







机器学习05:SVM支持向量机的学习和应用SVM解决猫狗图像分类问题
文章目录
前言
svm作为深度学习提出前曾经风靡一段时间的机器学习方法,广泛被应用在数据分类,数据处理上。它以巧妙的算法(巧妙到对我来说真的有点复杂了😫😫😫。。。),速度快,分类正确率高而著称。我们本篇博客则重点介绍svm支持向量机的具体原理,以及他具体如何来处理分类问题。
1.从二维线性模型说起
让我们先来看这个问题,假设我们有给出一系列数据:
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
(
x
3
,
y
3
)
.
.
.
(
x
n
,
y
n
)
{(x_1,y_1),(x_2,y_2),(x_3,y_3)...(x_n,y_n)}
(x1,y1),(x2,y2),(x3,y3)...(xn,yn)
假设我们已经知道了他们中存在两个聚类,那么现在我们想要利用这一系列训练样本,训练出一个能够划分的这两个聚类的方法。使得接下来我们随机输入的点都能被正确的划分聚类。可视化问题就是下面这一张图:
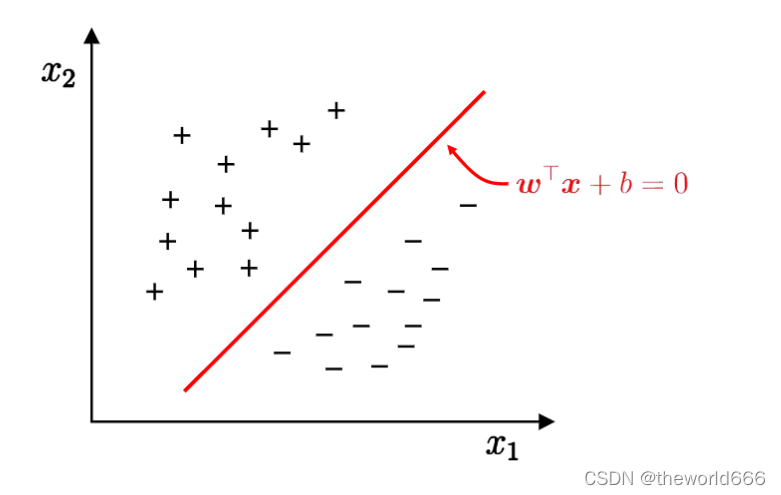
我们对此的目标就是寻找到出一个分割直线 wx + b =0,能够正确划分这两个聚类(之后我们使用正样本和负样本来代称)。使用数学问题来表述就是寻找到出一系列点使得对于所有正样本代入式子wx+b得到值为正,所有负样本代入式子wx+b值为负。
当然这里又出现问题了,就是其实根据训练数据样本的不同我们可以找到这样的分割向量其实理论上来说是可以无限种的(限制一段空间,我们依然能绘画出无数条直线)。那么选择哪一条最好呢?
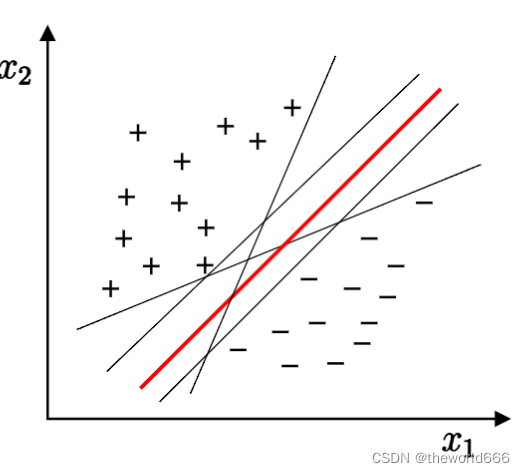
当然这里学者们依然给出了一个选择分隔直线的方法,我们选择能够能够使分隔间距最大的直线也就是图中红色这一条。为什么呢?因为我们生成出来的模型其实非常严重依赖当前训练集的数据。如果我们不选择间隔最大化的这条直线可能出现因为分隔平面与正样本区域距离的不够远导致一些原本属于负样本的点却被分类到负样本去了。
那么通过这上面的叙述,我们的问题就转化到下面这个问题上来了:
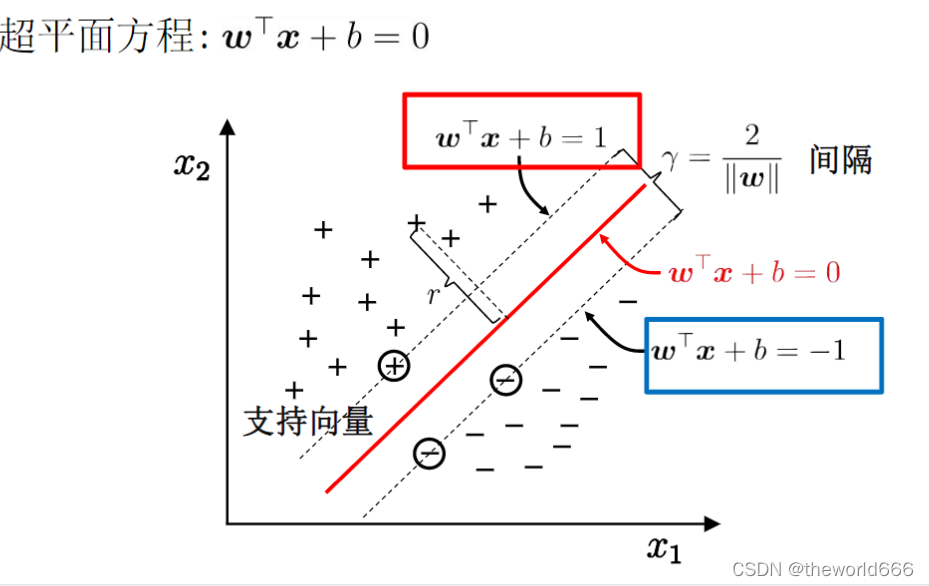
这些被圆圈圈住的点,我们就称之为支持向量(support vector)根据我们的假设这些支持向量代入直线计算只有可能为1或-1这两种值(至于如果你想了解为什么是1和-1而不是其他的数,这里推荐大家去看这位大佬的博客【机器学习算法】支持向量机入门教程及相关数学推导_SESESssss的博客-CSDN博客 ,这里我就不详细叙述了)。那么我们现在就是要寻找出一个最大间隔,这里我们使用数学表示就是:
对
于
正
样
本
,
负
样
本
中
最
靠
近
分
隔
直
线
的
向
量
存
在
以
下
参
数
w
,
b
使
得
w
⊤
x
+
b
=
1
w
⊤
x
+
b
=
−
1
我
们
计
算
这
两
条
直
线
到
直
线
w
⊤
x
+
b
=
0
的
距
离
计
算
可
得
:
γ
=
2
∥
w
∥
对于正样本,负样本中最靠近分隔直线的向量存在以下参数w,b使得\\ \boldsymbol{w}^{\top} \boldsymbol{x}+b=1 \\ \boldsymbol{w}^{\top} \boldsymbol{x}+b=-1\\ 我们计算这两条直线到直线\boldsymbol{w}^{\top} \boldsymbol{x}+b=0 的距离计算可得:\\ \gamma=\frac{2}{\|\boldsymbol{w}\|}
对于正样本,负样本中最靠近分隔直线的向量存在以下参数w,b使得w⊤x+b=1w⊤x+b=−1我们计算这两条直线到直线w⊤x+b=0的距离计算可得:γ=∥w∥2
这里在计算的时候使用了点到直线距离的计算公式有疑问的同学可以百度一下补充知识偶😘😘。到这里我们支持向量的最终目标就很明显了寻找到一个使得分隔最大的直线(对于高维的点是寻找分隔平面)来划分正样本和负样本。而为了寻找到这样的直线,我们其实并不需要利用所有样本,只需要这些距离分隔平面最近的向量来计算即可。所以这也是SVM(support vector machine)支持向量机名字的由来。他并不跟一般机器学习方法依赖数据集中的所有点来决定,他实际上只依赖于部分支持向量从而构建分类器。
那么又到了扯公式的时候了,如何寻找到这样的w,b呢?来让我们继续往下计算取:
arg
max
w
,
b
2
∥
w
∥
s.t.
y
i
(
w
⊤
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
…
,
m
.
\begin{aligned} \underset{\boldsymbol{w}, b}{\arg \max } & \frac{2}{\|\boldsymbol{w}\|} \\ \text { s.t. } & y_{i}\left(\boldsymbol{w}^{\top} \boldsymbol{x}_{i}+b\right) \geq 1, i=1,2, \ldots, m . \end{aligned}
w,bargmax s.t. ∥w∥2yi(w⊤xi+b)≥1,i=1,2,…,m.
这个式子不够方便计算,为了计算方便我们进行转换,求原始值倒数的最小值等同于求原始值的最大值,所以我们做如下转换:
arg
min
w
,
b
1
2
∥
w
∥
2
s.t.
y
i
(
w
⊤
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
…
,
m
\begin{aligned} \underset{w, b}{\arg \min } & \frac{1}{2}\|\boldsymbol{w}\|^{2} \\ \text { s.t. } & y_{i}\left(\boldsymbol{w}^{\top} \boldsymbol{x}_{i}+b\right) \geq 1, i=1,2, \ldots, m \end{aligned}
w,bargmin s.t. 21∥w∥2yi(w⊤xi+b)≥1,i=1,2,…,m
式子展开到现在其实已经知道怎么解决很明显了。相信如果是对学习过高等数学非常深刻的同学一定记得:举个例子:
给定一个约束条件F(x,y,z) = 0需要求解f(x,y,z)的最大值的方法。使用拉格朗日乘子方法可以轻松解决这个问题:
设
方
程
为
f
(
x
,
y
,
z
)
+
α
F
(
x
,
y
,
z
)
=
0
然
后
分
别
对
x
,
y
,
z
,
α
求
导
即
可
以
确
定
当
取
得
极
值
时
x
,
y
,
z
的
值
设方程为 f(x,y,z) + α F(x,y,z)=0\\ 然后分别对x,y,z,α求导即可以确定当取得极值时x,y,z的值
设方程为f(x,y,z)+αF(x,y,z)=0然后分别对x,y,z,α求导即可以确定当取得极值时x,y,z的值
但是这里可能有同学又要问了?但是你这里约束条件是不等式啊?不是等式这也能直接使用拉格朗日乘子方法来求解吗?那么接下来我们就来详细探究在不等式情况下我们需要如何求解呢?(接下来涉及很多数学公式的推导,限于博主的知识水平不足,可能推导过程中存在一些错误,希望大家能够在评论区指正😥😥😥
2. 如何求解SVM的相关变量
这里我们先来说明拉格朗日函数是否能解决不等式约束问题。其实拉格朗日函数原本的公式是:对于带约束条件的优化问题,如果满足以下形式,我们就可以使用拉格朗日函数进行转化:
min
x
∈
R
n
f
(
x
)
s.t.
c
i
(
x
)
⩽
0
,
i
=
1
,
2
,
⋯
,
k
h
j
(
x
)
=
0
,
j
=
1
,
2
,
⋯
,
l
\begin{aligned} &\min _{x \in \mathbb{R}^{n}} f(x) \\ &\text { s.t. } \\ &\begin{array}{l} c_{i}(x) \leqslant 0, \quad i=1,2, \cdots, k \\ h_{j}(x)=0, \quad j=1,2, \cdots, l \end{array} \end{aligned}
x∈Rnminf(x) s.t. ci(x)⩽0,i=1,2,⋯,khj(x)=0,j=1,2,⋯,l
对于上面这个式子,我们就可以转化为一个拉格朗日函数:
L
(
x
,
α
,
β
)
=
f
(
x
)
+
∑
i
=
1
k
α
i
c
i
(
x
)
+
∑
j
=
1
l
β
j
h
j
(
x
)
L(x, \alpha, \beta)=f(x)+\sum_{i=1}^{k} \alpha_{i} c_{i}(x)+\sum_{j=1}^{l} \beta_{j} h_{j}(x)
L(x,α,β)=f(x)+i=1∑kαici(x)+j=1∑lβjhj(x)
从而再进行求偏导联立方程等一系列操作来进行x变量的求解,而我们的svm其实是没有等式条件,所以我们可以把等式条件视为0=0,那么我们依然可以使用拉格朗日函数解决在不等式约束下的优化问题。
说明了能够使用拉格朗日函数方法求解在不等式约束下的极值优化问题那么我们现在就来从头到尾重新说明一下我们的求解变量步骤:
首先我们定义我们的问题如下
arg
min
w
,
b
1
2
∥
w
∥
2
s.t.
y
i
(
w
⊤
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
…
,
m
.
\begin{aligned} \underset{\boldsymbol{w}, b}{\arg \min } & \frac{1}{2}\|\boldsymbol{w}\|^{2} \\ \text { s.t. } & y_{i}\left(\boldsymbol{w}^{\top} \boldsymbol{x}_{i}+b\right) \geq 1, i=1,2, \ldots, m . \end{aligned}
w,bargmin s.t. 21∥w∥2yi(w⊤xi+b)≥1,i=1,2,…,m.
对此我们引入拉格朗日乘子使得式子如下:
L
(
w
,
b
,
α
)
=
1
2
∥
w
∥
2
−
∑
i
=
1
m
α
i
(
y
i
(
w
⊤
x
i
+
b
)
−
1
)
(
α
大
于
等
于
0
)
L(\boldsymbol{w}, b, \boldsymbol{\alpha})=\frac{1}{2}\|\boldsymbol{w}\|^{2}-\sum_{i=1}^{m} \alpha_{i}\left(y_{i}\left(\boldsymbol{w}^{\top} \boldsymbol{x}_{i}+b\right)-1\right) ({\alpha}大于等于0)
L(w,b,α)=21∥w∥2−i=1∑mαi(yi(w⊤xi+b)−1)(α大于等于0)
然后我们令函数L(w,b,α)对w和b的偏导为0,即可计算出最终的结果。但是这样的计算仍然是十分复杂的。所以我们这里使用一点小技巧将我们要计算出的最小结果(证明过程可以查看:不简单的SVM - 知乎 (zhihu.com))转化为:
min
w
,
b
1
2
w
T
w
=
min
w
,
b
max
α
L
(
w
,
b
,
α
)
=
max
α
min
w
,
b
L
(
w
,
b
,
α
)
\min _{w, b} \frac{1}{2} w^{T} w=\min _{w, b} \max _{\alpha} L(w, b, \alpha)=\max _{\alpha} \min _{w, b} L(w, b, \alpha)
w,bmin21wTw=w,bminαmaxL(w,b,α)=αmaxw,bminL(w,b,α)
也就是说我们最终求解w,b需要拉格朗日函数L的参与。那么我们接下来就直接在这个前提下进行推导。对于函数L我们令他对w,b的偏导都能为0得:
w
=
∑
i
=
1
m
α
i
y
i
x
i
,
∑
i
=
1
m
α
i
y
i
=
0
\boldsymbol{w}=\sum_{i=1}^{m} \alpha_{i} y_{i} \boldsymbol{x}_{i}, \quad \sum_{i=1}^{m} \alpha_{i} y_{i}=0
w=i=1∑mαiyixi,i=1∑mαiyi=0
将这样求解出来的公式代入原式可得:
min
α
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
⊤
x
j
−
∑
i
=
1
m
α
i
s.t.
∑
i
=
1
m
α
i
y
i
=
0
,
α
i
≥
0
,
i
=
1
,
2
,
…
,
m
.
\begin{array}{ll} \min _{\alpha} & \frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} \alpha_{i} \alpha_{j} y_{i} y_{j} \boldsymbol{x}_{i}^{\top} \boldsymbol{x}_{j}-\sum_{i=1}^{m} \alpha_{i} \\ \text { s.t. } & \sum_{i=1}^{m} \alpha_{i} y_{i}=0, \alpha_{i} \geq 0, i=1,2, \ldots, m . \end{array}
minα s.t. 21∑i=1m∑j=1mαiαjyiyjxi⊤xj−∑i=1mαi∑i=1mαiyi=0,αi≥0,i=1,2,…,m.
而这个就是我们支持向量机的基本形式,我们利用这个来求的使当前函数取得最小值时的α值。然后再利用上面求导朱来的公式求得我们的w值。
那么介绍完了这么多公式相信大家也昏昏欲睡了吧😂😂。那么我们接下来实战一下,在图像分类数据集上来尝试我们利用支持向量机svm的分类效果。
3.数据集介绍
SVM对于二分类问题有着非常好的效果。所以我们这里也使用一个非常著名的二分类数据集猫狗分类数据集,该数据集含有上万张的猫狗图像。他被经常使用于图像分类模型的测试和各式各样分类方法的测试。(依稀记得两年前被学长用猫狗分类数据集考核人工智能协会期末考试的噩梦时光)关于他的详细介绍和如何转化为向量,我在我之前的博客中有详细的介绍过(机器学习03:使用logistic回归方法解决猫狗分类问题_theworld666的博客-CSDN博客)。这里就不再详细介绍了。


4. 数据集处理
对于该数据集处理,为了加快速度我们这里会统一的将图像缩小为(64,64)的大小。同时也是为了方便处理,我们统一将猫狗标签使用-1,1进行划分:
import numpy as np
import random
import cv2
import glob
def path_to_data(all_img_path): #循环读取所有图片的路径
train_set = []
for path in all_img_path:
img = cv2.imread(path) #读取图片
mat = np.array(cv2.resize(img,(64,64))) #将图片大小调整为64*64
mat = mat/255 #图像像素值为0-255使用这样的方法归一化数据使得计算速度更快
train_set.append(mat.flatten())#使用ndarray自带的flatten方法进行压平
return train_set #返回存储所有像素数据的矩阵
if '__name__' == '__main__':
train_image_path = glob.glob("test/*.jpg")
# 使用列表推导式获得满足条件的图片
train_cat_path = [s for s in train_image_path if s.split('\\')[-1].split('.')[0] == "cat"]
train_dog_path = [s for s in train_image_path if s.split('\\')[-1].split('.')[0] == "dog"]
# 准备测试集数据,为了分类均匀猫和狗的图像选取一样多的数据量
test_dog_path = train_cat_path[500:650]
test_cat_path = train_cat_path[500:650]
test_cat_path.extend(test_dog_path)
test_label = [s.split('\\')[-1].split('.')[0] for s in test_cat_path]
test_data = path_to_data(test_cat_path)
label_to_index = {'dog': -1, 'cat': 1} # 标签替换字典
test_labels_nums = [label_to_index.get(l) for l in test_label] # 将猫和狗标签使用数字表示
#####准备训练集数据
train_cat_path = train_cat_path[:500]
train_dog_path = train_dog_path[:500]
train_cat_path.extend(train_dog_path)
train_image_path = train_cat_path
random.shuffle(train_image_path) ##训练集打乱数据加强训练模型泛化能力
train_label = [s.split('\\')[-1].split('.')[0] for s in train_image_path]
train_labels_nums = [label_to_index.get(l) for l in train_label]
dataArr = path_to_data(train_image_path)
在我们对测试集和训练集选择中,训练集抽取1000张图,测试集300张图片。其中训练集和测试集图片中的猫狗图片数量是一样多的。那么数据准备好了接下来我们就直接上硬菜:使用SVM代码解决图像分类问题并统计平均错误率。
5.使用SVM解决图像分类问题并统计平均错误率
def testRbf(dataArr, labelArr, testDataArr,testLabelArr,k1=1.3):
# 加载训练集
# dataArr, testDataArr, labelArr, testLabelArr = loadCSVfile2()
# 根据训练集计算b, alphas
print(np.shape(dataArr))
print(np.shape(labelArr))
b, alphas = smoP(dataArr, labelArr, 200, 0.0001, 100, ('rbf', k1))
datMat = np.mat(dataArr)
labelMat = np.mat(labelArr).transpose()
# 获得支持向量
svInd = np.nonzero(alphas.A > 0)[0]
sVs = datMat[svInd]
labelSV = labelMat[svInd]
print("支持向量个数:%d" % np.shape(sVs)[0])
m, n = np.shape(datMat)
errorCount = 0
for i in range(m):
# 计算各个点的核
kernelEval = kernelTrans(sVs, datMat[i, :], ('rbf', k1))
# 根据支持向量的点计算超平面,返回预测结果
predict = kernelEval.T * np.multiply(labelSV, alphas[svInd]) + b
# 返回数组中各元素的正负号,用1和-1表示,并统计错误个数
if np.sign(predict) != np.sign(labelArr[i]):
errorCount += 1
# 打印错误率
print('训练集错误率:%.2f%%' % ((float(errorCount) / m) * 100))
# showDataSet(dataArr, labelMat)
# 加载测试集
dataArr = testDataArr
labelArr = testLabelArr
errorCount = 0
datMat = np.mat(dataArr)
labelMat = np.mat(labelArr).transpose()
m, n = np.shape(datMat)
for i in range(m):
# 计算各个点的核
kernelEval = kernelTrans(sVs, datMat[i, :], ('rbf', k1))
# 根据支持向量的点计算超平面,返回预测结果
predict = kernelEval.T * np.multiply(labelSV, alphas[svInd]) + b
# 返回数组中各元素的正负号,用1和-1表示,并统计错误个数
if np.sign(predict) != np.sign(labelArr[i]):
errorCount += 1
# 打印错误率
print('测试集错误率:%.2f%%' % ((float(errorCount) / m) * 100))
return (float(errorCount) / m) #返回错误率吧
if __name__ == '__main__':
train_image_path = glob.glob("dc/train/*.jpg")
print(train_image_path[:10])
# 使用列表推导式获得满足条件的图片
train_cat_path = [s for s in train_image_path if s.split('\\')[-1].split('.')[0] == "cat"]
train_dog_path = [s for s in train_image_path if s.split('\\')[-1].split('.')[0] == "dog"]
# 准备测试集数据,为了分类均匀猫和狗的图像选取一样多的数据量
test_dog_path = train_cat_path[500:650]
test_cat_path = train_cat_path[500:650]
test_cat_path.extend(test_dog_path)
test_label = [s.split('\\')[-1].split('.')[0] for s in test_cat_path]
test_data = path_to_data(test_cat_path)
label_to_index = {'dog': -1, 'cat': 1} # 标签替换字典
test_labels_nums = [label_to_index.get(l) for l in test_label] # 将猫和狗标签使用数字表示
#####准备训练集数据
train_cat_path = train_cat_path[:500]
train_dog_path = train_dog_path[:500]
train_cat_path.extend(train_dog_path)
train_image_path = train_cat_path
random.shuffle(train_image_path) ##训练集打乱数据加强训练模型泛化能力
train_label = [s.split('\\')[-1].split('.')[0] for s in train_image_path]
train_labels_nums = [label_to_index.get(l) for l in train_label]
dataArr = path_to_data(train_image_path)
errornum=0
for i in range(10):
errornum+= testRbf(dataArr,np.mat(train_labels_nums),test_data,np.mat(test_labels_nums))
print("平均错误率是%.2f"%(errornum/10))
这里由于参考机器学习实战编写的SVM代码实在篇幅太长,所以就不放在博客里了。大家如果需要的话可以上Github下载即可😋😋😋😋。liujiawen-jpg/SVM: 使用支持向量机来解决猫狗分类问题 (github.com)
最终我们运行平均错误率吧达到了百分之二十五:

甚至达到了百分之1可以发现我们的效果还是非常不错的(这里博主多次运行发现实际上svm对于该数据集的随机性很强)所以建议大家每次训练完成后都使用numpy保存变量值,最后取最好的变量值即可。
结语
在本篇博客中,我们完成了对于SVM算法原理的简要阐释,以及如何使用SVM来解决一般图像二分类问题。当然由于本人水平有限对于SVM原理的阐述没有十分完全。有差错大家可以在评论区指正。















 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









