







爬虫简介
-
爬虫简介:一段自动抓取互联网信息的程序
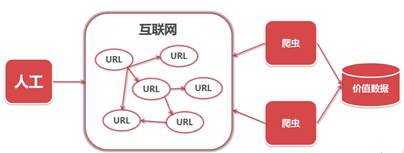
取代人工从浏览器访问,从一个url出发,访问所有的url,并从中获取有价值的数据 -
爬虫有什么用?
举个栗子:我可以把网上各个网站最漂亮的美女图片爬取出来,然后做一个最漂亮最全面的美女图片网
简单的爬虫架构
- 爬虫包含了哪些模块,这些模块怎么组装在一起,完成一个爬取任务
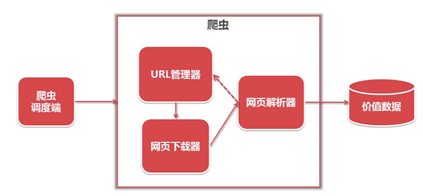
url管理器将url传送给网页下载器,网页解析器将下载的网页进行解析,然后做两个工作:
- 把解析出来的新的url回传给url管理器,继续循环做刚刚的流程
- 将有价值的数据提取出来
爬虫并不是将我们需要的数据爬取下载,而是将整个网页下载下来,在进行解析和提取,理解这点对我们后面的学习很有帮助
架构中的三大模块
url管理器
url管理器将url传送给网页下载器,防止重复抓取和循环抓取
网页下载器
将互联网上url对应的网页下载到本地的工具,这里用 urllib.request
urllib.request:(在python2中叫urllib2)
**> import urllib.request
#用一个字典保存header(模拟Mozilla浏览器)这个信息在浏览器上是可以查到的,有兴趣的可以自己去查资料看一看
headers={ “User-Agent”: " Mozilla/5.0 (Windows NT 6.1; Win64; x64)" }
#用Request方法把url和headers组合一起构造一个请求
#Request原型为Request(url,data,headers),这里是get请求,不需要post data,所以没有第二个参数data,所以指定headers=headers,告诉函数没有data参数
request =urllib.request.Request(url,headers=headers)
#用urlopen方法发送这个request请求,将返回值放入
response response = urllib.request.urlopen(request)
#将网页内容给html html = response.read()
#(当然还有别的方法,这个是稳定性相对较高,也比较容易理解的一种方法)**
import urllib.request #导包
url = "http://www.baidu.com"
headers = {
"User-Agent": " Mozilla/5.0 (Windows NT 6.1; Win64; x64)"} #伪装浏览器
request = urllib.request.Request(url,headers = headers) #通过Request创建request对象
response = urllib.request.urlopen(request) #通过urlopen创建response对象
html = response.read() #保存网页内容
print(len(html)) #输出网页的html的长度
网页解析器
四种网页解析器
- 正则表达式:比较直观,但比较复杂(字符串的模糊匹配)
- html.parser
- lxml
- BeautifulSoup:第三方插件,可以使用html.parser和lxml做为他的解析器,比较强大(结构化解析器)

网页的基本结构:

-
安装并测试beautifulsoup4:
(打开cmd,切换到python安装目录的Scripts文件夹中)
安装:pip install beatifulsoup4
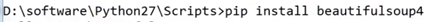
-
创建beautifulsoup对象:soup = BeautifulSoup(html, “lxml”)
其中html为刚刚下载的网页,lxml为网页解析器,也可以使用html.parser -
搜索节点:find_all(), find()
find_all()方法的原型:find_all(name, attrs, string)
name:节点的名称
attrs:节点的属性
string:节点的文字
例: 查找所有标签为a的节点:node = soup.find_all(‘a’)
查找所有标签为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 403
403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









