







目录
1.awk 简介
-
awk 以记录和字段的方式来查看文本文件
-
和其他编程语言一样, awk 包含变量、条件和循环
-
awk 能够进行运算和字符串操作
-
awk 能够生成格式化的报表数据
2.awk 概述
awk 程序 awk 命令、括在括号(或写在文件)中的程序指令以及输入文件的文件名几个部分组成。如果没有输入文件,输入则来自于标准输入。
awk 指令由模式、操作或者模式与操作的组合组成。模式是由某种类型的表达式组成的语句。如果某个表达式中没有出现关键在 if ,但实际在计算时却暗含 if 这个词,那么这个表达式就是模式。操作由括在大括号中的一条或多条语句组成,语句之间用分号或者换行符隔开。模式不能括在大括号中,模式由包括在两个正斜杠之间的正则表达式、一个或多个 awk 操作符组成的表达式组成。
格式:
awk '/search pattern1/ {Actions}
/search pattern2/ {Actions}' file
3. 工作原理
-
awk 使用一行作为输入(通过文件或者管道),并将这一行赋给内部变量 $0
-
行被空格分解为字段(单词),每一个字段存储在已编号的变量中,从 $1 开始。( awk 的内部变量 FS 用来确定字段的分隔符。初始时,为空格,包含制表符和空格符)
-
对于一行,按照给定的正则表达式的顺序进行匹配,如果匹配则执行对应的 Action ,如果没有匹配上则不执行任何动作 , Search Pattern 和 Action 是可选的,但是必须提供其中一个 。如果 Search Pattern 未提供,则对所有的输入行执行 Action 操作。如果 Action 未提供,则默认打印出该行的数据 。 {} 这种 Action 不做任何事情,和未提供的 Action 的工作方式不一样
-
打印字段,用 print 、 printf 、 sprintf ,格式: { print $1, $3 } 内部变量 output field separator ( OFS ),默认为空格, $n 之间的逗号被 OFS 中的字符替换。
-
输出之后,从文件中另取一行,并将其复制到 $0 中,覆盖原来的内容。重复进行……
4.gawk程序的可用选项

5.基础使用示例
5.1 使用数据字段变量:
- $0 代表整个文本行;
- $1 代表文本行中的第1个数据字段;
- $2 代表文本行中的第2个数据字段;
- $n 代表文本行中的第n个数据字段。
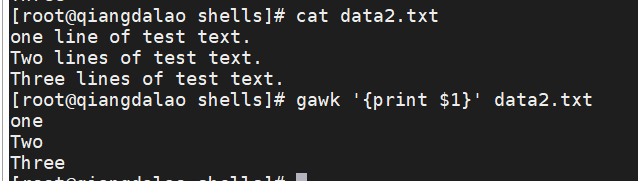
该程序用 $1 字段变量来仅显示每行文本的第1个数据字段。
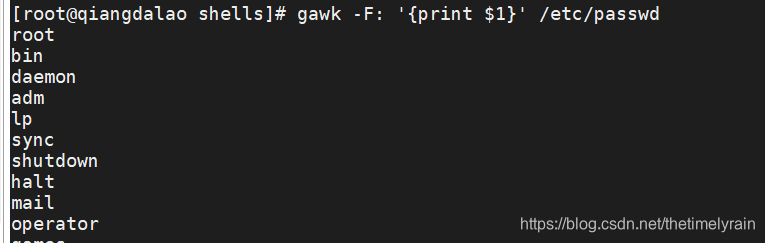
5.2 指定分隔符
如果你要读取采用了其他字段分隔符的文件,可以用 -F 选项指定。
gawk -F: '{print $1}' /etc/passwd这个简短的程序显示了系统中密码文件的第1个数据字段。由于/etc/passwd文件用冒号来分隔数字字段,因而如果要划分开每个数据元素,则必须在 gawk 选项中将冒号指定为字段分隔符
5.3 在程序脚本中使用多个命令
如果一种编程语言只能执行一条命令,那么它不会有太大用处。gawk编程语言允许你将多条命令组合成一个正常的程序。要在命令行上的程序脚本中使用多条命令,只要在命令之间放个分号即可。

第一条命令会给字段变量 $4 赋值。第二条命令会打印整个数据字段。注意, gawk程序在输出中已经将原文本中的第四个数据字段替换成了新值。
5.4 从文件中读取程序
跟sed编辑器一样,gawk编辑器允许将程序存储到文件中,然后再在命令行中引用
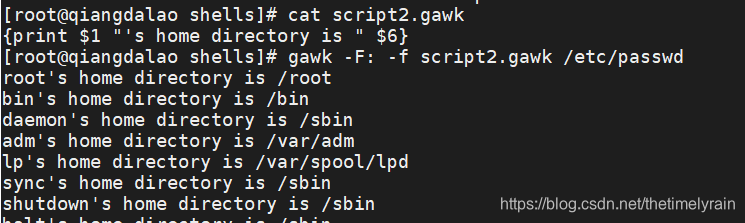
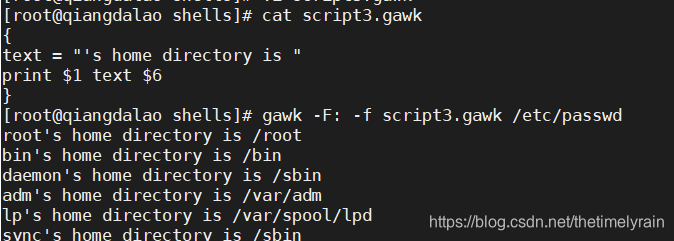
script2.gawk程序脚本会再次使用 print 命令打印/etc/passwd文件的主目录数据字段(字段变量 $6 ),以及 userid 数据字段(字段变量 $1 )。
可以在程序文件中指定多条命令。要这么做的话,只要一条命令放一行即可,不需要用分号。
5.5 在处理数据前后运行脚本
gawk还允许指定程序脚本何时运行。默认情况下,gawk会从输入中读取一行文本,然后针对该行的数据执行程序脚本。有时可能需要在处理数据前运行脚本,比如为报告创建标题。 BEGIN关键字就是用来做这个的。它会强制gawk在读取数据前执行 BEGIN 关键字后指定的程序脚本。
![]()
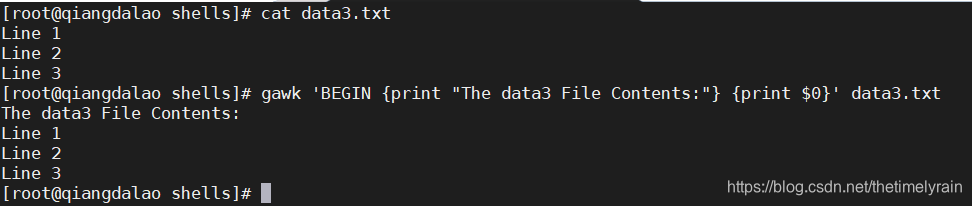
在gawk执行了BEGIN脚本后,它会用第二段脚本来处理文件数据。这么做时要小心,两段脚本仍然被认为是 gawk 命令行中的一个文本字符串。你需要相应地加上单引号。
与 BEGIN 关键字类似, END 关键字允许你指定一个程序脚本,gawk会在读完数据后执行它。

6 进阶使用
6.1内置变量
1.字段和记录分隔符变量:

变量 FS 和 OFS 定义了gawk如何处理数据流中的数据字段。你已经知道了如何使用变量 FS 来定义记录中的字段分隔符。变量 OFS 具备相同的功能,只不过是用在 print 命令的输出上。默认情况下,gawk将 OFS 设成一个空格,所以如果你用命令:
print $1,$2,$3会看到如下输出:
field1 field2 field3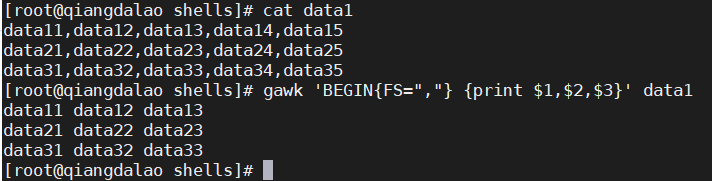
print 命令会自动将 OFS 变量的值放置在输出中的每个字段间。通过设置 OFS 变量,可以在输出中使用任意字符串来分隔字段。

FIELDWIDTHS 变量允许你不依靠字段分隔符来读取记录。在一些应用程序中,数据并没有使用字段分隔符,而是被放置在了记录中的特定列。这种情况下,必须设定 FIELDWIDTHS 变量来匹配数据在记录中的位置。一旦设置了 FIELDWIDTH 变量,gawk就会忽略 FS 变量,并根据提供的字段宽度来计算字段。下面是个采用字段宽度而非字段分隔符的例子。
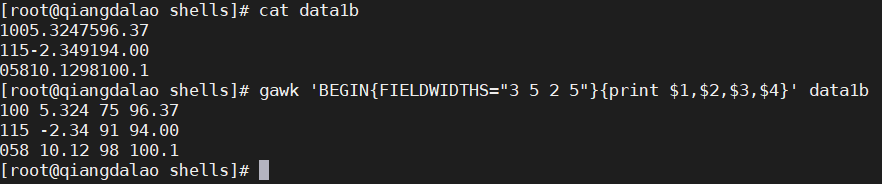
FIELDWIDTHS 变量定义了四个字段,gawk依此来解析数据记录。每个记录中的数字串会根据已定义好的字段长度来分割
警告 :一定要记住,一旦设定了 FIELDWIDTHS 变量的值,就不能再改变了。这种方法并不适用于变长的字段。
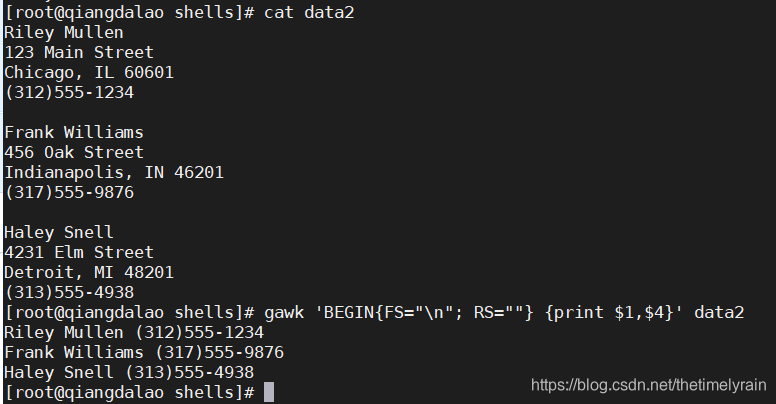
变量 RS 和 ORS 定义了gawk程序如何处理数据流中的字段。默认情况下,gawk将 RS 和 ORS 设为换行符。默认的 RS 值表明,输入数据流中的每行新文本就是一条新纪录。有时,你会在数据流中碰到占据多行的字段。典型的例子是包含地址和电话号码的数据,其
中地址和电话号码各占一行。
Riley Mullen
123 Main Street
Chicago, IL 60601
(312)555-1234如果你用默认的 FS 和 RS 变量值来读取这组数据,gawk就会把每行作为一条单独的记录来读取,并将记录中的空格当作字段分隔符。这可不是你希望看到的。要解决这个问题,只需把 FS 变量设置成换行符。这就表明数据流中的每行都是一个单独的字段,每行上的所有数据都属于同一个字段。但现在令你头疼的是无从判断一个新的数据行从何开始。
对于这一问题,可以把 RS 变量设置成空字符串,然后在数据记录间留一个空白行。gawk会把每个空白行当作一个记录分隔符。
2.数据变量
除了字段和记录分隔符变量外,gawk还提供了其他一些内建变量来帮助你了解数据发生了什么变化,并提取shell环境的信息

你应该能从上面的列表中认出一些shell脚本编程中的变量。 ARGC 和 ARGV 变量允许从shell中获得命令行参数的总数以及它们的值。但这可能有点麻烦,因为gawk并不会将程序脚本当成命令行参数的一部分。

ARGC 变量表明命令行上有两个参数。这包括 gawk 命令和 data1 参数(记住,程序脚本并不算参数)。 ARGV 数组从索引 0 开始,代表的是命令。第一个数组值是 gawk 命令后的第一个命令行参数。
说明 跟shell变量不同,在脚本中引用gawk变量时,变量名前不加美元符。

ENVIRON["HOME"] 变量从shell中提取了 HOME 环境变量的值。类似地, ENVIRON["PATH"] 提取了 PATH 环境变量的值。可以用这种方法来从shell中提取任何环境变量的值,以供gawk程序使用。
当要在gawk程序中跟踪数据字段和记录时,变量 FNR 、 NF 和 NR 用起来就非常方便。有时你并不知道记录中到底有多少个数据字段。 NF 变量可以让你在不知道具体位置的情况下指定记录中的最后一个数据字段。
NF: The variable NF is set to the total number of fields in the input record.
NR:The total number of input records seen so far.

NF 变量含有数据文件中最后一个数据字段的数字值。可以在它前面加个美元符将其用作字段变量。
FNR 和 NR 变量虽然类似,但又略有不同。 FNR 变量含有当前数据文件中已处理过的记录数,NR 变量则含有已处理过的记录总数。让我们看几个例子来了解一下这个差别
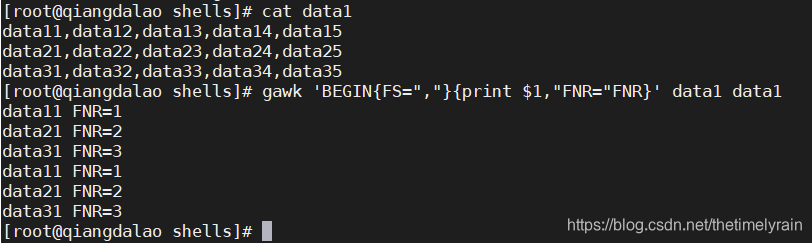
在这个例子中,gawk程序的命令行定义了两个输入文件(两次指定的是同样的输入文件)。这个脚本会打印第一个数据字段的值和 FNR 变量的当前值。注意,当gawk程序处理第二个数据文件时, FNR 值被设回了 1 。

FNR 变量的值在 gawk 处理第二个数据文件时被重置了,而 NR 变量则在处理第二个数据文件时继续计数。结果就是:如果只使用一个数据文件作为输入, FNR 和 NR 的值是相同的;如果使用多个数据文件作为输入, FNR 的值会在处理每个数据文件时被重置,而 NR 的值则会继续计数直到处理完所有的数据文件。
6.2自定义变量
跟其他典型的编程语言一样,gawk允许你定义自己的变量在程序代码中使用。gawk自定义变量名可以是任意数目的字母、数字和下划线,但不能以数字开头。重要的是,要记住 gawk 变量名区分大小写
1. 在脚本中给变量赋值
在gawk程序中给变量赋值跟在shell脚本中赋值类似,都用赋值语句
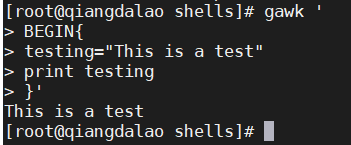
print 语句的输出是 testing 变量的当前值。跟shell脚本变量一样, gawk 变量可以保存数值或文本值
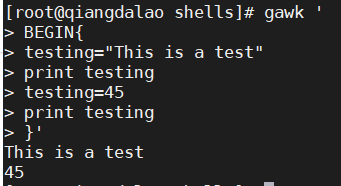
在这个例子中, testing 变量的值从文本值变成了数值.赋值语句还可以包含数学算式来处理数字值:

2.在命令行上给变量赋值
也可以用 gawk 命令行来给程序中的变量赋值。这允许你在正常的代码之外赋值,即时改变变量的值。下面的例子使用命令行变量来显示文件中特定数据字段
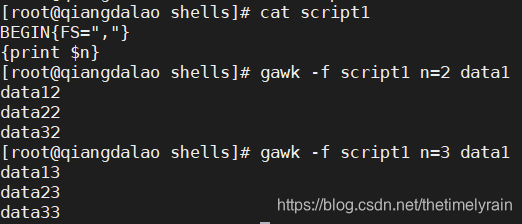
这个特性可以让你在不改变脚本代码的情况下就能够改变脚本的行为。第一个例子显示了文件的第二个数据字段,第二个例子显示了第三个数据字段,只要在命令行上设置 n 变量的值就行。使用命令行参数来定义变量值会有一个问题。在你设置了变量后,这个值在代码的 BEGIN 部分不可用。
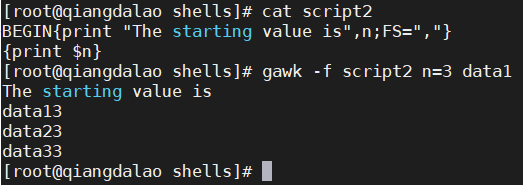
可以用 -v 命令行参数来解决这个问题。它允许你在 BEGIN 代码之前设定变量。在命令行上,-v 命令行参数必须放在脚本代码之前。

6.3 处理数组
1.定义数组变量
可以用标准赋值语句来定义数组变量。数组变量赋值的格式如下:
var[index] = element其中 var 是变量名, index 是关联数组的索引值, element 是数据元素值。下面是一些gawk中数组变量的例子。在引用数组变量时,必须包含索引值来提取相应的数据元素值
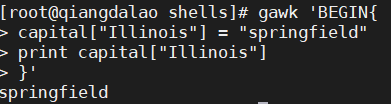
在引用数组变量时,会得到数据元素的值。数据元素值是数字值时也一样:
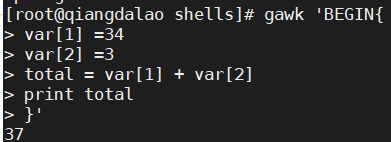
2.遍历数组变量
关联数组变量的问题在于你可能无法知晓索引值是什么。跟使用连续数字作为索引值的数字数组不同,关联数组的索引可以是任何东西。如果要在gawk中遍历一个关联数组,可以用 for 语句的一种特殊形式。
for (var in array)
{
statements
}这个 for 语句会在每次循环时将关联数组 array 的下一个索引值赋给变量 var ,然后执行一遍 statements 。重要的是记住这个变量中存储的是索引值而不是数组元素值。可以将这个变量用作数组的索引,轻松地取出数据元素值。
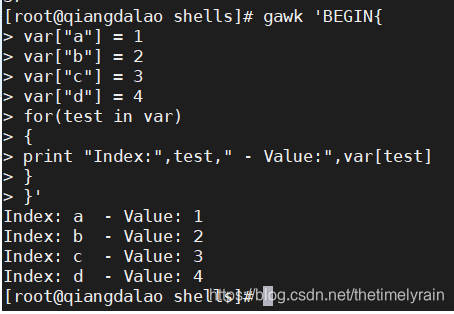
注意:索引值不会按任何特定顺序返回,但它们都能够指向对应的数据元素值。明白这点很重要,因为你不能指望着返回的值都是有固定的顺序,只能保证索引值和数据值是对应的
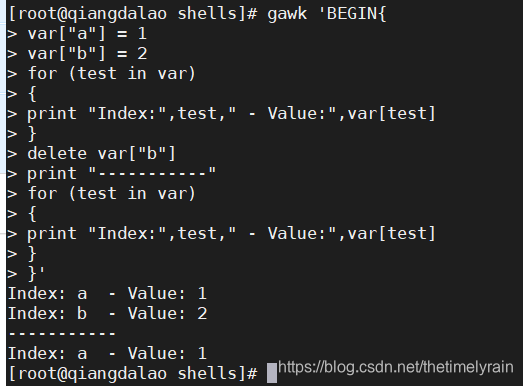
3.删除数组变量
从关联数组中删除数组索引要用一个特殊的命令
delete array[index]删除命令会从数组中删除关联索引值和相关的数据元素值
6.4 使用模式
1.正则表达式
在使用正则表达式时,正则表达式必须出现在它要控制的程序脚本的左花括号前。
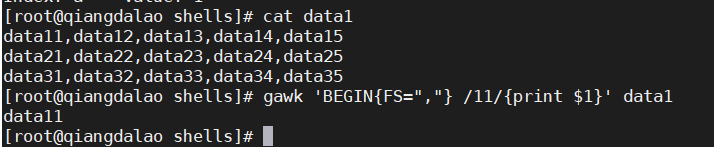
正则表达式 /11/ 匹配了数据字段中含有字符串 11 的记录。gawk程序会用正则表达式对记录中所有的数据字段进行匹配,包括字段分隔符。
2.匹配操作符
匹配操作符(matching operator)允许将正则表达式限定在记录中的特定数据字段。匹配操作符是波浪线( ~ )。可以指定匹配操作符、数据字段变量以及要匹配的正则表达式.
$1 ~ /^data/$1 变量代表记录中的第一个数据字段。这个表达式会过滤出第一个字段以文本 data 开头的所有记录。下面是在gawk程序脚本中使用匹配操作符的例子。

匹配操作符会用正则表达式 /^data2/ 来比较第二个数据字段,该正则表达式指明字符串要以文本 data2 开头。并使用$0打印整行内容.这可是件强大的工具,gawk程序脚本中经常用它在数据文件中搜索特定的数据元素

这个例子会在第一个数据字段中查找文本 root。如果在记录中找到了这个模式,它会打印该记录的第一个和最后一个数据字段值。
你也可以用 ! 符号来排除正则表达式的匹配
$1 !~ /expression/如果记录中没有找到匹配正则表达式的文本,程序脚本就会作用到记录数据
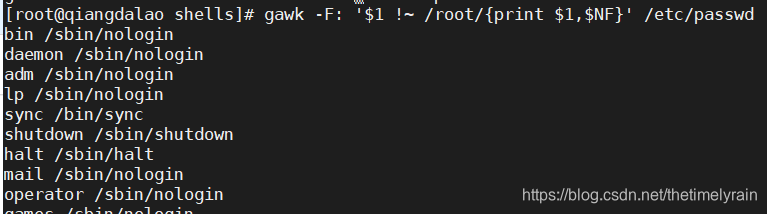
在这个例子中,gawk程序脚本会打印/etc/passwd文件中与用户ID root不匹配的用户ID和登录shell。
3.数学表达式
除了正则表达式,你也可以在匹配模式中用数学表达式。这个功能在匹配数据字段中的数字值时非常方便。举个例子,如果你想显示所有属于root用户组(组ID为 0 )的系统用户,可以用这个脚本。
gawk -F: '$4 == 0{print $1}' /etc/passwd
这段脚本会查看第四个数据字段含有值 0 的记录。在这个Linux系统中,有五个用户账户属于root用户组。
可以使用任何常见的数学比较表达式:
- x == y :值x等于y。
- x <= y :值x小于等于y。
- x < y :值x小于y。
- x >= y :值x大于等于y。
- x > y :值x大于y。
也可以对文本数据使用表达式,但必须小心。跟正则表达式不同,表达式必须完全匹配。数据必须跟模式严格匹配
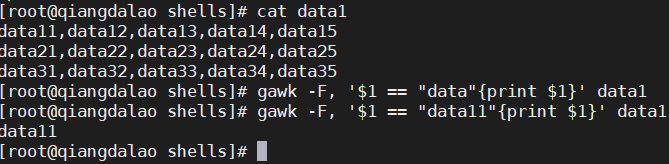
第一个测试没有匹配任何记录,因为第一个数据字段的值不在任何记录中。第二个测试用值data11 匹配了一条记录。
6.5 结构化命令
1. if 语句
gawk编程语言支持标准的 if-then-else 格式的 if 语句。你必须为 if 语句定义一个求值的条件,并将其用圆括号括起来。如果条件求值为 TRUE ,紧跟在 if 语句后的语句会执行。如果条件求值为 FALSE ,这条语句就会被跳过。可以用这种格式:
if (condition)
statement1也可以将它放在一行上,像这样:
if (condition) statement1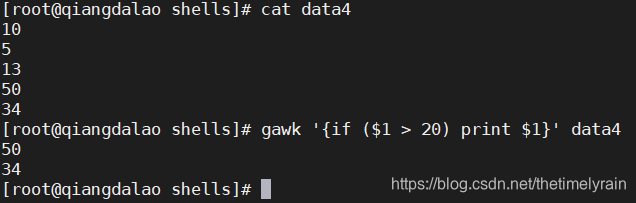
如果需要在 if 语句中执行多条语句,就必须用花括号将它们括起来。
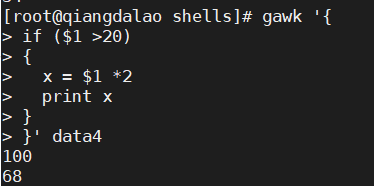
gawk 的 if 语句也支持 else 子句,允许在 if 语句条件不成立的情况下执行一条或多条语句。这里有个使用 else 子句的例子
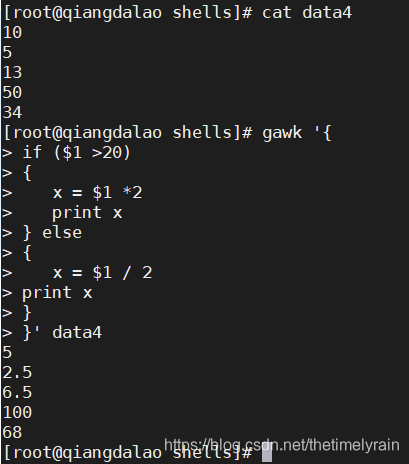
可以在单行上使用 else 子句,但必须在 if 语句部分之后使用分号
if (condition) statement1; else statement2以下是上一个例子的单行格式版本:

2.while 语句
while 语句为gawk程序提供了一个基本的循环功能。下面是 while 语句的格式:
while (condition)
{
statements
}while 循环允许遍历一组数据,并检查迭代的结束条件。如果在计算中必须使用每条记录中的多个数据值,这个功能能帮得上忙。
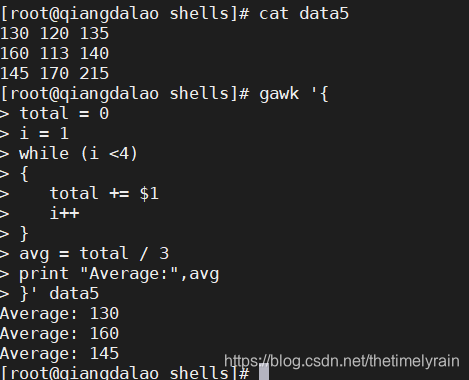
while 语句会遍历记录中的数据字段,将每个值都加到 total 变量上,并将计数器变量 i 增值。当计数器值等于 4 时, while 的条件变成了 FALSE ,循环结束,然后执行脚本中的下一条语句。这条语句会计算并打印出平均值。这个过程会在数据文件中的每条记录上不断重复
gawk编程语言支持在 while 循环中使用 break 语句和 continue 语句,允许你从循环中跳出。
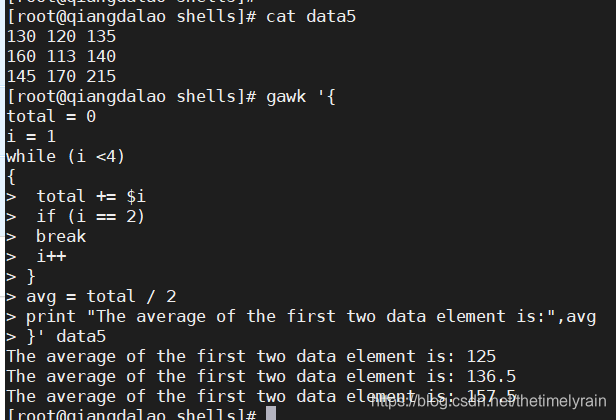
break 语句用来在 i 变量的值为 2 时从 while 循环中跳出。do-while语句使用较少,在此不介绍。
3.for语句
for 语句是许多编程语言执行循环的常见方法。gawk编程语言支持C风格的 for 循环。
for( variable assignment; condition; iteration process)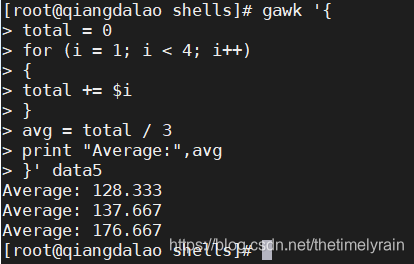
6.6 格式化打印
本文不做说明
6.7 内建函数
1.数学函数
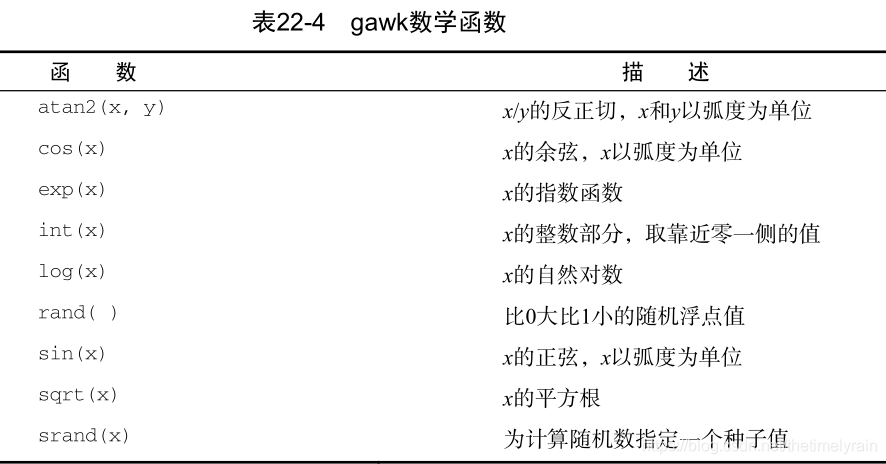
在使用一些数学函数时要小心,因为gawk语言对于它能够处理的数值有一个限定区间。如果超出了这个区间,就会得到一条错误消息

第一个例子会计算e的100次幂,虽然数值很大,但尚在系统的区间内。第二个例子尝试计算e的1000次幂,已经超出了系统的数值区间,所以就生成了一条错误消息。
除了标准数学函数外,gawk还支持一些按位操作数据的函数。
- and(v1, v2) :执行值 v1 和 v2 的按位与运算。
- compl(val) :执行 val 的补运算。
- lshift(val, count) :将值 val 左移 count 位。
- or(v1, v2) :执行值 v1 和 v2 的按位或运算。
- rshift(val, count) :将值 val 右移 count 位。
- xor(v1, v2) :执行值 v1 和 v2 的按位异或运算
2.字符串函数
gawk编程语言还提供了一些可用来处理字符串值的函数:



3. 时间函数
gawk编程语言包含一些函数来帮助处理时间值:

时间函数常用来处理日志文件,而日志文件则常含有需要进行比较的日期。通过将日期的文本表示形式转换成epoch时间(自1970-01-01 00:00:00 UTC到现在的秒数),可以轻松地比较日期。
下面是在gawk程序中使用时间函数的例子。
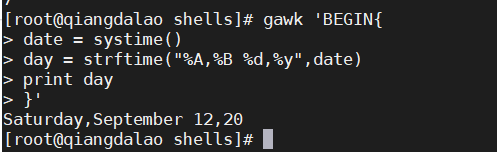
该例用 systime 函数从系统获取当前的epoch时间戳,然后用 strftime 函数将它转换成用户可读的格式,转换过程中使用了shell命令 date 的日期格式化字符。
4.自定义函数
本文不做说明。
7.实例
举例来说,我们手边有一个数据文件,其中包含了两支队伍(每队两名选手)的保龄球比赛得分情况
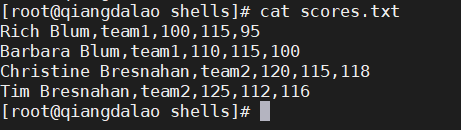
每位选手都有三场比赛的成绩,这些成绩都保存在数据文件中,每位选手由位于第二列的队名来标识。下面的脚本对每队的成绩进行了排序,并计算了总分和平均分。
#!/bin/bash
for team in $(gawk -F, '{print $2}' scores.txt | uniq)
do
gawk -v team=$team 'BEGIN{FS=",";total=0}
{
if ($2==team)
{
total += $3 + $4 + $5;
}
}
END {
avg = total / 6;
print "Total for", team, "is", total, ",the average is",avg
}' scores.txt
done
for 循环中的第一条语句过滤出数据文件中的队名,然后使用 uniq 命令返回不重复的队名。for 循环再对每个队进行迭代。for 循环内部的 gawk 语句进行计算操作。对于每一条记录,首先确定队名是否和正在进行循环的队名相符。这是通过利用 gawk 的 -v 选项来实现的,该选项允许我们在gawk程序中传递shell变量。如果队名相符,代码会对数据记录中的三场比赛得分求和,然后将每条记录的值再相加,只要数据记录属于同一队。
在循环迭代的结尾处,gawk代码会显示出总分以及平均分。输出结果如下。

其中for循环的变量定义还有另外一种方式:
#!/bin/bash
teams=$(gawk -F, '{print $2}' scores.txt | uniq)
for team in ${teams[@]}
do
gawk -v team=$team 'BEGIN{FS=",";total=0}
{
if ($2==team)
{
total += $3 + $4 + $5;
}
}
END {
avg = total / 6;
print "Total for", team, "is", total, ",the average is",avg
}' scores.txt
done
输出的结果也是一样的。
参考书籍:Linux命令行与shell脚本编程大全.第3版.pdf

















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









