






Data Intelligence
DI佳作:本体嵌入:融合外延与内涵新型本体表示学习方法
【导语】在人工智能与大数据时代,知识表示是机器理解世界的基石。然而,传统方法往往割裂了概念的外延(实例集合)与内涵(语义特征),导致知识表达片面、应用受限。Data Intelligence最新发表的《本体嵌入:融合外延与内涵知识的新型表示方法》 突破这一瓶颈,提出了一种统一的知识嵌入框架,实现两类知识的协同建模与联合优化!该论文由漆桂林教授领衔,作者团队来自东南大学、中国移动、德国蒂宾根大学、英国曼彻斯特大学等国内外知名机构的青年才俊。
文章信息:Wang K.Y., Qi G.L., Chen J.Y., et al.: Embedding Ontologies via Incorporating Extensional and Intensional Knowledge. Data Intelligence, Vol. 7, Issue 4, 1222-1241, 2024. DOI: https://doi.org/10.3724/2096-7004.di.2024.0088
点击文后“阅读原文”可直达论文全文。
该文介绍了EIKE框架,一种融合外延与内涵知识的本体嵌入方法。它通过外延空间的几何化表示和内涵空间的预训练语言模型(如Sentence-BERT)实现双空间建模,并采用联合训练机制优化表示。实验表明,EIKE在分类和链接预测任务上优于现有方法,为知识表示提供了新思路。未来将拓展支持更多逻辑关系并探索动态融合机制。
本体嵌入的背景与挑战
次我们公司的年度峰会旨在为广大科技从业者提供一个交流、学习和分享的平台,促进行业内企业之间的合作与发展。我们邀请了众多知名企业家、专家学者和行业领袖参加,共同探讨未来科技发展趋势和应对策略。
传统本体包含两类关键知识:外延知识(描述具体实例与概念的归属关系,例如特朗普是美国总统, Donald_Trump InstanceOf President_of_U.S.)和内涵知识(描述概念的内在属性与语义关联, 例如美国总统都是政治家, President_of_U.S. SubClassOf Polician)。然而,现有本体嵌入方法往往无法同时精细建模这两类知识——几何方法擅长外延表示但忽略文本语义,而语言模型虽能捕捉内涵信息却难以处理实例与概念的层次结构。这种割裂导致现有方法在知识表示全面性上的局限性。
文章进一步分析了本体嵌入的关键挑战:如何平衡结构化表示与语义理解。几何化方法(如TransC)通过空间区域表示概念层次,但无法利用概念描述文本;而纯文本方法(如OWL2Vec*)虽能利用语言信息,却难以区分概念与实例的几何特性, 而理想的解决方案需要同时满足:1)保留概念-实例的几何包含关系;2)捕捉概念属性的文本语义;3)维持isA关系的传递性。
EIKE方法的核心创新
针对上述挑战,本文提出EIKE框架(Extensional and Intensional Knowledge Embedding),通过双空间建模实现知识表示学习(如下图所示)
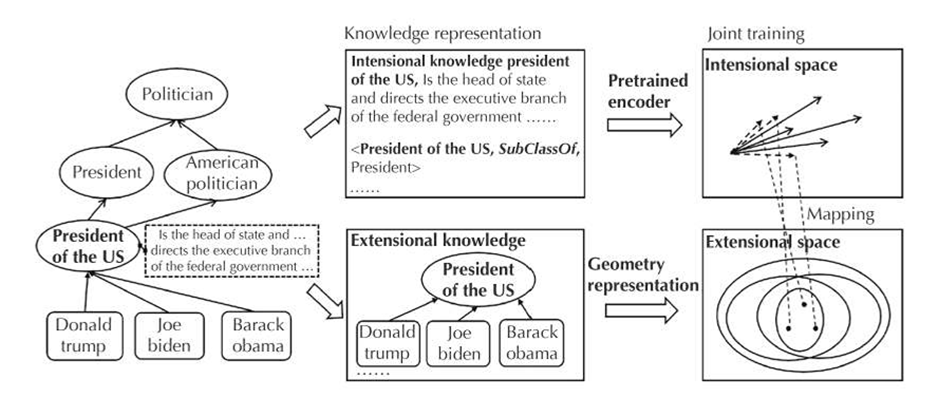
外延空间:采用几何化表示,将概念建模为椭球区域,实例表示为空间中的点,通过区域包含关系刻画InstanceOf和SubClassOf的层次结构。该方法继承TransEllipsoid的各向异性表示优势,能有效建模概念覆盖范围的差异。
内涵空间:创新性地引入预训练语言模型(Sentence-BERT),将概念名称及描述文本编码为语义向量,通过向量相似度度量概念间的语义关联。特别设计模长约束,使上位概念比下位概念具有更抽象的表示(模长更小)。
联合训练机制:设计三类三元组的差异化损失函数:(1) 外延空间的几何包含损失;(2) 内涵空间的语义相似度损失;(3) 实例关系的平移不变性损失。通过参数共享矩阵实现双空间表示的协同优化。
方法创新体现在:首次提出双空间表示框架,建立预训练语言模型与几何嵌入的协同训练,以及通过模长约束实现内涵空间的层次保持。
实验验证与应用前景
实验部分在YAGO39K, M-YAGO39K和DB99K-242 数据集上验证了EIKE的优越性:
分类任务:在InstanceOf和SubClassOf三元组分类上,EIKE均达到sota效果。例如EIKE-PRE-EYE版本F1值在YAGO39K和M-YAGO39K分别达到90.45%和87.12%,显著优于TransEllipsoid,TransC等基线,证明双空间融合的有效性。
链接预测:在关系三元组预测中,EIKE的在YAGO39K和DB99K-242的Hits@10分别达到76.2%和50.3%,均超过基线方法(75.1%和48.1%),显示外延建模对实例关系的增强作用。消融实验表明,预训练编码和恒等映射矩阵是关键成功因素。
未来方向包括:1)扩展支持SubPropertyOf等更丰富的逻辑关系;2)用图神经网络替代几何表示以增强表达能力;3)探索动态融合机制替代静态权重组合。这些发展为构建更强大的知识增强系统提供了新思路。
作者简介

汪可予 德国蒂宾根大学研究生,本科毕业于东南大学,主要研究方向包括大语言模型和神经符号人工智能。

漆桂林 东南大学教授、博士生导师,东南大学认知智能研究所所长。曾入选江苏省“六大人才高峰”高层次人才项目。现任中国中文信息学会语言与知识计算专业委员会副主任、中国科技情报学会知识组织专业委员会副主任。2011年11月至2012年2月及2013年6月至7月,担任澳大利亚格里菲斯大学访问教授;2013年1月至2月,担任法国图卢兹第一大学访问教授。ORCID:0000-0002-1957-6961

陈矫彦 英国曼彻斯特大学计算机科学系讲师(助理教授),同时兼任牛津大学计算机科学系高级研究员。此前,他曾任牛津大学全职高级研究员,并在海德堡大学从事博士后研究。陈矫彦本科和博士均毕业于浙江大学计算机科学与技术专业,2014年至2015年,他还曾担任苏黎世大学信息科学系访问博士生。他的主要研究方向包括知识表示、语言模型、数据密集型系统和机器学习。

黄毅 中国移动研究院人工智能与智慧运营中心高级研究员。本科毕业于北京理工大学,获硕士学位,目前在中国清华大学计算机科学与技术系攻读博士学位。主要研究方向为对话系统、知识工程和大语言模型(LLM)。他长期担任自然语言处理领域多个国际顶级会议和期刊(如ACL、EMNLP、AAAI和IJCAI)的审稿人和组织者,已发表专业论文40余篇。

吴天星 东南大学计算机科学与工程学院副教授。2018年毕业于东南大学软件工程专业,获博士学位。2018年至2019年在新加坡南洋理工大学从事博士后研究。主要研究方向为知识图谱、知识表示与推理以及数据挖掘。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









