格数据集上得到了验证,并辅以深入的消融研究,以探讨每个组件的影响。在未来的工作中,我们计划扩展HeGTa的适用性,使其能够处理布局更加多样化的表格,并通过将程序辅助范式集成到我们的方法中,进一步提升HeGTa在表格问答任务中的性能。
参考文献:
1. Cao, Y.; et al. 2023. API-Assisted Code Generation for Question Answering on Varied Table Structures. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023.
2. Chen, W. 2022. Large Language Models are few(1)-shot Table Reasoners. Findings of the Association for Computational Linguistics: EACL 2023. 2023.
3. Chen, W.; et al. 2022. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. Transactions on Machine Learning Research.
4. Chen, W.; et al. 2020. TabFact: A Large-scale Dataset for Table-based Fact Verification. In International Conference on Learning Representations.
5. Cheng, Z.; et al. 2021a. FORTAP: Using Formulas for Numerical Reasoning-Aware Table Pretraining. In Annual Meeting of the Association for Computational Linguistics.
6. Cheng, Z.; et al. 2021b. HiTab: A Hierarchical Table Dataset for Question Answering and Natural Language Generation. ArXiv, abs/2108.06712.
7. Cheng, Z.; et al. 2022. Binding Language Models in Symbolic Languages. ICLR 2023.
8. Chiang, W.-L.; et al. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna.lmsys.org (accessed 14 April 2023).
9. Deng, X.; et al. 2020. TURL: Table Understanding through Representation Learning. SIGMOD Rec., 51: 33–40.
10. Devlin, J.; et al. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. ArXiv, abs/1810.04805.
11. Dong, H.; et al. 2022. Table pre-training: A survey on model architectures, pre-training objectives, and downstream tasks. IJCAI 2023.
12. Du, L.; et al. 2021. TabularNet: A Neural Network Architecture for Understanding Semantic Structures of Tabular Data. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining.
13. Ghasemi-Gol, M.; and Szekely, P. A. 2018. TabVec: Table Vectors for Classification of Web Tables. ArXiv, abs/1802.06290.
14. Herzig, J.; et al. 2020. TaPas: Weakly Supervised Table Parsing via Pre-training. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020.
15. Hu, E. J.; et al. 2021. LoRA: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
16. Hu, Z.; et al. 2020. Heterogeneous graph transformer. In Proceedings of the web conference 2020, 2704–2710.
17. Jia, R.; et al. 2023. GetPt: Graph-enhanced General Table Pre-training with Alternate Attention Network. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
18. Jin, M.; et al. 2023a. Time-LLM: Time Series Forecasting by Reprogramming Large Language Models. ArXiv, abs/2310.01728.
19. Jin, R.; et al. 2023b. TabPrompt: Graph-based Pre-training and Prompting for Few-shot Table Understanding. In Conference on Empirical Methods in Natural Language Processing.
20. Li, X. L.; and Liang, P. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), abs/2101.00190.
21. Liu, H.; et al. 2023. Visual Instruction Tuning. ArXiv, abs/2304.08485.
22. Liu, Z.; et al. 2021. Relative and absolute location embedding for few-shot node classification on graph. In Proceedings of the AAAI conference on artificial intelligence, 4267–4275.
23. Lu, W.; et al. 2024. Large language model for table processing: A survey. arXiv preprint arXiv:2402.05121.
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









