






1. 基本概念
PageRank由Google创始人提出,是Google用来标识网页的重要性的一种方法,主要用于网页的排序,PR值越高说明网站越重要,故其排名也越靠前。某个网页的PageRank值可以理解为用户随机浏览点击网页最终将会到达这个特定网页的可能性,一个网页被越多的网页所指,说明这个网页越重要。
2. 重要假设
- 数量假设:在Web图模型中,如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要。
- 质量假设:指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更多的权重,越是质量高的页面指向页面A,则页面A越重要。
一个节点的重要性取决于入链的数量以及入链的质量。
3. 基础算法
(1)简单计算
公式:
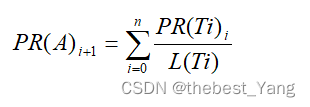
(节点A在第i+1次循环时的PR值等于,指向A节点的其他节点在第i次循环的PR值除以该节点的出度的值之和)
PR初始化值常用方法可以为1/N(N为网络节点个数),也可以为1,在这里选择1/N
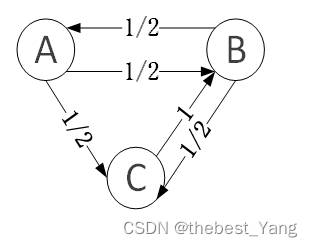
图1
以图1为例,具体运算如下: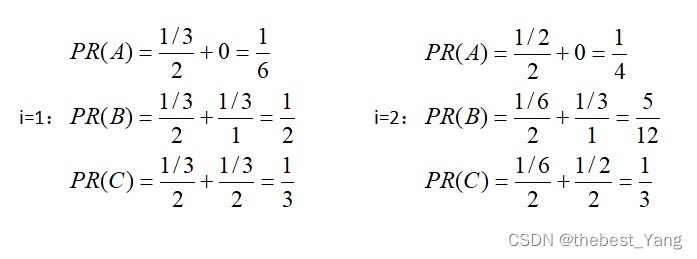
| 循环次数 PR值 | PR(A) | PR(B) | PR(C) |
| i=0(PR=1/N) | 1/3 | 1/3 | 1/3 |
| i=1 | 1/6 | 1/2 | 1/3 |
| i=2 | 1/4 | 5/12 | 1/3 |
(2)矩阵算法
公式:
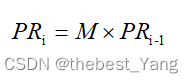
(M是网络的转移概率矩阵(马尔科夫矩阵),PRi-1是i-1时的PR矩阵)
还是以图1为例,转移概率矩阵的具体计算:1.画出网络的邻接矩阵;2.将邻接矩阵中非零的行向量元素都除以该元素对应行中,非零元素的个数;3.对2中的矩阵进行转置,即为转移概率矩阵
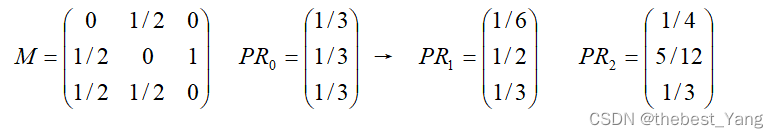
4. dead ends问题
示例1:
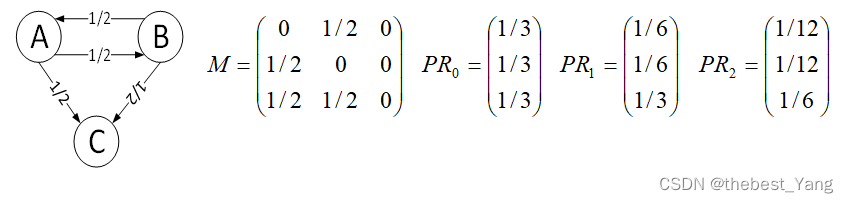
能看出PR值在等比例减小,无限趋近于0,没有办法达到一个收敛于稳定值的效果。
示例2:
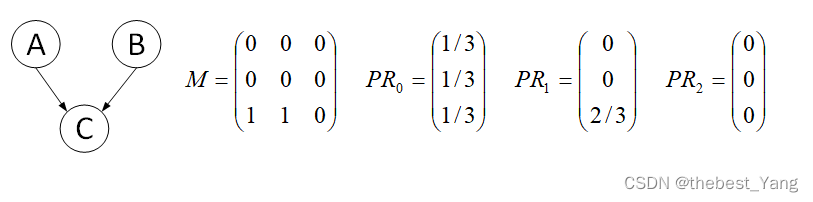
在这种情况下,PR值最后都为0。
解决办法:
某个节点的出度为0时,其对应的列向量元素都为零,提出一个修正方法将原公式中的M改为M+aT(e/n),公式转换为:
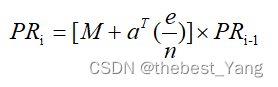
其中a=[a0,a1,…,an],当某个节点没有出链,即其列向量元素为0时,对应的ai=1,其余时候ai=0;e是元素全为1的n*n矩阵;n为节点个数。
其实就是用1/n来填补出链为0的节点在矩阵中所对应的列向量。
认为在出链为0的情况下,继续浏览该页面或跳转到网络中其他页面的概率相同,都为1/n。
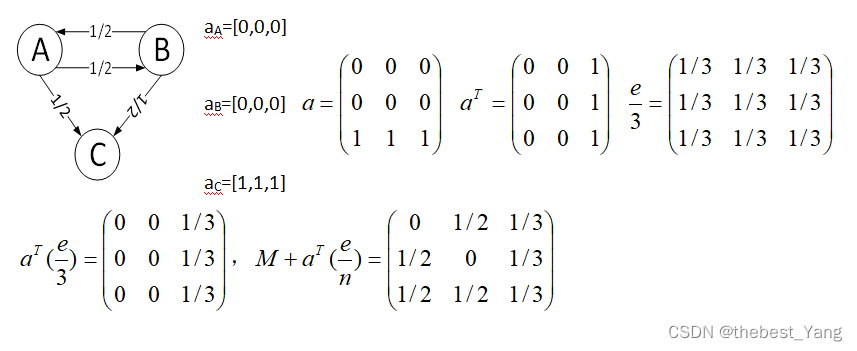
5.spider traps问题
spider traps是指网页唯一的指向了它本身,与其他节点没有出链,会导致PR值出现偏移。
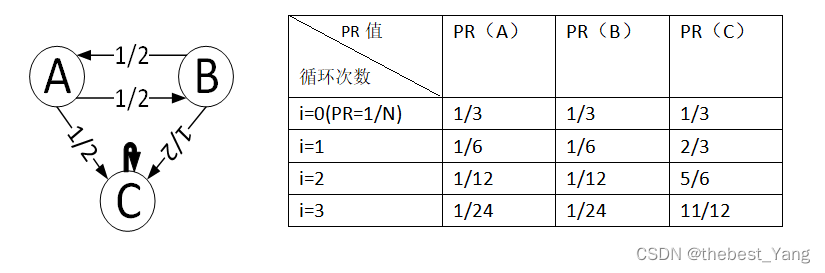
可知没有出链且唯一指向自己的节点,其PR值最终将无限趋近于1。
解决办法:
在Google网页排序的背景下,遇到出链为0的情况,即某个网站没有向下一个页面跳转的链接(出链),这时用户有一定概率跳转到其他网页。我们将用户正常浏览,即在网页中跟随出链打开下一个网页的概率设为β,将用户跳转到其他网页的概率设为1-β,这样能够在一定程度上解决出链为0的情况。对M进行修正:
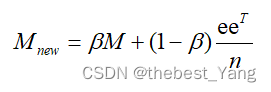
其中eeT为由1填满的n*n矩阵,β在应用中一般取值0.85。
新公式为:
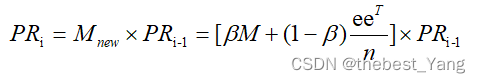

6.最终修正公式
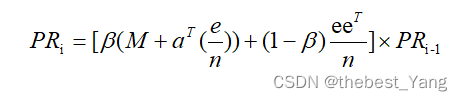
文章参考了b站帅器学习《PageRank算法》















 871
871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









