









前言
- 突然想爬取CSDN的专栏文章到本地保存了,为了影响小一点,特地挑选CSDN的首页进行展示。
- 综合资讯这一测试点是什么找到的呢?就是点击下图的热点文章,然后跳转到具体文章
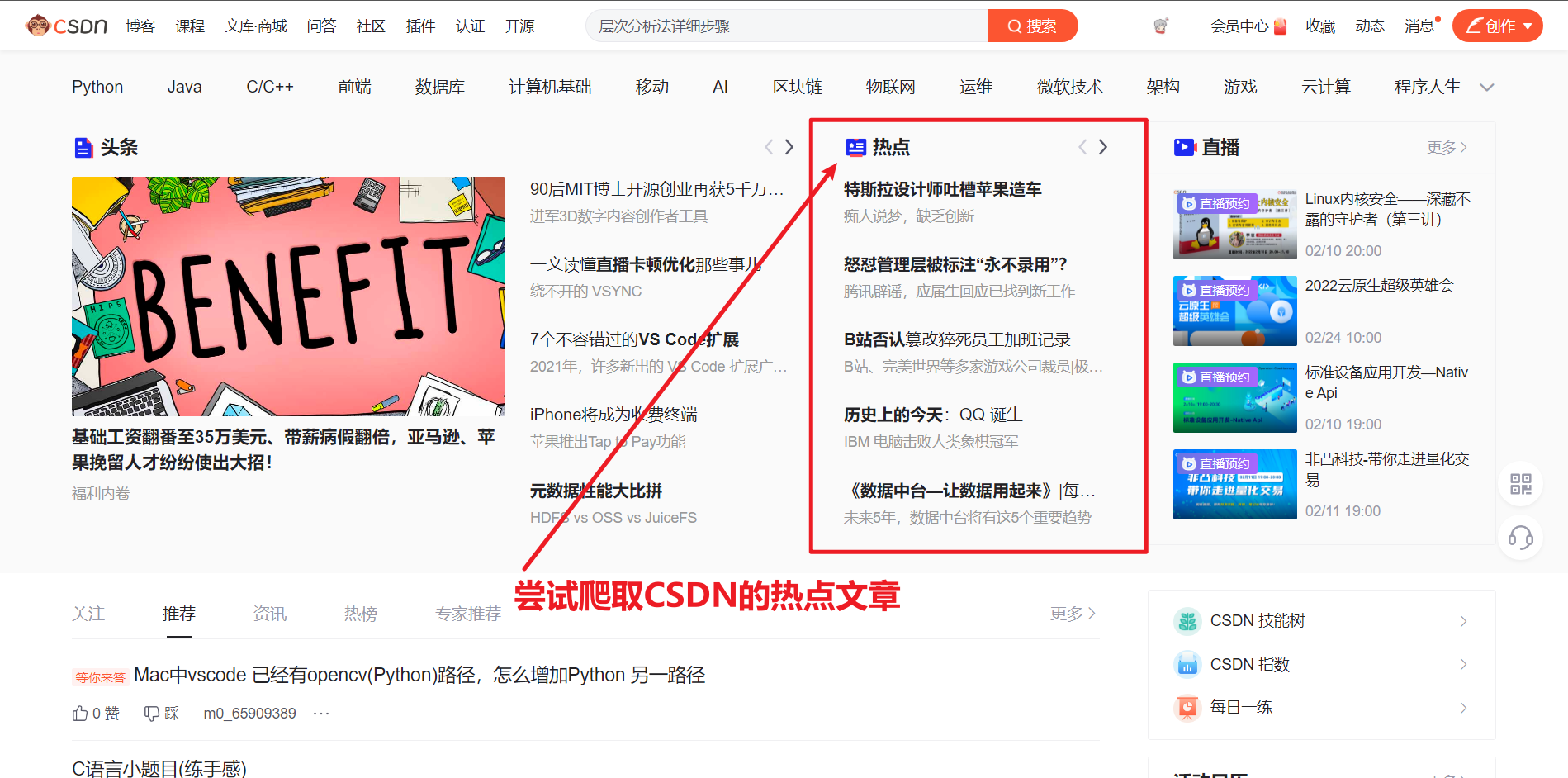
,然后再点击专栏文章,就进入了
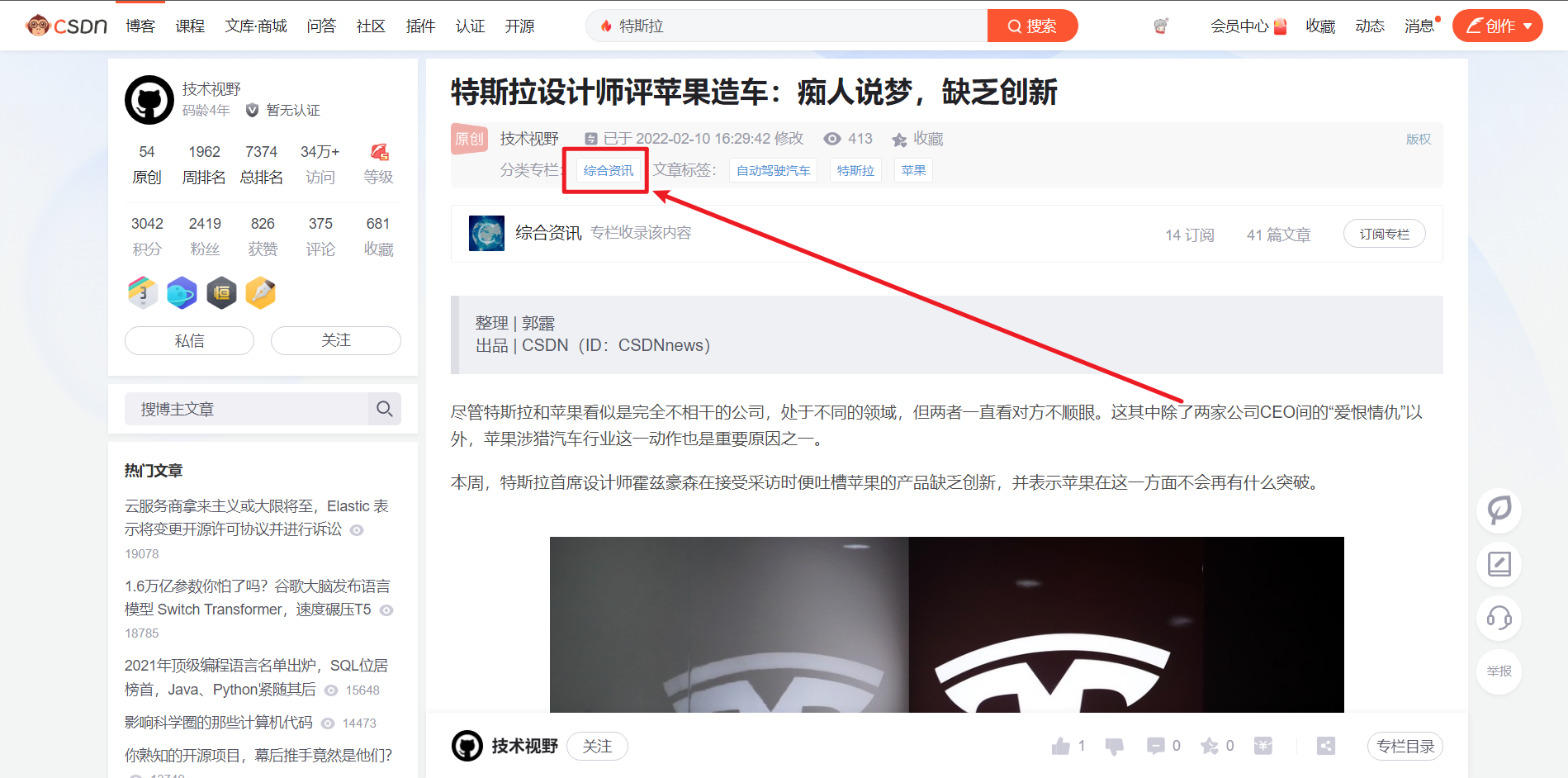
废话少说,直接上代码
-
用面向对象的思维实现了代码
-
代码思路放在了代码注释里面
-
用到了requests、bs4等主流接口
-
剩下的就是,希望大家有空基于这个继续开发完善,哈哈哈哈!!!
-
此代码和实现内容都已经打包上传只Gitee,可以点击查看
“”"
@Author:survive
@Blog(个人博客地址): https://blog.csdn.net/haojie_duan@File:csdn.py.py
@Time:2022/2/10 8:49@Motto:我不知道将去何方,但我已在路上。——宫崎骏《千与千寻》
代码思路:
1.确定目标需求:将csdn文章内容保存成 html、PDF、md格式
- 1.1首先保存为html格式:获取列表页中所有的文章ur1地址,请求文章ur1地址获取我们需要的文章内容
- 1.2 通过 wkhtmitopdf.exe把html文件转换成PDF文件
- 1.3 通过 wkhtmitopdf.exe把html文件转换成md文件2.请求ur1获取网页源代码
3.解析数据,提取自己想要内容
4.保存数据
5.转换数据类型把HTML转换成PDF、md文伴
“”"html_str = “”"
Document {article} """import requests
import parsel
import pdfkit #用来将html转为pdf
import re
import os
import urllib.parse
from bs4 import BeautifulSoup
import html2text #用来将html转换为md
import randomuser_agent库:每次执行一次访问随机选取一个 user_agent,防止过于频繁访问被禁止
USER_AGENT_LIST = [
“Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1”,
“Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11”,
“Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6”,
“Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6”,
“Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)”,
“Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3”,
“Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3”,
“Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3”,
“Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24”,
“Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24”
“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36”
]class CSDNSpider():
def init(self):
self.url = ‘https://blog.csdn.net/csdndevelopers/category_10594816.html’
self.headers = {
‘user-agent’:random.choice(USER_AGENT_LIST)
}def send_request(self, url): response = requests.get(url=url, headers=self.headers) response.encoding = "utf-8" if response.status_code == 200: return response def parse_content(self, reponse): html = reponse.text selector = parsel.Selector(html) href = selector.css('.column_article_list a::attr(href)').getall() name = 00 for link in href: print(link) name = name + 1 # 对文章的url地址发送请求 response = self.send_request(link) if response: self.parse_detail(response, name) def parse_detail(self, response, name): html = response.text # print(html) selector = parsel.Selector(html) title = selector.css('#articleContentId::text').get() # content = selector.css('#content_views').get() # 由于这里使用parsel拿到的网页文件,打开会自动跳转到csdn首页,并且不能转为pdf,就想在这里用soup soup = BeautifulSoup(html, 'lxml') content = soup.find('div',id="content_views",class_=["markdown_views prism-atom-one-light" , "htmledit_views"]) #class_="htmledit_views" # print(content) # print(title, content) html = html_str.format(article=content) self.write_content(html, title) def write_content(self, content, name): html_path = "HTML/" + str(self.change_title(name)) + ".html" pdf_path ="PDF/" + str(self.change_title(name))+ ".pdf" md_path = "MD/" + str(self.change_title(name)) + ".md" # 将内容保存为html文件 with open(html_path, 'w',encoding="utf-8") as f: f.write(content) print("正在保存", name, ".html") # 将html文件转换成PDF文件 config = pdfkit.configuration(wkhtmltopdf=r'G:Devwkhtmltopdfinwkhtmltopdf.exe') pdfkit.from_file(html_path, pdf_path, configuration=config) print("正在保存", name, ".pdf") # os.remove(html_path) # 将html文件转换成md格式 html_text = open(html_path, 'r', encoding='utf-8').read() markdown = html2text.html2text(html_text) with open(md_path, 'w', encoding='utf-8') as file: file.write(markdown) print("正在保存", name, ".md") def change_title(self, title): mode = re.compile(r'[\/:?*"<>|!]') new_title = re.sub(mode,'_', title) return new_title def start(self): response = self.send_request(self.url) if response: self.parse_content(response)if name == ‘main’:
csdn = CSDNSpider()
csdn.start()
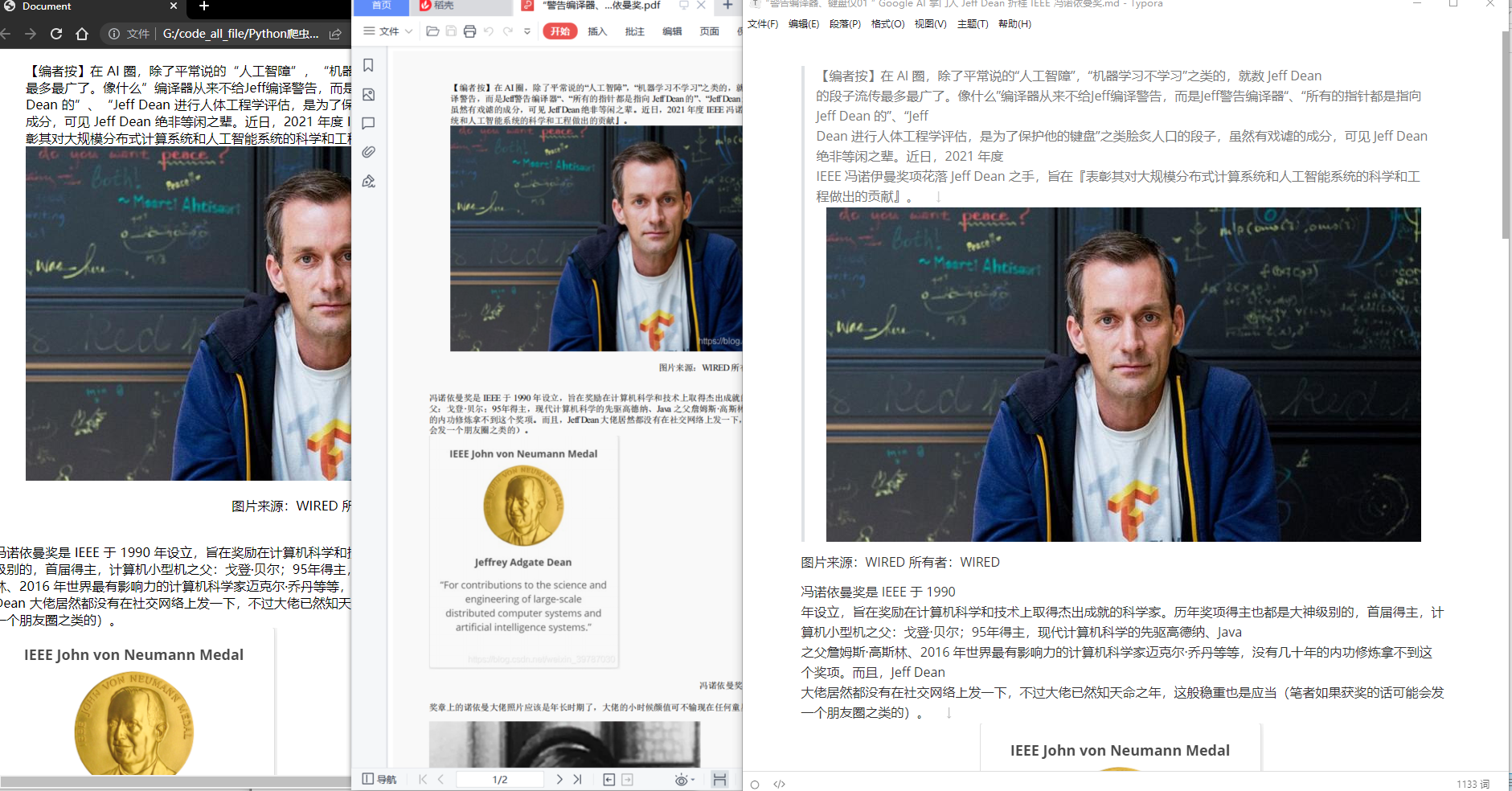
效果如下:
- 从左到右,分别是html、pdf、md格式

- 随便点开一篇文章检查,从左到右,分别是html、pdf、md格式
后记
参考文章:

















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











