






1. redis非关系型数据库【重要】
1.1 非关系型数据库
NoSql: [Not Only Sql不仅仅是sql]. 它是对所有非关系型数据库的一种统称。非关系数据库它们之间不存在任何的关联关系。 它的数据结构: key-value模式--而且数据也可以持久化到磁盘上。
常见的非关系数据库的种类:
redis: 典型的非关系数据库
mogodb: 它是介于关系型和非关系之间。
hbase: 数据库【海量数据】
1.2 什么是redis
Redis是一种开放源代码(BSD许可)的内存中数据结构存储,用作数据库,缓存和消息代理。Redis提供数据结构,例如字符串,哈希,列表,集合,带范围查询的排序集合,位图,超日志,地理空间索引和流。Redis具有内置的复制,Lua脚本,LRU驱逐,事务和不同级别的磁盘持久性,并通过Redis Sentinel和Redis Cluster自动分区提供了高可用性。
redis它是一个开源的数据库,缓存的服务器,它里面可以存放字符串,hash,列表,集合数据类型的数据,它的计算基于内存进行计算的。而且数据也可以持久化到磁盘中。 而且它也提高了哨兵模式以及集群模式来提高redis的可用性。
1.3 redis特点 【为什么使用】
1.Redis读取的速度是110000次/s,写的速度是81000次/s 2.原子 。Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。 ---影响redis性能的因素:内存而不是多线程 3.支持多种数据结构:string(字符串);list(列表);hash(哈希),set(集合);zset(有序集合) 4.持久化--磁盘--防止数据丢失 5.官方不支持window系统,但是又第三方版本。 linux系统。
1.4 如何安装redis
使用c语言编写的一款软件。
Redis从发布至今,已经有十余年的时光了,一直遵循着自己的命名规则:
版本号第二位如果是奇数,则为非稳定版本 如2.7、2.9、3.1
版本号第二位如果是偶数,则为稳定版本 如2.6、2.8、3.0、3.2
Redis的下载:Download | Redis

1.安装redis需要的环境。
gcc -v #查看版本
yum -y install gcc-c++ #安装c++库环境2.解压redis压缩文件
#切换到安装目录
cd /usr/soft
#解压下载的版本
tar -zxvf xxx.tar.gz

3.进入解压目录 并进行编译和安装
# 进入解压目录
cd redis-6.2.12
# 编译并安装
make && make install 
4.启动redis服务 在解压目录下
redis-server redis.conf
5.客户连接redis服务
redis-cli -h ip -p port
-h:表示连接redis服务所在的ip
-p:表示连接redis服务的端口号
redis-cli: 表示连接本地的redis服务

Redis关闭
-
第一种关闭方式:(断电、非正常关闭。容易数据丢失)
-
查询PID ps -ef | grep -i redis kill -9 PID
-
第二种关闭方式(正常关闭、数据保存)
redis-cli
shutdown 
或者通过指定端口号关闭
redis-cli -p 端口号
shutdown 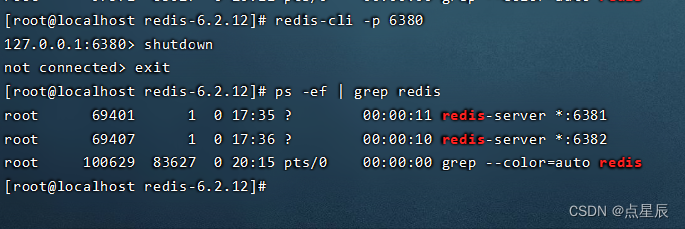
1.5 简单对redis配置文件了解
259 daemonize no: 设置redis服务启动时是否为守护进程
98 port 6379 修改redis的服务的端口号
75 bind * -::* 设置允许哪些ip连接redis服务器 * -::*允许所有



1.6 redis也提供了客户端界面

注意: 必须redis服务端设置了允许任意ip连接
1.7 redis中常用的命令
Redis 键(key) 命令:redis命令手册
Redis 命令参考:Redis 命令参考 — Redis 命令参考
(1)关于对key操作的命令
keys *: 查看redis中所有的key
exists key: 判断指定的key是否存在。存在返回1 否则返回0
del key: 删除指定的key
expire key seconds: 为指定的key设置过期时间。seconds 单位:秒


(2)关于库的命令:
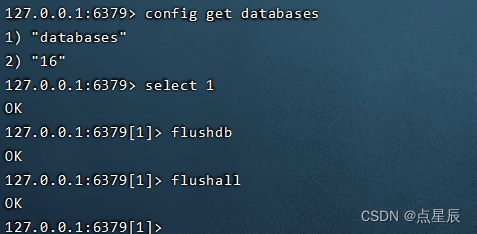
默认redis中存在16个库。 
select index: 切换到指定的数据库,数据库索引号
index用数字值指定,以0作为起始索引值。默认使用0号数据库。flushdb: 清空当前数据库
flushall: 清空所有库的数据
config get databases:使用config get databases可以获取的数据库的数量
(3)redis支持数据类型中常用命令
redis中存放的数据类型非常多,而我们使用最多的: 字符串类型,Hash类型,List队列类型, Set集合类型, SortSet有序集合类型。
set key value: 存储字符串类型的value.
get key: 根据key获取对应的value字符串值。
mset key value key value ...: 存储多个字符串类型的value
mget key key key...:获取多个key对应的value字符串值
setnx key value: 如果存在指定key,则不存入,如果不存在则存入。
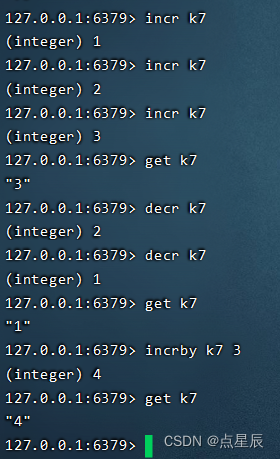
incr key: 对指定的key的value值进行递增。key对应的value必须为整型字符串
decr key: 对指定的key的value值进行递减。key对应的value必须为整型字符串
incrby key number: 按照number值进行递增

总结:
redis的安装
redis的简单配置
redis客户端界面
redis常用的命令 【1】key的命令 【2】库的命令 【3】关于字符串的命令
2. 回顾
1. nginx的高可用。---使用keepalived实现的
2. 非关系数据库--redis.
3. redis常用的命令:
[1]key的命令: keys *: 查看所有的key
[2]exists key:判断指定的keyi是否存在
[3]del key: 删除指定的key.
[4]expire key seconds: 为指定的key设置过期时间。
[2]关于库的命令: select n: 切换库。
flushdb:清空当前库
flushall:清空所有的库
[3]redis支持的数据类型: String Hash List set sortSet
String数据类型的命令: set key value
get key
mset key value key value....
mget key key
setnx key value
incr key:
decr key:
3. 正文
1. Redis其他数据类型
2. redis的应用场景。
3. redis的持久化方式
4. redis解决单机故障问题---集群模式
5. java连接redis.
4. Redis其他数据类型
4.1 hash数据类型
它的value就是一个hash类型,而hash类型的结构key value形式。一般用于存放对象数据。
hset key field value [field value]: 将哈希表 key 中的字段 field 的值设为value
hget key field: 获取存储在哈希表中指定字段的值。
hgetall key: 获取在哈希表中指定 key 的所有字段和值
hkeys key: 获取所有哈希表中的字段
hvals key: 获取哈希表中所有值
hdel key field: 删除一个或多个哈希表字段hmset :同时将多个 field-value (域-值)对设置到哈希表 key 中。

4.2 List<列表>数据类型
它的value是一个List数据类型,value可以是多个,而且有序,可以重复。
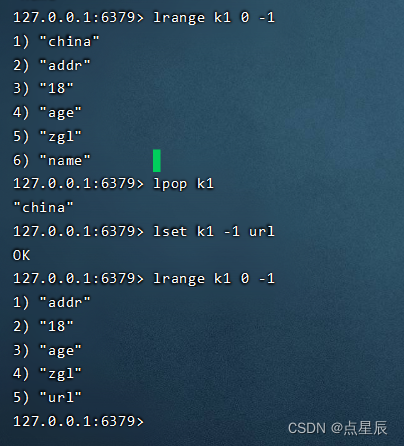
lpush key element [element...]: 在列表中添加一个或多个值
Lindex key index: 获取列表中指定下标的元素。
lrange key start end: 获取一定范围的元素。第一个为0 最后-1
lpop key: 移除左边第一个元素
lset key index element: 替换指定位置的元素内容

4.3 Set 数据类型
它和list类型差不多,只是它的值不允许重复,而且是无序。
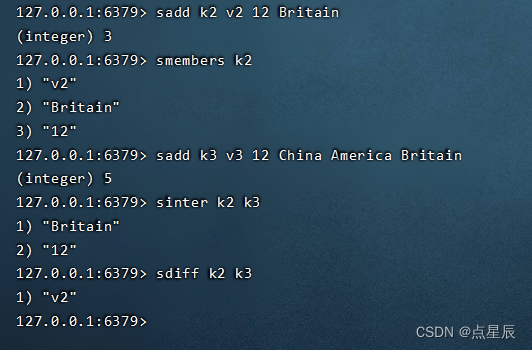
sadd key element[element....]: 在集合中添加一个或多个值
smembers key: 获取集合中所有的元素。
sinter key1 key2: 返回给定所有集合的交集
sdiff key1 key2: 返回给定所有集合的差集
4.4 sort set 数据类型
它和set比较相似,它在添加元素时,指定了分数值,按照分数排序。排行榜。
zadd key score element [score element ...]:添加有序集合元素
zrange key start end [withscopes]: 从小到大的形式获取集合中的元素
zrevrange key start end [withscopes]: 从大到小的形式获取集合中的元素
zrem k1 element [element]: 移除集合中一个或多个元素
 5. redis实际开发的应用场景
5. redis实际开发的应用场景
1、热点数据的缓存: 减少对数据库的访问频率和减轻数据库的压力。
2. 限时业务的运用: 秒杀 存储登录者用户信息 存储短信验证码
3. 计数器相关问题: 点赞数 收藏数 播放量。
4. 排行榜相关问题: sort set
5. 分布式锁: ---同步锁:
6. 限量秒杀: ---decr key:
6. redis的持久化
把内存中的数据持久化到磁盘中,防止数据丢失。---当redis服务器开启时,会把磁盘中的数据加载到内存中进行计算。
提高了两种持久化方式:
RDB和AOF.
6.1 RDB持久化
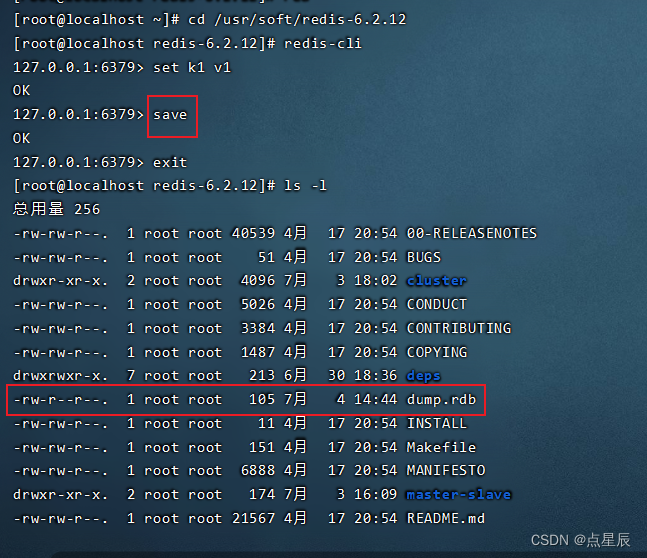
它是每隔一段时间进行快照存储。--它是一个二进制文件,里面的内容打开后无法看懂。
触发机制:
[1]save---手动触发
[2]bgsave--手动触发
[3]通过配置文件--自动触发
(1)save触发

 该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。具体流程如下:
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。具体流程如下:
执行完成时候如果存在老的RDB文件,就把新的替代掉旧的。我们的客户端可能都是几万或者是几十万,这种方式显然不可取。
bgsave:
 执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体流程如下:
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体流程如下:
bgsave在执行该命令时会fork出一个新的线程,单独执行rdb持久化操作,而不影响其他客户对redis服务的操作。
不管使用save还是bgsave都需要手动输入。我们也可以通过配置文件完成自动化rdb操作。

RDB快照持久化优缺点:
优点: ----数据恢复速度快。
缺点: ----数据完整性差--会丢失最后一段时间的数据。
6.2 AOF持久化
日志追加持久化,当我们执行写操作,会触发一个函数write,把会把写操作的命令追加到一个日志文件appendfile中。当服务器启动时会把appendfile中的命令从新执行一遍。默认不开启。
手动开启aof模式。 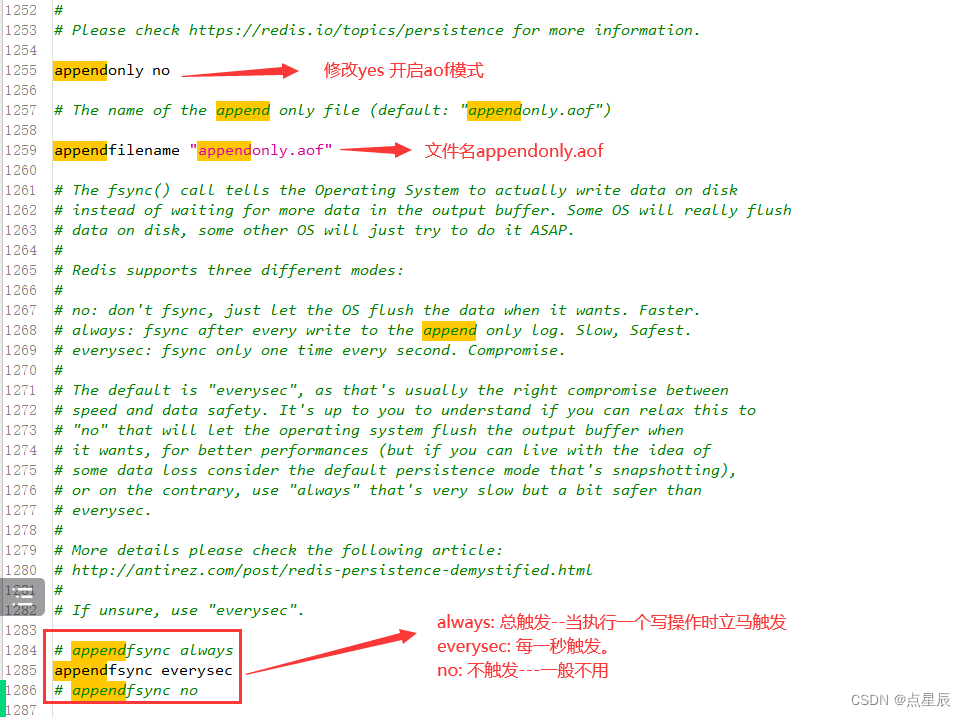
AOF优缺点:
优点: 数据完整性高---丢失最后一条指令。
缺点: 数据恢复慢。
如果rdb和aof都使用,当服务器重启时会加载哪个文件?
先加载AOF的文件【它以数据完整性为主】
7. redis集群模式
提供了三种集群模式.
[1]主从模式
[2]哨兵模式
[3]集群模式
为什么要使用集群模式?
[1]解决单机故障问题 [2]解决单机压力问题

7.1 主从模式
配从不配主:非常简单。
1.准备: 一台linux服务。 开三个redis服务----通过修改port----6380 [主] 6381 6382[从]。


2.分别修改 port端口号、rdb文件名和关闭aof
修改:
1.port端口号
2.rdb文件名dump638X.rbd
3.关闭aof



3.启动上面三个redis服务
redis-server redis6380.conf
redis-server redis6381.conf
redis-server redis6382.conf4.查看redis服务是否启动
ps -ef | grep redis
5.进入相应的客户端
redis-cli -p 6380
redis-cli -p 6381
redis-cli -p 6382


XShell安装:XShell免费版的安装配置教程以及使用教程(超级详细、保姆级)_普通网友的博客-CSDN博客



6. 查看每个redis服务的角色:
info replication
发现他们都是master角色,如何分配主从关系:
通过 :slaveof 将当前服务器转变从属服务器(slave server)
返回值:slaveof 命令执行后,总是返回OK
命令格式:slaveof host port
slaveof 192.168.206.134 6380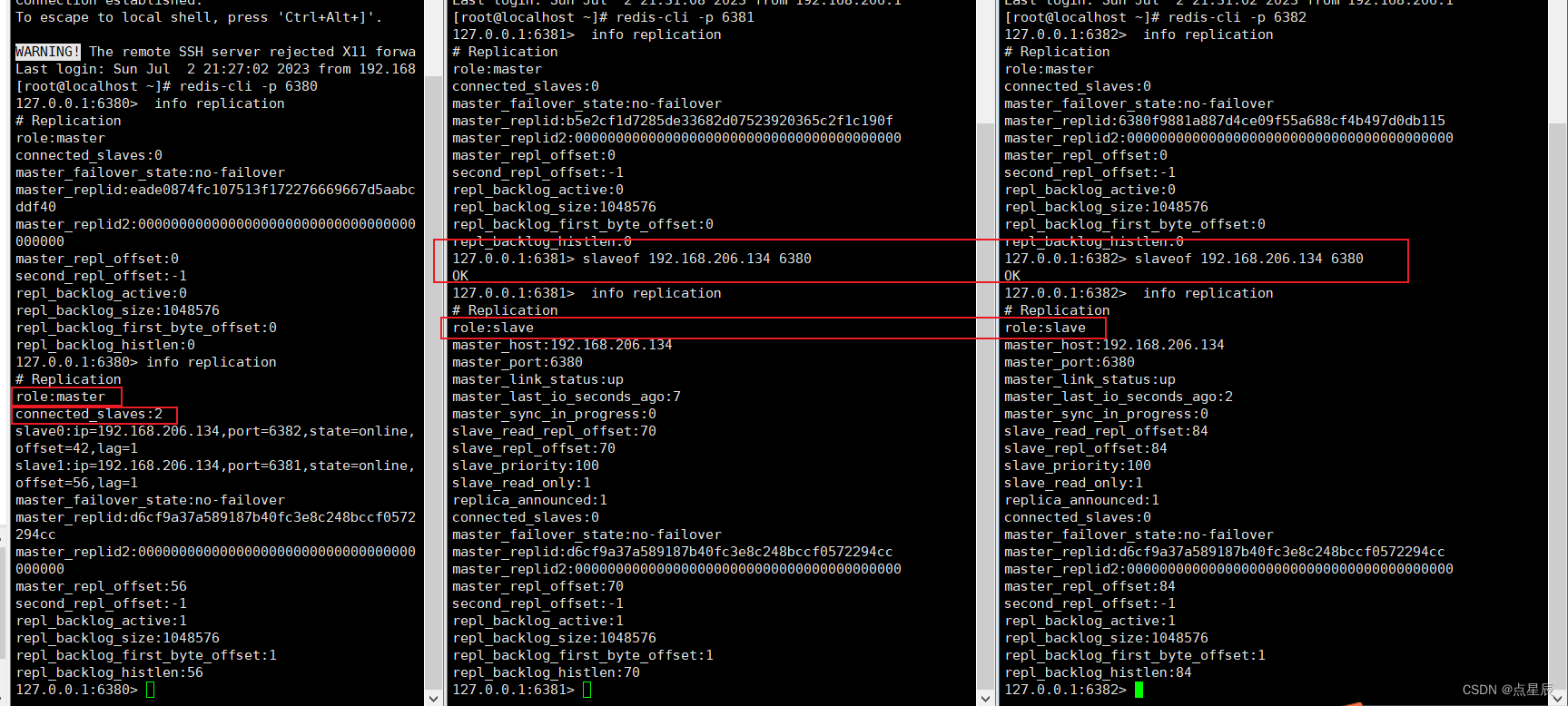
主节点修改数据时,主节点的数据会同步到所有的从节点。
从节点只能进行读操作,不能执行写操作。
(1) 如果主节点宕机,从节点会不会篡位?---不会自动上位。
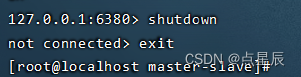


(2) 如果增加一个从节点,该节点会不会把之前主节点的数据同步过来?----一定同步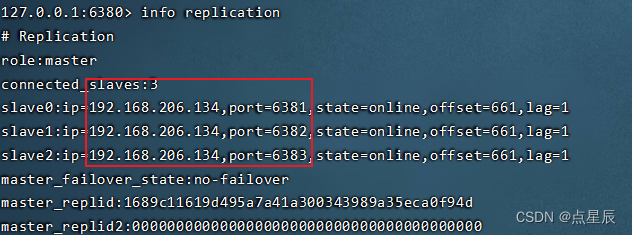


回顾:
1. redis非关系数据库--支持的数据类型
1.1 Hash数据类型:
1. hset key field value field value:存放hash数据
2. hget key field: 获取hash中指定field的值
3. hgetall key: 获取指定key对应所有hash类型
4. hkeys key:
5. hvals key:
6. hdel key field:
1.2 List列表类型:
lpush key value value value...
lindex key index:
lrange key start end:
lpop key:
lset key index newValue;
1.3 Set集合类型
sadd key value value ....:
smembers key:
sinter key key:
1.4 sort Set集合类型
zadd key score value score value...:
zrange key start end:
zrevrange key start end:
2.redis的持久化:
RDB:在一定时间间隔内,进行快照存储。优点:数据恢复快 缺点:数据完整性差。
AOF:日志追加,每执行一次写操作,则通过write函数追加到日志文件后面。优点:数据完整性高,缺点:数据恢复慢。
3.redis的应用场景:
热点数据的缓存: 减少对数据库的访问频率和减轻数据库的压力。
限时业务的运用
计数器相关问题
排行榜相关问题
分布式锁
限量秒杀
4.redis的集群模式:
[1]主从模式:主节点负责写操作,而从节点只负责读操作。如果主节点宕机,从节点不会自动上位。如果增加一个从节点,该节点会把之前主节点的数据同步过来。
7.3 哨兵模式
由于上面主从模式,主节点宕机后,从节点不会自动上位,这段时间内无法进行写操作了。
解决上面的问题:----哨兵模式---->【1】监控功能 【2】故障恢复 【3】选举一个master主节点
7.3.1 监控功能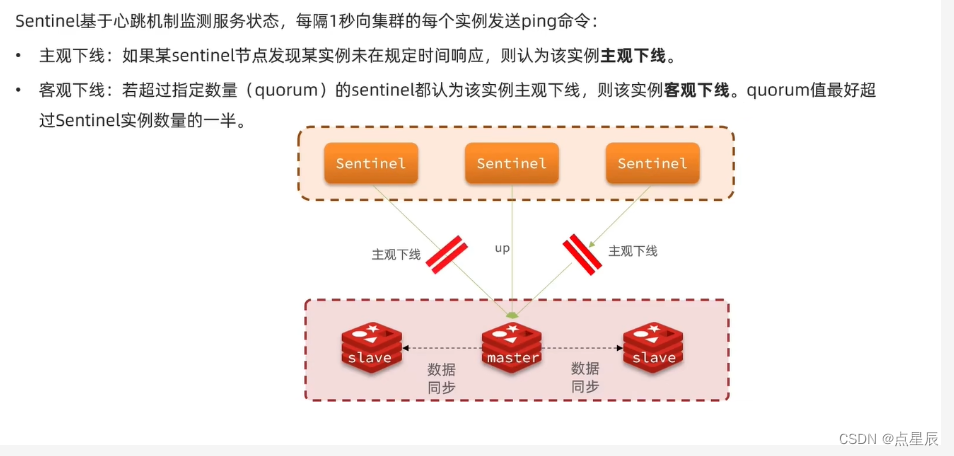
7.3.2 master节点的选举
7.3.3 启动哨兵
修改哨兵的配置:
修改为自己主节点ip和端口号
启动哨兵模式:
redis-sentinel sentinel.conf 
测试: 使用shutdown让主节点宕机 观察sentinel的控制台

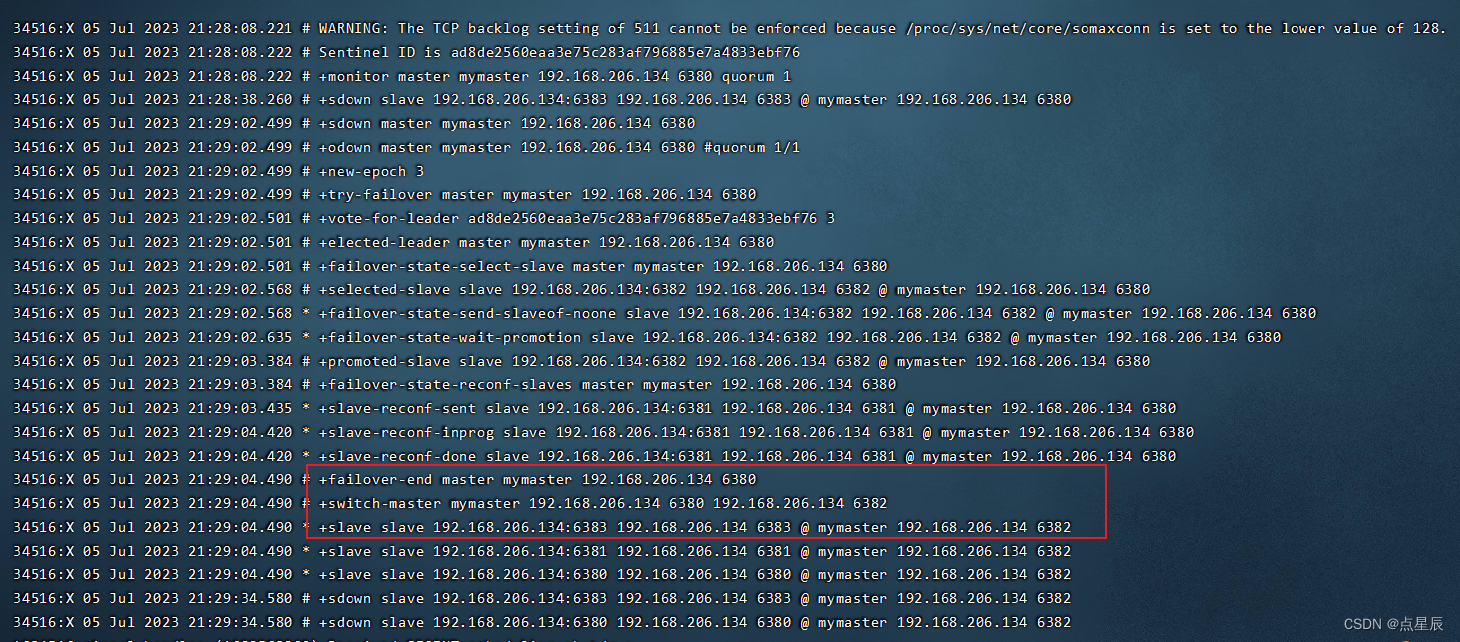
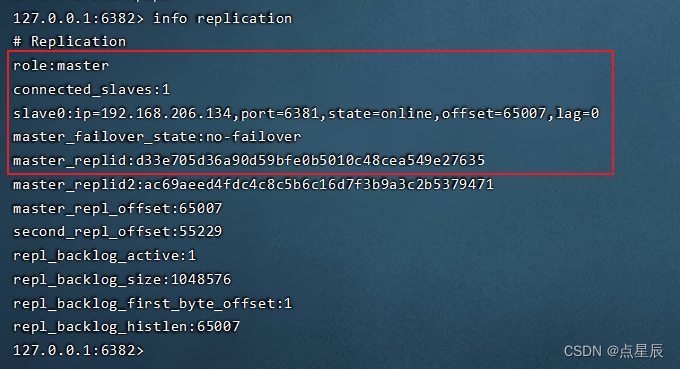
如果原来的master回来,跟着现在的master混。

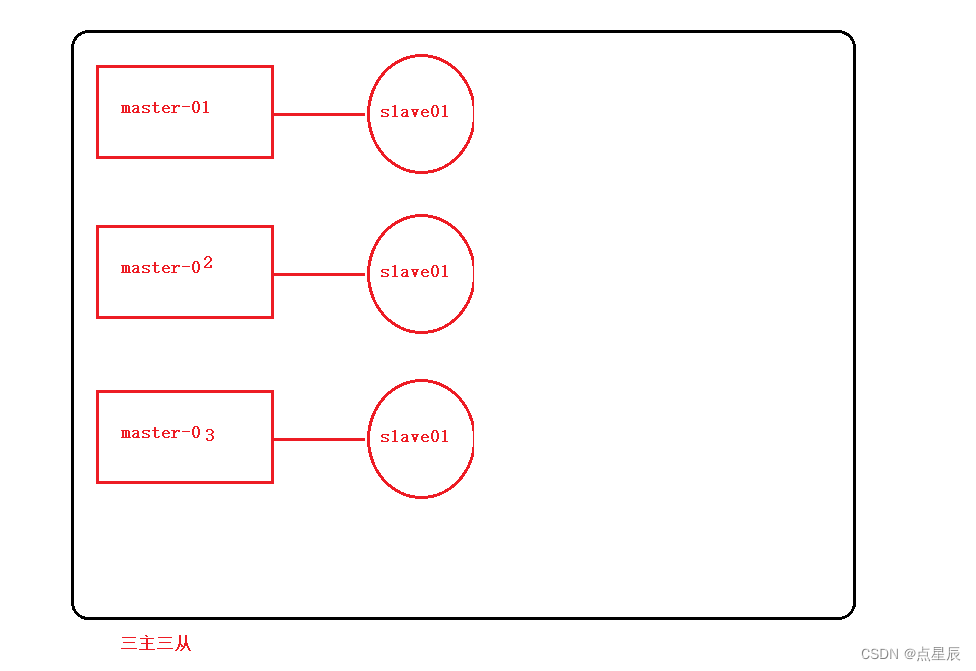
7.4 集群模式
不管是主从模式还是哨兵模式,始终只有一个master主节点。如果写操作并发高. 势必会导致master节点的压力过大。
真正的集群:
存储原理:
redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个整数结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
当你往Redis Cluster中加入一个Key时,会根据crc16(key) mod 16384计算这个key应该分布到哪个hash slot中,一个hash slot中会有很多key和value。你可以理解成表的分区,使用单节点时的redis时只有一个表,所有的key都放在这个表里;改用Redis Cluster以后会自动为你生成16384个分区表,你insert数据时会根据上面的简单算法来决定你的key应该存在哪个分区,每个分区里有很多key。
搭建三主三从:
7001~7006: 6台redis服务。
创建一个文件夹cluster存放6个redis的配置文件
创建cluster文件夹:
mkdir cluster
修改6台redis配置文件--必须redis服务是空的
(1)端口号
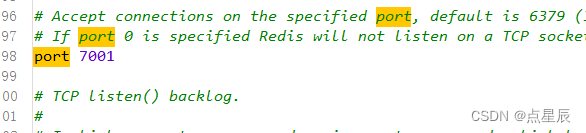
(2) bind绑定---任意
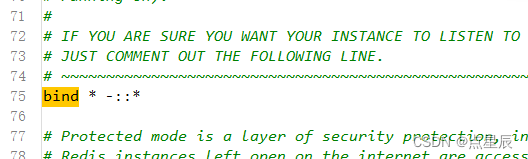
(3) dump文件的名称
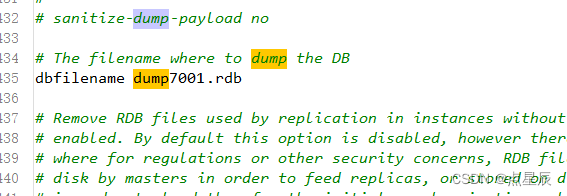
(4)必须开启aof模式并修改文件名

(5)开启集群模式
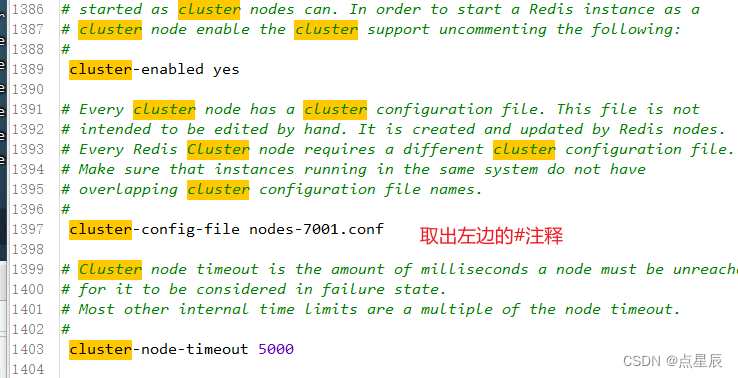
开启上面6台redis服务
redis-server redisXXX.conf
分槽,以及设置主从关系。
redis-cli --cluster create --cluster-replicas 1 192.168.206.134:7001 192.168.206.134:7002 192.168.206.134:7003 192.168.206.134:7004 192.168.206.134:7005 192.168.206.134:7006


访问:
redis-cli -c -h 192.168.206.134 -p 7001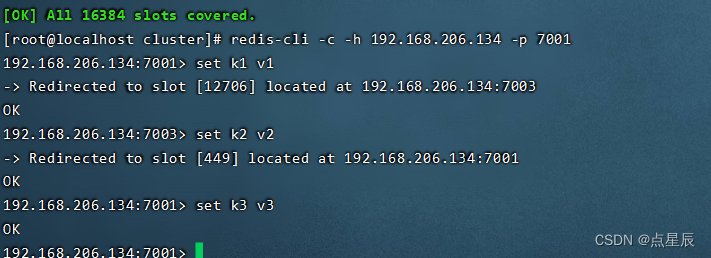















 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









