







超大分页怎么处理?
当数据库数据量达到百万级别,而我们又需要在查询条件之后使用limit进行分页,那么我们就不能简单的使用普通的sql语句了。比如我们有下面一张表:
CREATE TABLE `vote_record` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`user_id` varchar(20) NOT NULL DEFAULT '' COMMENT '用户Id',
`vote_num` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '投票数',
`group_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '用户组id 0-未激活用户 1-普通用户 2-vip用户 3-管理员用户',
`status` tinyint(2) unsigned NOT NULL DEFAULT '1' COMMENT '状态 1-正常 2-已删除',
`create_time` datetime NOT NULL DEFAULT '0000-00-00 00:00:00',
PRIMARY KEY (`id`),
KEY `vote_num` (`vote_num`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1000000 DEFAULT CHARSET=utf8 COMMENT='投票记录表';数据量达到百万级别:
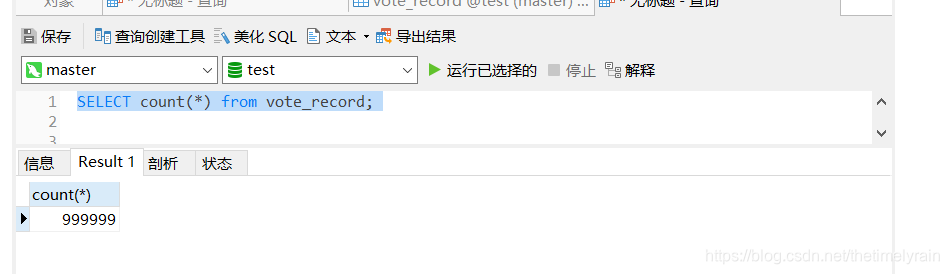
如果在这个时候我们按投票数检索并且需要分页怎么办?最初的sql如下:
SELECT * from vote_record where vote_num >200 limit 800000,10;看下查询时间:
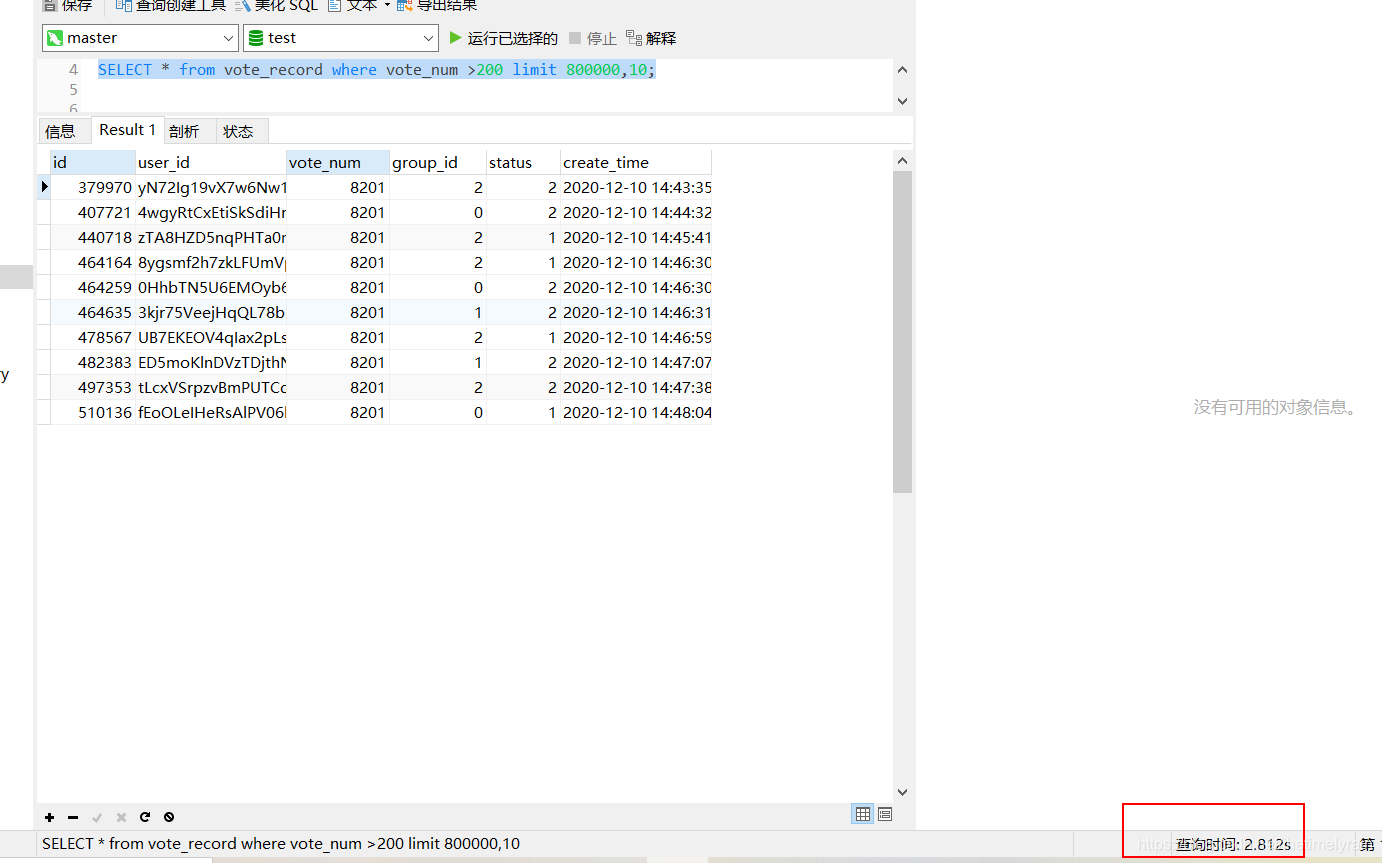
时间达到了2.8秒,这个显然不符合我们的预期,那么我们可以怎么优化呢?这条语句需要加载至少800000数据然后基本上全部丢弃,只取10条,当然比较慢.由于我们在vote_num上建立了索引,所以我们可以使用子查询的方法,先使用覆盖索引找到符号条件的id,再使用聚簇索引查询数据,简单来说就是:
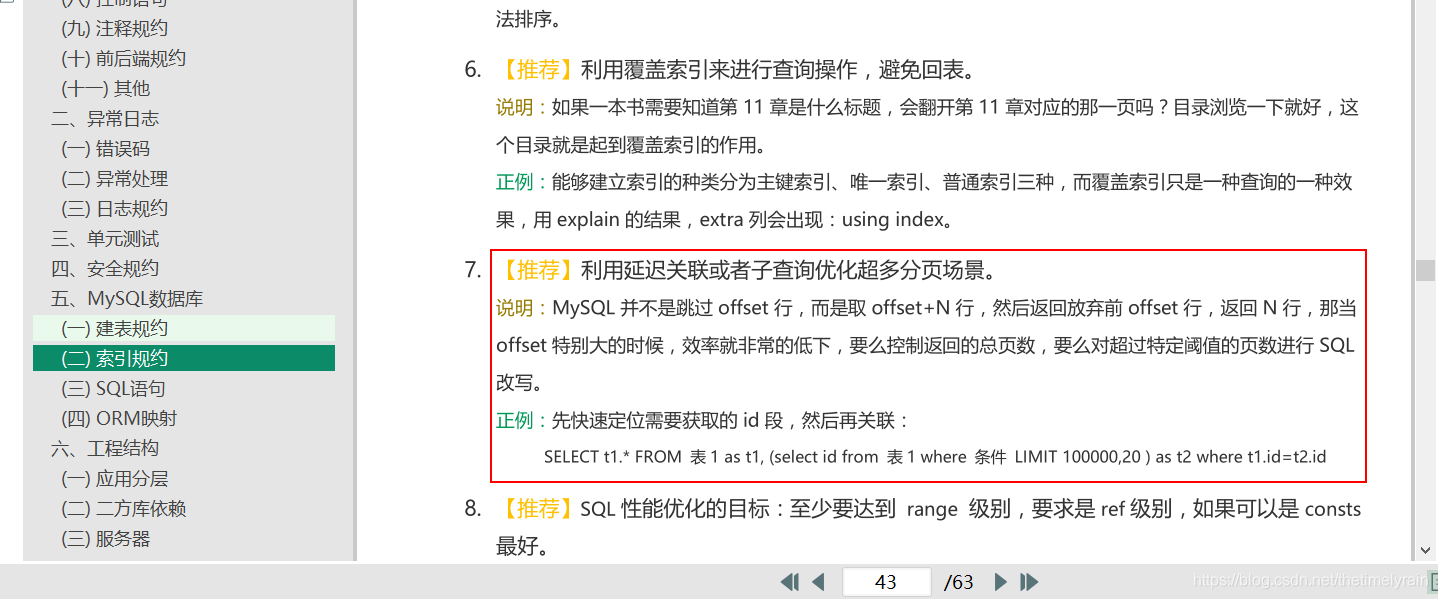
利用延迟关联或者子查询优化超多分页场景
SELECT
*
FROM
vote_record v1
INNER JOIN
(
SELECT id FROM vote_record WHERE vote_num > 200 LIMIT 800000, 10
) v2
ON v1.id = v2.id
由此看来,查询时间大大减少,结果也是正确的。阿里巴巴java开发手册里面也有类似的说明:

















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









